
python selenium 多线程、多进程漫画下载
用到的相关库和相关知识,应在阅读本文前了解:requests,selenium,os,logger及其他库;
提示:本文内容,只针对某个特定网站,其他网站不可用,仅作学习交流之用,如有对网站或其他人造成影响,请告知,立删文;
网站大概情况
猛猛干别人所有漫画太狠了,我们只是想下载自己想看的漫画,比如我们随便挑一个漫画名;

一般都会只显示一部分的漫画,需要点加载更多,才会出所有链接;网络抓包里面看了一下,也只会显示能看到的部分的链接,需要跟主页URL拼一下,但一般漫画都有很多话(集数);
我们点击加载更多,之后随便挑一个,直奔图片链接,发现一开始打开漫画页面,只会加载2张图,下滑之后每次再加载两张,是有两个参数控制的,
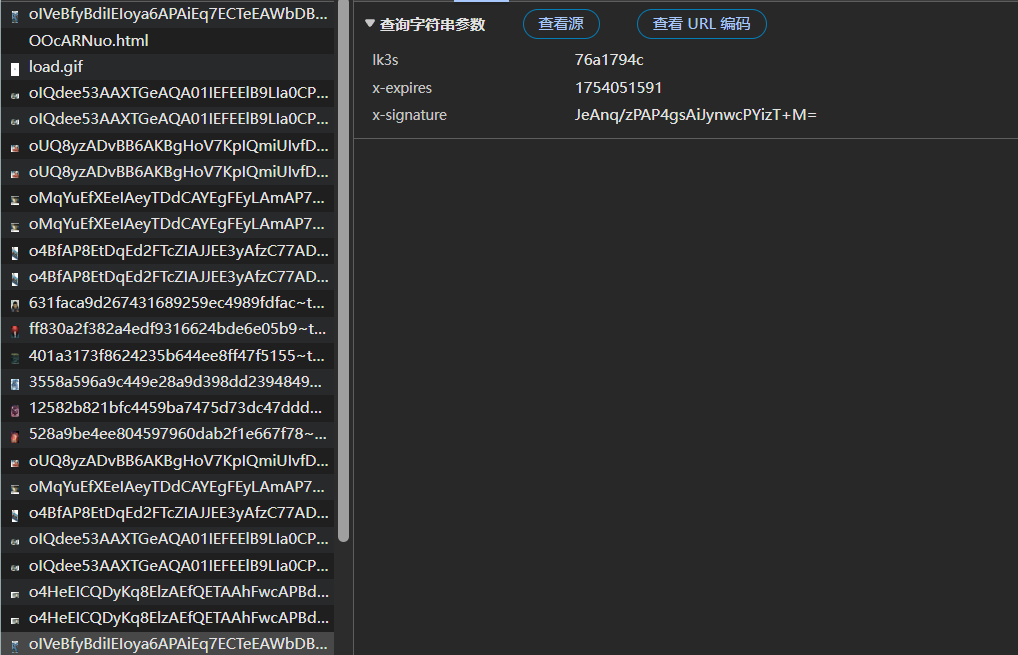
相信会点逆向的应该可以花点时间搞定,但绝对没必要,就老老实实用点自动化工具抓吧,反正时间主要是耗在请求图片,也不能猛猛攻击别人;
就用selenium演示啦;

说明:①本内容未提供多线程多进程下载的代码,因为叠加了多个加速buff速度挺快,会对别人网站造成压力,但是思维导图已经说明了一切;②关于网页的解析说明已删除,审核过不了,且太具有针对性...③主要是鼠标检测那块,实现了一个不停下滑的功能。④变量名称已尽可能用英文写得比较标准,但还是带点个人色彩,注释很多,自己看;
更新1:添加去掉非法字符功能,部分漫画名字里面有不能创建为文件夹的符号,要去掉,不然程序报错;
更新2:添加装饰器日志功能,优化了easy方法冗余操作,解决了一些bug,增加了独立单章下载功能,用来补全因各种原因漏掉的单个章节,亦可单独新下载一个从未下过漫画的某章节;
---
提醒:将本文写得方法封装成类,单线程下载速度,大概是文中单纯的函数组合基础版的五倍,毕竟定义类不搞太多全局变量,是要快一些;
再叠加多进程多线程buff,会更快,但太快对别人网站造成压力不妥,由于文中的方法是定点解析内容,故网页的前端代码改变的话,可能导致无法使用,需更改xpath或者用正则强行模糊寻找;
---
一、带着看看网站基本情况
一般的动漫网站,都是一个漫画manga中,含有多个章节chapter,经常是很多章节,所以要点击加载更多,由于漫画的特殊性,最好是从最老的一章开始下;
上图只是一个示意图,并不是用的这个网站!
点进具体一话中的图片,同时网页中的图片链接,用selenium的elements演示;
本文提供easy方法,selenium打开后,直接获取所有链接并下载,这样又快对网站压力也小;
同时提供hard方法,模拟鼠标一张张图往下滑,应对复杂检测;
二、多进程多线程携程异步和池子
进程、线程池肯定比单纯多进程多线程好,异步经常容易搞出点小问题,而且必须控制好,不然速度太快搞出事;
进程+线程池思路1:
先获取了所有章节链接,分离出下载单章的功能fun_1(例如本代码中的make_up功能),这个功能使用多线程下载,同时开个进程池,多process运行fun_1;
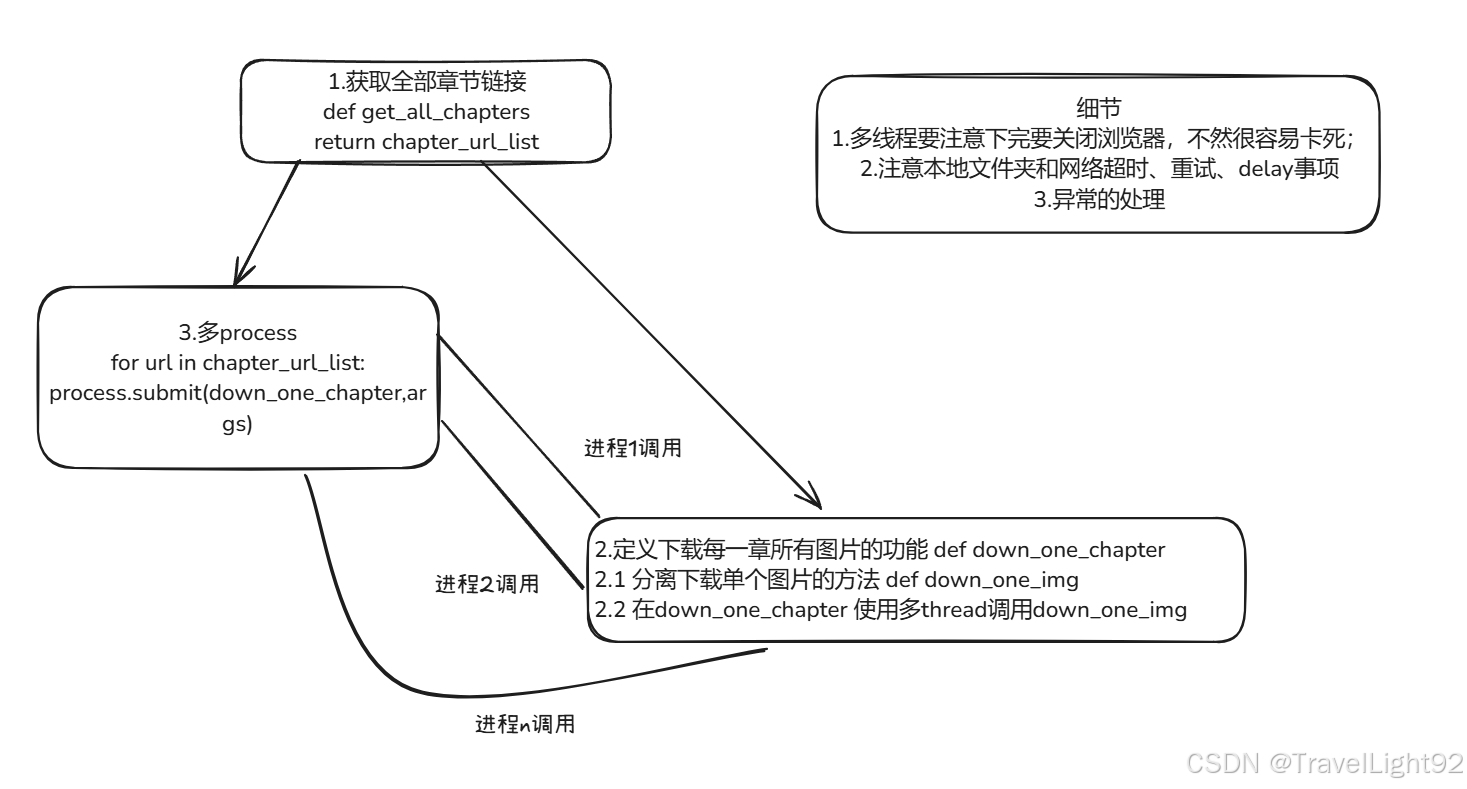
思路2:
fun_a,专门用于获取单个章节所有图片链接,用process1运行;
fun_b,专门下载process1传递过来的链接,同时注意保存的路径和图片顺序,用process2运行;用redis或者queue连通进程之间的数据隔离,注意退出机制;
感觉并不如思路1好...
图就不画了...
三、代码部分---单进程单线程不用类版本
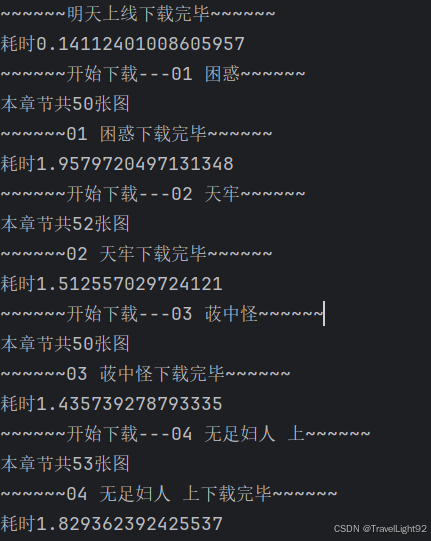
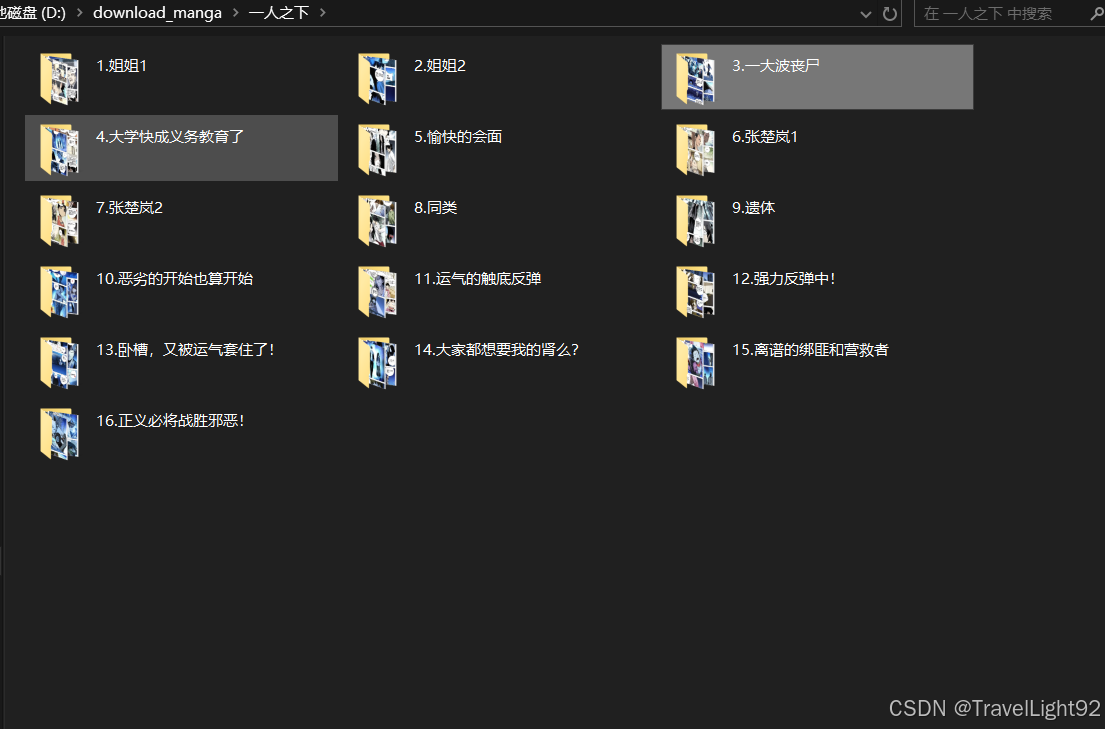
3.1先展示下载过程和结果
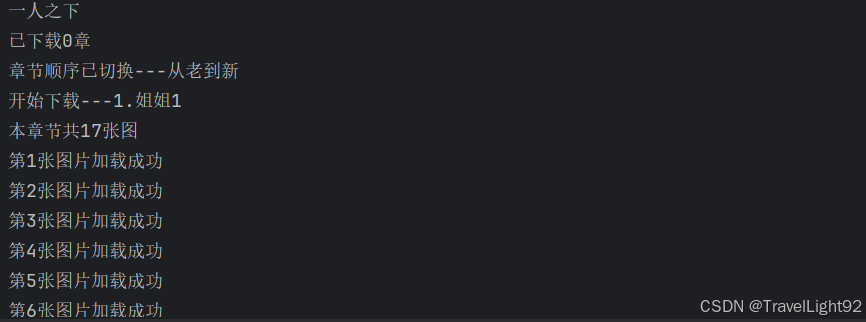
如果稍微叠一部分加速buff的话(未全部叠满,做人留一线,仅试运行下载了部分):
3.2代码部分
Tips:每一章下载之前,会打印这一章有多少图片,下载完会强制休息2秒,免得太快。sure参数是断点续传功能,如中途停掉程序,不确定最后一章是否下全,则sure=False把最近一章节重新下一遍;
import requests
from selenium import webdriver
import time
from selenium.webdriver.chrome.service import Service
from urllib import parse
import os
import re
import random
from selenium.webdriver.common.action_chains import ActionChains
from requests.adapters import HTTPAdapter
import gc
import logging
import sys
from functools import wraps
chromedriver_path = r"C:/Program Files/Google/Chrome/Application/chromedriver.exe"
my_serivce = Service(chromedriver_path)
my_options = webdriver.ChromeOptions() # 导入配置
my_options.add_experimental_option('detach', True) # 不自动关闭浏览器
my_options.add_experimental_option('excludeSwitches', ['enable-automation']) # 规避检测
my_options.add_argument('--headless') # 无头浏览器
my_options.add_argument('--disable-gpu')
# 1.1先打开选择的某一部漫画主页
cd = webdriver.Chrome(service=my_serivce, options=my_options) # 创建selenium对象
# main_page = "https://m.dumanwu.com/OjuNWRo/" # 漫画章节页
main_page = "https://m.dumanwu.com/OMssxtS/" # 漫画章节页
cd.get(main_page)
cd.implicitly_wait(2) # 隐式等待
# 1.2先创一个专门存漫画文件夹的文件夹
target_dir = "d:/download_manga" # 要在电脑上先创这个文件夹,或换makedirs方法递归创建
if not os.path.exists(target_dir):
os.mkdir(target_dir)
# 1.2.2 为每个漫画创一个子文件夹
manga_name =cd.find_element('xpath','//h1[@class="banner-title"]').text
print(manga_name)
# 1.2.1去除非法文件名字符
def be_good_name(name):
"""
有的漫画名有特殊字符,如 : ?等,会导致创建文件夹失败
"""
pattern = re.compile(r'[\/\\\:\*\?\"\<\>\|]')
new_name = pattern.sub('', name) # 去掉奇怪的字符,不然文件夹创建会失败
return new_name
manga_name = be_good_name(manga_name)
the_manga_dir = f"d:/download_manga/{manga_name}" # 这次要下载的某个漫画文件夹
if not os.path.exists(the_manga_dir):
os.mkdir(the_manga_dir)
# 1.3实例化logger
def create_logger(logger_name='download_log'):
"""
该模块功能:配合装饰器,将何时下了了什么漫画,以及何时手动停止记录
"""
logger = logging.getLogger(name=logger_name)
logger.setLevel(logging.INFO)
logger.propagate=False # 不向上传递
# 1.3.1 存储用
handler_file = logging.FileHandler('download_list.log',mode='a',encoding='utf-8')
format_file = logging.Formatter('%(asctime)s-%(levelname)s-%(message)s-%(thread)d'
,datefmt='%Y-%m-%d %H:%M:%S')
handler_file.setLevel(logging.INFO)
handler_file.setFormatter(format_file)
# 1.3.2 输出用
handler_console = logging.StreamHandler(sys.stdout)
handler_console.setLevel(logging.WARNING)
format_console = logging.Formatter('%(message)s-%(thread)d-%(process)d')
handler_console.setFormatter(format_console)
# 1.3.3添加
logger.addHandler(handler_file)
logger.addHandler(handler_console)
return logger
logger = create_logger()
def get_chaptert_urls(web_driver):
"""
该模块功能:
1.让章节数多的漫画,点击加载更多,同时让排序从老到新
2.获取每个章节的完整链接并返回,因为显示所有章节的页面,只会显示后半段,要拼接下
"""
try:
# 1.3找到并点击获取更多章节按钮
web_driver.find_element('xpath', value='//div[@class="chaplist-more"]/button').click()
"""
用下面这种写法也可以,稍微麻烦点,要先导包,很多视频的find_element_by什么的方法,早已deprecated
from selenium.webdriver.common.by import By
web_driver.find_element(By.XPATH,value='//div[@class="chaplist-more"]/button').click()
"""
web_driver.implicitly_wait(2) # 隐式等待2秒
# 1.4更改顺序,先下载最老的
web_driver.find_element('xpath', value='//div[@class="sortable"]/span').click()
zj_order = web_driver.find_element('xpath', value='//div[@class="sortable"]/img').get_attribute('alt')
if zj_order == 'desc':
print('章节顺序已切换---从老到新')
except:
print('章节较少,无需翻页')
finally:
# 1.5源码各章节,只有后半段的url,需要跟主页拼接
chapter_url_list = [] # 用于记录每一章的完整链接
chapter_url_list_pieces = web_driver.find_elements('xpath', value='//div[@class="chaplist-box"]/ul/li/a')
for piece in chapter_url_list_pieces:
temp_url = piece.get_attribute('href')
chapter_url = parse.urljoin(main_page, temp_url) # 自动拼接,懒得操心
# print(page_url)
chapter_url_list.append(chapter_url) # 将每个章节url存入列表
return chapter_url_list
# 1.6难一点适用性广的更新图片链接方法
def get_all_hard(imgs_links,web_driver,recursion_num =0):
"""
经研究,网页elements有鼠标检测之类的东西,不滑不执行js
该方法,模拟每次下滑一张图,并让鼠标悬停一下,并点击一下(不会跳转)
用一点点滚动的方式,而不是一下子滚到底,避免被检测或者网络不畅等
"""
page_counts = len(imgs_links)
for index_num in range(page_counts):
"""这个循环,用索引而不是内容,
因为原计划是每次下滑一次,就对所有链接重新解析一次,
后面发现每次更新消耗太大没必要,且图片总数在一开始就定下来了
"""
pic_element = imgs_links[index_num].find_element('xpath', './img') # 用于定位图片并下滑
loading_check = pic_element.get_attribute('src') # 获取图片真实链接
if not re.search(r'images/load.gif', loading_check):
print(f"第{index_num}张图片链接加载完成")
# print(pic_element.location,pic_element.size)
# imgs_links = web_driver.find_elements('xpath', value='//div[@class="main_img"]/div')
if re.search(r'images/load.gif', loading_check):
# 滚动到未加载完的图大概中间位置
target_location = pic_element.location['y'] + round(pic_element.size['height']*random.uniform(0.4,0.6))
# print(target_location)
javascript = f'document.documentElement.scrollTop={target_location};'
web_driver.execute_script(javascript)
# 执行鼠标悬停和点击操作
ActionChains(web_driver).move_to_element(pic_element).pause(.5).click(pic_element).perform()
web_driver.implicitly_wait(1)
# time.sleep(1)
print(f"第{index_num}张图片未加载完成,下滑一次")
# print(pic_element.location, pic_element.size)
# 由于我们每张图都点了一下,图链接理论上全部更新过了
imgs_links = web_driver.find_elements('xpath', value='//div[@class="main_img"]/div')
# 再循环检查一次,确保万无一失
for i in range(page_counts):
check_again = imgs_links[i].find_element('xpath', './img').get_attribute('src')
if re.search(r'images/load.gif', check_again):
recursion_num += 1
print(f"上一轮滑动有遗漏,再次执行,执行递归第{recursion_num}次")
imgs_links = get_all_hard(imgs_links,web_driver)
return imgs_links
# 1.7简单方法,这个网站简单可用
def get_all_easy(imgs_links):
"""
终究错付,仔细看源码,其实图片链接一开始就在里面
未被滑动到,则图片链接会在data-src属性,src属性中放着加载中的gif
滑动之后,data-src属性会被删除,加载中也会被删,图片链接会在src中,
这个raise ValueError()其实没太大必要,这个网站一开始只会加载前两个链接
由于get_attribute找不到会返回None但不报错,所以我设置了找不到强制报错,
实际上就是为了拿到前两个图的src,后面的链接都是拿的data-src
实际下载推荐这个方法,因为快,少加载一次,对别人服务器也好
由于本方法,本身就是为了用难一点的方法,所以没有对简单方法进行优化,实际上简单方法会省几个小步骤
"""
all_link_list = []
for i in imgs_links:
try:
one_link = i.find_element('xpath', './img').get_attribute('data-src')
if not one_link:
raise ValueError()
except:
one_link = i.find_element('xpath', './img').get_attribute('src')
all_link_list.append(one_link)
return all_link_list
def logging_wrapper(function):
"""
装饰器,为了给单个章节下载添加日志功能
不需要就把download_one_chapter上的@logging_wrapper注释掉
"""
@wraps(function)
def inner(*args,**kwargs):
t1 = time.time()
res = function(*args, **kwargs)
t2 = time.time()
print(f'本章节下载用时{t2-t1}')
if len(res)>=3:
logger.info(f"{res}下载完毕")
else:
# logger.warning(f'在第{res[0]}张图中断,{res[1]}')
logger.warning(f"{res}")
return inner
# 1.8 点进每一个章节中,并循环下载每个图
@logging_wrapper
def download_one_chapter(good_imgs_links,chapter_path,solver='hard',start_num=1):
req = requests.Session()
req.mount('http://', HTTPAdapter(max_retries=3))
req.mount('https://', HTTPAdapter(max_retries=3))
try:
for i in good_imgs_links:
if solver == 'hard':
one_pic_src = i.find_element('xpath', './img').get_attribute('src') # 使用复滚动点击方法
elif solver == 'easy':
one_pic_src = i # 使用easy方法要用这个
img_name = str(start_num) + '.jpg'
img_path = chapter_path+ '/' + img_name
# 确认图片链接加载成功再进行下载
img_bytes = req.get(one_pic_src).content
time.sleep(.5)
if req.head(one_pic_src).status_code == 200:
print(f"第{start_num}张图片加载成功")
with open(img_path, 'wb') as fp:
fp.write(img_bytes)
start_num += 1
except KeyboardInterrupt as e:
req.close() # 关闭连接
return start_num,e
else:
return chapter_path.split('/')[-1], len(good_imgs_links),"***"
def get_start_num(dir_path,sure=False):
"""
考虑到,一些漫画贼长,一次性可能下不完;
或者有更新,所以添加了这个继续下载\下载更新部分的功能
dir_path:下载的漫画目录
sure:最后一章可能没下完,如果不确定,直接重新把自己电脑的最后一章重新下一遍,
懒得判断到底下了多少张图,全部重新下一遍还简单点
"""
has_down_chapters = 0
for dir in os.listdir(dir_path):
if os.path.isdir(dir_path + '/' + dir):
has_down_chapters += 1
if not sure:
has_down_chapters-=1
print(f"已下载{has_down_chapters}章")
return has_down_chapters
def download_many(webdriver,solver='hard',sure=False):
"""
调用的主程序,该程序会嵌套调动其他函数,实现下载
"""
start_num = get_start_num(the_manga_dir,sure=sure)
if start_num <0: # 修复下载从未下过的漫画,且sure为False时只会下最后一章的BUG
start_num = 0
for chapter_url in get_chaptert_urls(webdriver)[start_num:]:
webdriver.get(chapter_url)
# 切换selenium视角到新窗口
webdriver.switch_to.window(cd.window_handles[-1])
# 每一章表面上看没有章节名,但在网页中可以查到
# 其中h1标签十分蛋疼,看起来只有一个内容,取出来却是个列表,换一个,名字有多处
chapter_name = webdriver.find_element('xpath', value='/html/head/meta[@itemprop="chaptername"]').get_attribute('content')
print(f"开始下载---{chapter_name}")
chapter_name = be_good_name(chapter_name) # 去掉奇怪字符
imgs_links = webdriver.find_elements('xpath', value='//div[@class="main_img"]/div')
print(f"本章节共{len(imgs_links)}张图")
# 新建章节文件夹
chapter_path = target_dir + '/' + manga_name + '/' + chapter_name
if not os.path.exists(chapter_path):
os.mkdir(chapter_path)
# 选择使用哪个获取单个章节所有图片链接的方式
if solver == 'hard': # 使用滚动点击的方法的操作
good_imgs_links = get_all_hard(imgs_links,cd) # 使用复滚动点击方法
elif solver == 'easy':
good_imgs_links = get_all_easy(imgs_links) # 这个纯属后加的,单纯用这个,实际上要少很多步骤
download_one_chapter(good_imgs_links,chapter_path,solver)
# 关闭当前窗口----该网站是直接跳转,所以不能关闭,但视角还是要切换
# webdriver.close()
# 切回之前的视角
webdriver.switch_to.window(cd.window_handles[0])
gc.collect()
# 休息一下
time.sleep(2)
# break
def make_up(webdriver,missing_cha_url,target_dir = "d:/download_manga",solver='easy'):
"""
该模块功能用来下载因各种原因漏掉的、残缺的单个章节;
一次下一个,手动挡补全,也可用来下载新漫画(自动创建文件)
"""
import shutil
# 打开以及解析
webdriver.get(missing_cha_url)
manga_name = webdriver.find_element('xpath',
value='/html/head/meta[@itemprop="comicname"]').get_attribute(
'content')
chapter_name = webdriver.find_element('xpath',
value='/html/head/meta[@itemprop="chaptername"]').get_attribute(
'content')
print(chapter_name)
# 删除和创建文件夹
chapter_path = target_dir + '/' + manga_name + '/' + chapter_name
if os.path.exists(chapter_path):
shutil.rmtree(chapter_path) # 先先删掉以免出现
print("旧文件夹已删除")
if not os.path.exists(chapter_path):
os.makedirs(chapter_path)
print("新文件夹已创建")
# 告诉本章节有多少个图
imgs_links = webdriver.find_elements('xpath', value='//div[@class="main_img"]/div')
print(f"章节{chapter_name}共{len(imgs_links)}张图")
# 选择解析链接方式
if solver == 'hard':
good_imgs_links = get_all_hard(imgs_links,webdriver)
elif solver == 'easy':
good_imgs_links = get_all_easy(imgs_links)
# 调用下载程序
download_one_chapter(good_imgs_links,chapter_path,solver=solver)
if __name__ == '__main__':
download_many(cd,solver='easy',sure=False)
# need = "https://m.dumanwu.com/IVXypXi/DDjjKhjq.html" # 测试用
# make_up(cd,need,solver='easy')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号