
TCP/IP协议栈在Linux内核中的运行时序分析
Linux系统的相关概念
1、系统调用
运行在用户空间的程序需要向操作系统内核请求需要更高权限运行的服务。系统调用提供用户程序与操作系统之间的接口。大多数系统交互式操作需求在内核态运行。如设备IO操作或者进程间通信。
2、Socket
在操作系统中,通常会为应用程序提供一组应用程序接口(API),称为套接字接口(英语:socket API)。应用程序可以通过套接字接口,来使用网络套接字,以进行资料交换。最早的套接字接口来自于4.2 BSD,因此现代常见的套接字接口大多源自Berkeley套接字标准。在套接字接口中,以IP地址及端口组成套接字地址,它提供一组通用函数来支持各种不同的协议。Linux中socket结构是struct sock,这个结构定义了socket所需要的所有状态信息,包括socket所使用的协议以及可以在socket上执行的操作。
3、网络协议
4、设备无关接口
设备无关接口net_device实现的,任何设备与上层通信都是通过net_device设备无关接口。它将设备与具有很多功能的不同硬件连接在一起,这一层提供一组通用函数供底层网络设备驱动程序使用,让它们可以对高层协议栈进行操作。
5、设备驱动程序
Linux把所有的硬件设备分为三大类:字符设备、块设备、网络设备。所有的网络消息都需要通过网络设备发出,这里Linux通过调用net_device的接口实现,但是每个设备要根据自身的情况针对性性地实现这些接口。设备驱动程序个允许电脑软件与硬件交互的程序,这种程序创建了一个硬件与硬件,或硬件与软件沟通的接口,经由主板上的总线或其它沟通子系统与硬件形成连接的机制,这样的机制使得硬件设备上的资料交换成为可能。
OSI七层网络模型和TCP/IP网络模型
在我们以前的学习中,常常将OSI的七层网络模型作为标准,但是OSI七层模型是一个理论模型,实际应用则千变万化,因此更多把它作为分析、评判各种网络技术的依据。
Linux中使用的TCP/IP网络模型就将七层合并为四层,分别是:应用层,传输层,网络层和网络接口层。
他们具体的对应关系如下图所示:
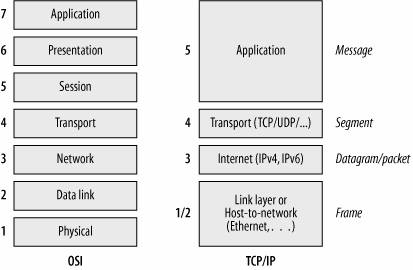
应用层与Socket
应用层进程使用socket进行网络通信,socket是独立于具体协议的网络编程接口,在OSI模型中,主要位于会话层和传输层之间,BSD Socket是通过标准的UNIX文件描述符和其它程序通讯的一个方法,目前已经被广泛移植到各个平台。
和socket相关的函数主要有socket,connect,bind,listen,accept,recv,send, close。这些函数中,最为关键的是创建,发送和接收三个函数。这些方法都通过Linux的系统调用实现,但是在系统调用中只有sys_socketcall来统一处理所有的socket请求。实际上,sys_socketcall的实现函数通过switch来分发不同的请求,其实现在/net/socket.c中,摘录代码如下:
SYSCALL_DEFINE2(socketcall, int, call, unsigned long __user *, args) { unsigned long a[AUDITSC_ARGS]; unsigned long a0, a1; int err; unsigned int len; if (call < 1 || call > SYS_SENDMMSG) return -EINVAL; len = nargs[call]; if (len > sizeof(a)) return -EINVAL; /* copy_from_user should be SMP safe. */ if (copy_from_user(a, args, len)) return -EFAULT; err = audit_socketcall(nargs[call] / sizeof(unsigned long), a); if (err) return err; a0 = a[0]; a1 = a[1]; switch (call) { case SYS_SOCKET: err = sys_socket(a0, a1, a[2]); break; case SYS_BIND: err = sys_bind(a0, (struct sockaddr __user *)a1, a[2]); break; case SYS_CONNECT: err = sys_connect(a0, (struct sockaddr __user *)a1, a[2]); break; case SYS_LISTEN: err = sys_listen(a0, a1); break; case SYS_ACCEPT: err = sys_accept4(a0, (struct sockaddr __user *)a1, (int __user *)a[2], 0); break; case SYS_GETSOCKNAME: err = sys_getsockname(a0, (struct sockaddr __user *)a1, (int __user *)a[2]); break; case SYS_GETPEERNAME: err = sys_getpeername(a0, (struct sockaddr __user *)a1, (int __user *)a[2]); break; case SYS_SOCKETPAIR: err = sys_socketpair(a0, a1, a[2], (int __user *)a[3]); break; case SYS_SEND: err = sys_send(a0, (void __user *)a1, a[2], a[3]); break; case SYS_SENDTO: err = sys_sendto(a0, (void __user *)a1, a[2], a[3], (struct sockaddr __user *)a[4], a[5]); break; case SYS_RECV: err = sys_recv(a0, (void __user *)a1, a[2], a[3]); break; case SYS_RECVFROM: err = sys_recvfrom(a0, (void __user *)a1, a[2], a[3], (struct sockaddr __user *)a[4], (int __user *)a[5]); break; case SYS_SHUTDOWN: err = sys_shutdown(a0, a1); break; case SYS_SETSOCKOPT: err = sys_setsockopt(a0, a1, a[2], (char __user *)a[3], a[4]); break; case SYS_GETSOCKOPT: err = sys_getsockopt(a0, a1, a[2], (char __user *)a[3], (int __user *)a[4]); break; case SYS_SENDMSG: err = sys_sendmsg(a0, (struct user_msghdr __user *)a1, a[2]); break; case SYS_SENDMMSG: err = sys_sendmmsg(a0, (struct mmsghdr __user *)a1, a[2], a[3]); break; case SYS_RECVMSG: err = sys_recvmsg(a0, (struct user_msghdr __user *)a1, a[2]); break; case SYS_RECVMMSG: err = sys_recvmmsg(a0, (struct mmsghdr __user *)a1, a[2], a[3], (struct timespec __user *)a[4]); break; case SYS_ACCEPT4: err = sys_accept4(a0, (struct sockaddr __user *)a1, (int __user *)a[2], a[3]); break; default: err = -EINVAL; break; } return err; }
sock_create
在调试中我们可以看到,虽然一开始调用__sys_socket函数创建socket,但是这个函数实际上又调用了sock_create函数来负责socket的真正创建。
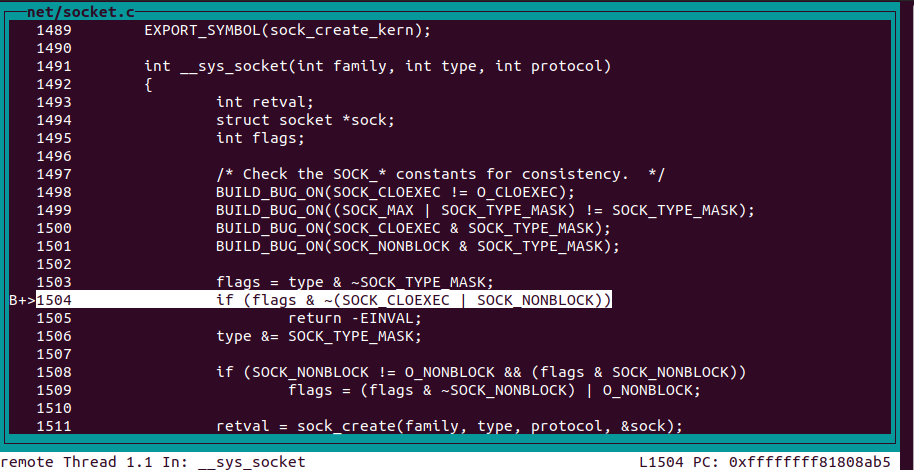

下面是sock_create函数的主要部分。
int __sock_create(struct net *net, int family, int type, int protocol, struct socket **res, int kern) { int err; struct socket *sock; const struct net_proto_family *pf; /* * Check protocol is in range */ if (family < 0 || family >= NPROTO) return -EAFNOSUPPORT; if (type < 0 || type >= SOCK_MAX) return -EINVAL; /* Compatibility. This uglymoron is moved from INET layer to here to avoid deadlock in module load. */ if (family == PF_INET && type == SOCK_PACKET) { static int warned; if (!warned) { warned = 1; pr_info("%s uses obsolete (PF_INET,SOCK_PACKET)\n", current->comm); } family = PF_PACKET; } err = security_socket_create(family, type, protocol, kern); if (err) return err; /* * Allocate the socket and allow the family to set things up. if * the protocol is 0, the family is instructed to select an appropriate * default. */ sock = sock_alloc(); if (!sock) { net_warn_ratelimited("socket: no more sockets\n"); return -ENFILE; /* Not exactly a match, but its the closest posix thing */ } sock->type = type; #ifdef CONFIG_MODULES /* Attempt to load a protocol module if the find failed. * * 12/09/1996 Marcin: But! this makes REALLY only sense, if the user * requested real, full-featured networking support upon configuration. * Otherwise module support will break! */ if (rcu_access_pointer(net_families[family]) == NULL) request_module("net-pf-%d", family); #endif rcu_read_lock(); pf = rcu_dereference(net_families[family]); err = -EAFNOSUPPORT; if (!pf) goto out_release; /* * We will call the ->create function, that possibly is in a loadable * module, so we have to bump that loadable module refcnt first. */ if (!try_module_get(pf->owner)) goto out_release; /* Now protected by module ref count */ rcu_read_unlock(); err = pf->create(net, sock, protocol, kern); if (err < 0) goto out_module_put; /* * Now to bump the refcnt of the [loadable] module that owns this * socket at sock_release time we decrement its refcnt. */ if (!try_module_get(sock->ops->owner)) goto out_module_busy; /* * Now that we're done with the ->create function, the [loadable] * module can have its refcnt decremented */ module_put(pf->owner); err = security_socket_post_create(sock, family, type, protocol, kern); if (err) goto out_sock_release; *res = sock; return 0; out_module_busy: err = -EAFNOSUPPORT; out_module_put: sock->ops = NULL; module_put(pf->owner); out_sock_release: sock_release(sock); return err; out_release: rcu_read_unlock(); goto out_sock_release; }
这里先给这个socket分配了需要的内存,然后调用net_family的create函数,针对特定的协议创建socket,并且在对应的net family中将其初始化。
__sys_sendto
虽然在声明中也有__sys_send()函数,但实际上是对 sys_sendto的封装,所以我们可以直接观察sys_sendto函数。
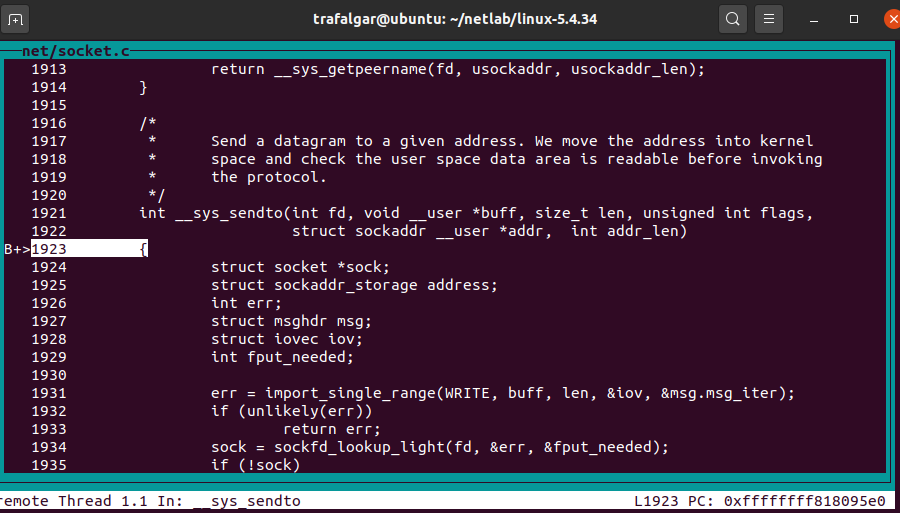
我们抽离出代码的主要逻辑
SYSCALL_DEFINE6(sendto, int, fd, void __user *, buff, size_t, len, unsigned int, flags, struct sockaddr __user *, addr, int, addr_len) { struct socket *sock; struct sockaddr_storage address; int err; struct msghdr msg; struct iovec iov; int fput_needed; err = import_single_range(WRITE, buff, len, &iov, &msg.msg_iter); if (unlikely(err)) return err; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (!sock) goto out; msg.msg_name = NULL; msg.msg_control = NULL; msg.msg_controllen = 0; msg.msg_namelen = 0; if (addr) { err = move_addr_to_kernel(addr, addr_len, &address); if (err < 0) goto out_put; msg.msg_name = (struct sockaddr *)&address; msg.msg_namelen = addr_len; } if (sock->file->f_flags & O_NONBLOCK) flags |= MSG_DONTWAIT; msg.msg_flags = flags; err = sock_sendmsg(sock, &msg); out_put: fput_light(sock->file, fput_needed); out: return err; }
这个函数主要有三个部分
-
首先根据描述符fd找到socket
-
然后将相关的信息复制到内核态
-
最后调用sock_sendmsg发送消息。
__sys_recvfrom
socket层的接受函数由__sys_recvfrom处理

recvfrom函数的主体内容如下
可以看到,和sendto的结构大致类似
-
首先根据描述符fd找到socket
-
但是由于是接收,所以要先得到信息
-
最后将相关的信息复制到用户态。
SYSCALL_DEFINE6(recvfrom, int, fd, void __user *, ubuf, size_t, size, unsigned int, flags, struct sockaddr __user *, addr, int __user *, addr_len) { struct socket *sock; struct iovec iov; struct msghdr msg; struct sockaddr_storage address; int err, err2; int fput_needed; err = import_single_range(READ, ubuf, size, &iov, &msg.msg_iter); if (unlikely(err)) return err; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (!sock) goto out; msg.msg_control = NULL; msg.msg_controllen = 0; /* Save some cycles and don't copy the address if not needed */ msg.msg_name = addr ? (struct sockaddr *)&address : NULL; /* We assume all kernel code knows the size of sockaddr_storage */ msg.msg_namelen = 0; if (sock->file->f_flags & O_NONBLOCK) flags |= MSG_DONTWAIT; err = sock_recvmsg(sock, &msg, iov_iter_count(&msg.msg_iter), flags); if (err >= 0 && addr != NULL) { err2 = move_addr_to_user(&address, msg.msg_namelen, addr, addr_len); if (err2 < 0) err = err2; } fput_light(sock->file, fput_needed); out: return err; }
传输层
传输层负责数据包的传输,TCP/IP协议栈在这一层有两种实现:TCP和UDP。我们在这里仅分析TCP的实现。TCP负责数据的发送和接收,所以也有对应的两个函数。
tcp_sendmsg
TCP使用 tcp_sendmsg来发送数据

tcp_sendmsg负责TCP的发送,下面是其主要代码
int tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size) { struct tcp_sock *tp = tcp_sk(sk); struct sk_buff *skb; int flags, err, copied = 0; int mss_now = 0, size_goal, copied_syn = 0; bool sg; long timeo; lock_sock(sk); ............. if (((1 << sk->sk_state) & ~(TCPF_ESTABLISHED | TCPF_CLOSE_WAIT)) && ! (tcp_passive_fastopen(sk)) { ............. } ............. while (--iovlen >= 0) { ............. new_segment: ............. skb = sk_stream_alloc_skb(sk, select_size(sk, sg), sk->sk_allocation); ............. skb_entail(sk, skb); } ............. wait_for_sndbuf: set_bit(SOCK_NOSPACE, &sk->sk_socket->flags); wait_for_memory: if (copied) tcp_push(sk, flags & ~MSG_MORE, mss_now, TCP_NAGLE_PUSH, size_goal); if ((err = sk_stream_wait_memory(sk, &timeo)) != 0) goto do_err; ............. out: if (copied) tcp_push(sk, flags, mss_now, tp->nonagle, size_goal); ............. do_fault: if (! skb->len) { tcp_unlink_write_queue(skb, sk); ............. } do_error: ............. out_err: .............
由于是TCP协议,所以需要计算校验和,并检查是否完成了三次握手。然后才开始正式的处理
-
遍历用户态的数据,如果有数据就复制数据到Socket Buffer
-
New Segment:如果需要新的内存存储Socket Buffer,那么需要申请内存并初始化相关的参数,然后将其加入到处理队列
-
Wait For Sndbuf:在发送缓存不够时,需要等待
-
Wait For Memory:在TCP层内存不够时,需要等待
-
Out:如果有数据在发送队列中,立即发送
-
Do Fault,Do Error,Out Error:处理出现的异常
tcp_v4_rcv
tcp层的数据接收主要在tcp_v4_rcv中进行处理
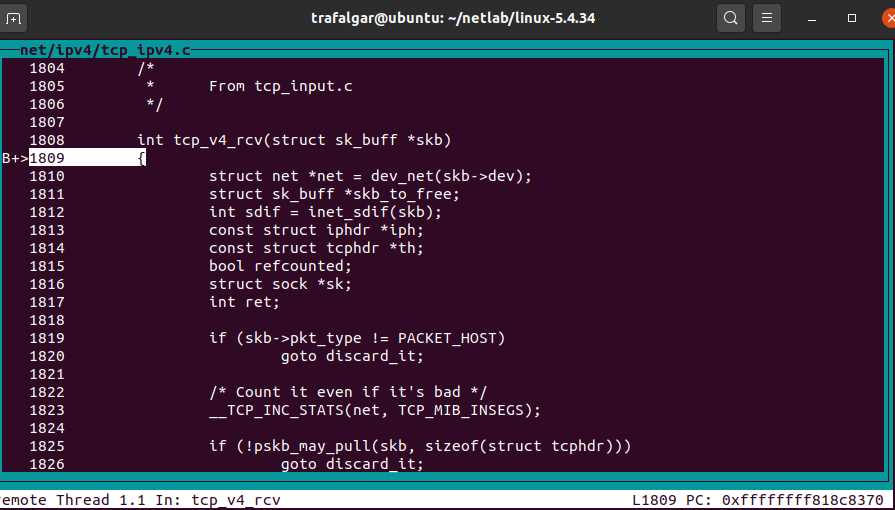
通过分析,可以摘抄出其主要代码:
int tcp_v4_rcv(struct sk_buff *skb) { struct net *net = dev_net(skb->dev); struct sk_buff *skb_to_free; int sdif = inet_sdif(skb); int dif = inet_iif(skb); const struct iphdr *iph; const struct tcphdr *th; bool refcounted; struct sock *sk; int ret; ............. if (skb_checksum_init(skb, IPPROTO_TCP, inet_compute_pseudo)) goto csum_error; ............. lookup: sk = __inet_lookup_skb(&tcp_hashinfo, skb, __tcp_hdrlen(th), th->source, th->dest, &refcounted); ............. process: if (sk->sk_state == TCP_TIME_WAIT) ............. if (sk->sk_state == TCP_NEW_SYN_RECV) ............. if (unlikely(iph->ttl < inet_sk(sk)->min_ttl)) ............. put_and_return: if (refcounted) sock_put(sk); ............. no_tcp_socket: ............. discard_it: ............. discard_and_relse: ............. do_time_wait: ............. switch (tcp_timewait_state_process(inet_twsk(sk), skb, th)) { case TCP_TW_SYN: { struct sock *sk2 = inet_lookup_listener(); ............. case TCP_TW_ACK: ............. case TCP_TW_RST: tcp_v4_send_reset(sk, skb); ............. case TCP_TW_SUCCESS:; }
-
由于是TCP,所以要先检查数据包的checksum。
-
Look Up:根据相关的信息检索socket buffer。
-
Process:根据TCP状态判断要进行什么操作,然后跳转到相应的代码段。
-
Put and Return:当这个数据包合法时,将其送入socket队列。
-
No TCP Socket:使用IPsec策略检查数据包,如果不合法,就抛弃,如果是其他情况,给另一端返回错误信息。
-
Discard和Discard and Release:这两个代码段功能类似,都是丢弃数据包。
-
Do Time Wait:处理超时的情况,并且根据当前的处理状态进行不同的处理。
网络层
输入数据包在IP层的处理
ip_rcv函数的作用是对数据包做各种合法性检查:协议头长度、协议版本、数据包长度、校验和等。 然后调用网络过滤子系统的回调函数对数据包进行安全过滤, 如果数据包通过过滤系统则调用ip_rcv_finish函数对数据包进行实际处理接口层。

ip_rcv_finish函数主要完成的任务是:
-
确定数据包是前送还是在本机协议栈中上传,如果是前送需要确定输出网络设备和下一个接收站点的地址。
-
解析和处理部分IP选项。
static int ip_rcv_finish(struct sk_buff *skb) { const struct iphdr *iph = ip_hdr(skb); struct rtable *rt; /* * 获取数据包传递的路由信息,如果 skb->dst 数据域为空,就通过路由子系统获取, * 如果 ip_route_input 返回错误信息,表明数据包目标地址不正确,扔掉数据包 */ if (skb_dst(skb) == NULL) { int err = ip_route_input_noref(skb, iph->daddr, iph->saddr, iph->tos, skb->dev); ............. } /* * 如果配置了流量控制功能,则更新QoS的统计信息 */ ............. if (unlikely(skb_dst(skb)->tclassid)) { ............. } ............. /* 在此函数中确定下一步对数据包的处理函数是哪一个,实际是调用函数指针 skb->dst->input * 函数指针的值可能为 ip_local_deliver 或 ip_forward 函数 */ return dst_input(skb); drop: kfree_skb(skb); return NET_RX_DROP; }
数据包从IP层上传至传输层
数据包从IP层上传至传输层IP层处理完成后,如果是本地数据则调用ip_local_deliver函数,此函数的作用是如果IP数据包被分片了,在这里重组数据包。 然后再次通过NF_HOOK宏进入过滤子系统,最后调用ip_local_deliver_finish函数将数据包传递给传输层相关协议。
Linux内核支持的传输层协议都实现了各自的协议处理函数(如UDP、TCP协议),然后将协议处理函数放到struct net_protocol结构体中。 最后将struct net_protocol结构体注册到inet_protos[MAX_INET_PROTOS]全局数组中, 网络层协议头中的protocol数据域描述的协议编码,就是该协议在inet_protos全局数组中的索引号。
ip_local_deliver_finish函数的主要任务是:
-
将数据包传递给正确的协议处理函数
-
将数据包传递给裸IP
............. __skb_pull(skb, ip_hdrlen(skb)); ............. rcu_read_lock(); { ............. resubmit: /* 如果有RAW socket传递给RAW socket处理 */ raw = raw_local_deliver(skb, protocol); /* 根据 protocol 在inet_protos数组中获得上层协议实例 */ hash = protocol & (MAX_INET_PROTOS - 1); ipprot = rcu_dereference(inet_protos[hash]); if (ipprot != NULL) { ............. /* 将数据包发送给上层协议 */ ret = ipprot->handler(skb); if (ret < 0) { protocol = -ret; goto resubmit; } IP_INC_STATS_BH(net, IPSTATS_MIB_INDELIVERS); } else { /* 如果获取不到上层协议实例,并且也没有RAW socket则发送ICMP端口不可达报文 */ if (!raw) { if (xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) { IP_INC_STATS_BH(net, IPSTATS_MIB_INUNKNOWNPROTOS); icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PROT_UNREACH, 0); } } else IP_INC_STATS_BH(net, IPSTATS_MIB_INDELIVERS); kfree_skb(skb); } } out: rcu_read_unlock(); return 0; }
-
Resubmit:根据数据包内容获取上层协议实例,然后将数据包发送给上层协议。如果不能我去上层协议,就发送ICMP的端口不可达信息
数据链路层和物理层
Linux 提供了一个 Network device的抽象层,将设备抽象为单纯的文件,将网络设备抽象为流文件。具体的物理网络设备在设备驱动中需要实现其实现在 linux/net/core/dev.c中的的虚函数。Network Device抽象层调用具体网络设备的函数来实现数据的发送与接收。
dev_queue_xmit

static int __dev_queue_xmit(struct sk_buff *skb, void *accel_priv) { struct net_device *dev = skb->dev; struct netdev_queue *txq; struct Qdisc *q; int rc = -ENOMEM; ............. /*此处主要是取出此netdevice的txq和txq的Qdisc,Qdisc主要用于进行拥塞处理,一般的情况下,直接将 *数据包发送给driver了,如果遇到Busy的状况,就需要进行拥塞处理了,就会用到Qdisc*/ txq = netdev_pick_tx(dev, skb, accel_priv); q = rcu_dereference_bh(txq->qdisc); ............. /*如果Qdisc有对应的enqueue规则,就会调用__dev_xmit_skb,进入带有拥塞的控制的Flow,注意这个地方,虽然是走拥塞控制的 *Flow但是并不一定非得进行enqueue操作啦,只有Busy的状况下,才会走Qdisc的enqueue/dequeue操作进行 */ if (q->enqueue) { rc = __dev_xmit_skb(skb, q, dev, txq); goto out; } /*此处是设备没有Qdisc的,实际上没有enqueue/dequeue的规则,无法进行拥塞控制的操作, *对于一些loopback/tunnel interface比较常见,判断下设备是否处于UP状态*/ if (dev->flags & IFF_UP) { int cpu = smp_processor_id(); /* ok because BHs are off */ if (txq->xmit_lock_owner != cpu) { if (__this_cpu_read(xmit_recursion) > RECURSION_LIMIT) goto recursion_alert; skb = validate_xmit_skb(skb, dev); if (!skb) goto drop; HARD_TX_LOCK(dev, txq, cpu); /*这个地方判断一下txq不是stop状态,那么就直接调用dev_hard_start_xmit函数来发送数据*/ if (!netif_xmit_stopped(txq)) { __this_cpu_inc(xmit_recursion); skb = dev_hard_start_xmit(skb, dev, txq, &rc); __this_cpu_dec(xmit_recursion); if (dev_xmit_complete(rc)) { HARD_TX_UNLOCK(dev, txq); goto out; } } HARD_TX_UNLOCK(dev, txq); net_crit_ratelimited("Virtual device %s asks to queue packet!\n", dev->name); } else { /* Recursion is detected! It is possible, * unfortunately */ recursion_alert: net_crit_ratelimited("Dead loop on virtual device %s, fix it urgently!\n", dev->name); } } rc = -ENETDOWN; drop: rcu_read_unlock_bh(); atomic_long_inc(&dev->tx_dropped); kfree_skb_list(skb); return rc; out: rcu_read_unlock_bh(); return rc; }
发送报文有2中情况:
1.有拥塞控制策略的情况,比较复杂,但是目前最常用
2.先检查是否有enqueue的规则,如果有即调用dev_xmit_skb进入拥塞控制的flow,如果没有且txq处于On的状态,那么就调用dev_hard_start_xmit直接发送到driver,好 那先分析带Qdisc策略的flow 进入__dev_xmit_skb
net_rx_action
其主要代码如下
static void net_rx_action(struct softirq_action *h) { struct list_head *list = &__get_cpu_var(softnet_data).poll_list; unsigned long time_limit = jiffies + 2; int budget = netdev_budget; void *have; ............. while (!list_empty(list)) { struct napi_struct *n; int work, weight; ............. work = 0; if (test_bit(NAPI_STATE_SCHED, &n->state)) { //对于NAPI设备如e1000驱动此处为poll为e1000_clean() 进行轮询处理数据 //对于非NAPI设备此处poll为process_backlog() 看net_dev_init()中的初始化 work = n->poll(n, weight); trace_napi_poll(n); } //返回值work需要小于等于weight work返回的是此设备处理的帧个数不能超过weight WARN_ON_ONCE(work > weight); budget -= work; //禁止本地中断 local_irq_disable(); /* Drivers must not modify the NAPI state if they * consume the entire weight. In such cases this code * still "owns" the NAPI instance and therefore can * move the instance around on the list at-will. */ //消耗完了此设备的权重 if (unlikely(work == weight)) { //若此时设备被禁止了 则从链表删除此设备 if (unlikely(napi_disable_pending(n))) { //开启本地cpu中断 local_irq_enable(); napi_complete(n); //关闭本地cpu中断 local_irq_disable(); } else//否则将设备放到链表的最后面 list_move_tail(&n->poll_list, list); } netpoll_poll_unlock(have); } out: //开启本地cpu中断 local_irq_enable(); #ifdef CONFIG_NET_DMA dma_issue_pending_all(); #endif return; softnet_break: __get_cpu_var(netdev_rx_stat).time_squeeze++; //在这里触发下一次软中断处理 __raise_softirq_irqoff(NET_RX_SOFTIRQ); goto out; }
总结
根据上述的内容,我们可以画出大致的时序图如下。

