
kafka学习
1. 同一个组, 如果消费者数>partation数, 则多出的消费者数啥也不干; 如果消费者数<partation数, 则有得消费者会消费多个partation;
2.同时如果消费者没有变动(添加/杀掉), 则已经分配好的关系不会改变.
3.保证顺序,可以使用key,kafka生产者发送消息时会根据key去判断消息打到那个patitation.
4.kafka的partation如果是多个borker, 则采用均匀分配策略
下图设置topic-1的partions为3,会自动分配在不同的broker上,采用均匀分配策略,当broker和partions一样时,就均匀分布在不同的broker上。
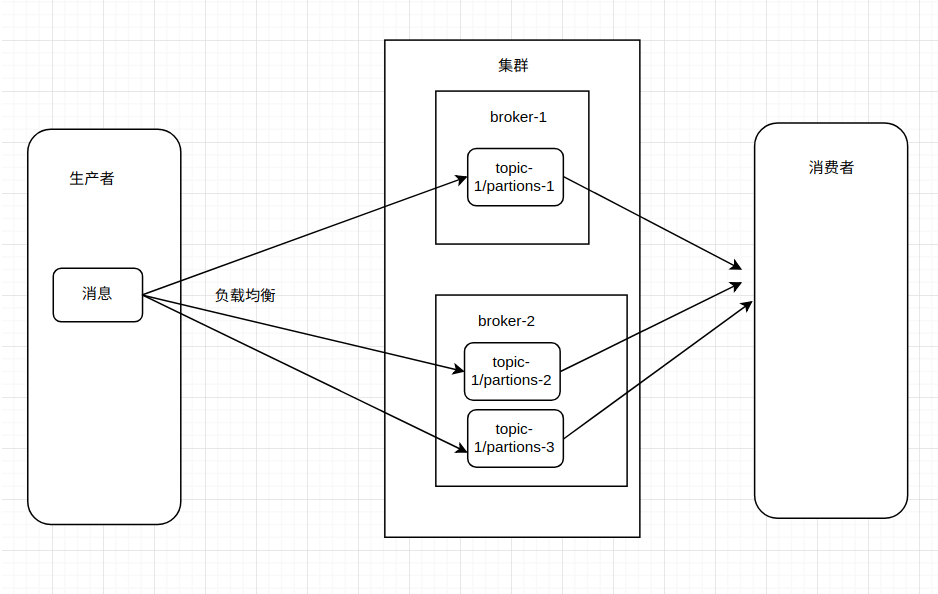
5.副本: 是指patation的备份.(它的备份并不备份在本机上, 这样即时一台挂了,其他机器也顶上), 如果不设副本, 则replicationFactor为1(本身相当于1个副本)
6. 集群搭建: https://blog.csdn.net/qq_32212587/article/details/124447901
https://xdclass.net/#/dplayer?video_id=65&e_id=128054
或https://www.bilibili.com/video/BV1VS4y1K7kD?p=5
或 https://coding.imooc.com/class/chapter/434.html#Anchor
如果想支持用户随时关注取关,
@Bean
public KafkaConsumer getConsumer(){ Properties properties = new Properties(); //设置key-value序列化 properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.ByteArrayDeserializer"); properties.put("bootstrap.servers",servers); properties.put("session.timeout.ms",sessionTimeout); //提交方式 // properties.put("enable.auto.commit",enableAutoCommit); properties.put("auto.commit.interval.ms",autoCommitInterval); properties.put("group.id",groupId); properties.put("auto.offset.reset",autoOffsetReset); properties.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 10000); properties.put(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG,1048576 * 4); properties.put(ConsumerConfig.FETCH_MAX_WAIT_MS_CONFIG,10000); properties.put(ConsumerConfig.FETCH_MIN_BYTES_CONFIG,1048576); properties.put("heartbeat.interval.ms",heartbeatIntervalMS); return new KafkaConsumer(properties); }
------------------------------ kafka主动拉取消息,多线程处理数据---------------------------
public KafkaConsumer getConsumer(){
Properties properties = new Properties();
//设置key-value序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.ByteArrayDeserializer");
properties.put("bootstrap.servers",servers);
properties.put("session.timeout.ms",sessionTimeout);
//提交方式
properties.put("enable.auto.commit",enableAutoCommit);
properties.put("auto.commit.interval.ms",autoCommitInterval);
properties.put("group.id",groupId);
properties.put("auto.offset.reset",autoOffsetReset);
properties.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 10000);
properties.put(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG,1048576 * 4);
properties.put(ConsumerConfig.FETCH_MAX_WAIT_MS_CONFIG,10000);
properties.put(ConsumerConfig.FETCH_MIN_BYTES_CONFIG,1048576);
properties.put("heartbeat.interval.ms",heartbeatIntervalMS);
return new KafkaConsumer(properties);
}
@Slf4j
@Component
public class MyConsumerRunnable implements ApplicationRunner {
@Autowired
KafkaConsumerConfig kafkaConsumerConfig;
@Value("${maxQueueSize}")
private int maxQueueSize = 300;
@Autowired
private FileBeatLogHandler fileBeatLogHandler;
@Override
public void run(ApplicationArguments args){
KafkaConsumer consumer = null;
try{
consumer = kafkaConsumerConfig.getConsumer();
consumer.subscribe(Collections.singletonList("my_beats"));
while (true) {
if(ThreadPoolUtil.executor.getQueue().size()>maxQueueSize) {
log.info("线程池队列中线程数:{}",ThreadPoolUtil.executor.getQueue().size());
Thread.sleep(1000);
continue;
}
try {
ConsumerRecords<String, byte[]> records = consumer.poll(100);
if(records.isEmpty()) continue;
log.info("拉取到了{}条消息", records.count());
Runnable runnable = () -> {
fileBeatLogHandler.consume(records);
};
ThreadPoolUtil.executor.execute(runnable);
}catch (Exception e) {
log.error("消费kafka数据失败!, error: {}", e.getMessage());
}
}
}catch (Exception e) {
log.error("MyConsumerRunnable-run失败!, error: {}", e.getMessage());
}finally {
if (consumer!=null){
consumer.close();
}
}
}
}
无聊我就学英语

 浙公网安备 33010602011771号
浙公网安备 33010602011771号