
Selenium Python抓淘宝数据 基于手动登录后
本文主要是演示selenium模拟浏览器,抓取淘宝数据,需要手动扫码登录,虽然很多文章都有写如何用账号密码登录,但如今就连人工打开浏览器,输账号密码都会有滑块,并且怎么都滑不成功,即使成功了还要验证手机,不如直接扫码。
一、前期
from selenium import webdriver
import time
from selenium.webdriver.chrome.service import Service
from selenium.webdriver import ChromeOptions
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from lxml import etree
import os
import pandas as pd
import random我们直奔登录页面,不进首页,避免还要鼠标点击跳转;
定义一个类,前期准备工作是开启一个chrome浏览器,多线程什么的别想了,现在*宝反爬太严,你敢爬快了,分分钟各种验证就来了;
class DoTaoBao():
def __init__(self, search,store_path='d:/tb_data',sleep_interval=3,max_page=100):
self.search = search # 搜索的关键字
self.store_path = store_path # 存本地的话,位置
self.sleep_interval = sleep_interval # 翻页的间隔时间
self.max_page = max_page # 最多爬到多少页
if not os.path.exists(store_path):
os.makedirs(store_path)
def prepare(self):
chrome_options = ChromeOptions()
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
chrome_options.add_experimental_option('detach', True)
s = Service("C:/Program Files/Google/Chrome/Application/chromedriver.exe")
# 创建一个浏览器
self.browser = webdriver.Chrome(options=chrome_options,service=s)1.1 进入页面
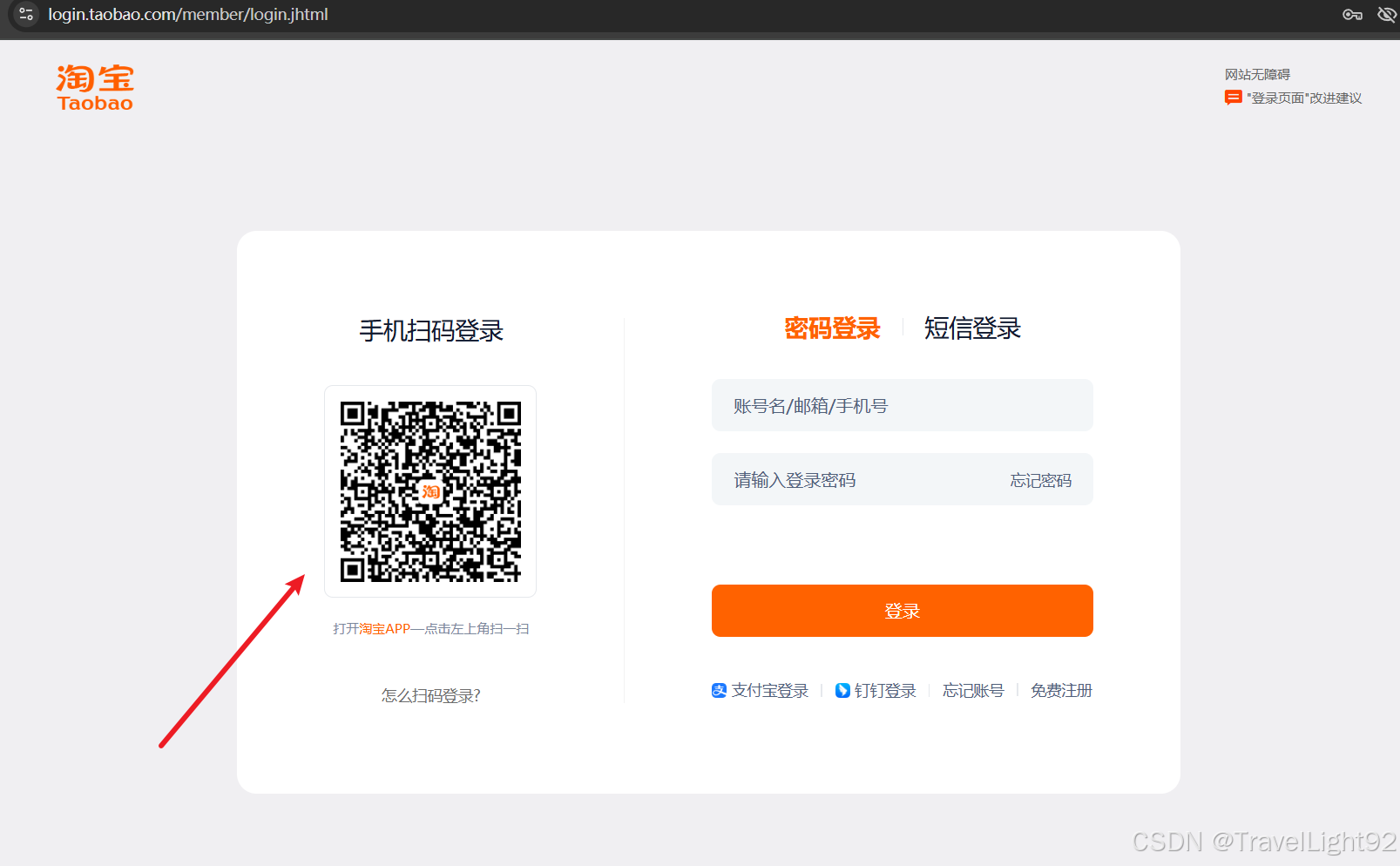
此时你的浏览器打开了登录页面,sleep个十秒,拿出手机扫码,经过实测,很多输账号密码的方式,都被限制了,不如老实扫码;
登录之后,找到搜索框,发送搜索文字,并稍加停顿,回车确认;
def first_step(self):
self.browser.get('https://login.taobao.com/member/login.jhtml') # 直奔登录页面
# browser.get('https://www.taobao.com/')
time.sleep(10)
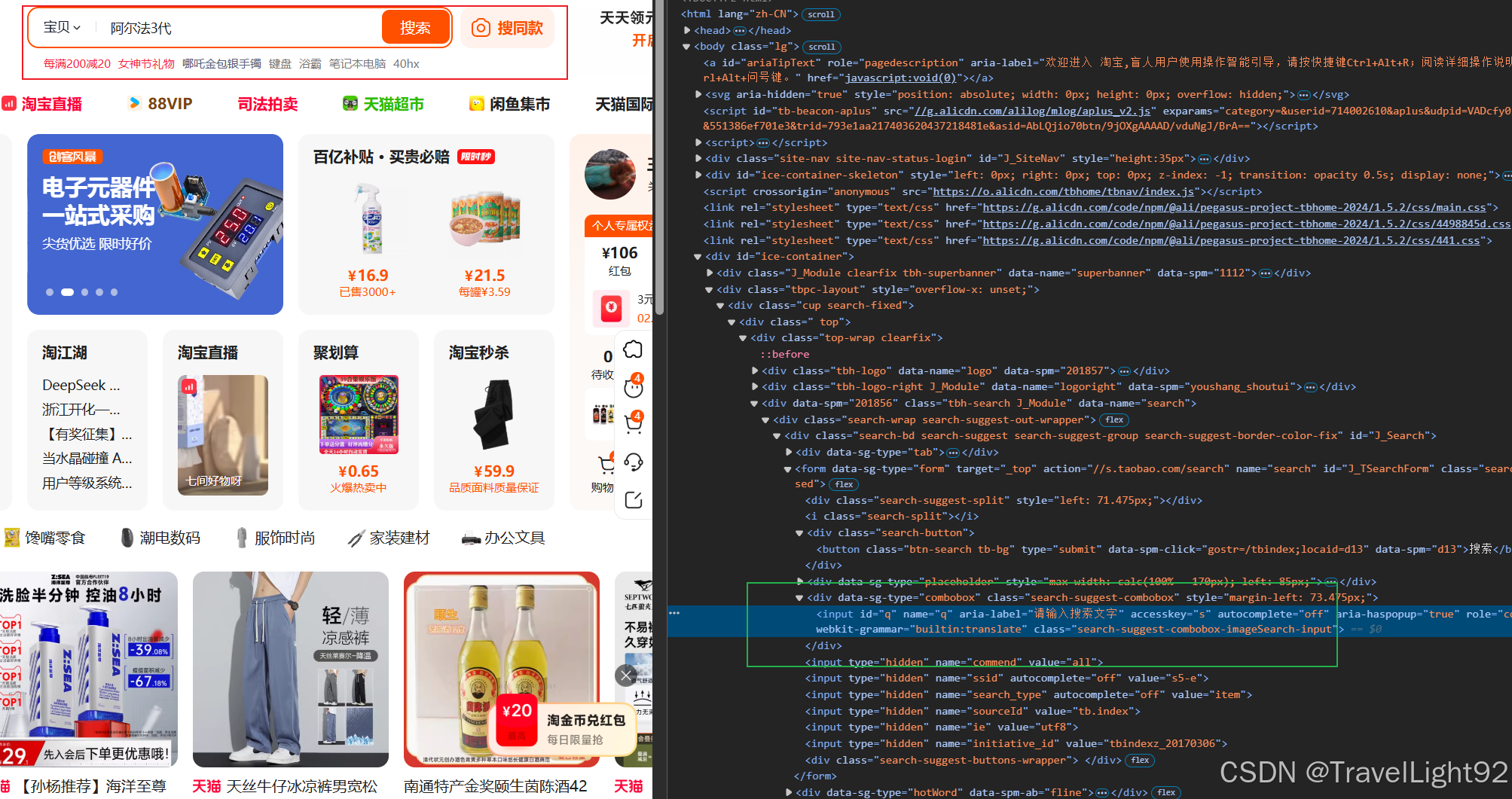
# 找到输入框
search_btn = self.browser.find_element(by="id", value='q')
search_btn.send_keys(self.search)
time.sleep(1)
search_btn.send_keys(Keys.ENTER)
time.sleep(1)
# 切换窗口
self.browser.switch_to.window(self.browser.window_handles[-1])
# 第一次向下滑动窗口,看到翻页按钮
self.browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
wait = WebDriverWait(self.browser, 10)
# 第一次必须看到下一页,确保网页加载完毕
next_button_see = wait.until(EC.presence_of_element_located(
(By.XPATH, '//button[@class="next-btn next-medium next-btn-normal next-pagination-item next-next"]')))输入内容并回车之后,会弹出一个新标签页,所以必须让selenium切换窗口;
第一页我们直接执行JS拉到底,等待看到下一页的按钮后,基本确定网页加载完毕,或者用其他方式,必须要稍作停留;
1.2 坑-1
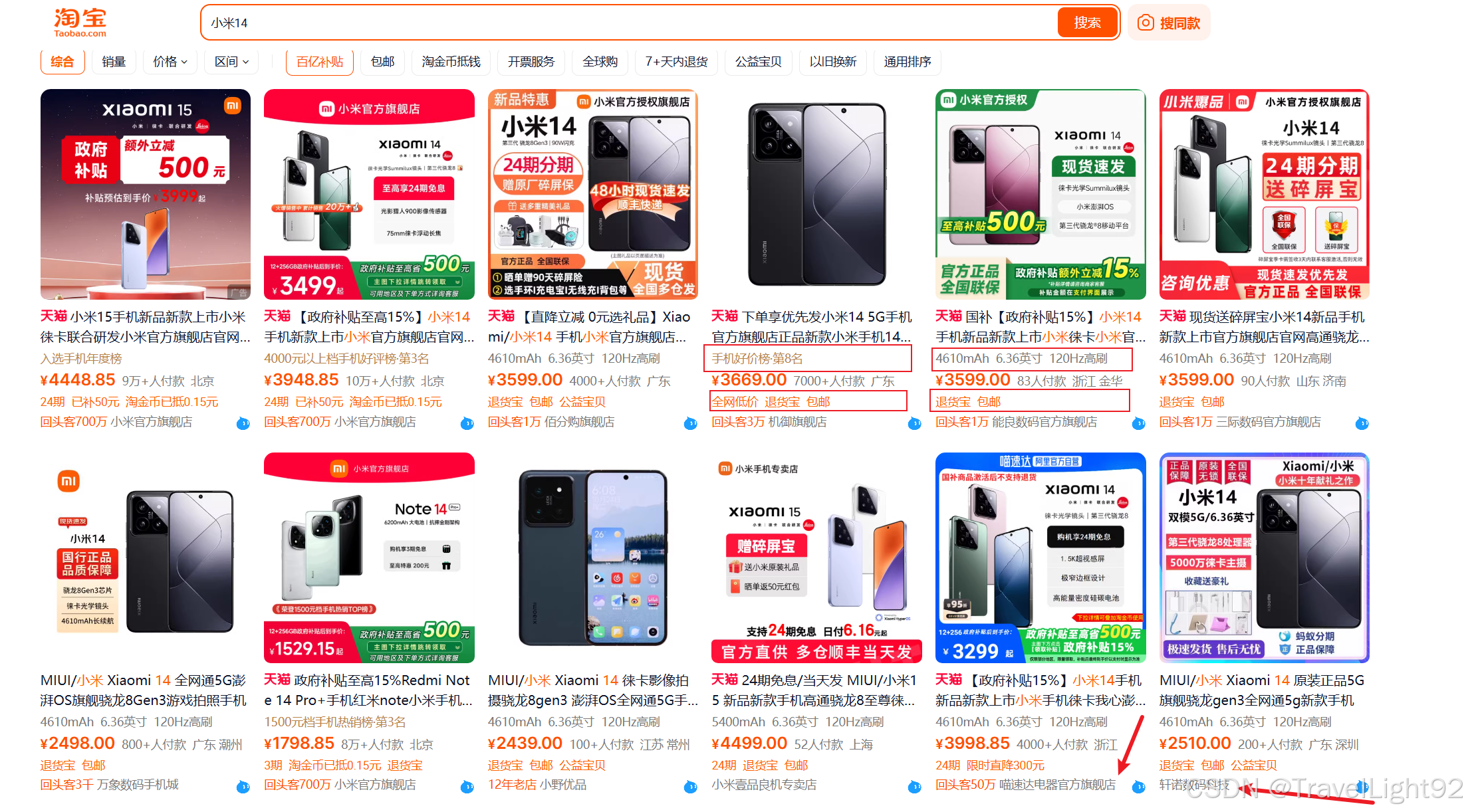
熟悉或者爬过*宝的都知道,这页面元素内容令人蛋疼:
①例如店铺名那一行,有的有二个shop_tag和shop_name;②价格,整数和小数部分,分开两个字符串,切勿尝试在爬虫过程中合并成一个数字,因为你会遇到“待发布”之类的东西,等数据都抓到了,在本地自行捣鼓;③一页显示多少个商品,会根据窗口大小变化,不一定都是6*8;等等
1.3 坑-2
此时在首页,虽然第一页和第二页,就是url中一个**page=1**和**page=2**的区别,但是不要用改url的方式翻页,要点下一页,不然就卡死在第一页,无论page=多少都是第一页,或者不停地在页面选择那块输入数字也行;
1.4 坑-3 别用find_element,要用etree parse(page_source)
根据坑-1内容,如果我们此时直接用selenium的find_element方法,比如肯定要爬店铺名字,有的商品那一行就一个,你抓第二行没有,就会报错,总不能写很多个try except吧,定义一个函数,每个元素都用一次,感觉更加麻烦,虽然也可以,不过并不聪明也很麻烦;
我们让浏览器滑到底,等页面元素都加载完,拿到page_source再慢慢解析;
有的数据可能为空,可以自定义一个函数处理为空的报错问题;
@staticmethod
def avoid_none(data):
if data:
return data[0]
else:
return None或者用列表推导式:
tree.xpath()解析出来的是一个列表,list[0]如果为空也报错,此时利用列表推导式;
data = tree.xpath("by","value").什么方法 :list
data = [data[0] if data else None][0]
所以你会看到下面定位一个元素代码很长,其实单纯为了找不到就返回None而已;
def get_one_page(self, p_source):
# 例如用csv存储数据
df = pd.DataFrame(
columns=['product_name', 'detail_link', 'thumb_link', 'price_int', 'price_float', 'sale_amount', 'sub_tag',
'desc_tag', 'shop_place', 'shop_name', 'shop_tag'])
tree = etree.HTML(p_source)
div_list = tree.xpath('//div[@id="content_items_wrapper"]/div')
for div in div_list:
product_name = div.xpath('./a//div[@class="title--qJ7Xg_90 "]/span//text()')
detail_link = div.xpath('./a/@href')[0]
thumb_link = div.xpath('./a/div/div[1]/div[1]/img/@src')[0]
price_int = div.xpath('./a//div[contains(@class,"priceInt")]/text()')[0]
price_float = div.xpath('./a//div[contains(@class,"priceFloat")]/text()')[0]
sale_amount = DoTaoBao.avoid_none(div.xpath('./a//span[contains(@class,"realSales")]/text()'))
sub_tag = div.xpath('./a//div[contains(@class,"subIconWrapper")]/@title')[0]
desc_tag = div.xpath('./a//div[contains(@class,"descBox")]//text()')
shop_place = div.xpath('./a//div[contains(@class,"procity")]//text()')
shop_name = div.xpath('./a//span[contains(@class,"shopNameText")]/text()')[0]
shop_tag = DoTaoBao.avoid_none(div.xpath('./a//span[contains(@class,"shopTagText")]/text()'))
# 向df最后一行写入数据
df.loc[len(df)] = [product_name, detail_link, thumb_link, price_int, price_float, sale_amount, sub_tag,
desc_tag, shop_place, shop_name, shop_tag]
print(product_name, detail_link, thumb_link, price_int, price_float, sale_amount, sub_tag, desc_tag,
shop_place, shop_name, shop_tag)
# 每爬完一页,追加一次数据
df.to_csv(self.store_path + '/' + self.search + '.csv', index=False, mode='a', encoding='utf-8-sig', header=False)1.5 坑-4,选择器定位别太精确,多用or和模糊
由于网页元素并不完全一致,所以得多用or,或者模糊一点,数据到本地肯定要清洗一下。
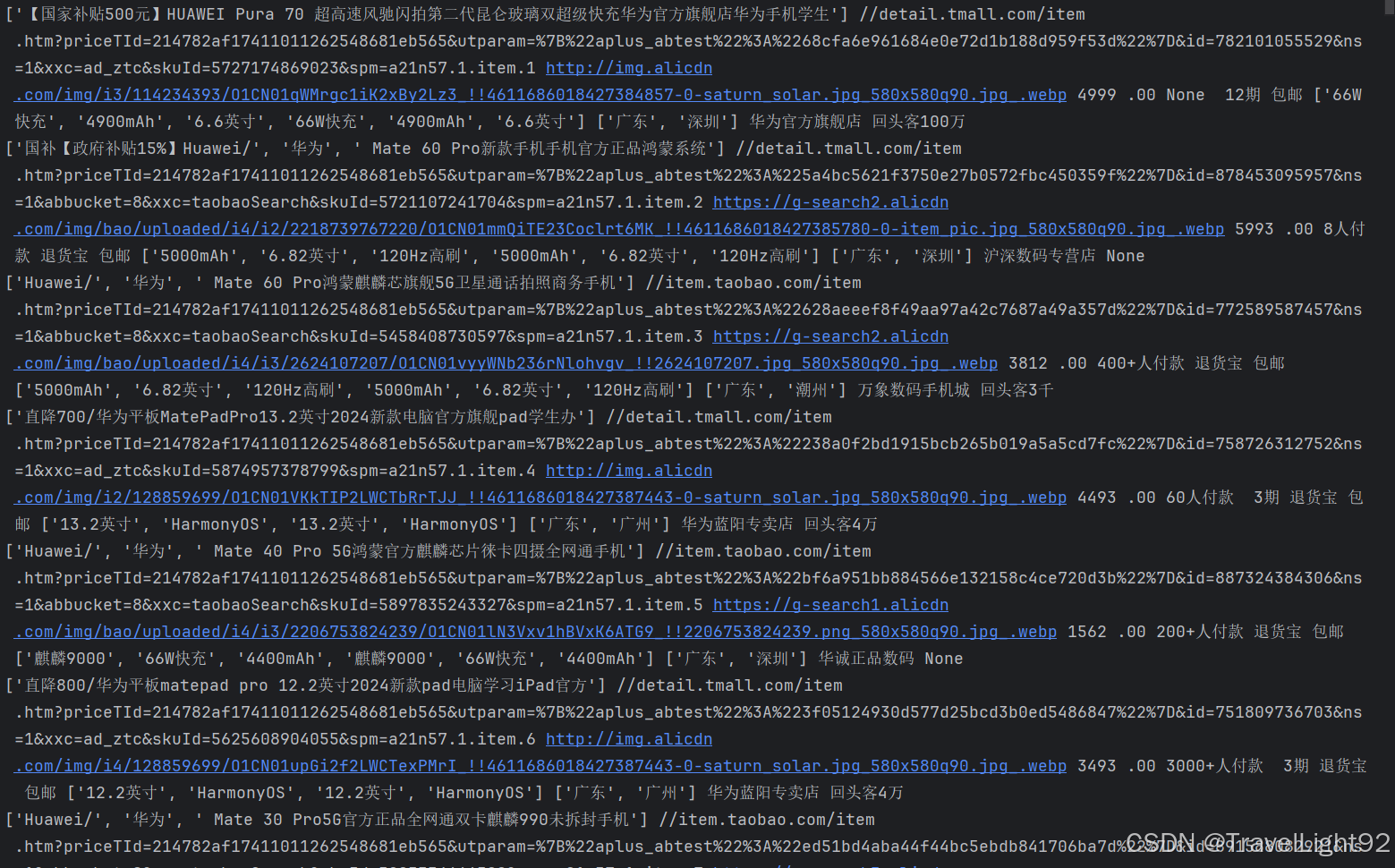
例如本文中的xpath,就没有写到完美,还有进步空间,能看这篇文章的你肯定可以自行搞定。
1.6 翻页--下滑时间间隔、翻页间隔很重要
此时的情况,第一页的内容已经写进去了;
就剩下翻页了,强烈的建议是,翻到第二页,模拟一下鼠标下滑,滑一下间隔一下,不要一次性干到底,很容易被检测,同时翻页的间隔,强烈建议不低于四五秒,不然会出现各种检测,当第一个检测出现了,证明后面会有五花八门各种检测,并且频率越来越高;
本文中,有三种滑动的方式,也可以自己写更加精确的;
def get_all_page(self):
for i in range(1, self.max_page + 1):
if self.scroll_way == 1:
# 模拟人进行浏览---页面高度约为3995
for _ in range(1, 4):
self.browser.execute_script(f'window.scrollBy(0,{random.randint(900, 1000)})')
time.sleep(1)
elif self.scroll_way == 2: # 直接滑到底部
self.browser.execute_script("var q=document.documentElement.scrollTop=0")
self.browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
elif self.scroll_way == 3: # 滑到看到下一页
self.browser.execute_script("arguments[0].scrollIntoView();", self.next_button)
self.browser.implicitly_wait(5)
page_source = self.browser.page_source
# with open(f'd:/page_source_{i}.html','w',encoding='utf-8') as f:
# f.write(page_source).
self.get_one_page(page_source)
self.next_button = self.browser.find_element("xpath",
'//button[@class="next-btn next-medium next-btn-normal next-pagination-item next-next"]')
self.next_button.click()
if i == self.max_page:
self.browser.quit()
time.sleep(self.sleep_interval)
def main(self):
self.prepare()
self.first_step()
self.get_all_page()再加上这个就完整了;
pachong = DoTaoBao(search='华为matepro',store_path='d:/tb_data',sleep_interval=5)
pachong.main()
二、完整代码
from selenium import webdriver
import time
from selenium.webdriver.chrome.service import Service
from selenium.webdriver import ChromeOptions
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from lxml import etree
import os
import pandas as pd
import random
# 前期准备
class DoTaoBao():
def __init__(self, search,store_path='d:/tb_data',sleep_interval=3,max_page=100,scroll_way=1):
self.search = search
self.store_path = store_path
self.sleep_interval = sleep_interval
self.max_page = max_page
self.scroll_way = scroll_way
if not os.path.exists(store_path):
os.makedirs(store_path)
@staticmethod
def avoid_none(data):
if data:
return data[0]
else:
return None
def prepare(self):
chrome_options = ChromeOptions()
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation']) # 屏蔽掉selenium检测
chrome_options.add_experimental_option('detach', True) # 不自动关闭浏览器
s = Service("C:/Program Files/Google/Chrome/Application/chromedriver.exe")
# 创建一个浏览器
self.browser = webdriver.Chrome(options=chrome_options,service=s)
def first_step(self):
self.browser.get('https://login.taobao.com/member/login.jhtml') # 直奔登录页面
# browser.get('https://www.taobao.com/')
time.sleep(10)
# 找到输入框
search_btn = self.browser.find_element(by="id",value='q')
search_btn.send_keys(self.search)
time.sleep(1)
search_btn.send_keys(Keys.ENTER)
time.sleep(1)
# 切换窗口
self.browser.switch_to.window(self.browser.window_handles[-1])
# 第一次向下滑动窗口,看到翻页按钮
self.browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
wait = WebDriverWait(self.browser, 10)
# 第一次必须看到下一页,确保网页加载完毕
next_button_see = wait.until(EC.presence_of_element_located((By.XPATH,'//button[@class="next-btn next-medium next-btn-normal next-pagination-item next-next"]')))
def get_one_page(self,p_source):
# 例如用csv存储数据
df = pd.DataFrame(columns=['product_name','detail_link','thumb_link','price_int','price_float','sale_amount','sub_tag','desc_tag','shop_place','shop_name','shop_tag'])
tree = etree.HTML(p_source)
div_list = tree.xpath('//div[@id="content_items_wrapper"]/div')
for div in div_list:
# 忘记把商品名称弄进去
product_name = div.xpath('./a//div[@class="title--qJ7Xg_90 "]/span//text()')
detail_link = div.xpath('./a/@href')[0]
thumb_link = div.xpath('./a/div/div[1]/div[1]/img/@src')[0]
price_int = div.xpath('./a//div[contains(@class,"priceInt")]/text()')[0]
price_float = div.xpath('./a//div[contains(@class,"priceFloat")]/text()')[0]
sale_amount = DoTaoBao.avoid_none(div.xpath('./a//span[contains(@class,"realSales")]/text()'))
sub_tag = div.xpath('./a//div[contains(@class,"subIconWrapper")]/@title')[0]
desc_tag = div.xpath('./a//div[contains(@class,"descBox")]//text()')
shop_place = div.xpath('./a//div[contains(@class,"procity")]//text()')
shop_name = div.xpath('./a//span[contains(@class,"shopNameText")]/text()')[0]
shop_tag = DoTaoBao.avoid_none(div.xpath('./a//span[contains(@class,"shopTagText")]/text()'))
# 向df最后一行写入数据
df.loc[len(df)] = [product_name,detail_link,thumb_link,price_int,price_float,sale_amount,sub_tag,desc_tag,shop_place,shop_name,shop_tag]
print(product_name, detail_link, thumb_link, price_int, price_float, sale_amount, sub_tag, desc_tag,
shop_place, shop_name, shop_tag)
# 每爬完一页,追加一次数据
df.to_csv(self.store_path+'/'+self.search+'.csv',index=False,mode='a',encoding='utf-8-sig',header=False)
def get_all_page(self):
for i in range(1,self.max_page+1):
if self.scroll_way == 1:
# 模拟人进行浏览---页面高度约为3995
for _ in range(1, 4):
self.browser.execute_script(f'window.scrollBy(0,{random.randint(900, 1000)})')
time.sleep(1)
elif self.scroll_way == 2: # 直接滑到底部
self.browser.execute_script("var q=document.documentElement.scrollTop=0")
self.browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
elif self.scroll_way == 3: # 滑到看到下一页
self.browser.execute_script("arguments[0].scrollIntoView();", self.next_button)
self.browser.implicitly_wait(5)
page_source = self.browser.page_source
# with open(f'd:/page_source_{i}.html','w',encoding='utf-8') as f:
# f.write(page_source).
self.get_one_page(page_source)
self.next_button = self.browser.find_element("xpath",
'//button[@class="next-btn next-medium next-btn-normal next-pagination-item next-next"]')
self.next_button.click()
if i ==self.max_page:
self.browser.quit()
time.sleep(self.sleep_interval)
def main(self):
self.prepare()
self.first_step()
self.get_all_page()
pachong = DoTaoBao(search='华为matepro',store_path='d:/tb_data',sleep_interval=5,max_page=3,scroll_way = 2)
pachong.main()
会有重复数据,因为网页本身就会重复推荐;
结果如下:
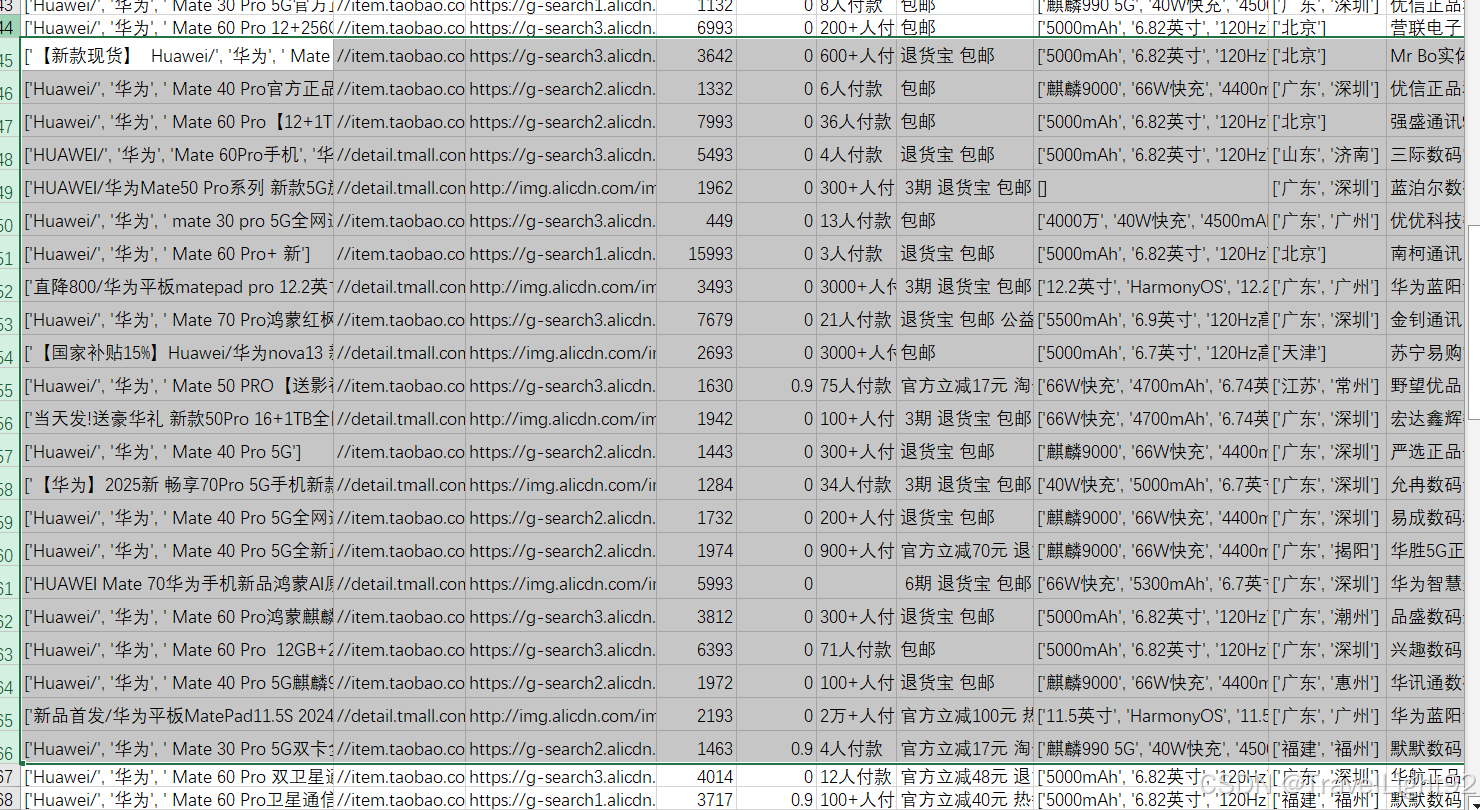
三、数据清洗和分析
可以参考之前写的
<a href = "https://www.cnblogs.com/travel92/p/18824888" target="_blank">数据清洗分析案例</a>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号