操作系统考点自我总结
数据表示
±0相同的编码是补码和移码
求反码:
- 正数:与原码一致
- 负数:除符号位,其它位取反
求补码
- 正数:与原码一致
- 负数:除符号位,其他位取反加1
求移码:将补码的符号位取反
| 码制 | 定点整数 | 定点小数 | 范围 | |
| 源码 | -(2n-1-1)~+(2n-1-1) | -(1-2-(n-1))~+(1-2-(n-1)) | 2n-1 | |
| 反码 | -(2n-1-1)~+(2n-1-1) | -(1-2-(n-1))~+(1-2-(n-1)) | 2n-1 | |
| 补码 | -2n-1~+(2n-1-1) | -1~+(1-2-(n-1)) | 2n | 适合加减运算 |
| 移码 | -2n-1~+(2n-1-1) | -1~+(1-2-(n-1)) | 2n | 适合浮点数阶码 |
海明码
校验位个数:2n+k ≥ n + k,n是数据位,k是校验位
需要哪些校验位校验
比如:D9D8D7D6D5D4P4D3D2D1P3D0P2P1
D9(位序14)有P4(位序8)、P3(位序4)、P2(位序2)校验
D5(位序10)有P4(位序8)、P2(位序2)校验
奇校验:二进制数据中1的个数是奇数,只能检测
偶校验:二进制数据中1的个数是偶数,既能检测也能纠正
校验的最小码距:2
CRC(循环冗余校验码)
采用模2除法进行校验码计算
求CRC编码,一致数据信息位1100,生成多项式位X3+X+1(1011)
- 信息码补0(多项式的最高位数是几就几个0)最高是X3,所以补三个0为1100000
- 1100000/1011=010
- CRC编码为1100000+010=1100010
浮点数
浮点数表示数的范围由阶码确定,精度由尾数确定
范围:阶码范围*精度范围
注意阶码=阶码符+阶码值
最适合表示阶码的是移码
CPU
CPU依据指令周期的不同阶段来区分在内存中的是指令(取指令)还是数据(分析和执行指令)
运算器
- 算数逻辑单元(ALU):(算术+逻辑)运算
- 累加寄存器(AC):为ALU提供工作区
- 数据缓冲寄存器(DR):暂存内存I/O的指令和数据
- 状态寄存器(PSW):保存数据处理的结果(状态标志+控制标志)
控制器
- 指令寄存器(IR):指令从DR送入IR暂存
- 程序计数器(PC):存放下一指令的地址
- 地址寄存器(AR):保存当前CPU所访问的内存地址
- 指令译码器(ID):对操作码字段分析解释
单核处理器同一时刻允许占用资源的进程数为1个
输入/输出
CPU采用程序查询方式和DMA方式时,CPU与外设可并行工作
- DMA方式:不需要CPU干涉,CPU是在一个总线周期结束时相应DMA请求的
- 无条件传送:端口总是准备好输入输出数据
- 程序查询方式:是占用CPU最多的,串行工作
- 通道控制方式:利用软件手段控制传送,免去cpu接入
在UNIX中输入输出设备被看作是特殊文件
用户进程->与设备无关的系统软件->设备驱动程序->中断处理程序
总线
- 数据总线:双向传送数据
- 地址总线:传送CPU发出的地址
- 控制总线:双向传送信号和状态信息
总线带宽=总线宽度(bit)*总线频率(MHz)÷8(bit/B)
1B=8bit
总线复用的目的是减少总线数量,提高总线利用率
指令系统
n条指令的执行时间的公式
顺序方式:(取指时间+分析时间+执行时间)*n
流水线方式:取指时间*n+分析时间+执行时间
存储系统
通用寄存器->Cache->主存储器->联机磁盘->脱机磁盘
磁盘=外存
内存=主存,主要由DRAM组成
页式存储淘汰页面号
状态位、访问位、修饰位每个位都是用1和0来表示当前状态
- 状态位为0时,不在内存,不考虑
- 访问位、修饰位按顺序找到最小的:00、01、10、11
- 找到对应的页面号,此页面号可以淘汰
缺页中断
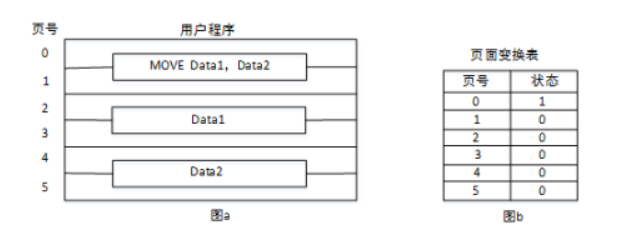
由图看出页号1~5都不在内存中,所以取数据时必须先将其置换到内存,因此总共时5次缺页中断
取指令产生1次中断,取Data1和Data2分别产生2次中断
Cache
主要由SRAM组成,命中率要在90%以上
地址映像方法:
- 直接映像:主存块与Cache块固定(速度快)
- 全相联映像:主存块任意存储到Cache块(速度慢)
- 组相联映像:主存块和Cache先分组,然后再组内任意存储(折中)
SRAM和DRAM都是可读可写的,DRAM需要定期刷新
分级存储体系是为了能得到更好的性价比
BIOS存储在ROM中
寻址
- 立即寻址:直接取出操作数本身
- 直接寻址:地址码字段给出的地址是操作数的有效地址
- 间接寻址:地址码字段给出的地址不是操作数的地址,而是主存单元的地址
逻辑地址求物理地址
- 将页面大小转成2n,单位是B
- 逻辑地址=页号+页内地址,根据页面大小和逻辑地址推出页号
- 比如页面大小4K,逻辑地址为2D16H
- 4K = 212B,D16H对应的也是12位,所以页号是2
- 物理地址=物理块号+逻辑地址
- 一般有表格显示页号与物理块号的关系
- 用物理块号拼接D16H即可
- (物理块号+1)%字长+1=位示图编号
二级索引文件长度计算
- 块号=磁盘块大小/每块所占字节(即一级索引最大块号)
- 二级索引最大块号=一级索引最大块号2
- 文件大小=二级索引最大块号*磁盘块大小
- 索引表的地址项就是逻辑块号
例子:某文件系统采用索引节点管理,某磁盘索引块和磁盘数据块大小为1KB字节且每个索引节点有8个地址项iaddr[0]~iaddr[7],每个地址项大小为4字节,其中iaddr[0]~iaddr[4]采用直接索引地址索引,iaddr[5]和iaddr[6]采用一级间接地址索引,iaddr[7]采用二级间接地址索引。若要访问文件userA中逻辑块号4和5的信息,则系统应分别采用(),该文件系统可表示的当个文件最大长度是()
因为iaddr[0]~iaddr[4]采用直接索引地址索引,逻辑块号4采用的是直接索引,有5个索引
因为iaddr[5]和iaddr[6]采用一级间接地址索引,逻辑块号5采用的是一级间接地址索引
磁盘索引块的大小是1KB,地址项大小为4字节,所以索引块中有1024/4=256个索引
一级索引有两个索引块号,索引是2*256=512个索引
二级索引只有一个索引块号,所以是256*256=65536个索引
所以文件可表示的长度为5+512+65536=66053
磁盘最短移臂调度法:
- 确认当前移动臂位于几号柱面,设为n
- 将柱面号排序,排序的依据与n的距离从小到大排
- 柱面号相同时,根据扇区从小到大排序
- 扇区相同时,根据磁头号从小到大排序
- 求平均移臂距:根据以上排号的序列,求柱面号之间的差值的总和/序列个数,注意别忘了最开始的n
进程
n个并发进程,每个进程需要m个R,保证系统不发生死锁,至少需要几个R
R = n*(m-1)+1
信号量
- 公用:初值为1或者资源数目
- 私用:初值为0或者某个正数
当有进程运行时(占用着资源),其他进程访问信号量,信号量S就会减1
- S ≥ 0:资源的可用数
- S<0:进程的阻塞数
- P操作:申请资源
- V操作:释放资源
如何判断同步信号量还是互斥信号量?
互斥:是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。但互斥无法限制访问者对资源的访问顺序,即访问是无序的。互斥量值只能为0/1
同步:是指在互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。在大多数情况下,同步已经实现了互斥,特别是所有写入资源的情况必定是互斥的。少数情况是指可以允许多个访问者同时访问资源
若P(X)信号和V(X)信号在同一进程对象上则是互斥信号,否则为同步信号
进程资源有向图
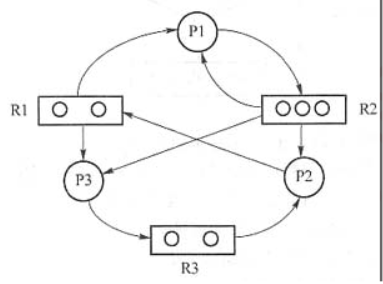
请求资源:⚪->▢
分配资源:▢->⚪
因为R1将两个资源分配给了P1和P3,R2将三个资源分配个了P1、P2、P3,所以P2再请求R1和P1再请求R2是拿不到资源的,所以P1和P2是阻塞点
而R3只分配了一个资源给P2,P3请求时,R3还有资源,所以P3不是阻塞点
该图可以化简:P3->P1->P2
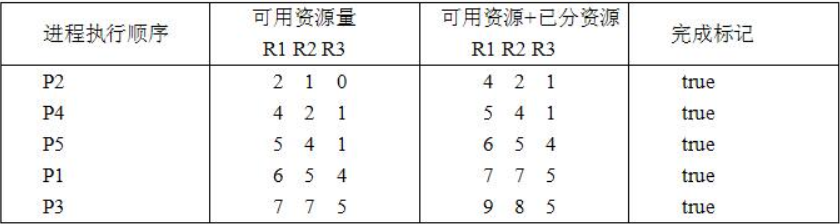
根据下表,求进程的执行序列,R1,R2,R3的资源分别是9,8,5
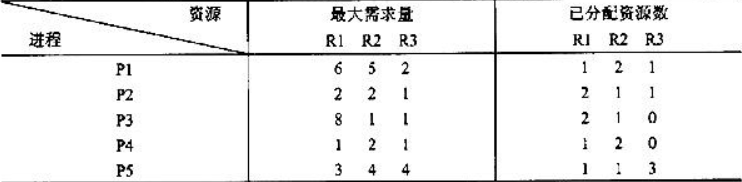
- 求剩余资源,(R1,R2,R3)-SUM(R1已分配,R2已分配,R3已分配)=(9,8,5)-(1+2+2+1+1,2+1+1+2+1,1+1+0+0+3)=(9-7,8-7,5-5)=(2,1,0)
- 求出每个进程尚需资源量
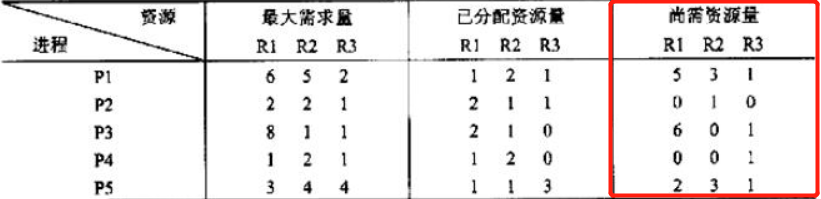
-
用剩余资源量和尚需资源量做对比,最开始P2是符合的,所以是第一个
- 用P2的已分配资源量+剩余资源量得到可用资源量,继续找下一个进程,依此类推
性能
计算机系统性能两大方面:
- 可用性(可靠性):
- 持续工作时间
- 处理效率
- 吞吐率
- 响应时间
- 资源利用率
- 可用性(可靠性):
缓冲
单缓冲:(读入缓冲区时间+缓冲区送至用户区时间)*磁盘块+处理时间
双缓冲:(读入缓冲区时间)*磁盘块+缓冲区送至用户区时间+处理时间
吞吐率计算
吞吐率=1/max{t1,t2,...tm}
流水线中n条指令的吞吐率=n/(t1+t2+...+tm)+(n-1)*max{t1,t2,...,tm}
流水线执行周期为流水线执行时间最长的一段
性能优化
数据库系统优化:
- CPU/内存使用状况
- 优化设计(查询语句性能)
- 优化管理
- 进程/线程
- 硬盘空间/日志文件大小
应用系统优化:
- 可用性
- 响应时间
- 并发用户
- 系统资源占用
媒体
图像
颜色:
- 真彩色:RGB基色分量
- 伪彩色:彩色查找表
- 直接色:RGB子域索引
- 矢量:有大小有方向
- 饱和度:颜色的纯度(鲜艳度)
- 显示深度>图像深度:全一致
- 显示深度=图像深度:不一致时,出现失真
- 显示深度<图像深度:全失真
声音
- 音调:振动频率
- 音高:振动幅度
- 语音信号最高频率4KHZ,数字语音采样频率8KHZ
MPEG标准
- MPEG-1->VCD,编码技术
- MPEG-2->DVD,编码技术
- MPEG-4->编码技术
- MPEG-7->多媒体内容描述接口
- MPEG-21->多媒体应用框架
程序语言
- 编译程序:源程序翻译成目标程序
- 信息存入符号表(标识符+属性)
- 编译正确的程序可以消除词法及语法错误,但不能完全消除语义错误
- 解释程序:直接解释或翻译成中间代码,不生成独立的目标程序
移进规约分析法:(自底向上)
- 词法分析:识别单词符号,过滤注释,查不出拼错的保留字
- 语法分析:接收以单词为单位的输入,分析语法规则是否符合
- 语义分析:分析语法结构的含义,检查是否存在静态语义错误(动态语义错误在运行时发现)
- 中间代码生成:可没有
- 代码优化:可没有
- 目标代码生成:分配寄存器的工作在此进行
语法制导翻译是静态语义分析
高级语言源程序通过编译或解释方式进行翻译时,可先生成与源程序等价的中间代码(一般是后缀是和三地址码)
基本上是上下文无关文法
数据空间采用堆存储分配策略
中间代码表示方式:逆波兰,四元式,三元式,树
LR分析法中:LR(0)是最弱的,LR(1)是最强的
C++运行过程:预处理->编译->汇编->全链接
其他
冗余(储备)技术,利用系统的并联模型来提高系统可靠性。包括
- 冗余备份的存储及调用
- 实现纠错检测及恢复的数据
- 实现容错软件所需的固化程序
计算机按指令系统架构区分:
- CISC(复杂指令集计算机):可以直接对主存单元的数据进行处理,寄存器数量在32个以内
- RISC(精简指令集计算机):指令数量少,寻址少,以硬布线逻辑控制为主,寄存器数量在32个以上
注意函数的调用时值调用还是引用调用
- 引用调用:传的是地址,函数内变化,函数外也跟着变
- 值调用:只在函数内变
Flynn分类法:(I:指令流,D:数据流)
- SISD、SIMD(通过资源重复实现并行性)、MISD、MIMD
- GPU是SIMD架构
- MISD只有理论意义而无实例
微程序一般由硬件执行
二进制数据中1的个数是奇数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号