
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/4042467.html
本文主要以mllib 1.1版本为基础,分析朴素贝叶斯的基本原理与源码
一、基本原理
理论上,概率模型分类器是一个条件概率模型。
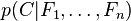
独立的类别变量 有若干类别,条件依赖于若干特征变量
有若干类别,条件依赖于若干特征变量 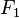 ,
, ,...,
,...,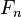 。但问题在于如果特征数量
。但问题在于如果特征数量 较大或者每个特征能取大量值时,基于概率模型列出概率表变得不现实。所以我们修改这个模型使之变得可行。 贝叶斯定理有以下式子:
较大或者每个特征能取大量值时,基于概率模型列出概率表变得不现实。所以我们修改这个模型使之变得可行。 贝叶斯定理有以下式子:
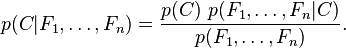
对于朴素贝叶斯,它的特征变量,,...,是相互独立的,则有
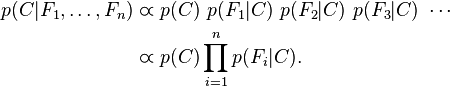
在MLlib中的朴素贝叶斯主要用于文本分类,根据上面公式则可以计算document(D)属于类别C的概率

其中:tk表示document中的词,n表示词汇总数目
在文本分类中我们的目标是找出document最有可能属于哪个类别,在朴素贝叶斯分类器就是最大后验概率的所属的那个类别Cmap

为了计算方便与避免小数,可以利用log函数![]() 将联乘变成联加
将联乘变成联加

其中: N:所有类别document总数, Nc:C类别document数目, Tct: 词k在c类别document中出现次数, n:词汇总数目


为了解决出现0的情况,通常会进行Laplace进行平滑处理

二、源码分析
NaiveBayes的实现比较简单,NaiveBayes类中的run方法实现P(c)与P(tk|c)的计算
aggregated通过combineByKey函数统计每个类别的document数Nc以及Tct
pi(i)对应公式中的p(c),只是在分子、分母中多了一些平滑因子lambda
theta(i)(j)对应公式中的P(tk|c)

得到NaiveBayesModel后,就可以用它来对新数据进行预测了,根据上面公式计算cmap找出概率最大项对应的类别就是预测值。

原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/4042467.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号