
量化交易系统--数据库搭建(从原理到实践)
数据模块架构:


数据库用途规划
| 数据库 | 存储内容 | 分片策略 | 推荐理由 |
|---|---|---|---|
| TDengine | Tick数据、分钟线 | 超级表 + 子表 | 性能与灵活性的完美结合,为时序数据而生。 |
| PostgreSQL | 日线、复杂因子、基本面 | 单一大表 + 时间分区 | 适合复杂关联查询和分析,关系模型表现力强。 |
| Redis | 实时行情、状态、缓存 | Key中含代码 | 逻辑分片,实现毫秒级访问,清晰直观。 |
| MySQL | 元数据(代码表、日历) | 经典关系表 | 保证数据一致性和关系完整性。 |

一、TDengine (专为时序数据设计)
策略:超级表(Super Table) + 子表(Sub-Table)模式 —— 这是“所有股票一张表”和“每支股票一张表”优势的结合体,是最优解。
TDengine的设计哲学是:为每个数据采集点(在您这就是每支股票)创建一张独立的子表,但这些子表都遵循一个由超级表定义的统一模板。
优势:您既可以像查询“一张大表”那样进行全局分析,又可以像查询“单个小表”那样高效获取单支股票的数据。
结论:对于TDengine,您不需要自己纠结分片策略,使用其内置的超级表模式就是最佳实践。
二、PostgreSQL + TimescaleDB (用于日线、基本面、复杂因子)
策略:单一大表 + 分区表(Partitioning) —— 即“所有股票放一张表”,但按时间或股票代码进行分区。
PostgreSQL更适合用宽表模式存储日线等低频数据,并结合TimescaleDB或原生分区表来管理数据。
2. 独立性安排
所有日线数据都在 quotes_daily 这一张表里,通过 symbol_id 和 trade_date 来定位数据。
优点:
查询方便:轻松实现“查询所有A股2023年市盈率低于10的股票”这样的复杂筛选,如果分表,这种查询将是噩梦。
维护简单:备份、索引、Vacuum等操作只需要对一张表进行。
关系清晰:易于与基本面等其他表进行关联查询(JOIN)。
三、Redis (用于实时缓存和状态)
策略:Key-Value设计,Key中包含股票代码 —— 这是一种逻辑上的“分表”。
Redis是键值数据库,它的“表”就是Key。我们通过精心设计Key的名称来实现逻辑隔离。
-
“表”结构设计
最新行情(Hash):
Key: quote:{symbol} 如 quote:600000.SH
Value: { price: 10.50, open: 10.30, high: 10.60, volume: 12345678, ts: 1685437200000 }订单簿(Sorted Set 或 Hash):
Key: orderbook:{symbol} 如 orderbook:600000.SH
Value: { bids: '[[10.49, 1000], [10.48, 500]]', asks: '[[10.51, 2000]]' } (可以用JSON字符串存储)集合(Set):
Key: industry:banks (存储所有银行股的代码)
Members: -
独立性安排
每支股票的数据在逻辑上都是独立的,通过Key中的{symbol}来区分。
优点:
极致性能:读取quote:600000.SH就像直接访问内存中的一个变量,速度极快。
清晰明了:Key的设计模式使得数据管理非常直观。
四、MySQL/MariaDB (用于元数据)
策略:经典的关联表设计 —— 全部是关系表,不分表。
这里存储的是高度结构化的关系数据,完全遵循数据库范式设计。
独立性安排
所有同类数据存于一张表。例如,所有股票代码都在 symbols 表里。
优点:
数据一致性:避免重复,易于管理。
强大的查询能力:可以轻松执行复杂的关联查询
行动指南
在NAS的Docker上部署TDengine
TDengine文档:https://docs.taosdata.com/2.6/
从 3.3.7.0 版本开始,TDengine TSDB 的镜像名称调整如下:
社区版的镜像名称从 tdengine/tdengine 重命名为 tdengine/tsdb
企业版的镜像名称从 tdengine/tdengine-ee 重命名为 tdengine/tsdb-ee
Docker布署:https://docs.taosdata.com/get-started/docker/
我实际的YAML文件:
version: '3.8'
services:
tdengine:
image: docker.1ms.run/tdengine/tdengine:latest
container_name: tdengine
restart: always # 容器故障或NAS重启时自动恢复
environment:
- TAOS_FQDN=tdengine # 容器内部主机名
- TAOS_PASSWORD=password # 设置强密码,但这个密码好像没卵用
- TAOS_PORT=6030 # 客户端连接端口
ports:
- "6030:6030" # 客户端连接端口
- "6041:6041" # REST API端口
- "6042:6042" # 其他服务端口
- "6043-6049:6043-6049" # 预留端口范围
- "6041-6049:6041-6049/udp" # UDP协议端口
volumes:
# 数据持久化到NAS本地目录,需提前创建
- /volume5/docker5/tdengine/data:/var/lib/taos
# 日志持久化,便于问题排查
- /volume5/docker5/tdengine/log:/var/log/taos
# 配置文件持久化(首次启动后会自动生成配置)
- /volume5/docker5/tdengine/config:/etc/taos
healthcheck:
# 健康检查,确保服务正常运行
test: ["CMD", "taos", "-s", "show databases;"]
interval: 30s
timeout: 10s
retries: 3
好了,具体的命令,参考:https://docs.taosdata.com/reference/tools/taos-cli/
taos> CREATE DATABASE IF NOT EXISTS stock
> KEEP 365 -- 数据保留365天
> CACHE 16 -- 缓存大小16MB
> UPDATE 1 -- 允许数据更新
> CHARSET UTF8; -- 支持中文(与其他参数同属CREATE语句的一部分)
>
>
> show databases;
Create OK, 0 row(s) affected (0.004209s)
DB error: Incomplete SQL statement [0x80002601] (0.000281s)
taos> show databases;
name |
=================================
information_schema |
performance_schema |
stock |
log |
Query OK, 4 row(s) in set (0.006709s)
taos> exit
按照上述设计,首先创建 symbols 等元数据表。
编写数据采集程序,按照“超级表”模式将Tick数据写入TDengine,同时将最新数据写入Redis。
日线数据继续写入PostgreSQL的超表。
在您的数据管理层(适配器+工厂模式)中,封装好对不同数据库的查询逻辑,对上层应用提供统一接口。
连通性测试
john@Desktop-CLF:/$ telnet 192.168.123.104 6041
Trying 192.168.123.104...
Connected to 192.168.123.104.
Escape character is '^]'.
john@Desktop-CLF:/$ telnet 192.168.123.104 6030
Trying 192.168.123.104...
Connected to 192.168.123.104.
Escape character is '^]'.
从以上操作来看,telnet 命令的输出已经表明连接成功了:
当你执行 telnet 192.168.123.104 6041 时,显示 Connected to 192.168.123.104,说明 6041 端口已连通
执行 telnet 192.168.123.104 6030 时,同样显示 Connected to 192.168.123.104,说明 6030 端口也已连通
# 发送认证请求测试(返回 200 表示正常)6041 是 TDengine 的 REST 端口,可通过 curl 发送 HTTP 请求验证:
john@Desktop-CLF:/$ curl -u root:taosdata "http://192.168.123.104:6041/rest/sql" -d "show databases;"
{"code":0,"column_meta":[["name","VARCHAR",64]],"data":[["information_schema"],["performance_schema"],["stock"],["log"],["db"]],"rows":5}john@Desktop-CLF:/$
从 curl 命令的输出结果来看,你的 WSL 已经成功连接到 NAS 中的 TDengine 数据库了!
响应中的 "code":0 表示请求成功
返回了数据库列表(information_schema、stock、log 等),说明 TDengine 服务正常响应
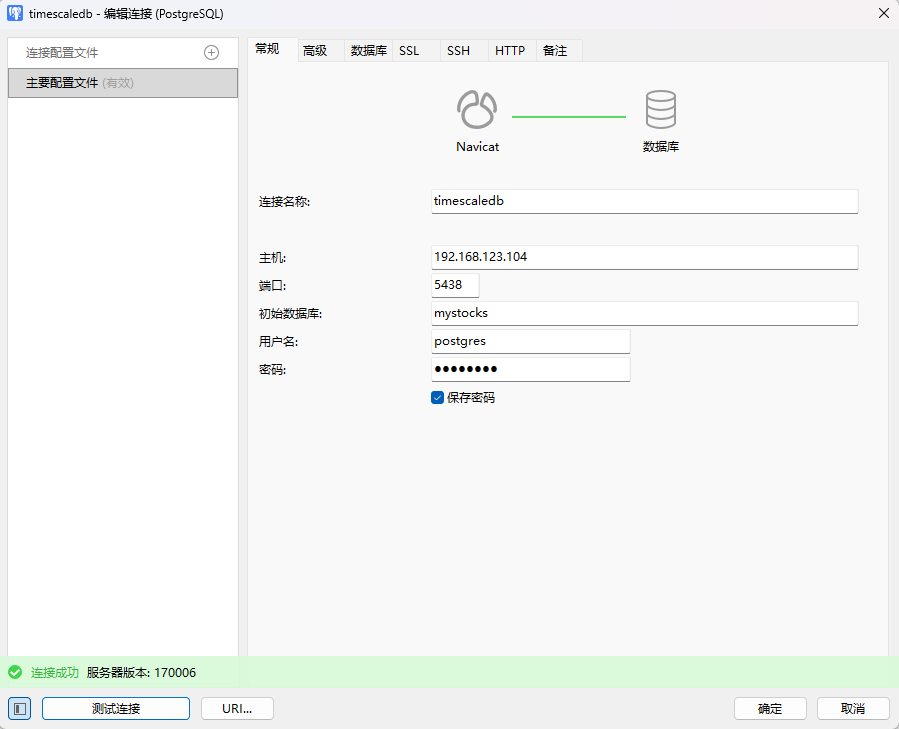
NAS布署 PostgreSQL + TimescaleDB
安装 TimescaleDB 扩展(PostgreSQL 的时序时序数据库扩展)需要根据你的操作系统和 PostgreSQL 版本进行操作。以下是Docker安装步骤:
使用官方 TimescaleDB Docker 镜像(推荐)
Timescale 提供了预安装 TimescaleDB 扩展的 PostgreSQL 镜像,直接使用即可:
- 拉取官方镜像
下载镜像
docker pull docker.1ms.run/timescale/timescaledb-ha:pg17.6-ts2.22.0-oss
启动前准备
确保宿主机端口 5433 未被占用(可通过 netstat -tulpn | grep 5433 检查)。
执行命令查看 5433 端口被哪个进程 / 容器占用:
bash
# 查看 5433 端口占用情况
sudo netstat -tulpn | grep 5433
# 或用 docker 专门查看容器端口占用
docker ps --filter "publish=5433"
#如果换了 5434 后仍提示端口占用,可继续尝试 5435、5436 等,直到找到空闲端口。也可换这个命令:
sudo netstat -tulpn | grep 543
如果输出结果显示有容器(比如你之前的 db 服务)占用 5433,就必须给新容器换一个未占用的端口。
重建数据目录权限(避免权限错误):
bash
sudo rm -rf /volume5/docker5/timescale/pgdata # 清除可能损坏的旧数据
sudo mkdir -p /volume5/docker5/timescale/pgdata
sudo chmod 700 /volume5/docker5/timescale/pgdata # PostgreSQL 要求的严格权限
点击查看YAML文件代码
version: '3.8'
services:
timescaledb:
image: docker.1ms.run/timescale/timescaledb-ha:pg17.6-ts2.22.0-oss
container_name: timescaledb-oss
restart: unless-stopped
ports:
- "5438:5432" # 已确认的未占用端口,避开冲突
volumes:
# 官网指定 PGDATA 路径,宿主机目录按实际权限调整
- /volume5/docker5/timescale/pgdata:/home/postgres/pgdata/data
- /volume5/docker5/timescale/conf:/etc/postgresql/17/main/conf.d
#######################################
# 核心修复:使用容器内默认 postgres 用户(UID 999),而非宿主机 UID
# 官网强调:TimescaleDB 镜像内 postgres 用户 UID 固定为 999,GID 固定为 999
#######################################
user: "999:999" # 容器内 postgres 用户的默认 UID/GID,无需修改
environment:
# 官网必填初始化配置
POSTGRES_DB: mystocks
POSTGRES_USER: postgres
POSTGRES_PASSWORD: password #自己设置
PGDATA: /home/postgres/pgdata/data # 严格对齐官网 PGDATA 路径
# 官网单节点与扩展配置
PATRONI_MODE: "standalone"
PATRONI_SCOPE: "timescale-single-node"
TIMESCALEDB_TELEMETRY: "off"
POSTGRES_MULTIPLE_DATABASES: "mystocks"
TIMESCALEDB_EXTENSION_CREATE_IF_NOT_EXISTS: "true"
# 官网性能与时区配置
TZ: "Asia/Shanghai"
PATRONI_POSTGRESQL_PARAMETERS: |
shared_buffers = 512MB
work_mem = 32MB
max_connections = 100
log_directory = '/home/postgres/pgdata/data/logs'
# 官网标准健康检查
healthcheck:
test: ["CMD-SHELL", "pg_isready -U ${POSTGRES_USER} -d ${POSTGRES_DB} -h 127.0.0.1 -p 5432"]
interval: 10s
timeout: 5s
retries: 5
start_period: 60s # 适配 PostgreSQL 17 初始化耗时
networks:
default:
driver: bridge
验证安装
进入容器并连接 PostgreSQL:
bash
# 进入容器
docker exec -it timescaledb psql -U postgres -d your_db
# 在 PostgreSQL 终端中验证
CREATE EXTENSION IF NOT EXISTS timescaledb;
SELECT timescaledb_version(); # 输出版本号即成功
请分析一下这两个版本的差异:基于 PostgreSQL 17 的最新版本是 timescale/timescaledb-ha:pg17,轻量级的 TimescaleDB 非 HA Docker 镜像使用 Alpine。基于 PostgreSQL 17 的最新版本是 timescale/timescaledb:latest-pg17。
timescale/timescaledb-ha:pg17 和 timescale/timescaledb:latest-pg17 都是基于 PostgreSQL 17 的 TimescaleDB 镜像,但针对不同场景设计,核心差异体现在高可用性(HA)支持、底层系统和功能定位上。以下是具体分析:
-
高可用性(HA)支持
timescale/timescaledb-ha:pg17
专为高可用集群设计,内置 HA 所需的组件和配置(如 Patroni、etcd 等)。
支持自动故障转移、主从复制、集群状态管理,适合生产环境中对可用性要求高的场景(如金融、工业监控等)。
可直接用于搭建多节点集群,无需手动配置 replication 或故障转移逻辑。
timescale/timescaledb:latest-pg17
是单节点轻量镜像,不包含 HA 组件,仅集成了 TimescaleDB 扩展的基础功能。
适合开发、测试环境,或对可用性要求不高的单节点生产场景(如小型应用、个人项目)。 -
底层系统与镜像大小
timescale/timescaledb-ha:pg17
基于Debian/Ubuntu系统构建(非 Alpine),包含更多系统工具和依赖(如集群管理工具、监控组件等)。
镜像体积较大(通常数百 MB),因为需要容纳 HA 相关的额外软件。
timescale/timescaledb:latest-pg17
基于Alpine Linux构建(轻量级 Linux 发行版),仅包含运行 TimescaleDB 必需的组件。
镜像体积更小(通常几十 MB),启动速度更快,适合资源受限的环境或追求轻量化部署的场景。 -
功能与工具集成
timescale/timescaledb-ha:pg17
集成了 HA 集群管理工具(如 Patroni 用于自动切换,etcd 用于分布式配置存储)。
包含监控和运维相关工具(如 Prometheus exporters、日志收集组件),方便集群状态监控。
预设了针对集群优化的 PostgreSQL 配置(如连接池、复制参数等)。
timescale/timescaledb:latest-pg17
仅包含 PostgreSQL 17 核心和 TimescaleDB 扩展,无额外集群工具。
配置更精简,适合自定义调整参数,或作为基础镜像二次构建。 -
适用场景
镜像 适用场景 优势 劣势
timescale/timescaledb-ha:pg17 生产环境、多节点集群、高可用性需求 内置 HA 功能、适合大规模部署、运维工具齐全 体积大、资源消耗高、配置复杂
timescale/timescaledb:latest-pg17 开发 / 测试、单节点部署、轻量应用 体积小、启动快、配置简单 无 HA 支持、需手动搭建集群
总结建议
若需要在生产环境中保证服务不中断(如避免单点故障),选择 timescale/timescaledb-ha:pg17,并配合官方文档搭建集群。
若用于本地开发、测试,或部署单节点服务,timescale/timescaledb:latest-pg17 更轻便高效。
两者均支持 TimescaleDB 的核心功能(如超表、时序数据优化等),差异主要体现在集群可用性和部署复杂度上。
timescale/timescaledb-ha 镜像的这些版本差异主要体现在 包含的组件功能 和 是否包含商业特性 上。以下是具体解析:
版本命名规则
先理解版本号的构成:pg<PostgreSQL版本>-ts<TimescaleDB版本>-[all]-[oss]
pg17.6:基于 PostgreSQL 17.6
ts2.22.0:集成 TimescaleDB 2.22.0 扩展
后缀 all/oss 表示功能范围差异
各版本区别
版本 核心差异 适用场景
pg17.6-ts2.22.0 基础高可用版本,包含 TimescaleDB 社区版核心功能 + HA 组件(Patroni、etcd 等),但不含额外工具链。 仅需基础 HA 集群功能,不需要监控、备份等附加工具的场景。
pg17.6-ts2.22.0-all 在基础版之上,额外集成了 完整工具链,包括:
- 监控工具(Prometheus exporter、Grafana 配置)
- 备份工具(pgBackRest)
- 日志管理(Vector)
- 集群管理辅助脚本。 生产环境中需要一站式 HA 解决方案,包含监控、备份等运维功能的场景。
pg17.6-ts2.22.0-oss 仅包含 开源(Open Source)组件,不含任何 Timescale 商业特性(如 Timescale Cloud 集成、企业级支持工具等),HA 功能基于纯开源软件实现。 对开源合规性要求严格,不希望引入任何商业闭源组件的场景。
pg17.6-ts2.22.0-all-oss 集成完整工具链(同 all 版本),但 仅包含开源组件,不含商业特性。 需要完整运维工具链,同时要求纯开源合规的生产环境。
关键区别点总结
all 后缀:是否包含完整运维工具链(监控、备份、日志等)。
带 all:工具齐全,开箱即用,适合生产环境。
不带 all:仅基础 HA 功能,工具需自行部署。
oss 后缀:是否限制为纯开源组件。
带 oss:仅包含开源许可的功能,无商业特性(如 Timescale 企业级插件)。
不带 oss:可能包含 Timescale 商业特性(需注意许可条款)。
选择建议
生产环境优先选 all 版本(如 pg17.6-ts2.22.0-all),工具链齐全,减少运维成本。
若有开源合规要求(如禁止使用非开源组件),选 all-oss 版本。
仅做测试或自定义工具链时,可选基础版(不带 all)。
注意:商业特性的使用可能受许可限制,生产环境使用前建议查阅 Timescale 官方许可说明。
如果你不需要搭建多节点 HA 集群,也不开启 TimescaleDB 遥测和执行定期备份时序数据,那么可以考虑选择非 HA 版本的 TimescaleDB 镜像,这样可以避免一些不必要的组件和功能,从而减小镜像体积。
在 TimescaleDB 的镜像版本中,带有 “-all” 后缀的版本通常包含了所有的组件和依赖项,包括 HA 相关的组件,所以体积会比较大。而 “-oss” 后缀的版本是开源社区版,不包含一些商业功能和 HA 组件,可能更适合你的需求。
NAS布署Redis数据库
services:
redis:
image: docker.1ms.run/redis:latest
restart: unless-stopped
volumes:
- /volume5/docker5/Redis:/data
ports:
- "6379:6379"
networks:
- paperless-shared-network # 加入paperless网络, 各位可以忽略我这一句
- mystocks-network # 加入mystocks网络
command: redis-server --appendonly yes
networks:
# 关键修改:Redis负责创建该网络(不再标记为external)
paperless-shared-network:
driver: bridge # 由Redis初始化网络,确保始终存在
mystocks-network:
driver: bridge
Grafana实现TDEngine完整的监控功能(尚未尝试)
TDengine 能够与开源数据可视化系统 Grafana 快速集成搭建数据监测报警系统,整个过程无需任何代码开发,TDengine 中数据表的内容可以在仪表盘(DashBoard)上进行可视化展现。
完整的监控功能需要安装并运行 taoskeeper 服务。taoskeeper 负责接收监控指标数据并创建 log 库。
TDEngine安装配置参考链接:https://blog.csdn.net/weixin_44462773/article/details/130999428
grafana创建面板链接:https://docs.taosdata.com/third-party/grafana/
https://docs.taosdata.com/third-party/visual/grafana/#安装-grafana-plugin-并配置数据源
https://docs.taosdata.com/operation/monitor/#tdinsight---使用监控数据库--grafana-对-tdengine-进行监控的解决方案?login=from_csdn
在WSL中安装DBeaverCE
https://dbeaver.io/download/
所说还有另外一种方案:https://docs.taosdata.com/reference/explorer/
我选择安装WSL版本,如下:
#安装dbeaver-ce
sudo snap install dbeaver-ce
(base) root@Desktop-CLF:~# sudo snap list | grep dbeaver-ce
dbeaver-ce 25.2.0.202508311659 400 latest/stable dbeaver-corp -
#运行
dbeaver-ce
安装完成后,可参考官方DBeaver连接的指南(但实际上没参考它):https://docs.taosdata.com/third-party/tool/dbeaver/
配置 TDengine 连接,填入主机地址、端口号、用户名和密码。如果 TDengine 部署在本机,可以只填用户名和密码,默认用户名为 root,默认密码为 taosdata。
注意:这里没有连SSH

建表程序(init_db_monitor.py)
import sqlalchemy
from sqlalchemy import text
from sqlalchemy.exc import SQLAlchemyError
import logging
import argparse
import os
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
def load_env_config(env_file='env'):
"""从环境变量文件加载配置"""
config = {}
try:
# 检查文件是否存在
if not os.path.exists(env_file):
raise FileNotFoundError(f"环境变量文件 '{env_file}' 不存在")
# 读取文件内容
with open(env_file, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
# 跳过注释和空行
if not line or line.startswith('#'):
continue
# 解析键值对
if '=' in line:
key, value = line.split('=', 1)
config[key.strip()] = value.strip()
# 验证必要的配置项
required_keys = ['MYSQL_HOST', 'MYSQL_USER', 'MYSQL_PASSWORD', 'MYSQL_PORT']
for key in required_keys:
if key not in config:
raise ValueError(f"环境变量文件缺少必要配置: {key}")
return {
'user': config['MYSQL_USER'],
'password': config['MYSQL_PASSWORD'],
'host': config['MYSQL_HOST'],
'port': int(config['MYSQL_PORT']),
'database': 'mysql', # 初始连接使用的数据库
'charset': 'utf8mb4',
'collation': 'utf8mb4_unicode_ci'
}
except Exception as e:
logger.error(f"加载配置失败: {str(e)}")
raise
def get_sql_commands(drop_existing=False, charset='utf8mb4', collation='utf8mb4_unicode_ci'):
"""生成SQL命令,支持删除已有表选项"""
drop_commands = ""
if drop_existing:
drop_commands = """
DROP TABLE IF EXISTS table_validation_log;
DROP TABLE IF EXISTS table_operation_log;
DROP TABLE IF EXISTS column_definition_log;
DROP TABLE IF EXISTS table_creation_log;
"""
return f"""
CREATE DATABASE IF NOT EXISTS db_monitor
CHARACTER SET {charset}
COLLATE {collation};
USE db_monitor;
{drop_commands}
CREATE TABLE table_creation_log (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '自增主键',
table_name VARCHAR(255) NOT NULL COMMENT '表名',
database_type ENUM('TDengine', 'PostgreSQL', 'Redis', 'MySQL', 'MariaDB') NOT NULL COMMENT '数据库类型',
database_name VARCHAR(255) NOT NULL COMMENT '数据库名称',
creation_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
modification_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
status ENUM('success', 'failed') NOT NULL COMMENT '创建状态',
table_parameters JSON NOT NULL COMMENT '表参数配置(JSON格式)',
ddl_command TEXT NOT NULL COMMENT '执行的DDL命令',
error_message TEXT COMMENT '错误信息(如有)',
INDEX idx_database_type (database_type),
INDEX idx_creation_time (creation_time)
) ENGINE=InnoDB DEFAULT CHARSET={charset} COMMENT='表创建日志表';
CREATE TABLE column_definition_log (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '自增主键',
table_log_id INT NOT NULL COMMENT '关联的表创建日志ID',
column_name VARCHAR(255) NOT NULL COMMENT '列名',
data_type VARCHAR(100) NOT NULL COMMENT '数据类型',
col_length INT COMMENT '列长度',
col_precision INT COMMENT '精度',
col_scale INT COMMENT '小数位数',
is_nullable BOOLEAN DEFAULT TRUE COMMENT '是否允许为空',
is_primary_key BOOLEAN DEFAULT FALSE COMMENT '是否为主键',
default_value VARCHAR(255) COMMENT '默认值',
comment TEXT COMMENT '列备注',
FOREIGN KEY (table_log_id) REFERENCES table_creation_log(id) ON DELETE CASCADE,
INDEX idx_table_log_id (table_log_id)
) ENGINE=InnoDB DEFAULT CHARSET={charset} COMMENT='列定义日志表';
-- 新增表操作日志表
CREATE TABLE table_operation_log (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '自增主键',
table_name VARCHAR(255) NOT NULL COMMENT '表名',
database_type ENUM('TDengine', 'PostgreSQL', 'Redis', 'MySQL', 'MariaDB') NOT NULL COMMENT '数据库类型',
database_name VARCHAR(255) NOT NULL COMMENT '数据库名称',
operation_type ENUM('CREATE', 'ALTER', 'DROP', 'VALIDATE') NOT NULL COMMENT '操作类型',
operation_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '操作时间',
operation_status ENUM('success', 'failed') NOT NULL COMMENT '操作状态',
operation_details JSON NOT NULL COMMENT '操作详情(JSON格式)',
ddl_command TEXT COMMENT '执行的DDL命令',
error_message TEXT COMMENT '错误信息(如有)',
INDEX idx_operation_time (operation_time),
INDEX idx_operation_type (operation_type)
) ENGINE=InnoDB DEFAULT CHARSET={charset} COMMENT='表操作日志表';
-- 新增表结构验证日志表
CREATE TABLE table_validation_log (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '自增主键',
table_name VARCHAR(255) NOT NULL COMMENT '表名',
database_type ENUM('TDengine', 'PostgreSQL', 'Redis', 'MySQL', 'MariaDB') NOT NULL COMMENT '数据库类型',
database_name VARCHAR(255) NOT NULL COMMENT '数据库名称',
validation_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '验证时间',
validation_status ENUM('pass', 'fail') NOT NULL COMMENT '验证状态',
validation_details JSON NOT NULL COMMENT '验证详情(JSON格式)',
issues_found TEXT COMMENT '发现的问题',
INDEX idx_validation_time (validation_time)
) ENGINE=InnoDB DEFAULT CHARSET={charset} COMMENT='表结构验证日志表';
"""
def create_database_and_tables(drop_existing=False):
try:
# 从env文件加载配置
db_config = load_env_config()
# 创建数据库连接字符串
connection_str = (
f"mysql+pymysql://{db_config['user']}:{db_config['password']}@"
f"{db_config['host']}:{db_config['port']}/{db_config['database']}?"
f"charset={db_config['charset']}"
)
# 建立数据库连接
engine = sqlalchemy.create_engine(connection_str)
with engine.connect() as connection:
# 确保自动提交模式开启
connection = connection.execution_options(autocommit=True)
# 获取SQL命令
sql_commands = get_sql_commands(
drop_existing=drop_existing,
charset=db_config['charset'],
collation=db_config['collation']
).split(';')
# 执行SQL命令
for cmd in sql_commands:
cmd = cmd.strip()
if cmd: # 跳过空命令
logger.info(f"执行SQL命令: {cmd[:80]}...") # 只显示前80个字符
connection.execute(text(cmd))
logger.info("所有数据库和表创建成功!")
return True
except SQLAlchemyError as e:
logger.error(f"执行SQL时发生错误: {str(e)}")
return False
except Exception as e:
logger.error(f"发生意外错误: {str(e)}")
return False
if __name__ == "__main__":
# 解析命令行参数
parser = argparse.ArgumentParser(description='创建监控数据库和表结构')
parser.add_argument('--drop-existing', action='store_true',
help='删除已存在的表(如果存在)')
args = parser.parse_args()
create_database_and_tables(drop_existing=args.drop_existing)
建立建表接口
CREATE DATABASE IF NOT EXISTS db_monitor;
USE db_monitor;
CREATE TABLE table_creation_log (
id INT AUTO_INCREMENT PRIMARY KEY,
table_name VARCHAR(255) NOT NULL,
database_type ENUM('TDengine', 'PostgreSQL', 'Redis', 'MySQL', 'MariaDB') NOT NULL,
database_name VARCHAR(255) NOT NULL,
creation_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
modification_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
status ENUM('success', 'failed') NOT NULL,
table_parameters JSON NOT NULL,
ddl_command TEXT NOT NULL,
error_message TEXT,
INDEX idx_database_type (database_type),
INDEX idx_creation_time (creation_time)
);
CREATE TABLE column_definition_log (
id INT AUTO_INCREMENT PRIMARY KEY,
table_log_id INT NOT NULL,
column_name VARCHAR(255) NOT NULL,
data_type VARCHAR(100) NOT NULL,
col_length INT, -- 避免使用关键字 length
col_precision INT, -- 避免使用关键字 precision
col_scale INT, -- 避免使用关键字 scale
is_nullable BOOLEAN DEFAULT TRUE,
is_primary_key BOOLEAN DEFAULT FALSE,
default_value VARCHAR(255),
comment TEXT,
FOREIGN KEY (table_log_id) REFERENCES table_creation_log(id) ON DELETE CASCADE
);
-- 新增表操作日志表
CREATE TABLE table_operation_log (
id INT AUTO_INCREMENT PRIMARY KEY,
table_name VARCHAR(255) NOT NULL,
database_type ENUM('TDengine', 'PostgreSQL', 'Redis', 'MySQL', 'MariaDB') NOT NULL,
database_name VARCHAR(255) NOT NULL,
operation_type ENUM('CREATE', 'ALTER', 'DROP', 'VALIDATE') NOT NULL,
operation_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
operation_status ENUM('success', 'failed') NOT NULL,
operation_details JSON NOT NULL,
ddl_command TEXT,
error_message TEXT,
INDEX idx_operation_time (operation_time),
INDEX idx_operation_type (operation_type)
);
-- 新增表结构验证日志表
CREATE TABLE table_validation_log (
id INT AUTO_INCREMENT PRIMARY KEY,
table_name VARCHAR(255) NOT NULL,
database_type ENUM('TDengine', 'PostgreSQL', 'Redis', 'MySQL', 'MariaDB') NOT NULL,
database_name VARCHAR(255) NOT NULL,
validation_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
validation_status ENUM('pass', 'fail') NOT NULL,
validation_details JSON NOT NULL,
issues_found TEXT,
INDEX idx_validation_time (validation_time)
);
增强的python监控数据库实现代码:
点击查看代码
import json
import logging
import os
from datetime import datetime
from enum import Enum
from typing import Dict, List, Any, Optional, Tuple
import sqlalchemy as sa
from sqlalchemy import create_engine, Column, Integer, String, DateTime, Text, JSON, Boolean, Enum as SQLEnum
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, relationship
import psycopg2
import taos
import redis
import pymysql
from dotenv import load_dotenv
import yaml
# 加载环境变量
load_dotenv()
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("DatabaseTableManager")
# 从环境变量获取监控数据库连接
MONITOR_DB_URL = os.getenv("MONITOR_DB_URL", "mysql+pymysql://user:password@localhost/db_monitor")
Base = declarative_base()
class DatabaseType(Enum):
TDENGINE = "TDengine"
POSTGRESQL = "PostgreSQL"
REDIS = "Redis"
MYSQL = "MySQL"
MARIADB = "MariaDB"
# ORM模型
class TableCreationLog(Base):
__tablename__ = 'table_creation_log'
id = Column(Integer, primary_key=True)
table_name = Column(String(255), nullable=False)
database_type = Column(String(20), nullable=False)
database_name = Column(String(255), nullable=False)
creation_time = Column(DateTime, default=datetime.utcnow)
modification_time = Column(DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
status = Column(String(10), nullable=False)
table_parameters = Column(JSON, nullable=False)
ddl_command = Column(Text, nullable=False)
error_message = Column(Text)
# 关系
columns = relationship("ColumnDefinitionLog", backref="table_log", cascade="all, delete-orphan")
class ColumnDefinitionLog(Base):
__tablename__ = 'column_definition_log'
id = Column(Integer, primary_key=True)
table_log_id = Column(Integer, sa.ForeignKey('table_creation_log.id'))
column_name = Column(String(255), nullable=False)
data_type = Column(String(100), nullable=False)
col_length = Column(Integer) # 避免使用关键字 length
col_precision = Column(Integer) # 避免使用关键字 precision
col_scale = Column(Integer) # 避免使用关键字 scale
is_nullable = Column(Boolean, default=True)
is_primary_key = Column(Boolean, default=False)
default_value = Column(String(255))
comment = Column(Text)
class TableOperationLog(Base):
__tablename__ = 'table_operation_log'
id = Column(Integer, primary_key=True)
table_name = Column(String(255), nullable=False)
database_type = Column(String(20), nullable=False)
database_name = Column(String(255), nullable=False)
operation_type = Column(SQLEnum('CREATE', 'ALTER', 'DROP', 'VALIDATE'), nullable=False)
operation_time = Column(DateTime, default=datetime.utcnow)
operation_status = Column(String(10), nullable=False)
operation_details = Column(JSON, nullable=False)
ddl_command = Column(Text)
error_message = Column(Text)
class TableValidationLog(Base):
__tablename__ = 'table_validation_log'
id = Column(Integer, primary_key=True)
table_name = Column(String(255), nullable=False)
database_type = Column(String(20), nullable=False)
database_name = Column(String(255), nullable=False)
validation_time = Column(DateTime, default=datetime.utcnow)
validation_status = Column(String(10), nullable=False)
validation_details = Column(JSON, nullable=False)
issues_found = Column(Text)
class DatabaseTableManager:
def __init__(self):
# 初始化监控数据库连接
self.monitor_engine = create_engine(MONITOR_DB_URL)
Base.metadata.create_all(self.monitor_engine)
Session = sessionmaker(bind=self.monitor_engine)
self.monitor_session = Session()
# 从环境变量加载各数据库连接配置
self.db_configs = {
DatabaseType.TDENGINE: {
'host': os.getenv('TDENGINE_HOST', 'localhost'),
'user': os.getenv('TDENGINE_USER', 'root'),
'password': os.getenv('TDENGINE_PASSWORD', 'taosdata'),
'port': int(os.getenv('TDENGINE_PORT', '6030'))
},
DatabaseType.POSTGRESQL: {
'host': os.getenv('POSTGRESQL_HOST', 'localhost'),
'user': os.getenv('POSTGRESQL_USER', 'postgres'),
'password': os.getenv('POSTGRESQL_PASSWORD', ''),
'port': int(os.getenv('POSTGRESQL_PORT', '5432'))
},
DatabaseType.REDIS: {
'host': os.getenv('REDIS_HOST', 'localhost'),
'port': int(os.getenv('REDIS_PORT', '6379')),
'password': os.getenv('REDIS_PASSWORD', None),
'db': int(os.getenv('REDIS_DB', '0'))
},
DatabaseType.MYSQL: {
'host': os.getenv('MYSQL_HOST', 'localhost'),
'user': os.getenv('MYSQL_USER', 'root'),
'password': os.getenv('MYSQL_PASSWORD', ''),
'port': int(os.getenv('MYSQL_PORT', '3306'))
},
DatabaseType.MARIADB: {
'host': os.getenv('MARIADB_HOST', 'localhost'),
'user': os.getenv('MARIADB_USER', 'root'),
'password': os.getenv('MARIADB_PASSWORD', ''),
'port': int(os.getenv('MARIADB_PORT', '3306'))
}
}
# 各数据库连接池
self.db_connections = {}
def get_connection(self, db_type: DatabaseType, db_name: str, **kwargs):
"""获取数据库连接"""
conn_key = f"{db_type.value}_{db_name}"
if conn_key in self.db_connections:
return self.db_connections[conn_key]
# 获取默认配置并更新用户提供的参数
config = self.db_configs[db_type].copy()
config.update(kwargs)
try:
if db_type == DatabaseType.TDENGINE:
# TDengine连接
conn = taos.connect(
host=config['host'],
user=config['user'],
password=config['password'],
port=config['port'],
database=db_name
)
elif db_type == DatabaseType.POSTGRESQL:
# PostgreSQL连接
conn = psycopg2.connect(
host=config['host'],
user=config['user'],
password=config['password'],
port=config['port'],
database=db_name
)
elif db_type == DatabaseType.REDIS:
# Redis连接
conn = redis.Redis(
host=config['host'],
port=config['port'],
db=config['db'],
password=config['password'],
decode_responses=True
)
elif db_type in [DatabaseType.MYSQL, DatabaseType.MARIADB]:
# MySQL/MariaDB连接
conn = pymysql.connect(
host=config['host'],
user=config['user'],
password=config['password'],
port=config['port'],
database=db_name,
charset='utf8mb4'
)
else:
raise ValueError(f"Unsupported database type: {db_type}")
self.db_connections[conn_key] = conn
return conn
except Exception as e:
logger.error(f"Failed to connect to {db_type.value} database {db_name}: {str(e)}")
raise
def _log_operation(self, table_name: str, db_type: DatabaseType, db_name: str,
operation_type: str, operation_details: Dict, ddl_command: str = "",
status: str = "success", error_message: str = ""):
"""记录操作日志到监控数据库"""
log_entry = TableOperationLog(
table_name=table_name,
database_type=db_type.value,
database_name=db_name,
operation_type=operation_type,
operation_status=status,
operation_details=operation_details,
ddl_command=ddl_command,
error_message=error_message
)
self.monitor_session.add(log_entry)
self.monitor_session.commit()
return log_entry.id
def create_table(self, db_type: DatabaseType, db_name: str, table_name: str,
columns: List[Dict], **kwargs) -> bool:
"""在指定数据库中创建表"""
# 记录开始信息到监控表
operation_id = self._log_operation(
table_name, db_type, db_name, "CREATE",
{"columns": columns, "kwargs": kwargs},
status="processing"
)
try:
# 获取数据库连接
conn = self.get_connection(db_type, db_name, **kwargs)
# 生成DDL语句
if db_type == DatabaseType.TDENGINE:
ddl = self._generate_tdengine_ddl(table_name, columns, kwargs.get('tags', []))
cursor = conn.cursor()
cursor.execute(ddl)
elif db_type == DatabaseType.POSTGRESQL:
ddl = self._generate_postgresql_ddl(table_name, columns, **kwargs)
cursor = conn.cursor()
cursor.execute(ddl)
conn.commit()
elif db_type in [DatabaseType.MYSQL, DatabaseType.MARIADB]:
ddl = self._generate_mysql_ddl(table_name, columns, **kwargs)
cursor = conn.cursor()
cursor.execute(ddl)
conn.commit()
elif db_type == DatabaseType.REDIS:
# Redis没有表结构,这里可以创建一些初始结构
ddl = f"REDIS INIT for {table_name}"
self._initialize_redis_structure(conn, table_name, columns)
else:
raise ValueError(f"Unsupported database type: {db_type}")
# 记录表创建日志
log_entry = TableCreationLog(
table_name=table_name,
database_type=db_type.value,
database_name=db_name,
status='success',
table_parameters=json.dumps({"columns": columns, "kwargs": kwargs}),
ddl_command=ddl
)
self.monitor_session.add(log_entry)
self.monitor_session.flush() # 获取ID但不提交
# 记录列定义
for col_def in columns:
col_log = ColumnDefinitionLog(
table_log_id=log_entry.id,
column_name=col_def['name'],
data_type=col_def['type'],
col_length=col_def.get('length'),
col_precision=col_def.get('precision'),
col_scale=col_def.get('scale'),
is_nullable=col_def.get('nullable', True),
is_primary_key=col_def.get('primary_key', False),
default_value=col_def.get('default'),
comment=col_def.get('comment')
)
self.monitor_session.add(col_log)
# 提交所有更改
self.monitor_session.commit()
# 更新操作日志
self._log_operation(
table_name, db_type, db_name, "CREATE",
{"columns": columns, "kwargs": kwargs}, ddl, "success"
)
# 验证表结构
self.validate_table_structure(db_type, db_name, table_name, columns)
return True
except Exception as e:
# 记录错误信息
error_msg = str(e)
logger.error(f"Failed to create table {table_name}: {error_msg}")
# 更新操作日志
self._log_operation(
table_name, db_type, db_name, "CREATE",
{"columns": columns, "kwargs": kwargs}, "", "failed", error_msg
)
self.monitor_session.rollback()
return False
def alter_table(self, db_type: DatabaseType, db_name: str, table_name: str,
alterations: List[Dict], **kwargs) -> bool:
"""修改表结构"""
# 记录开始信息
operation_id = self._log_operation(
table_name, db_type, db_name, "ALTER",
{"alterations": alterations, "kwargs": kwargs},
status="processing"
)
try:
conn = self.get_connection(db_type, db_name, **kwargs)
cursor = conn.cursor()
# 生成ALTER语句
ddl = self._generate_alter_ddl(db_type, table_name, alterations)
# 执行ALTER语句
cursor.execute(ddl)
if db_type != DatabaseType.REDIS: # Redis不需要commit
conn.commit()
# 更新操作日志
self._log_operation(
table_name, db_type, db_name, "ALTER",
{"alterations": alterations, "kwargs": kwargs}, ddl, "success"
)
# 更新表创建日志中的修改时间
table_log = self.monitor_session.query(TableCreationLog).filter_by(
table_name=table_name,
database_type=db_type.value,
database_name=db_name
).first()
if table_log:
table_log.modification_time = datetime.utcnow()
self.monitor_session.commit()
return True
except Exception as e:
error_msg = str(e)
logger.error(f"Failed to alter table {table_name}: {error_msg}")
self._log_operation(
table_name, db_type, db_name, "ALTER",
{"alterations": alterations, "kwargs": kwargs}, "", "failed", error_msg
)
return False
def drop_table(self, db_type: DatabaseType, db_name: str, table_name: str, **kwargs) -> bool:
"""删除表"""
# 记录开始信息
operation_id = self._log_operation(
table_name, db_type, db_name, "DROP",
{"kwargs": kwargs},
status="processing"
)
try:
conn = self.get_connection(db_type, db_name, **kwargs)
cursor = conn.cursor()
# 生成DROP语句
if db_type == DatabaseType.TDENGINE:
ddl = f"DROP TABLE IF EXISTS {table_name}"
elif db_type == DatabaseType.POSTGRESQL:
ddl = f"DROP TABLE IF EXISTS {table_name} CASCADE"
elif db_type in [DatabaseType.MYSQL, DatabaseType.MARIADB]:
ddl = f"DROP TABLE IF EXISTS {table_name}"
elif db_type == DatabaseType.REDIS:
# Redis没有表的概念,删除相关的所有键
ddl = f"Redis keys deletion for pattern: {table_name}:*"
keys = conn.keys(f"{table_name}:*")
if keys:
conn.delete(*keys)
else:
raise ValueError(f"Unsupported database type: {db_type}")
# 执行DROP语句(Redis除外)
if db_type != DatabaseType.REDIS:
cursor.execute(ddl)
conn.commit()
# 更新操作日志
self._log_operation(
table_name, db_type, db_name, "DROP",
{"kwargs": kwargs}, ddl, "success"
)
# 从监控表中删除相关记录
table_log = self.monitor_session.query(TableCreationLog).filter_by(
table_name=table_name,
database_type=db_type.value,
database_name=db_name
).first()
if table_log:
# 删除相关的列定义记录(由于外键约束,会级联删除)
self.monitor_session.delete(table_log)
self.monitor_session.commit()
return True
except Exception as e:
error_msg = str(e)
logger.error(f"Failed to drop table {table_name}: {error_msg}")
self._log_operation(
table_name, db_type, db_name, "DROP",
{"kwargs": kwargs}, "", "failed", error_msg
)
return False
def validate_table_structure(self, db_type: DatabaseType, db_name: str,
table_name: str, expected_columns: List[Dict], **kwargs) -> Dict:
"""验证表结构是否符合预期"""
validation_details = {
"expected_columns": expected_columns,
"actual_columns": [],
"matches": False,
"issues": []
}
try:
# 获取实际表结构
actual_structure = self.get_table_info(db_type, db_name, table_name, **kwargs)
if not actual_structure:
validation_details["issues"].append("Table does not exist or cannot be accessed")
validation_status = "fail"
else:
validation_details["actual_columns"] = actual_structure.get("columns", [])
# 验证列匹配
expected_cols = {col["name"]: col for col in expected_columns}
actual_cols = {col["name"]: col for col in actual_structure.get("columns", [])}
# 检查缺失的列
for col_name in expected_cols:
if col_name not in actual_cols:
validation_details["issues"].append(f"Missing column: {col_name}")
# 检查多余的列
for col_name in actual_cols:
if col_name not in expected_cols:
validation_details["issues"].append(f"Extra column: {col_name}")
# 检查列属性
for col_name in expected_cols:
if col_name in actual_cols:
expected = expected_cols[col_name]
actual = actual_cols[col_name]
# 检查数据类型
if expected.get("type") and actual.get("type"):
if expected["type"].lower() != actual["type"].lower():
validation_details["issues"].append(
f"Column {col_name} type mismatch: expected {expected['type']}, got {actual['type']}"
)
# 检查是否允许为空
if "nullable" in expected and "nullable" in actual:
if expected["nullable"] != actual["nullable"]:
validation_details["issues"].append(
f"Column {col_name} nullable mismatch: expected {expected['nullable']}, got {actual['nullable']}"
)
# 确定验证状态
validation_details["matches"] = len(validation_details["issues"]) == 0
validation_status = "pass" if validation_details["matches"] else "fail"
except Exception as e:
error_msg = str(e)
logger.error(f"Failed to validate table {table_name}: {error_msg}")
validation_details["issues"].append(f"Validation error: {error_msg}")
validation_status = "fail"
# 记录验证结果
validation_log = TableValidationLog(
table_name=table_name,
database_type=db_type.value,
database_name=db_name,
validation_status=validation_status,
validation_details=validation_details,
issues_found="; ".join(validation_details["issues"]) if validation_details["issues"] else None
)
self.monitor_session.add(validation_log)
self.monitor_session.commit()
return validation_details
def batch_create_tables(self, config_file: str):
"""通过配置文件批量创建表"""
try:
with open(config_file, 'r') as f:
config = yaml.safe_load(f)
results = {}
for table_config in config.get('tables', []):
db_type = DatabaseType[table_config['database_type'].upper()]
db_name = table_config['database_name']
table_name = table_config['table_name']
columns = table_config['columns']
kwargs = table_config.get('kwargs', {})
result = self.create_table(db_type, db_name, table_name, columns, **kwargs)
results[table_name] = result
return results
except Exception as e:
logger.error(f"Failed to batch create tables: {str(e)}")
return {"error": str(e)}
def _generate_alter_ddl(self, db_type: DatabaseType, table_name: str, alterations: List[Dict]) -> str:
"""生成ALTER TABLE语句"""
ddl_parts = []
for alteration in alterations:
operation = alteration.get('operation') # ADD, DROP, MODIFY, RENAME
if operation == 'ADD':
col_def = self._generate_column_definition(alteration)
ddl_parts.append(f"ADD COLUMN {col_def}")
elif operation == 'DROP':
ddl_parts.append(f"DROP COLUMN {alteration['column_name']}")
elif operation == 'MODIFY':
col_def = self._generate_column_definition(alteration)
ddl_parts.append(f"MODIFY COLUMN {col_def}")
elif operation == 'RENAME':
ddl_parts.append(f"RENAME COLUMN {alteration['old_name']} TO {alteration['new_name']}")
return f"ALTER TABLE {table_name} {', '.join(ddl_parts)}"
def _generate_column_definition(self, col_def: Dict) -> str:
"""生成列定义字符串"""
definition = f"{col_def['name']} {col_def['type']}"
# 处理长度/精度
if col_def.get('length') and col_def['type'].lower() in ['varchar', 'char']:
definition += f"({col_def['length']})"
elif col_def.get('precision') and col_def['type'].lower() in ['numeric', 'decimal']:
if col_def.get('scale'):
definition += f"({col_def['precision']}, {col_def['scale']})"
else:
definition += f"({col_def['precision']})"
# 处理约束
if not col_def.get('nullable', True):
definition += " NOT NULL"
if col_def.get('default') is not None:
definition += f" DEFAULT {col_def['default']}"
if col_def.get('comment'):
definition += f" COMMENT '{col_def['comment']}'"
return definition
# 其他方法 (_generate_tdengine_ddl, _generate_postgresql_ddl, _generate_mysql_ddl,
# _initialize_redis_structure, get_table_info, close_all_connections) 保持不变
# 但需要更新以使用新的列名 (col_length, col_precision, col_scale)
# 使用示例
if __name__ == "__main__":
manager = DatabaseTableManager()
# 批量创建表示例
results = manager.batch_create_tables("tables_config.yaml")
print("Batch create results:", results)
# 修改表示例
alterations = [
{
"operation": "ADD",
"name": "new_column",
"type": "VARCHAR",
"length": 100,
"nullable": True,
"comment": "New column added by alter operation"
}
]
success = manager.alter_table(
DatabaseType.MYSQL,
'test_db',
'test_table',
alterations,
host='localhost',
user='root',
password='password'
)
print(f"Alter table {'成功' if success else '失败'}")
# 删除表示例
success = manager.drop_table(
DatabaseType.MYSQL,
'test_db',
'test_table',
host='localhost',
user='root',
password='password'
)
print(f"Drop table {'成功' if success else '失败'}")
manager.close_all_connections()
python连接TDengine
参考:https://docs.taosdata.com/2.6/develop/connect/
先下载这个:https://www.taosdata.com/assets-download/3.0/TDengine-client-3.3.6.13-Windows-x64.exe
# 安装最新版本
pip3 install taospy
# 安装指定版本
pip3 install taospy==2.6.2
# 从 GitHub 安装
pip3 install git+https://github.com/taosdata/taos-connector-python.git
#对于 REST 连接,只需验证是否能成功导入 taosrest 模块。可在 Python 交互式 Shell 中输入:
import taosrest

参考
TDengine文档:https://docs.taosdata.com/reference/connector/java/#properties

 浙公网安备 33010602011771号
浙公网安备 33010602011771号