
es整理
1.索引分为读索引和写索引,可以每天建一个写索引, 并把之前的写索引改为is_write_index: false
2.分片shards(primary/replica), "别名+是否可写" 3个概念
2.1 primary分片不一定是平均分布的, 甚至所有primary分片可在一个节点上.
2.2 replica不参与写, 但是会参与读,所以也能提升读性能.
2.3 原则上primary与对应的replica不能再同一个节点上, 但是实际上是可以的,此时的replica被特殊标识
3.假定shards=2, replica=1,那么一个index有2个primary shard, 每个primary shard有一个副本 ==> 共有4块数据
4.如果字段是对象,且对象中的字段个数不确定,可以使用flattened类型,它和object类型类似,但是它不走分词. 而且查询既支持a查询,也支持a.b查询. 适用场景: dynamic定义为 strict了,但是某个对象中的字段不确定.(其实可以还是使用Object类型,在对象中再设置dynamic=true)
5.dynamic: strict的也可以添加字段, 通过 PUT /xxx/_mapping {"properties": 你的字段}, 但是不可以修改类型.
6. reindex 可以通过script处理数据, 比如判断哪些数据要哪些不要, 可以挑选需要的字段, 还可以对字段重命名等,见波波微课3.1.6reindex课程
7.不需要打分的text设置为norms=false, 不需要查询的字段设置index=false, 不需要排序和script访问的字段设置doc_values=false; (es查询流程,先通过倒排索引只查出文档id, 如果要再聚合则需要查文档中具体的值. 此时如果直接拿文档内容性能是很查的, 所以lucence就搞了一个正排索引表. 参见https://blog.csdn.net/qq_26229005/article/details/90340398)
50.常用命令:
50.1 查集群健康状态 GET /_cluster/health 或 /_cat/health?v
50.2 查看节点状态 GET /_cat/nodes?v
50.3 查看所有index健康状态 GET /_cat/indices?v &health=red
50.4 查看素有shards健康状态 GET /_cat/shards?v
50.6 创建索引 PUT /索引名称 {"aliases": {}, "mappings": {}, "settings": {}}
50.7 添加(包括两种,1用户提供id: PUT, 2.自动生成id: POST) eg:
PUT /book/_doc/1
{字段}
POST /book/_doc
{字段}
50.8 修改 // 注意put也有更新功能,只是它必须写完整所有字段, 而post是对指定的字段操作.
1. 修改某个值
POST /books/_update/1 { "doc" : { "字段" : "值" } } 2. 通过script修改值,甚至可以添加修改字段名
复杂的条件更新

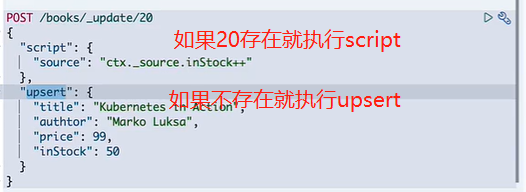
50.9 删除
DELETE /book/_doc/123
post /book/_delete_by_query
{}
50.10 额外补充_bulk
POST /book/_bulk
{ "index/create" : {}}
{数据}
{ "index/create" : {}}
{数据}
50.11 添加或修改字段(在严格模式不可修改), 同时还能添加别名
#添加/修改字段
PUT /book/_mapping
{
"properites" : {
"新字段" : {
"type" : "xxx"
}
}
}
#添加别名
PUT /book/_mapping
50.12 添加别名
PUT /book/_alias/别名名称
50.13 关闭写索引的方法
POST /_aliases
{
"actions" : [
"add" : {
"index" : "xxx" ,
"alias" : "别名" ,
"is_write_index" : false
}
]
}
或设置阻止写入. 建议用下面这种
PUT /book/_setting
{
"settings" : {
"index.blocks.write" : true
}
}
50.20 查询
1. GET /books/_doc/1 #查指定id
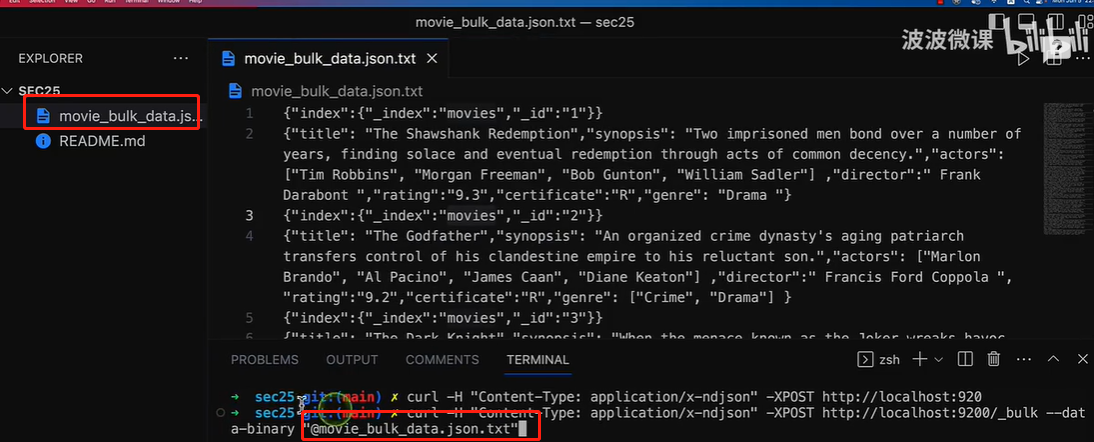
50.30 curl导入数据
60.查询小知识
60.1 如果让一个字段既支持分词,同时也支持keyword, 可以把字段type定义为text,同时添加fileds: {raw: {type: keyword}}, 通过wildcard: xxx.raw进行模糊查询
60.2 es支持字段中包含对象, 其查询字段用aaa.bbb搞
60.3 term是精确查询, 只能查不进行分词的字段, wildcard是like查询, 也是查询keyword类型. 特殊说明term可以查到数组中的一个完整字符串
60.4 match会查分词
70. 其他说明
70.1 实际使用可以建模板+alias, 每天/月第一秒关闭写索引, 然后新建一个今天的写索引索引. 这样方便老化数据,与提升查询性能. 见 https://www.bilibili.com/video/BV1bz4y1g7wP/?spm_id_from=333.788
如何提示查询性能呢? 指定索引时可以使用统配, 比如查询book*的数据 ==>更简单的方法是使用_rollover [ 4.8-高级索引操作-rollover API_哔哩哔哩_bilibili.html ]
要求:
1. 原索引名称必须符合格式,保证可以自增
2._rollover作用在别名上,所以原索引必须有别名
==> 更简单的是通过生命周期策略 [4.9-索引生命周期管理(ILM)]
步骤:
1. 创建ilm策略
2.创建模板并应用策略,并指定别名
3.创建索引必须有别名
70.2 一个输入内容需要同时查几个字段, 可以使用copy_to
100: strict的索引添加字段并数据迁移. 见附件. https://files.cnblogs.com/files/trump2/strict-%E6%B7%BB%E5%8A%A0%E5%AD%97%E6%AE%B5.zip?t=1696730686&download=true
A. 建立模板; B. 把原来的索引写功能关闭; C.创建新的写索引; D._reindex数据迁移; E.删掉旧的索引

 浙公网安备 33010602011771号
浙公网安备 33010602011771号