『论文』YOLO series(v1, v2, v3, YOLOx)
『论文』YOLO series(v1, v2, v3, YOLOx)
简要总结
回溯一下几个方法的主要contribution:
- YOLOv1:1. 开始了YOLO的检测范式(完整的grids尺寸输出 + ground truth preparation SxSx(5B+K) + nms) 2. objectness的设计
- YOLOv2:1. 使用anchor box 2. 使用FCN而不是最后flatten掉 3. 使用B(5+K) 4. 使用k-means在VOC上得到anchor预设 5. 优化regression量的小设计(输出位置offset将进入sigmoid加到anchor初始位置得到box位置预测,输出scale "offset"将作为exp的幂乘到anchor初始尺寸得到box尺寸预测)6. reorg操作稍微把多尺度特征结合了一下 7. Multi-scale training(在训练时选择多种图像尺寸进行输入)7. 使用DarkNet-19,运用了卷积三件套conv, BN和leakyrelu,加入了bn的使用
- YOLOv3:1. Logistic regression for confidence scores (objectness) 2. Multiple independent logistic classifier for each class rather than one softmax layer 3. 使用DarkNet-53,运用了residual connection 4. Multi-scale prediction,使用FPN,并在其在3个尺度上进行多级检测,最终会输出52×52×3(1+C+4)、26×26×3(1+C+4)和13×13×3(1+C+4)三个预测张量,然后将这些预测结果汇总到一起
- YOLOX:1. 基于YOLOv3-SPP,使用BCE Loss for training cls and obj branch and IoU Loss for training reg branch,以及obj应该使用的是IoU-aware分支 2. 使用decoupled head(两个不同的分支来最后输出cls和reg以及IoU-aware,而不是一个branch最后全在channel里)3. Strong data augmentation:add Mosaic and MixUp 4. simply使用anchor-free,且multi positives(simply assigns the center 3×3 area as positives)5. SimOTA for label assignment:select the top k predictions with the least cost within a fixed center region as its positive samples,对于每个gt的k是被动态决定的
YOLOv1
The YOLO model (“You Only Look Once”; Redmon et al., 2016) is the very first attempt at building a fast real-time object detector. Because YOLO does not undergo the region proposal step and only predicts over a limited nmproves the converging speedumber of bounding boxes, it is able to do inference super fast.
Ground-truth preparation
-
Split an image into S×S cells. If an object's center falls into a cell, that cell is "responsible" for detecting the existence of that object. Each cell predicts (a) the location of B bounding boxes, (b) a confidence score, and (c) a probability of object class conditioned on the existence of an object in the bounding box
-
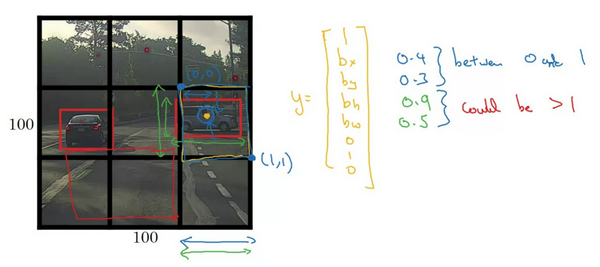
The coordinates of bounding box are defined by a tuple of 4 values, (center x-coord, center y-coord, width, height) — (x,y,w,h), where x and y are set to be offset of a cell location. Moreover, x, y, w and h are normalized by the image width and height, and thus all between (0, 1].
-
A confidence score indicates the likelihood that the cell contains an object:
Pr(containing an object) x IoU(pred, truth); where Pr = probability and IoU = interaction under union- If the cell contains an object, it predicts a probability of this object belonging to every class Ci,i=1,…,K: Pr(the object belongs to the class C_i | containing an object). At this stage, the model only predicts one set of class probabilities per cell, regardless of the number of bounding boxes, B
-
In total, one image contains S×S×B bounding boxes, each box corresponding to 4 location predictions, 1 confidence score, and K conditional probabilities for object classification. The total prediction values for one image is S×S×(5B+K), which is the tensor shape of the final conv layer of the model.
-
Note: 总的来说个人感觉:YOLO 最关键的( 也是不同于two-stage办法的地方)就是它的ground-truth设计方式。其把image分为grids,为每个grids去设计label,于是每个grid都有个5B+K的channels,使得对于一个image的label有一个非常concrete的完整的尺寸格式(S x S x (5B+K)),可以想象,那我网络输出的时候也就非常舒服,直接一趟下来得到一个这样尺寸的结果即可了。而回想R-CNN family,它们往往是生成proposals,fine-tune proposals作为最终预测,然后根据它们和ground-truth们的IoU来分配positive pairs,这是相对YOLO第一个比较割裂的地方,另外之后,得到的feature vector一个再进行fc然后softmax,一路也fc进行了offset的prediction,也没有YOLO这样这么爽,有了最终得到的prediction这个具体尺寸的东西,和ground-truth一起做文章就行了(设计loss等)。所以其实是:逐网格找东西
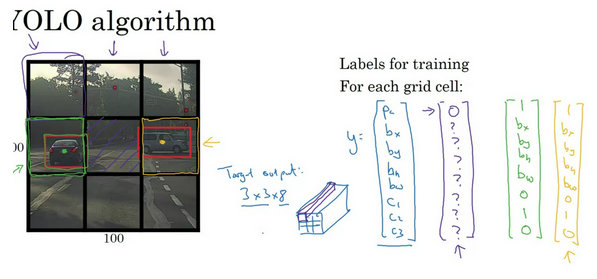
-
Note: 感觉有的地方说的是5B+K,这也是论文里的原话,不过这样设计是没有为B个bbox每一个都单独分配位置预测class probabilities,而是一个grid就一组,它们都是对应这一组关于分类的预测。个人觉得这样还是默认为了这个grid只有一个object,只是用2个bbox去都完成完成试试。有的地方则是直接说的两组独立的,那也就是(5+K),如cousera和tudelft的lecture里。个人感觉这样比较好理解,可能是后面的YOLO版本但是之后更为常用了吧
-
Note: 另一个点是bbox的位置尺寸都是相对该grid然后0到1来编码的,而不是绝对坐标。尺寸上,知乎那篇里面的说法是以image的w和h归一化了,不管了。
-
Note: 另外,个人认为有个点就是关于objectness。其在论文中还有blog里说的,是
Pr(containing an object) x IoU(pred, truth)。其想要表达的意思就是说,我存在与否以及存在的话这个bbox大概和这个object本身有多一致了。可以想象,对于ground-truth,grid里某个box这个地方肯定是1了,毕竟又存在又完美就是它,但是对于网络预测的这个单个值你当然不能说这里面有多少P_r有多少IoU,其实就是输出了这个数蕴含了这样两个大概的涵义,因为想要去接近的ground-truth这个地方是1那就是可以认为是这两个数相乘组成的,相当于一种看这个值意义的想法。所以个人认为,不去管这个IoU,直接说这个值就是代表P_r,也就是“是否有object”,ground-truth就是有或没有,网络输出的小数就是我目前多认为它有或没有。这样理解应该是完全没有问题的,而且脑子里也更简单一些。 -
Note: 是的,没错,YOLOv1就是最早的anchor-free通用检测器!
-
Note: 知乎那个blog里说的,而且我也有这样的感觉,很同意:YOLO 的精髓在一在于把背景和前景的各个类别的学习给解耦了。objectness 分支就负责学习前景和背景,本质是个二分类,作用十分相当于Faster R-CNN中 的 RPN,而类别学习只学正样本的信息,标签里也没加进去背景标签,这就等于Faster R-CNN 的第二阶段。而像SSD和RetinaNet,都是把背景作为一类标签加到了class里,把背景和前景的各个类别的学习耦合到了一块去,那自然要比YOLO学得麻烦一些。 个人感觉,这才是YOLO为什么对Focal loss不敏感的原因,因为它用objectness分支把背景和前景的各个类别的学习解耦了。class分支只需要学正样本就好了,不需要像RetinaNet那样,单独的背景要和其他一大堆前景标签一块battle,把置信度拉到自己头上。Objectness 预测分支才是YOLO的灵魂!如果没有这个分支,那和SSD、RetinaNet 也就没差别了。
Network Architecture
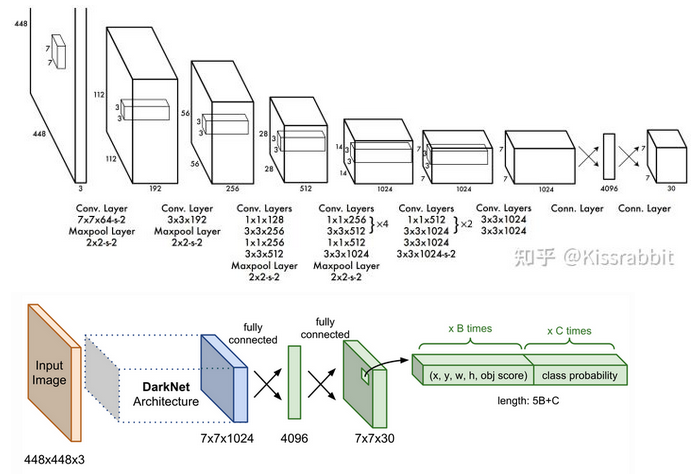
- The base model is similar to GoogLeNet with inception module replaced by 1x1 and 3x3 conv layers. The final prediction of shape S×S×(5B+K) is produced by two fully connected layers over the whole conv feature map
- Note: 这里就像前面说的,直接一通网络得到最后想要的尺寸的output就行了,所以结构本身真的简单多了。448x448的image经过了64倍的降采样至7x7。有一个点就是,可以发现最后7x7x1024到最终输出的地方是这样操作的:直接flatten,然后接fc至4096维vector(参数量:7x7x1024x4096+4096=2x10^8,所以作者实际上是先连了个256缓一缓再接的4096:7x7x1024x256+256+256x4096+4096=1.4x10^7, 稍微好一些),然后fc,然后直接reshape回想要的7x7x30。可以想象,这样过程其中的flatten破坏了空间特征信息
Loss Function
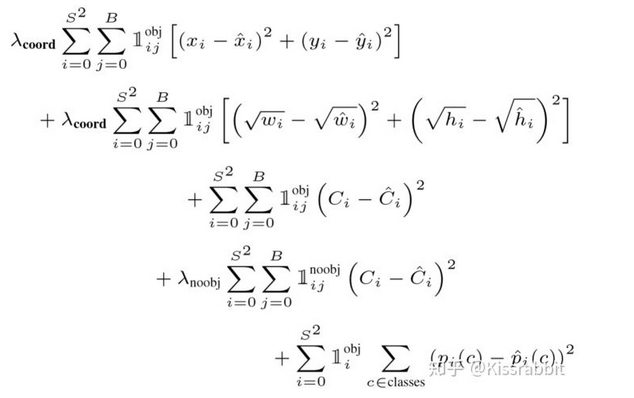
- 图中的第一行和第二行关于box的regression。注意都有indicator function,当然是只对有object的grid去regress box位置和尺寸。
- 第三行和第四行就是关于objectness的, 让有和没有object的grid里的box们的这个值都趋于它们应该的值。这里有个小细节其实是,最直观的这个C_i就是1或者0嘛,但是仔细想想对于一个grid,那目标肯定是1或者0,但是对于具体的grid里的box,有的box其实一点都不好,直接说这个box的objectness就是1其实不太合适,因为按我们之前的最根本的定义,这个objectness 其实是objectness * IoU (pred, gt),所以如果它一点都不好,这个值其实是在IoU上打折扣的,也就是说它的这个值的目标值并不拉满到1。所以实际上在训练中是:
- 计算当前该gridB个bbox与此处的真实bbox之间的IoU,得到B个IoU值,选择其中最大的IoU值来作为这个grid里box的objectness / confidence的学习目标;对于bbox的位置信息参数(即中心点和框的宽高),也只让这个IoU最大的那个bbox去反向传播。也是从知乎那个blog里看来的,个人觉得这就是一种设计方式吧。
- 第五行就是关于classification的了。从上面的loss我们发现都是用MSE来计算的,这是因为YOLO-v1关于框的五个参数和类别都是用的是线性函数(全连接层不加激活函数)来做的预测。至于在classification这里YOLOv1都没用softmax,也许是某种历史问题。
NMS

- For each class, perform NMS above for nms. (pick the highest, discard highly-overlapped ones, append that highest one to the result, and repeat)
YOLOv2 / YOLO9000
YOLOv2 (Redmon & Farhadi, 2017) is an enhanced version of YOLO. YOLO9000 is built on top of YOLOv2 but trained with joint dataset combining the COCO detection dataset and the top 9000 classes from ImageNet.
在2016年的CVPR会议上,继YOLOv1工作后,原作者再次推出YOLOv2(或YOLO9000,但我们只关注YOLOv2这一部分)。相较于上一代的YOLOv1,YOLOv2在其基础之上做了大量的改进和优化,不仅仅是对模型本身做了优化,同时还引入了由Faster R-CNN工作提出的 anchor box机制,并且使用了kmeans聚类方法来获得更好的anchor box,边界框的回归方法也因此做了调整。在VOC2007数据集上,YOLOv2超越了同年发表在ECCV会议上的SSD工作,是那个年代当之无愧的最强目标检测器之一。
A variety of modifications (could be summarized as 8 modifications) are applied to make YOLO prediction more accurate and faster, including:
BatchNorm helps

- Add batch norm on all the conv layers, leading to huge improvement over convergence
- 在YOLOv1中,每一层卷积的结构都是线性卷积和激活函数,并没有使用诸如批归一化(batch normalization,简称BN)、层归一化(layer,normalization,简称LN)、实例归一化(instance normalization,简称IN)等任何归一化层。这一点是受限于那个年代的相关技术的发展,而以现在的眼光来看,这些归一化层几乎是搭建网络的标配,尤其是在计算机视觉领域中,BN层几乎随处可见。于是,在YOLOv2中,YOLO作者为YOLOv1添加了BN层,即卷积层的组成从原先的线性卷积与激活函数的组合改进为后来常用的“卷积三件套”:线性卷积、BN层以及激活函数,如图1所示。
- 于是,YOLOv1得到了第一次性能提升,在VOC2007测试集上,从原本的63.4% mAP提升到65.8% mAP。
- Image resolution matters
- Fine-tuning the base model with high resolution images improves the detection performance
- 在YOLOv1中,其backbone先在ImageNet上进行预训练,预训练时所输入的图像尺寸是224×224,而做检测任务时,YOLOv1所接收的输入图像尺寸是448×448,不难想到,训练过程中,网络必须要先克服由分辨率尺寸的剧变所带来的问题。毕竟,backbone网络在ImageNet上看得都是224×224的低分辨率图像,突然看到448×448的高分辨率图像,难免会“眼晕”。为了缓解这一问题,作者将已经在224×224的低分辨率图像上训练好的分类网络又在448×448的高分辨率图像上进行微调,共微调10个轮次。微调完毕后,再去掉最后的全局平均池化层和softmax层,作为最终的backbone网络。
- 于是,YOLOv1网络获得了第二次性能提升:从65.8% mAP提升到69.5% mAP。
Convolutional anchor box detection
- Rather than predicts the bounding box position with fully-connected layers over the whole feature map, YOLOv2 uses convolutional layers to predict locations of anchor boxes, like in faster R-CNN. The prediction of spatial locations and class probabilities are decoupled. Overall, the change leads to a slight decrease in mAP, but an increase in recall
-
Use anchor boxes
- 所谓的anchor box,字面翻译为“锚框”。如何理解“锚框”?我们很容易会想到一艘轮船到了岸边,要抛下锚从而将船身固定住,锚框的意思便是将一堆边界框放置在特征图网格的每一处位置,通常每个位置都放置相同数量的相同尺寸的锚框。个人感觉,每组anchors就像在每个grid作为码头的锚点附近扔下的一些能够稍微晃动的框框们
- 这一机制最早是在Faster R-CNN 中提出的,用在RPN网络中,RPN 网络在这些预先放置好的锚框上去为后续的预测提供感兴趣区域(Region of Interest,RoI)。每个网格处设定了k个不同尺寸、不同宽高比的anchor box,RPN 网络会为每一个anchor box学习若干偏移量:中心点的偏移量和宽高的偏移量。用这些偏移量去调整每一个anchor box,得到最终的边界框。由此可见,anchor box的本质是提供边界框的尺寸先验,网络使用偏移量在这些先验值上进行调整,从而得到最终的尺寸,对于边界框的学习,不再是之前的“无中生有”了。因此,anchor box与其直接翻译成“锚框”,不如翻译成“先验框”更加贴切。加入先验框的目标检测网络,后来都被称为“Anchor-based”模型。
- Note: 这里这个知乎作者总结得挺精髓,也是完美符合我对Faster R-CNN 的理解。回想YOLOv1,可以想象它对于每个grid处的output预测就是去硬预测这个值的,从啥都没有直接去得到这个值。而回想Faster R-CNN 它的proposals的设计和loss都是让这个网络最后regress这个proposal / RoI 去做的offset和scale multiplication,这个设计其实真的很妙,所以YOLOv2这里也就是把这个方法给融进来了。这个作者说得挺好,现在,不再是之前的“无中生有”了。总之,先验框的作用就是提供边界框的尺寸先验信息,让网络只需学习偏移量来调整先验框去获得最终的边界框,相较于YOLOv1的直接回归边界框的宽高,基于先验框的方法表现得往往更好。
- 设计先验框的一个难点在于设计多少个先验框,且每个先验框的尺寸(宽高比和面积)又是多少。对于宽高比,研究者们通常采取的配置是1 : 1、1 : 3以及3 : 1;对于面积,常用的配置是32、64、128、256以及512。以上述两个配置为例,每一个面积都使用3个长宽比,因此,不难算出共有15个先验框,即k=15。对于一个13×13的网格,每一处的网格都要放置15个先验框,因此,这张网格上共有13×13×15=2535个先验框。如果我们用更多的网格,这个数量会更多。先验框越多,所需的参数量就越大,自然就会带来更多的计算量上的压力。
-
Use convolutional layers
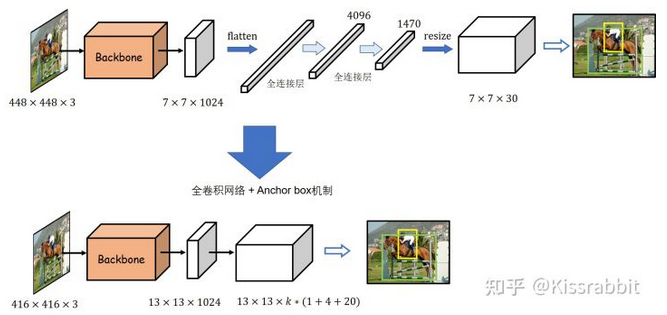
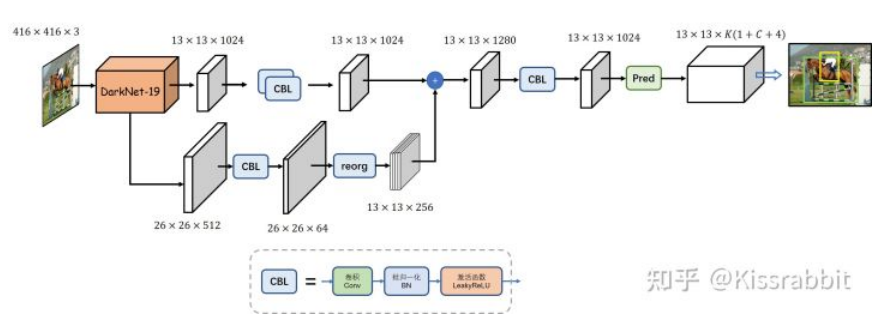
- 在YOLOv1中,有一个很显著的问题就是网络在最后阶段使用了全连接层这不仅破坏了先前的特征图所包含的空间信息结构,同时也导致参数量爆炸。为了解决这一问题,作者便将其改成了全卷积结构,并且添加了Faster R-CNN 工作所提出的anchor box机制。具体来说,首先,网络的输入图像尺寸从448改为416,去掉了YOLOv1网络中的最后一个池化层和所有的全连接层,修改后的网络的最大降采样倍数为32(由64变为32,因应该是因为去掉了最后一个池化层),最终得到的也就是13×13的网格,不再是7×7。每个网格处都预设了k个的anchor box。网络只需要学习将先验框映射到真实框的尺寸的偏移量即可,无需再学习整个真实框的尺寸信息,这使得训练变得更加容易
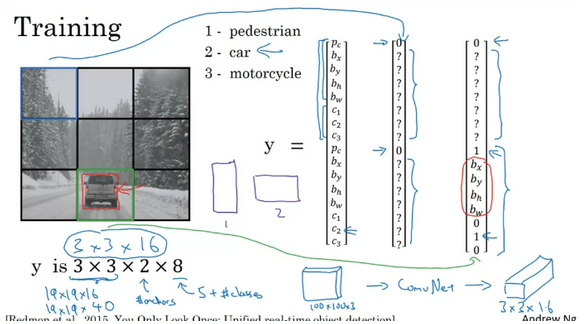
- 其实,在之前的YOLOv1中,我们已经知道每个网格处会有1个边界框输出,而现在变成了预测k个先验框的偏移量。原先的YOLOv1中,每个网格处的B个边界框都有一个置信度,但是类别是共享的,因此每个网格处最终只会有一个输出,而不是B个输出(置信度最高的那一个),倘若一个网格包含了两个以上的物体,那必然会出现漏检问题。加入先验框后,YOLOv1改为每一个先验框都预测一个类别和置信度,即每个网格处会有多个边界框的预测输出。因此,现在的YOLOv1的输出张量大小是S×S×k×(1+4+C),每个边界框的预测都包含1个置信度、4个边界框的位置参数和个类别预测
- Note: 原来之前经常见到的每个box都包含5+C的格式已经是YOLOv2的改进了,而且所谓box其实也已经是anchor box了。就像tudelft lecture里一样,那个slides里已经在提”anchor box”. 但其实纯纯的v1是没有的。而且这里作者也提到了关于之前类别是共享的,实际上只是每个grid检测一个box的问题,和我之前自己心里想的是一致的。
尽管网络结构变成了全卷积网络,并使用了anchor box机制,但网络的精度并没有提升,反倒是略有所下降,69.5% mAP降为69.2% mAP,但召回率却从81%提升到88%。召回率的提升意味着YOLO可以找出更多的目标了,尽管精度下降了一点点。由此可见,每个网格输出多个检测结果确实有助于网络检测更多的物体。因此,作者并没有因为这微小的精度损失而放弃掉这一改进。
K-means clustering of box dimensions
- Different from faster R-CNN that uses hand-picked sizes of anchor boxes, YOLOv2 runs k-mean clustering on the training data to find good priors on anchor box dimensions. The distance metric in k-means is designed to rely on IoU scores:
\(\texttt{dist}(x,c_i)=1−\texttt{IoU}(x,c_i),i=1,…,k\)
where x is a ground truth box candidate and c_i is one of the centroids. The best number of centroids (anchor boxes) k can be chosen by the elbow method. The anchor boxes generated by clustering provide better average IoU conditioned on a fixed number of boxes - 前面简介anchor box机制时,我们提到了这些先验框的一些参数需要人工设计,包括先验框的数量和大小。在Faster R-CNN中,这些参数都是由人工设定的,然而YOLO作者认为人工设定的不一定好。于是作者采用kmeans方法在VOC数据集上进行聚类,一共聚类出k个先验框(k是通过实验的一个最终设定)。聚类的目标是数据集中所有检测框的宽和高,与类别无关。为了能够实现这样的聚类,作者使用IoU作为聚类的衡量指标。
- 通过kmeans聚类的方法所获得的先验框显然会更适合于所使用的数据集,但这也会带来一个问题:从A数据集聚类出的先验框显然难以适应新的B数据集。尤其A和B两个数据集中所包含的数据相差甚远时,这一问题会更加的严重。因此,当我们换一个数据集,如COCO数据集,则需要重新进行一次聚类,如果样本不够充分,这种聚类出来的先验框也就不够好,这也是YOLOv2以及后续的YOLO版本的潜在问题之一。另外,由聚类所获得的先验框严重依赖于数据集本身,倘若数据集规模过小、样本不够丰富,那么由聚类得到的先验框也未必会提供足够好的尺寸先验信息。当然,即便是人工设计的先验框也有着类似的问题,甚至整个anchor-based模型都有这一类问题,所以才有了后来的anchor free工作,这是后话,暂且不提。
- Note: 具体这个k-means是怎么做的呢,以后有时间看看
Direct location prediction
-
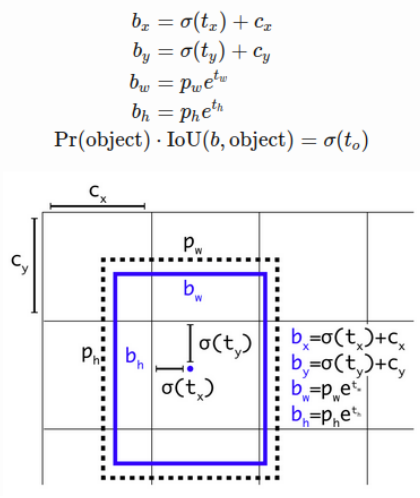
YOLOv2 formulates the bounding box prediction in a way that it would not diverge from the center location too much. If the box location prediction can place the box in any part of the image, like in regional proposal network, the model training could become unstable.
-
Given the anchor box of size (p_w,p_h) at the grid cell with its top left corner at (c_x,c_y), the model predicts the offset and the scale, (t_x,t_y,t_w,t_h) and the corresponding predicted bounding box b has center (b_x,b_y) and size (b_w,b_h). The confidence score is the sigmoid (σ) of another output t_o
-
首先,对每一个边界框,YOLO 仍旧去学习中心点偏移量 t_x和t_y 。我们知道,这个中心点偏移量是介于01范围之间的数,在YOLOv1时,作者没有在意这一点,直接使用线性函数输出,这显然是有问题的,在训练初期,模型很有可能会输出数值极大的中心点偏移量,导致训练不稳定甚至发散。于是,作者使用sigmoid函数使得网络对偏移量的预测是处在01范围中。我们的YOLOv1+正是借鉴了这一点。另外对于尺寸,对每一个边界框,由于有了边界框的尺寸先验信息,故网络不必再去学习整个边界框的宽高了,也是采取exp-log方法fine-tune
-
Note: 其实这里和R-CNN当时的设计就很像了,尺寸上都是用exp-log预测指数上的target,是一样的。而在平移上是有点类似,不过不一样。R-CNN 那边预测的target是要再乘上尺寸作为最终的offset,它本身没有什么约束,不过也是相当于由尺度normalization过,也肯定不是一个绝对值。而YOLO一直是关于grid做文章,这个地方的offset都是0到1之间的,于是这里的设计方法就是预测一个还要输进sigmoid的target。总的来说,这部分也是很好理解的。
-
使用kmeans聚类方法获得先验框,再配合“location prediction”的边界框预测方法,YOLOv1的性能得到了显著的提升:从69.6% mAP提升到74.4% mAP。不难想到,性能提升的主要来源在于kmeans聚类,更好的先验信息自然会有效提升网络的检测性能。只不过,这种先验信息是依赖于数据集的,这是一个潜在问题,感兴趣的读者不妨在这一点上稍作思考。
Add fine-grained features
-
YOLOv2 adds a passthrough layer to bring fine-grained features from an earlier layer to the last output layer. The mechanism of this passthrough layer is similar to identity mappings in ResNet to extract higher-dimensional features from previous layers. This leads to 1% performance increase
-
随后,YOLO 作者又借鉴了同年的SSD工作:使用更高分辨的特征。在SSD工作中,检测是在多张特征图上进行的,不同的特征图的分辨率也不同。可以理解为,特征图的分辨率越高,所划分的网格也就越精细,能够更好地捕捉目标的细节信息。相较于YOLOv1只在一张7×7的过于粗糙的网格上做检测,使用多种不同分辨率的特征图自然会更好。
-
于是,YOLO 作者借鉴了这一思想。具体来说,之前的改进中,YOLOv1都是在最后一张大小为13×13×1024的特征图上进行检测,为了引入更多的细节信息,作者将backbone的第17层卷积输出的26×26×512特征图拿出来,做一次特殊的降采样操作,得到一个13×13×2048特征图,然后将二者在通道的维度上进行拼接,最后在这张融合了更多信息的特征图上去做检测。
-
需要说明的是,这里的特殊降采样操作并不是常用的步长为2的池化层或步长为2的卷积操作,而是一种类似于在图像分割任务中常用到的pixelshuffle操作的逆操作。依据YOLO官方配置文件中的命名方式,我们暂且称之为reorg操作。
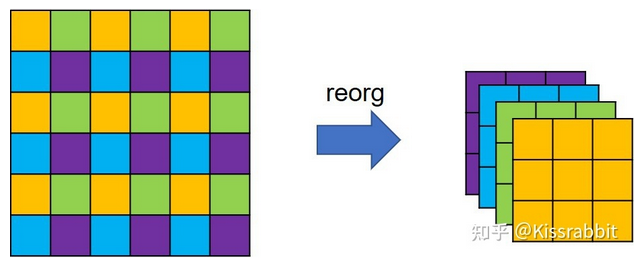
-
不难发现,特征图在经过reorg操作的处理后,特征图的宽高会减半,而通道则扩充至4倍,因此,从backbone拿出来的26×26×512特征图就变成了13×13×2048特征图。这种特殊降采样操作的好处就在于降低分辨率的同时,没丢掉任何细节信息,信息总量保持不变。
-
这一改进在论文中被命名为“passthrough”。加上该操作后,在VOC 2007测试集上的mAP从74.4%再次涨到了75.4%。由此可见,引入更多的细节信息,确实有助于提升模型的检测性能。
Multi-scale training
- In order to train the model to be robust to input images of different sizes, a new size of input dimension is randomly sampled every 10 batches. Since conv layers of YOLOv2 downsample the input dimension by a factor of 32, the newly sampled size is a multiple of 32
- 在计算机视觉中,一个十分常见的图像处理操作是图像金字塔,即将一张图像缩放到不同的尺寸,同一目的,在不同分辨率的图像中,所包含的信息量也不一样,直观的体现便是分辨率越高,构成目标所需要的像素量就越多,目标本身的大小(或像素面积)也就越大。通过使用图像金字塔的操作,网络能够在不同尺寸下去感知同一目标,从而增强了其本身对目标尺寸变化的鲁棒性,如图8所示。YOLO作者便将这一思想用到了模型训练中,以提升YOLO对物体的尺度变化的适应能力。
- 具体来说,在训练网络时,每训练迭代10次(常用iteration表示训练一次,即一次前向传播和一次反向传播,而训练一轮次则用epoch,即数据集的所有数据都经过了一次迭代),就从{320,352,384,416,448,480,512,576,608}选择一个新的图像尺寸用作后续10次训练的图像尺寸。注意,这些尺寸都是32的整数倍,因为网络的最大降采样倍数就是32,倘若输入一个无法被32整除的图像尺寸,则会遇到些不必要的麻烦。
- 这种多尺度训练的好处就在于可以改变数据集中各类物体的大小占比,比如说,一个物体在608的图像中占据较多的像素,面积较大,而在320图像中就会变少了,就所占的像素数量而言,相当于从一个较大的物体变成了较小物体。通常,多尺度训练是常用的提升模型性能的技巧之一。不过,技巧终归是技巧,并不总是有效的,若是我们的目标几乎不会有明显的尺寸变化,那么也就没必要进行多尺度训练了。
- 配合多尺寸训练,YOLOv1再一次获得了提升:从75.4% mAP提升到76.8% mAP。既然已经使用了多尺度训练,YOLOv1模型不仅可以使用416这个尺寸去做测试,也可以使用更大的图像尺寸去做测试。于是,作者又使用544尺寸去测试mAP,意料之内地得到了更高的测试结果:78.6% mAP。
Light-weighted base model

- To make prediction even faster, YOLOv2 adopts a light-weighted base model, DarkNet-19, which has 19 conv layers and 5 max-pooling layers. The key point is to insert avg poolings and 1x1 conv filters between 3x3 conv layers
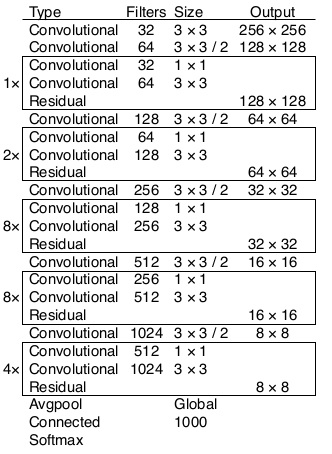
- 作者设计了新的backbone网络取代原先的GoogLeNet风格的backbone网络,新网络被命名为DarkNet19,其网络结构如表1所示。其中的卷积层即为前面所提到的“卷积三件套”:线性卷积、BN 层以及LeakyReLU 激活函数的组合。DarkNet19名字中的19是因为该网络共包含19个卷积层。
- 作者首先将DarkNet19在ImageNet上进行预训练,获得了72.9%的top1准确率和91.2%的top5准确率。在精度上,DarkNet19网络达到了VGG网络的水平,但前者模型更小。
- 预训练完毕后,去掉表6-1中的最后第24层的卷积层、第25层的平池化层以及第26层的softmax层,然后换掉原先的backbone网络。于是,YOLOv1网络从上一次的69.2% mAP提升到69.6% mAP。
YOLOv3
YOLOv3 is created by applying a bunch of design tricks on YOLOv2. The changes are inspired by recent advances in the object detection world.
在上一章的最后,我们提到不论是YOLOv1,还是YOLOv2,都有一个共同的致命缺陷:只使用了最后一个经过32倍降采样的特征图(简称C5特征图)。尽管YOLOv2使用了passthrough技术将16倍降采样的特征图(即C4特征图)融合到了C5特征图中,但最终的检测仍是在C5尺度的特征图上进行的,最终结果便是导致了模型的小目标的检测性能较差。
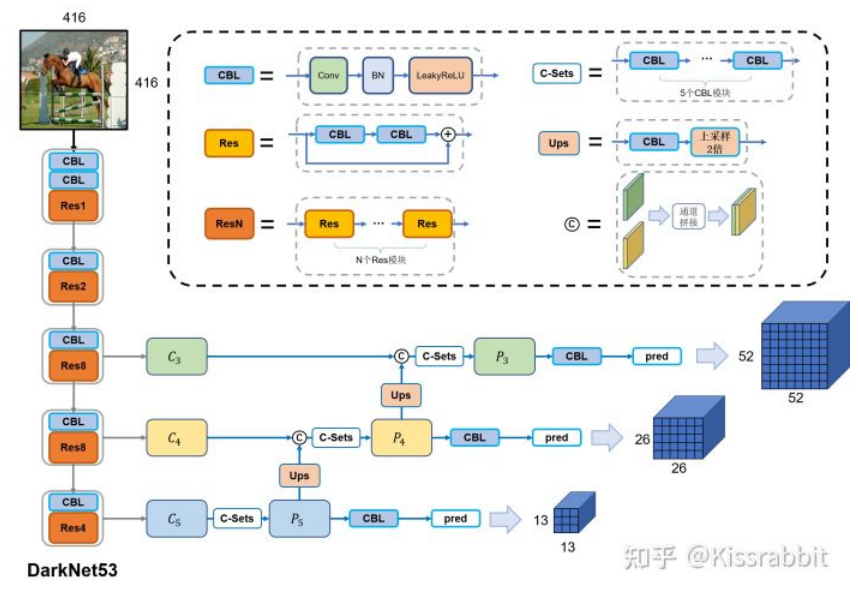
为了解决这一问题,YOLO 作者做了第三次改进,不仅仅是使用了更好的主干网络:DarkNet-53,更重要的是使用了FPN技术与多级检测方法,相较于YOLO的前两代,YOLOv3的小目标的检测能力提升显著。
Logistic regression for confidence scores:
- YOLOv3 predicts an confidence score (objectness) for each bounding box using logistic regression, while YOLO and YOLOv2 uses sum of squared errors for classification terms (see the loss function above). Linear regression of offset prediction leads to a decrease in mAP
- 官方的YOLOv3所使用的置信度损失函数为二元交叉熵(binary cross-entropy)。通过前面的学习,我们已经知道,边界框的置信度实际就是表示此网格处是否有中心点,即是否有物体,因此,YOLO便将其视为一个01二分类的问题,预测的值越接近1,表示这个地方越有可能存在一个目标,反之越不可能存在目标。
- 如果我们简单地采用0和1作为置信度标签,那么对于每一个有着机器学习基础的读者来说,这就是我们再熟悉不过的二元交叉熵了:当标签为1时,网络的理想预测输出就应该是1;当标签为0时,网路的理想预测输出应该时0;在这种情况下,二元交叉熵函数的最小值就是0。如果我们是将当前的预测框与目标框之间的IoU作为置信度标签——正如我们之前一直所采用的方式那样(Note: 是的,我刚想说,这也是我之前自己总结的,没有直接用object or not的0或1,而是根据grid内这个班里最好的IoU作为目标)——那么,对于上面,我们不妨对变量\(C\)求导,并令导数等于0,不难解出,当且仅当\(C=\hat{C}\)时,损失函数会达到最小值\(-\hat{C}\log({\hat{C}})-(1-\hat{C})\log(1-\hat{C})\) 。注意,这个情况下,即二元交叉熵函数的标签不是0和1,而是0到1范围内的实数时,该最小值不是等于0的。举个例子,假如标签 \(C=0.6\) ,带入上式,不难算出此时的最小值为0.673(保留三位小数的结果)。因此,训练中我们会发现,这种情况下的二元交叉损失是不可能等于0的。
- Note: 简单来说,就是由于我们用的目标不是0和1这样的对于该grid的终极目标(这个看似对,但其实如果作为我们预测的去追求的目标是不合适的,因为这是对于这个grid完美的ground-truth的,它的位置尺寸是完美的,所以可以说自己完全是object yes),而是用IoU,让预测出的这个正样本box跟随自己的当前位置尺寸情况,认清自己现在是个什么状态,有多重合了,这才符合这个值所代表的意义,也是与ground-truth的0或1一致的。感觉自己对这个的理解这样表达出来真的不错,mark一下。所以在这种情况下,我们常用的交叉熵那肯定是确定的对或错,体现在二维上那就是0或1,function loss最低算出来那就是0,但是现在既然目标本来就不是0或1,这个函数值也就不在这个函数能够表达的最低了(相当于定义域不给取到那里了)
- 倘若读者熟悉FCOS,对这个问题应该是很清楚的,这也是为什么我们在训练FCOS时,会发现centerness分支的loss是不会掉到0附近的。但这个问题不重要,因为损失函数的最小值又不一定得是0,这取决于我们使用何种度量方式了,对于某些度量,0就是最小值,表示两个量是一样的,如L1损失和L2损失,对于某些度量,0不总之代表两个量是一样的,如上面的BCE损失。切莫思维惯性地认为损失为0就是最小值。我们需要关注的,则是损失函数要达到最小值,而不是最小值本身。言归正传。
- 笔者在初尝试实现YOLOv3时,便遵从官方YOLOv3的方法,使用BCE去计算置信度损失,即objectness损失,而不再是先前的MSE,在COCO上的AP在33左右(其实已经达到了官方YOLOv3在COCO上的性能)。随后,笔者又尝试了一下MSE,在相同的训练配置情况下,COCO上的AP达到了37。虽然,笔者使用BCE时,性能其实和官方的YOLOv3的性能对上了,但考虑到使用MSE效果如此优越,便仍采用MSE,不更换BCE。
- 不过,多说一句,采用MSE而在COCO上达到了更好的AP,就代表着MSE更好吗?有没有可能MSE限制了我的模型天花板呢?也就是说,它掉进的是一个局部极小值,这个局部极小值只是当前给出了好的COCO性能,而限制了模型性能的进一步提升,因为后来我上了很多trick,都难以再提升我的YOLOv3的性能了,这一点一直让我想不明白。总而言之,我们自己实现的YOLOv3仍使用MSE损失函数而不是二元交叉熵函数来作为置信度的损失函数。具体细节,读者可以打开项目中的tools.py文件查看损失函数的实现细节。
No more softmax for class prediction:
- When predicting class confidence, YOLOv3 uses multiple independent logistic classifier for each class rather than one softmax layer. This is very helpful especially considering that one image might have multiple labels and not all the labels are guaranteed to be mutually exclusive
- 官方的YOLOv3使用sigmoid函数处理每一个类的预测输出,而不是softmax,因此,不同类之间的预测是独立的,而不是互斥的,换言之,所有类别的概率和是可以大于1的,在多标签任务中(如一个人的标签同时是“人”和“男人”两类),这种情况是很常见的。这就相当于我们一共设置了C个二元分类器,每一个分类器去负责检测自己所对应的类别,对于此种情况,自然采用BCE损失函数去计算类别损失。从官方论文来看,YOLO作者之所以这么做,是因为作者考虑到同一个目标可能会有多个标签,比如一个目标是犬,同时还是个拉布拉多犬,并且还是一只雌性犬,同时,作者也认为softmax去做类别预测和sigmoid去做类别预测都差不多,不会在性能上拉开多少。
- 不过,既然没什么性能差别,也没什么理论上的差别,那我们则仍使用softmax做类别预测,使用交叉熵函数计算类别损失。这一点与先前的YOLOv1+和YOLOv2+都保持一致。
Darknet + ResNet as the base model:
- The new Darknet-53 still relies on successive 3x3 and 1x1 conv layers, just like the original dark net architecture, but has residual blocks added
- YOLOv3的第一处改进便是换上了更好的backbone网络:DarkNet53。相较于YOLOv2中所使用的DarkNet19,新的网络使用了更多的卷积——53层卷积,同时,添加了残差网络中的残差连结结构,以提升网络的性能。DarkNet53的具体结构如图2所示,注意,DarkNet53网络中的降采样操作没有使用Maxpooling层,而是由stride=2的卷积来实现。卷积层仍旧是线性卷积、BN层以及LeakyReLU激活函数的串联组合。
- 在ImageNet数据集上,DarkNet53的top1准确率和top5准确率几乎与ResNet101和ResNet152持平,但速度却显著高于后两者。因此,相较于所对比的两个残差网络,DarkNet53在速度和精度上具有更高的性价比。不过,由于DarkNet53是由较小众的DarkNet深度学习框架实现的,因此没有成为学术界的主流模型,其受欢迎程度仍不及ResNet系列。所以,除了YOLO系列的工作,我们几乎是很少能看到DarkNet的身影的,包括近来的CSPDarkNet系列,我们也几乎看不到别的工作。
- 多说几句,目前来看,目标检测领域的baseline几乎已经被RetinaNet工作统治了,很多增量式的改进也都是在RetinaNet的基础上做的,往往Mask R-CNN和Faster R-CNN也会用上,毕竟是双阶段检测器的经典之作。之所以会采用RetinaNet作为baseline,一个原因是RetinaNet的网络十分简洁,训练起来也没有太tricky的东西。也许有人会说,YOLO也很简洁呀,确实,YOLO正因为其网络十分简洁,因而有着较好的泛化性,没有设计过多的trick来在COCO上刷性能(有可能过拟合)。但另一个很重要的原因便是RetinaNet的训练时间很短,通常只需要在COCO上训练12个epoch,数据增强也只需要使用随机水平翻转即可。相反,YOLOv3往往需要在COCO上训练超过200个epoch,并且使用包括随机水平翻转、颜色扰动、随机剪裁和多尺度训练在内等大量的数据增强手段。因此,就训练时间而言,YOLOv3往往会需要多得多的时间,这对于没有太多显卡的研究员来说并不友好。尤其是当今又是一个“拼手速”的时代,我们往往急于求成,快点拿到涨点的结果然后写到实验里,发出论文来,因此,训练耗时更少的RetinaNet显然是个更好的选择。不过,在解决实际问题时,YOLO系列更加受欢迎,毕竟在实际任务里,“实时性”是个很重要的指标,这一点恰恰是RetinaNet的劣势。YOLO性能强、速度快、计算量也要远小于RetinaNet,因此更适合用在实际部署中,无非是训练成本大了些。所以孰优孰劣,不能一概而论。言归正传。
- 笔者出于对这个工作的喜爱,尝试使用PyTorch深度学习框架对其进行了复现。复现此模型的最关键之处在于我们手上要有庞大的ImageNet数据集和算力足够的GPU设备。对此,我们不做要求,读者可以直接下载由笔者复现的DarkNet53网络的预训练权重文件,读者可在项目代码中的README文件中找到相关下载链接。读者会得到两个文件:
darknet53_75.42.pth和darknet53_hr_77.76.pth。前者是使用224的输入图像尺寸进行训练得到的,而官方YOLOv3是使用256的图像尺寸进行训练的,因此性能上自然会有所差距,但这个并不影响我们的后续工作。而后者中的“hr”表示这个是在448的图像上微调过,这一技巧我们已经在讲解YOLOv2的章节中介绍过了。
Multi-scale prediction:
- Inspired by image pyramid, YOLOv3 adds several conv layers after the base feature extractor model and makes prediction at three different scales among these conv layers. In this way, it has to deal with many more bounding box candidates of various sizes overall
- 知乎Kissrabit关于FPN以及multi-scale prediction的讨论
- FPN的最早是在2017年的CVPR会议上提出的,其创新点在于提出了一种自底向上(bottom-up)的结构,融合多个不同尺度的特征图去进行目标预测。FPN工作认为网络浅层的特征图包含更多的细节信息,但语义信息较少,而深层的特征图则恰恰相反。原因之一便是卷积神经网络的降采样操作,降采样对小目标的损害显著大于大目标,直观的理解便是小目标的像素少于大目标,也就越难以经得住降采样操作的取舍,而大目标具有更多的像素,也就更容易引起网络的“关注”,在YOLOv1+和YOLOv2+的工作中我们也发现了,相较于小目标,大目标的检测结果要好很多。
- 随着网络深度的加深,降采样操作的增多,细节信息不断被破坏,致使小物体的检测效果逐渐变差,而大目标由于像素较多,仅靠网络的前几层还不足以使得网络能够认识到大物体(感受野不充分),但随着层数变多,网络的感受野逐渐增大,网络对大目标的认识越来越充分,检测效果自然会更好。于是,一个很简单的解决方案便应运而生:浅层网络负责检测较小的目标,深层网络负责检测较大的目标。考虑识别物体的类别依赖于语义信息,因此将深层网络的语义信息融合到浅层网络中去是个很自然的想法。
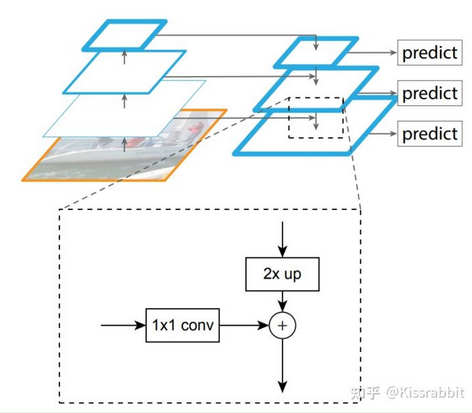
- FPN工作的出发点便是如此,提出了一个行之有效的网络结构,如图4所示。其基本思想便是对深层网络输出的特征图使用上采样操作,然后与浅层网络进行融合,使得来自于不同尺度的细节信息和语义信息得到了有效的融合。
- 从网格的角度来看,越浅层的网格,划分出的网格也越精细,以416的输入尺寸为例,经过8倍降采样得到的特征图C3相当于是一个?的网格,这要比经过32倍降采样得到的特征图C5所划分的?的网格精细得多,也就更容易去检测小物体。同时,更加精细的网格,也就更能避免先前所提到的“语义歧义”的问题。
- 既然,FPN将不同尺度的特征图的信息进行了一次融合,那么一个很自然的方法也就应运而生:多级检测(multi-level detection)。最早,多级检测方法可以追溯到SSD网络,SSD正是使用不同大小的特征图来检测不同尺度的目标,这一方法的思想内核便是“分而治之”,即不同尺度的物体由不同尺度的特征图去做检测,而不是像YOLOv2那样,都堆在最后的C5特征图上去做检测。而FPN正是在这个基础上,让不同尺度的特征图先融合一遍,再去做检测。FPN的这一强大特性,使得它称为了“分而治之”检测方法的重要模块。也为后续许多的特征融合工作带去了启发,如PAN和BiFPN。
- 这里强调一下,“分而治之”方法的内核不是FPN,而是多级检测。FPN不过是锦上添花,即使我们不做特征融合,依旧可以做多级检测,如SSD。只是,使用特征融合手段,可以让检测的效果更好罢了。
- 多说一句,既然有“分而治之”,便也应有“合而治之”,所谓“合而治之”,是指所有物体我们都在一个特征图上去检测,换言之,就是“单级检测”(single-level detection),比如早期的YOLOv1和YOLOv2,便是最为经典的单级检测工作。只不过,主流普遍认为这种只在C5特征图上去单级检测的检测器,小目标检测效果是不行的,尽管这一点被ECCV2020的DeTR和CVPR2021的YOLOF工作否决了,却依旧难以扭转这一根深蒂固的观念,前者似乎只被关注了Transformer这一点上,而后者似乎被认为是“开历史倒车”。无数的历史已证明,根深蒂固的观念是很难被改变,而一旦被改变的那一天,便是一场旧事物的大毁灭与新事物的大喷发……
- 不过,还有一类单级检测工作则另辟蹊径,借鉴人体关键点检测工作的思想,使用高分辨率的特征图如只经过4倍降采样得到的特征图C2来检测物体,典型的工作包括CornerNet和脍炙人口的CenterNet。以512的输入尺寸为例,只经过4倍降采样得到的特征图C2相当于是一个128×128的网格,要比C5的16×16精细的多,然后再将所有尺度的信息都融合到这一张特征图来,使得这样一张具有精细的网格的特征图既具备足够的细节信息,又具备足够的语义信息。不难想象,这样的网络只需要一张特征图便可以去检测所有的物体。这一类工作具有典型的encoder和decoder的结构,通常encoder由常用的ResNet组成,decoder由简单的FPN结构或者反卷积组成,当然,也可以使用Hourglass网络。这一类的单级检测很轻松的得到了研究学者们的认可,毕竟,相较于在粗糙的C5上做检测,直观上便很认同分辨率高得多的C2特征图检测方式。只不过,C2特征图的尺寸太大,会带来很大的计算量,但是,这类工作不需要诸如800×1333的输入尺寸,仅仅512×512的尺寸便可以达到与之相当的性能。
- “分而治之”与“合而治之”各有千秋,这里我们不去下孰优孰劣的定论,由读者自己来判断吧。再次言归正传。
- YOLOv3的关键改进便是使用了FPN结构与多级检测方法。YOLOv3在3个尺度上去进行预测,分别是经过8倍降采样的特征图C3、经过16倍降采样的特征图C4和经过32倍降采样的特征图C5。完整的YOLOv3网络结构如图5所示,整体来看,其网络结构并不复杂。
- 在每个特征图上,YOLOv3在每个网格处放置3个先验框。由于YOLOv3一共使用3个尺度,因此,YOLOv3一共设定了9个先验框,这9个先验框仍旧是使用kmeans聚类的方法获得的。在COCO上,这9个先验框的宽高分别是(10, 13)、(16, 30)、(33, 23)、(30, 61)、(62, 45)、(59, 119)、(116, 90)、(156, 198)、(373, 326)。注意,YOLOv3的先验框尺寸不同于YOLOv2,后者是除以了32,而前者是在原图尺寸上获得的,没有除以32。
- 每个尺度的网格都放置3个先验框,且每个先验框的预测仍旧是包括置信度、类别和位置参数(换言之,输出共包括objectness+class+bbox三部分输出),因此,每个尺度所预测的张量的通道数都是3×(1+C+4)。以416的输入尺寸为例,YOLOv3最终会输出52×52×3(1+C+4)、26×26×3(1+C+4)和13×13×3(1+C+4)三个预测张量,然后将这些预测结果汇总到一起,进行后处理,得到最终的检测结果。
- 其实,不难看出,相较于YOLOv2,YOLOv3主要就是额外多了两个尺度的预测。尽管YOLOv3的性能不及RetinaNet,但在AP50指标上,YOLOv3几乎和RetinaNet达到一个水准,但YOLOv3的速度是后者的3倍左右。在精度和速度的平衡上,YOLOv3做得十分出色,也因此,YOLOv3工作的问世使得工业界的模型又进行了一次迭代更新。
- Anchor大小也改变? A: 不需要随之改变的。多尺度训练的一个作用就是在训练过程中,让一些原本较大的物体变小,让一些原本较小的物体变大,这个目的就是为了增加数据集里不同大小的物体的数量,相当于人,对数据集做了一次扩展,如果anchor box 也跟着变,那就和多尺度训练的目的背道而驰了。但多尺度训练是一个比较强的训练技巧,不是那种一加上就好使的。你可以使用我的强化版yolo v1项目,里面也实现了一整套的yolo ,训练更稳定一些
Skip-layer concatenation:
- YOLOv3 also adds cross-layer connections between two prediction layers (except for the output layer) and earlier finer-grained feature maps. The model first up-samples the coarse feature maps and then merges it with the previous features by concatenation. The combination with finer-grained information makes it better at detecting small objects.
Interestingly, focal loss does not help YOLOv3, potentially it might be due to the usage of λnoobj and λcoord — they increase the loss from bounding box location predictions and decrease the loss from confidence predictions for background boxes. Overall YOLOv3 performs better and faster than SSD, and worse than RetinaNet but 3.8x faster.

- Note: 我感觉这个推测十分合理。所以YOLO对于正负样本不平衡的这个事应该是比较robust的(这也是为了classification的focal loss想要去解决的,还记得吗,大量的easy negatives会让loss很低,但是其实没什么用),因为objectness的存在,如果是负样本,只参与了objectness的loss,不会在loss贡献上成大气候
YOLOX
1. Introduction
- YOLO series [23, 24, 25, 1, 7] always pursuit the optimal speed and accuracy trade-off for real-time applications. They extract the most advanced detection technologies available at the time (e.g., anchors [26] for YOLOv2 [24], Residual Net [9] for YOLOv3 [25]). Currently, YOLOv5 [7] holds the best trade-off performance with 48.2% AP on COCO at 13.7 ms.1
- Nevertheless, over the past two years, the major advances in object detection academia have focused on
- anchor-free detectors [29, 40, 14],
- advanced label assignment strategies [37, 36, 12, 41, 22, 4], and
- end-to-end (NMS-free) detectors [2, 32, 39].
These have not been integrated into YOLO families yet, as YOLOv4 and YOLOv5 are still anchor-based detectors with hand-crafted assigning rules for training.
2.1. YOLOX-DarkNet53
Implementation details
- 300 epochs with 5 epochs warm-up
- SGD for training, SGD momentum is 0.9 and weight decay is 0.0005
- Learning rate of lr×BatchSize/64 (linear scaling [8]), with a initial lr = 0.01 and cosine lr schedule
- Batch size is 128 by default to typical 8-GPU devices
- The input size is evenly drawn from 448 to 832 with 32 strides (Note: multi-scale training). 不再是以往的320-608了。这应该是追求large input size的涨点。
- FPS and latency in this report are all measured with FP16-precision and batch=1 on a single Tesla V100
YOLOv3 baseline
- Adopts the architecture of DarkNet53 backbone and an SPP layer, referred to YOLOv3-SPP in some papers. We slightly change some training strategies compared to the original implementation
- EMA weights updating
- IoU loss and IoU-aware branch. We use BCE Loss for training cls and obj branch, and IoU Loss for training reg branch. (Note: 加入了IoU-aware分支,这一点应该是和PP-YOLO是对齐的)
- Only conduct RandomHorizontalFlip, ColorJitter and multi-scale for data augmentation. RandomResizedCrop is kind of overlapped with the planned mosaic augmentation
Decoupled head
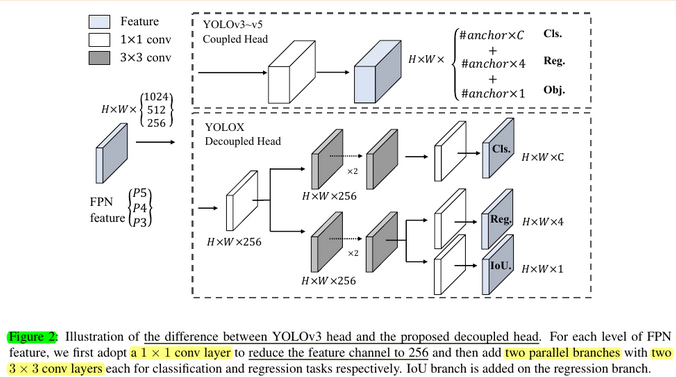
- In object detection, the conflict between classification and regression tasks is a well-known problem [27, 34]. Thus the decoupled head for classification and localization is widely used in the most of one-stage and two-stage detectors [16, 29, 35, 34]
- Note: 具体来说,是什么conflict?感觉其实,毕竟cls的学习显然和reg不一样,仅使用一个branch来完成两个类型完全不同的目标,确实有点难度。
- However, as YOLO series’ backbones and feature pyramids ( e.g., FPN [13], PAN [20].) continuously evolving, their detection heads remain coupled
- Our two analytical experiments indicate that
- Replacing YOLO’s head with a decoupled one greatly improves the converging speed
- The decoupled head is essential to the end-to-end version of YOLO(will be described next)
- We thus replace the YOLO detect head with a lite decoupled head. Concretely, it contains a 1 × 1 conv layer to reduce the channel dimension, followed by two parallel branches with two 3 × 3 conv layers respectively
- Note: 第一个改进就是YOLOv3的head部分。一直以来,YOLO工作都是仅使用一个branch就同时完成obj、cls以及reg三部分的预测。而我们所熟知的RetinaNet则是使用两个并行分支去分别做cls和reg的预测。YOLOX作者认为仅使用一个分支是不合适的,于是,就把原先的Coupled head改成类似于RetinaNet的那种Decoupled head
Strong data augmentation
- We add Mosaic and MixUp into our augmentation strategies. Mosaic is proposed by ultralytics-YOLOv3, then widely used in YOLOv4 [1], YOLOv5 [7] and other detectors [3]. MixUp [10] is originally designed for image classification task but then modified in BoF [38] for object detection training
- After using strong data augmentation, we found ImageNet pre-training is no more beneficial, we thus train all the following models from scratch
- Note: YOLOX继续给baseline增加了Mosaic和Mix-up两个数据增强手段。在训练的最后15个epoch,这两个数据增强会被关闭掉,而在这之前,Mosaic和Mix-up是都开着的,这个细节需要注意一下,笔者的经验是,如果我们从头到尾都开这两个数据增强,性能反而提升不大。
Anchor-free
- Both YOLOv4 [1] and YOLOv5 [7] follow the original anchor-based pipeline of YOLOv3. However, the anchor mechanism has many known problems
- First, to achieve optimal detection performance, one needs to conduct clustering analysis to determine a set of optimal anchors before training. Those clustered anchors are domain-specific and less generalized
- Second, anchor increases the complexity of detection heads, and the number of predictions for each image (Note: pressure on post-processing, I think). And moving such large amount of predictions between devices (e.g., from NPU to CPU) may become a potential bottleneck in terms of the overall latency
- Anchor-free mechanism significantly reduces the number of design parameters which need heuristic tuning and many tricks involved (e.g., Anchor Clustering [24], Grid Sensitive [11].), making the detector simpler in its training and decoding phase
- Switching YOLO to an anchor-free manner is quite simple:
- We reduce the predictions for each location from 3 to 1 and make them directly predict four values i.e., two offsets in terms of the left-top corner of the grid, and the height and width of the predicted box.
- We assign the center location of each object as the positive sample and pre-define a scale range, as done in [29], to designate the FPN level for each object
- Note:
- 有关于anchor box的种种缺点,相信大家都很清楚了,在先前讲解FCOS的文章里也详说了这一点,就不再赘述了。于是,YOLOX作者便去掉了anchor box,和FCOS一样,每个grid都只预测一个目标。
- 去掉了anchor box,也就是去掉了size的先验,故而FPN肯定会出现问题:如何做尺度分配?对于这一问题,YOLOX直接使用FCOS的路子,预先设定一个尺寸范围,根据每个gt的size来判断应该分配到哪个尺度上去。这个预先设定的size范围,论文里没有给出,就需要我们自己去看源码了,但这个不是实质问题,不影响后续的阅读。 对于一个给定的gt边界框,首先根据它的size确定所匹配的尺度,然后就和YOLOv3一样了,计算它在这个尺度上的中心点位置,计算中心点偏差 t_x, t_y ,至于宽高w, h ,就直接作为回归目标(注意,这里要把宽高做归一化,这是基操。)
- 多说一句,anchor-free再怎么anchor-free,它的本质还是anchor-based,只不过,一个anchor处没再放k个anchor box。真正的anchor free,在笔者看来,应该是完全不要spatial维度,或者说,完全不需要再spatial维度上去做遍历(俗称查网格)找目标。所以,相较于anchor-free,笔者更喜欢用更加提切的、误导性更小的anchor box free。
Multi positives
- The above anchor-free version selects only ONE positive sample (the center location) for each object meanwhile ignores other high quality predictions
- However, optimizing those high quality predictions may also bring beneficial gradients, which may alleviates the extreme imbalance of positive/negative sampling during training
- We simply assigns the center 3×3 area as positives, also named “center sampling” in FCOS
- Note: 在完成了anchor-free化的改进后,我们会发现一个问题,那就是一个gt框只有一个正样本,也就是one-to-one,这个问题所带来的最大阻碍就是训练时间会很长,同时收敛速度很慢。为了缓解这一问题,YOLOX作者便自然想到可以增加正样本的数量,使用one-to-many策略。很简单,之前只考虑中心点所在的网格,这会改成以中心点所在的网格的3x3邻域,都作为正样本,直观上来看,正样本数量增加至9倍。每个grid都去学到目标中心点的偏移量和宽高,此时,显然这个中心点偏移量不再是01了,这一点细节的变化需要留意一下。
SimOTA (Note: for label assignment)
- Based on our own study OTA [4], we conclude four key insights for an advanced label assignment:
- 1). loss/quality aware
- 2). center prior
- 3). dynamic number of positive anchors for each ground-truth (abbreviated as dynamic top-k). The term "anchor" refers to "anchor point" in the context of anchor-free detectors and "grid" in the context of YOLO
- 4). global view
- OTA meets all four rules above, hence we choose it as a candidate label assigning strategy. Specifically, OTA [4] analyzes the label assignment from a global perspective and formulate the assigning procedure as an Optimal Transport (OT) problem.
- However, in practice we found solving OT problem via Sinkhorn-Knopp algorithm brings 25% extra training time, which is quite expensive for training 300 epochs. We thus simplify it to dynamic top-k strategy, named SimOTA, to get an approximate solution
- We briefly introduce SimOTA here:
- SimOTA first calculates pair-wise matching degree, represented by cost [4, 5, 12, 2] or quality [33] for each prediction-gt pair. For ex, the cost in SimOTA:
\(c_{ij}=L_{ij}^{cls}+\lambda L_{ij}^{reg}\)
where λ is a balancing coefficient. \(L_{ij}^{cls}\) and \(L_{ij}^{reg}\) are classficiation loss and regression loss between gt \(g_i\) and prediction \(p_j\) - For gt \(g_i\), we select the top k predictions with the least cost within a fixed center region as its positive samples (Note: the fixed region is the 3x3 area around the center mentioned earlier, I think)
- Finally, the corresponding grids of those positive predictions are assigned as positives, while the rest grids are negatives. Noted that the value k varies for different ground-truth
- SimOTA first calculates pair-wise matching degree, represented by cost [4, 5, 12, 2] or quality [33] for each prediction-gt pair. For ex, the cost in SimOTA:
End-to-end YOLO
- We follow [39] to add two additional conv layers, one-to-one label assignment, and stop gradient. These enable the detector to perform an end-to-end manner, but slightly decreasing the performance and the inference speed
- We thus leave it as an optional module which is not involved in our final models

 浙公网安备 33010602011771号
浙公网安备 33010602011771号