Python爬虫
一、环境配置
Python+pip 的安装
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
请求库:urllib,requests,selenium,scrapy解析库:beautifulsoup4,pyquery,lxml,scrapy,re数据库:redis,pymysql,pymongoMongoDB的安装和配置+robot 3t (27017)Redis 的安装和配置 +RedisDesktopManager (6379)Mysql的安装和配置 + Navicat for mysql (3306)pip install requests selenium beautifulsoup4 pyquery pymysql pymongo redis flask django jupyter |
二、爬虫基本原理
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
爬虫基本流程
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
1:向服务器发起请求通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器的响应。2:获取响应内容 如果服务器正常响应,会得到一个Response,Response的内容便是所要获取的页面内容,类型可能有HTML、JSON、二进制文件(如图片、视频等类型)。 3:解析内容 得到的内容可能是HTML,可以用正则表达式、网页解析库进行解析。可能是JSON,可以直接转成JOSN对象进行解析,可能是二进制数据,可以保存或者进一步处理 4:保存内容 保存形式多样,可以保存成文本,也可以保存至数据库,或者保存成特定格式的文件。 |
requests和response

Request中包含哪些内容?
- 1:请求方式
主要是GET、POST两种类型,另外还有HEAD、PUT、DELETE、OPTIONS等。
- 2:请求URL
URL全称是统一资源定位符,如一个网页文档、一张图片、一个视频等都可以用URL来唯一来确定
- 3:请求头
包含请求时的头部信息,如User-Agent、Host、Cookies等信息
- 4:请求体
请求时额外携带的数据,如表单提交时的表单数据
Response中包含哪些内容?
- 1:响应状态
有多种响应状态,如200代表成功,301代表跳转,404代表找不到页面,502代表服务器错误等
- 2:响应头
如内容类型、内容长度、服务器信息、设置cookies等等
- 3:响应体
最主要的部分,包含了请求资源的内容,如网页HTML、图片二进制数据等。
实例代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
from fake_useragent import UserAgentimport requestsua=UserAgent()#请求的网址url="http://www.baidu.com"#请求头headers={"User-Agent":ua.random}#请求网址response=requests.get(url=url,headers=headers)#响应体内容print(response.text)#响应状态信息print(response.status_code)#响应头信息print(response.headers) |


- 请求和响应:
- 请求:
"GET /index http1.1\r\nhost:c1.com\r\nContent-type:asdf\r\nUser-Agent:aa\r\nreferer:www.xx.com;cookie:k1=v1;k2=v2;\r\n\r\n"
- 响应:
"HTTP/1.1 200 \r\nSet-Cookies:k1=v1;k2=v2,Connection:Keep-Alive\r\nContent-Encoding:gzip\r\n\r\n<html>asdfasdfasdfasdfdf</html>"
- 携带常见请求头
- user-agent
- referer
- host
- content-type
- cookie
- csrf
- 原因1:
- 需要浏览器+爬虫先访问登录页面,获取token,然后再携带token去访问。
- 原因2:
- 两个tab打开的同时,其中一个tab诱导你对另外一个tab提交非法数据。
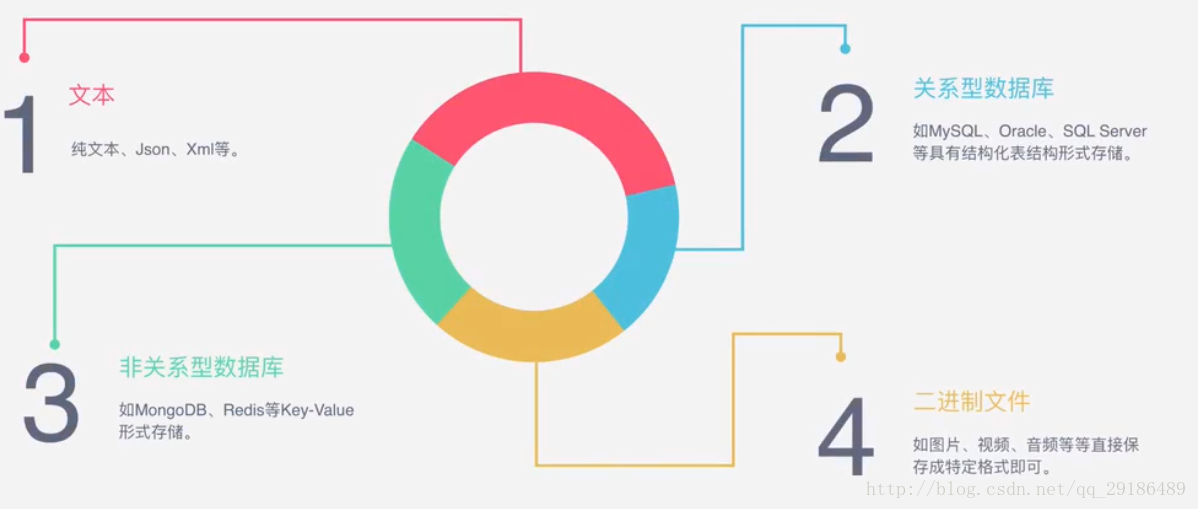
能抓到怎样的数据?
- 1:网页文本
如HTML文档、JSON格式文本等
- 2:图片文件
获取的是二进制文件,保存为图片格式
- 3:视频
同为二进制文件,保存为视频格式即可
- 4:其他
只要能够请求到的,都能够获取到
import requests
#下载百度的LOGO
response=requests.get("https://www.baidu.com/img/bd_logo1.png")
with open("1.jpg","wb") as f:
f.write(response.content)
f.close()
解析方式

为什么我们抓到的有时候和浏览器看到的不一样?
有时候,网页返回是JS动态加载的,直接用请求库访问获取到的是JS代码,不是渲染后的结果。

怎样保存数据?
好了,有了这些基础知识以后,就开始咱们的学习之旅吧!
三、urllib- 内置请求库

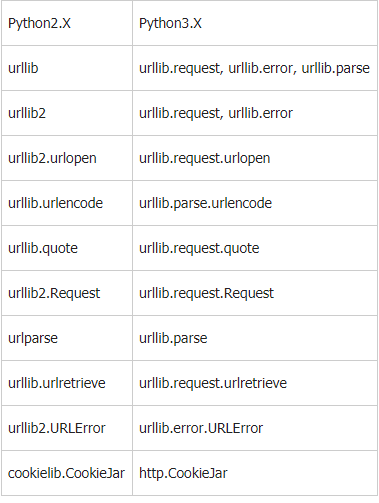
urllib库对照速查表
1.请求

urllib.request.urlopen(url.data=None,[timeout,]*cafile=None,capath=None,cadefault=False,context=None)
In [1]: import urllib.request
In [2]: response = urllib.request.urlopen('http://www.baidu.com')
In [3]: print(response.read().decode('utf-8'))
import urllib.parse
import urllib.request
data = bytes(urllib.parse.urlencode({'world':'hello'}),encoding='utf8')
response = urllib.request.urlopen('http://httpbin.org/post',data=data)
print(response.read())
import urllib.request
response = urllib.request.urlopen('http://httpbin.org/get',timeout=1)
print(response.read())
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://httpbin.org/get',timeout=0.1)
except urllib.error.URLError as e:
if isinstance(e.reason,socket.timeout):
print('TIME OUT')
In [38]: urllib.request.quote('张亚飞')
Out[38]: '%E5%BC%A0%E4%BA%9A%E9%A3%9E'
In [39]: urllib.request.quote('zhang')
Out[39]: 'zhang'
urllib.request.urlretrieve(url)
In [41]: urllib.request.urljoin('http://www.zhipin.com',"/job_detail/a53756b0e6
...: 5b7a5f1HR_39m0GFI~.html")
Out[41]: 'http://www.zhipin.com/job_detail/a53756b0e65b7a5f1HR_39m0GFI~.html'
2.响应
In [1]: import urllib.request
In [2]: response = urllib.request.urlopen('https://pytorch.org/')
In [3]: response.__class__
Out[3]: http.client.HTTPResponse
3.状态码
HTTP状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型,后两个数字没有分类的作用。HTTP状态码共分为5种类型

更详细的信息请点击 http://www.runoob.com/http/http-status-codes.html
In [1]: import urllib.request
In [2]: response = urllib.request.urlopen('https://pytorch.org/')
In [3]: response.__class__
Out[3]: http.client.HTTPResponse
In [4]: response.status
Out[4]: 200
In [6]: response.getheaders()
Out[6]:
[('Server', 'GitHub.com'),
('Content-Type', 'text/html; charset=utf-8'),
('Last-Modified', 'Sat, 15 Dec 2018 19:40:33 GMT'),
('ETag', '"5c1558b1-6e22"'),
('Access-Control-Allow-Origin', '*'),
('Expires', 'Sun, 16 Dec 2018 12:10:41 GMT'),
('Cache-Control', 'max-age=600'),
('X-GitHub-Request-Id', 'D0E4:46D5:2655CC0:2F6CE98:5C163E69'),
('Content-Length', '28194'),
('Accept-Ranges', 'bytes'),
('Date', 'Sun, 16 Dec 2018 12:00:42 GMT'),
('Via', '1.1 varnish'),
('Age', '0'),
('Connection', 'close'),
('X-Served-By', 'cache-hkg17924-HKG'),
('X-Cache', 'MISS'),
('X-Cache-Hits', '0'),
('X-Timer', 'S1544961642.791954,VS0,VE406'),
('Vary', 'Accept-Encoding'),
('X-Fastly-Request-ID', '7fdcbfe552a9b6f694339f8870b448184e60b210')]
In [8]: response.getheader('server')
Out[8]: 'GitHub.com'
In [15]: from urllib.parse import urlencode
In [16]: data = urlencode({'username':'zhangyafei','password':123455678})
In [17]: data
Out[17]: 'username=zhangyafei&password=123455678'
In [18]: data.encode('utf-8')
Out[18]: b'username=zhangyafei&password=123455678'
In [19]: headers = {'User-Agent':ua.random}
In [25]: data = data.encode('utf-8')
In [27]: req = urllib.request.Request(url='http://httpbin.org/post',data=data,headers=headers,method='POST')
In [28]: response = urllib.request.urlopen(req)
In [29]: response.read().decode('utf-8')
Out[29]: '{\n "args": {}, \n "data": "", \n "files": {}, \n "form": {\n "
password": "123455678", \n "username": "zhangyafei"\n }, \n "headers": {\n
"Accept-Encoding": "identity", \n "Connection": "close", \n "Content-Le
ngth": "38", \n "Content-Type": "application/x-www-form-urlencoded", \n "H
ost": "httpbin.org", \n "User-Agent": "Mozilla/5.0 (Windows NT 6.2) AppleWebK
it/537.36 (KHTML, like Gecko) Chrome/28.0.1467.0 Safari/537.36"\n }, \n "json"
: null, \n "origin": "111.53.196.6", \n "url": "http://httpbin.org/post"\n}\n'
添加报头 req.add_header(headers)
4.Handler代理
import urllib.request
proxy_handler = urllib.request.ProxyHandler({
'http':'http://127.0.0.1:9743',
'https':'https://127.0.0.1:9743'
})
opener = urllib.request.build_opener(proxy_handler)
response = opener.open('http://httpbin.org/get')
print(response.read())
5.Cookie
import http.cookiejar,urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
for item in cookie:
print(item.name+"="+item.value)
import http.cookiejar,urllib.request
filename = "cookie.txt"
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True,ignore_expires=True)
6.异常处理
from urllib import request,error
try:
response = request.urlopen('http://cuiqingcai.com/index.html')
except error.URLError as e:
print(e.reason)
from urllib import request,error
try:
response = request.urlopen('http://cuiqingcai.com/index.html')
except error.HTTPError as e:
print(e.reason,e.code,e.headers,sep='\n')
except error.URLError as e:
print(e.reason)
else:
print('Request successfully')
7.url解析
In [31]: from urllib.parse import urlparse
In [32]: result=urlparse('http://www.baidu.com/index.html;user?id=5#comment',sc
...: heme='https',allow_fragments=False)
In [33]: result
Out[33]: ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html',
params='user', query='id=5#comment', fragment='')
urllib.parse.rlunparse
from urllib.parse import urljoin
print(urljoin('http://www.baidu.com','FAQ.html'))
http://www.baidu.com/FAQ.html
print(urljoin('http://www.baidu.com/about.html','https://cuiqingcai.com/FAQ.html'))
https://cuiqingcai.com/FAQ.html
print(urljoin('www.baidu.com?wd=abc','https://cuiqingcai.com/index.php '))
https://cuiqingcai.com/index.php
print(urljoin('www.baidu.com','?category=2#comment'))
www.baidu.com?category=2#comment
print('www.baidu.com#comment','?category=2')
www.baidu.com#comment ?category=2
from urllib.parse import urljoin
print(urljoin('http://www.baidu.com','FAQ.html'))
http://www.baidu.com/FAQ.html
print(urljoin('http://www.baidu.com/about.html','https://cuiqingcai.com/FAQ.html'))
https://cuiqingcai.com/FAQ.html
print(urljoin('www.baidu.com?wd=abc','https://cuiqingcai.com/index.php '))
https://cuiqingcai.com/index.php
print(urljoin('www.baidu.com','?category=2#comment'))
www.baidu.com?category=2#comment
print('www.baidu.com#comment','?category=2')
www.baidu.com#comment ?category=2
案例:抓取贴吧图片
# -*- coding: utf-8 -*-
"""
Created on Sat Jul 28 19:54:15 2018
@author: Zhang Yafei
"""
import urllib.request
import re
import time
import os
import pymongo
import requests
client = pymongo.MongoClient('localhost')
DB = client['tieba_img']
MONGO_TABLE = 'IMGS'
def spider():
url = "https://tieba.baidu.com/p/1879660227"
req = urllib.request.Request(url)
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
imgre = re.compile(r'src="(.*?.jpg)" pic_ext',re.S)
imglist = re.findall(imgre,html)
return imglist
def download(imglist):
rootdir = os.path.dirname(__file__)+'/download/images'
#os.mkdir(os.getcwd()+'/download/images')
if not os.path.exists(rootdir):
os.mkdir(rootdir)
x = 1
for img_url in imglist:
print("正在下载第{}张图片".format(x))
try:
urllib.request.urlretrieve(img_url,rootdir+'\\{}.jpg'.format(x))
print("第{}张图片下载成功!".format(x))
except Exception as e:
print('第{}张图片下载失败'.format(x),e)
finally:
x += 1
time.sleep(1)
print('下载完成')
def download2(imglist):
x = 0
for url in imglist:
x += 1
print('正在下载第{}个图片'.format(x))
try:
response = requests.get(url)
save_image(response.content,x)
except Exception as e:
print('请求图片错误!',e)
print('下载完成')
def save_image(content,x):
file_path = '{0}/download/images1/{1}.{2}'.format(os.path.dirname(__file__),x,'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
if f.write(content):
print('下载第{}个图片成功'.format(x))
else:
print('下载第{}个图片失败'.format(x))
f.close()
else:
print('此图片已下载')
def save_to_mongo(imglist):
for url in imglist:
imgs = {'img_url':url}
if DB[MONGO_TABLE].insert_one(imgs):
print('存储到mongo_db数据库成功!')
else:
print('存储到mongo_db数据库失败!')
def main():
imglist = spider()
download(imglist)
save_to_mongo(imglist)
# download2(imglist)
if __name__ == "__main__":
main()
四、requests
实例引入
|
1
2
3
4
5
6
7
|
import requestsresponse = requests.get('http://www.baidu.com/')print(type(response))print(response.status_code)print(response.text)print(type(response.text))print(response.cookies) |
<class 'requests.models.Response'>
200
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-。。。
<class 'str'>
<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
1,.请求
import requests
requests.post('http://www.httpbin.org/post')
requests.put('http://www.httpbin.org/put')
requests.delete('http://www.httpbin.org/delete')
requests.head('http://www.httpbin.org/get')
requests.options('http://www.httpbin.org/get')
# 基本get请求
import requests
response = requests.get('http://www.httpbin.org/get')
print(response.text)
#带参数的get请求
import requests
data ={
'name':'germey',
'age':22
}
response = requests.get('http://www.httpbin.org/get',params=data)
print(response.text)
解析json
import requests,json
response = requests.get('http://www.httpbin.org/get')
print(type(response.text))
print(response.text)
print(response.json())
print(json.loads(response.text))
添加headers
import requests
response = requests.get('https://www.zhihu.com/explore')
print(response.text)
import requests
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
response = requests.get('https://www.zhihu.com/explore',headers=headers)
print(response.text)
获取二进制数据
import requests
response = requests.get('https://github.com/favicon.ico')
print(type(response.text),type(response.content))
print(response.content)
print(response.text)
import requests
response = requests.get('https://github.com/favicon.ico')
with open('.\images\logo.gif','wb') as f:
f.write(response.content)
f.close()
基本post请求
import requests
data = {'name':'kobe','age':'23'}
response = requests.post('http://www.httpbin.org/post',data=data)
print(response.text)
# post方式
import requests
data = {'name':'kobe','age':'23'}
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Mobile Safari/537.36'
}
response = requests.post('http://www.httpbin.org/post',data=data,headers=headers)
print(response.json())
2.响应
import requests
response= requests.get('http://www.jianshu.com')
response.encoding = response.apparent_encoding
print(type(response.status_code),response.status_code)
print(type(response.headers),response.headers)
print(type(response.cookies),response.cookies)
print(type(response.url),response.url)
print(type(response.history),response.history)
import requests
response = requests.get('http://www.jianshu.com')
exit()if not response.status_code == requests.codes.ok else print('requests succfully')
import requests
response = requests.get('http://www.jianshu.com')
exit() if not response.status_code == 200 else print('requests succfully')
3.高级操作
import requests
files = {'file':open('images/logo.gif','rb')}
response = requests.post('http://www.httpbin.org/post',files=files)
print(response.text)
import requests
response = requests.get('http://www.baidu.com')
print(response.cookies)
for key,value in response.cookies.items():
print(key+'='+value)
import requests
requests.get('http://www.httpbin.org/cookies/set/number/123456789')
response = requests.get('http://www.httpbin.org/cookies')
print(response.text)
import requests
s = requests.Session()
s.get('http://www.httpbin.org/cookies/set/number/123456789')
response = s.get('http://www.httpbin.org/cookies')
print(response.text)
import requests
response = requests.get('https://www.12306.cn')
print(response.status_code)
import requests
from requests.packages import urllib3
urllib3.disable_warnings()
response = requests.get('https://www.12306.cn',verify=False)
print(response.status_code)
import requests
response = requests.get('https://www.12306.cn',cert=)
print(response.status_code)
import requests
proxies = {
'http':'http://101.236.35.98:8866',
'https':'https://14.118.254.153:6666',
}
response = requests.get('https://www.taobao.com',proxies=proxies)
print(response.status_code)
import requests
response = requests.get('https://www.taobao.com',timeout=1)
print(response.status_code)
import requests
from requests.exceptions import ReadTimeout
try:
response = requests.get('http://www.httpbin.org',timeout=0.1)
print(response.status_code)
except:
print('TIME OUT')
import requests
from requests.exceptions import Timeout
from requests.auth import HTTPBasicAuth
try:
response = requests.get('http://120.27.34.24:9001',auth=HTTPBasicAuth('user','123'))
print(response.status_code)
except Timeout:
print('time out')
import requests
response = requests.get('http://120.27.34.24:9001',auth=('user','123'))
print(response.status_code)
import requests
from requests.exceptions import ReadTimeout,HTTPError,ConnectionError,RequestException
try:
response = requests.get('http://www.httpbin.org/get',timeout=0.5)
print(response.status_code)
except ReadTimeout:
print('TIME OUT')
except ConnectionError:
print('Connect error')
except RequestException:
五、正则表达式
1.re.match
1.re.match
re.match尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none.
Re.match(pattern,string,flags=0)
最常规的匹配
import re
content = ‘Hello 123 4567 World_This is a Regex Demo’
泛匹配
import re
content = 'Hello 123 4567 World_This is a Regex Demo'
result = re.match('^Hello.*Demo$',content)
print(result)
print(result.group())
print(result.span())
匹配目标
import re
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^Hello\s(\d+)\sWorld.*Demo$',content)
print(result)
print(result.group(1))
print(result.span())
贪婪匹配
import re
content = 'Hello 123 4567 World_This is a Regex Demo'
result = re.match('^He.*(\d+).*Demo$',content)
print(result)
print(result.group(1))
print(result.span())
非贪婪匹配
import re
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^He.*?(\d+).*Demo$',content)
print(result)
print(result.group(1))
print(result.span())
匹配模式
import re
content = """Hello 1234567 World_This
is a Regex Demo"""
result = re.match('^He.*?(\d+).*?Demo$',content,re.S)
print(result.group(1))
转义
import re
content = 'price is $5.00'
result = re.match('^price is \$5\.00$',content)
print(result)
2.re,search()
re.search
re.search扫描整个字符串,然后返回第一个成功的匹配
import re
content = 'Extra strings Hello 1234567 World_This is a Regex Demo Extra strings'
result = re.search('Hello.*?(\d+).*Demo',content)
print(result.groups()) print(result.group(1))
总结:为匹配方便,能用re.rearch就不用re.match
3.re.findall(pattern, string, flags=0)
regular_v1 = re.findall(r"docs","https://docs.python.org/3/whatsnew/3.6.html")
print (regular_v1)
# ['docs']
regular_v9 = re.findall(r"\W","https://docs.python.org/3/whatsnew/3.6.html")print (regular_v9)# [':', '/', '/', '.', '.', '/', '/', '/', '.', '.']4.re.sub(substr,new_str,content)
re.sub
替换字符串中每一个匹配的字符串后返回匹配的字符串
import re
content = 'Extra strings Hello 1234567 World_This is a Regex Demo Extra strings'
result = re.sub('\d+','',content)
print(result)
import re
content = 'Extra strings Hello 1234567 World_This is a Regex Demo Extra strings'
result = re.sub('\d+','replacement',content)
print(result)
import re
content = 'Extra strings Hello 1234567 World_This is a Regex Demo Extra strings'
result = re.sub('(\d+)',r'\1 8901',content)
print(result)
5.re.compile(pattern,re.S)
re.compile
import re
content = '''Hello 1234567 World_This
is a Regex Demo'''
pattern = re.compile('^He.*Demo',re.S)
result = re.match(pattern,content)
result1 = re.match('He.*Demo',content,re.S)
print(result)
print(result1)
# 实例:爬取豆瓣读书
import requests
import re
content = requests.get('https://book.douban.com/').text
pattern=re.compile('<li.*?cover.*?href="(.*?)".*?title="(.*?)".*?more-meta.*?author>(.*?)</span>.*?year>(.*?)</span>.*?publisher>(.*?)</span>.*?abstract(.*?)</p>.*?</li>',re.S)
results = re.findall(pattern,content)
for result in results:
url,name,author,year,publisher,abstract=result
name = re.sub('\s','',name)
author = re.sub('\s', '', author)
year = re.sub('\s', '', year)
publisher = re.sub('\s', '', publisher)
print(url,name,author,year,publisher,abstract)
六、BeautifulSoup
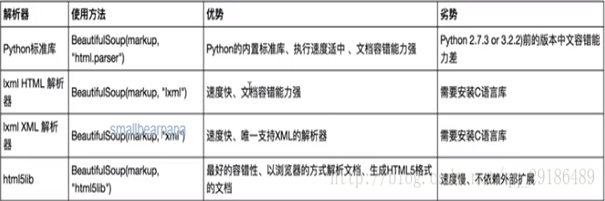
解析库
1.基本使用
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
print(soup.prettify())
print(soup.title.string)
2.选择器
标签选择器
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
print(soup.title)
print(type(soup.title))
print(soup.head)
print(soup.p)
获取名称
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
print(soup.title.name)
获取属性
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
print(soup.p.attrs['class'])
print(soup.p['class'])
获取内容
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
print(soup.title.string)
嵌套选择
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
print(soup.head.title.string)
子节点和子孙节点
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
print(soup.div.contents)
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
print(soup.div.children)
for i,child in enumerate(soup.div.children):
print(i,child)
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
print(soup.div.descendants)
for i,child in enumerate(soup.div.descendants):
print(i,child)
父节点和祖先节点
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
print(soup.p.parent)
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
print(list(enumerate(soup.p.parents)))
兄弟节点
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
print(list(enumerate(soup.p.next_siblings)))
print(list(enumerate(soup.p.previous_siblings)))
标准选择器
find_all(name,attrs,recursive,text,**kwargs)
可根据标签名,属性,内容查找文档
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
print(soup.find_all('p'))
print(type(soup.find_all('p')[0]))
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
for div in soup.find_all('div'):
print(div.find_all('p'))
attrs
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
print(soup.find_all(attrs={'id':'app'}))
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
print(soup.find_all(id='app'))
print(soup.find_all(class_='wb-item'))
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
print(soup.find_all(text='赞'))
find(name,attrs,recursive,text,**kwagrs)
find返回单个元素,find_all返回所有元素
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
print(soup.find('p'))
print(type(soup.find('p')))
find_parents() 和find_parent()
find_next_siblings()和find_next_silbing()
find_previous_siblings()和find_previous_sibling()
find_all_next()和find_next()
find_all_previous()和find_previous()
css选择器
通过select()直接传给选择器即可完成传值
ID选择器,标签选择器,类选择器
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
print(soup.select('#app'))
print(soup.select('p'))
print(soup.select('.surl-text'))
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
divs = soup.select('div')
for div in divs:
print(div.select('p'))
获取属性
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
for div in soup.select('div'):
print(div['class'])
print(div.attrs['class'])
获取内容
from bs4 import BeautifulSoup
import requests
r = requests.get('https://m.weibo.cn')
soup = BeautifulSoup(r.text,'lxml')
for div in soup.select('div'):
print(div.get_text())
总结: 1.推介使用lxml解析器,必要时选择html.parser
2.标签选择功能弱但是速度快
3.建议使用find和find_all查询选择单个或多个结果
4.如果对css选择器熟悉使用select()
5.记住常用的获取属性和文本值的方法
七、Pyquery
强大又灵活的网页解析库,如果你嫌正则太麻烦,beautifulsoup语法太难记,又熟悉jQuery,pyquery是最好的选择
1,.初始化
字符串初始化
from pyquery import PyQuery as pq
import requests
html = requests.get('https://www.taobao.com')
doc = pq(html.text)
print(doc('a'))
url初始化
from pyquery import PyQuery as pq
doc = pq(url='https://www.baidu.com')
print(doc('head'))
文件初始化
from pyquery import PyQuery as pq
doc = pq(filename='weibo.html')
print(doc('li'))
2.基本css选择器
from pyquery import PyQuery as pq
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Mobile Safari/537.36'
}
doc = pq(url='https://www.baidu.com',headers=headers)
print(doc('a'))
3.查找元素
子元素
from pyquery import PyQuery as pq
import requests
html = requests.get('https://www.taobao.com')
doc = pq(html.text)
items = doc('.nav-bd')
print(items)
li = items.find('li')
print(type(li))
print(li)
lis = items.children()
print(type(lis))
print(lis)
lis = items.children('.active')
print(type(lis))
print(lis)
父元素
from pyquery import PyQuery as pq
import requests
html = requests.get('https://www.baidu.com')
doc = pq(html.text)
print(doc)
items = doc('.pipe')
parent = items.parent()
print(type(parent))
print(parent)
from pyquery import PyQuery as pq
import requests
html = requests.get('https://www.taobao.com')
doc = pq(html.text)
items = doc('.pipe')
parents = items.parents()
print(type(parents))
print(parents)
兄弟元素
li = doc('.nav-bd .pipe')
print(li.siblings())
print(li.siblings('.active'))
4.遍历
from pyquery import PyQuery as pq
import requests
html = requests.get('https://www.taobao.com')
doc = pq(html.text)
lis = doc('.pipe').items()
print(lis)
for li in lis:
print(li)
5.获取信息
获取属性
from pyquery import PyQuery as pq
import requests
html = requests.get('https://www.taobao.com')
doc = pq(html.text)
a = doc('a')
print(a)
for a1 in a.items():
print(a1.attr('href'))
print(a1.attr.href)
获取文本
from pyquery import PyQuery as pq
import requests
html = requests.get('https://www.taobao.com')
doc = pq(html.text)
items = doc('.nav-bd')
print(items.text())
获取html
from pyquery import PyQuery as pq
import requests
html = requests.get('https://www.taobao.com')
doc = pq(html.text)
items = doc('.nav-bd')
print(items)
print(items.html())
6.dom操作
addclass,removeclass
from pyquery import PyQuery as pq
import requests
html = requests.get('https://www.taobao.com')
doc = pq(html.text)
li = doc('.nav-bd .active')
li.removeClass('.active')
print(li)
li.addClass('.active')
print(li)
attr,css
from pyquery import PyQuery as pq
import requests
html = requests.get('https://www.taobao.com')
doc = pq(html.text)
lis = doc('.nav-bd li')
lis.attr('name','link')
print(lis)
lis.css('font','14px')
print(lis)
remove
from pyquery import PyQuery as pq
import requests
html = requests.get('https://www.taobao.com')
doc = pq(html.text)
items = doc('.nav-bd a')
print(items.text())
items.find('p').remove()
print(items.text())
其他dom方法
http://pyquery.readthedocs.io/en/latest/api.html
其它伪类选择器
http://jquery.cuishifeng.cn
八、Selenium
自动化测试工具,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题
1.基本使用
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('kw')
input.send_keys('Python')
input.send_keys(Keys.ENTER)
wait = WebDriverWait(browser,10)
wait.until(EC.presence_of_element_located((By.ID,'content_left')))
print(browser.current_url)
print(browser.get_cookies)
print(browser.page_source)
finally:
browser.close()
2.声明浏览器对象
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.PhantomJS()
browser = webdriver.Edge()
browser = webdriver.Safari()
3.访问页面
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
print(browser.page_source)
browser.close()
4.查找元素
单个元素
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element_by_id('q')
input_second = browser.find_element_by_css_selector('#q')
input_third = browser.find_element_by_xpath('//*[@id="q"]')
print(input_first,input_second,input_third)
browser.close()
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_css_selector
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
input_first = browser.find_element(By.ID,'kw')
print(input_first)
browser.close()
多个元素
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
lis = browser.find_elements(By.CSS_SELECTOR,'.service-bd li')
print(lis)
browser.close()
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
lis = browser.find_elements_by_css_selector('.service-bd li')
print(lis)
browser.close()
find_elements_by_id
find_elements_by_name
find_elements_by_xpath
find_elements_by_css_selector
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
5.元素交互操作
对元素进行获取的操作
交互操作
将动作附加到动作链中串行执行
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to_frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
target = browser.find_element_by_css_selector('#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source,target)
actions.perform()
执行JavaScript
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
browser.execute_script('alert("to button")')
获取元素信息
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = "https://www.zhihu.com/explore"
browser.get(url)
logo = browser.find_element_by_id('zh-top-link-logo')
print(logo)
print(logo.get_attribute('class'))
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = "https://www.zhihu.com/explore"
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.text)
print(input.id)
print(input.location)
print(input.tag_name)
print(input.size)
frame
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
print(source)
try:
logo = browser.find_element_by_class_name('logo')
except Exception as e:
print(e)
browser.switch_to.parent_frame()
logo = browser.find_element_by_class_name('logo')
print(logo)
print(logo.text)
6.等待
隐式等待
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait(10)
browser.get('https://www.zhihu.com/explore')
input = browser.find_element_by_class_name('zu-top-add-question')
print(input)
browser.close()
显式等待
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get('https://www.taobao.com/')
wait = WebDriverWait(browser,10)
input = wait.until(EC.presence_of_element_located((By.ID,'q')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'.btn-search')))
print(input,button)
browser.close()
7.前进后退
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com/')
browser.get('https://www.taobao.com/')
browser.get('https://www.python.org/')
browser.back()
time.sleep(1)
browser.forward()
browser.close()
8.选项卡管理
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles)
browser.switch_to_window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to_window(browser.window_handles[0])
browser.get('https://www.python.org')
print(browser.page_source)
9.cookies
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
print(browser.get_cookies())
browser.add_cookie({'name':'name','domian':'www.zhihu.com','value':'kobe'})
print(browser.get_cookies())
browser.delete_all_cookies()
print(browser.get_cookies())
browser.close()
10.异常处理
from selenium import webdriver
from selenium.common.exceptions import TimeoutException,NoSuchElementException
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
except TimeoutException:
print('TIME OUT')
try:
browser.find_element_by_id('hello')
except NoSuchElementException:
print('No Element')
finally:
browser.close()
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 31 16:41:13 2018
@author: Zhang Yafei
"""
from selenium import webdriver
import time
import selenium.webdriver.support.ui as ui
from selenium.webdriver import ActionChains
from selenium.common.exceptions import UnexpectedAlertPresentException
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
#1.登录淘宝
#browser.find_element_by_xpath('//li[@id="J_SiteNavLogin"]/div[1]/div[1]/a[1]').click()
#browser.find_element_by_xpath('//div[@id="J_QRCodeLogin"]/div[5]/a[1]').click()
#browser.find_element_by_name('TPL_username').send_keys('15735177116')
#browser.find_element_by_name('TPL_password').send_keys('zyf120874')
#browser.find_element_by_id('J_SubmitStatic').click()
#browser.find_element_by_name('TPL_username').send_keys('15735177116')
#browser.find_element_by_name('TPL_password').send_keys('zyf120874')
#dragger=browser.find_element_by_id('nc_1_n1z')#.滑块定位
#action=ActionChains(browser)
#for index in range(500):
# try:
# action.drag_and_drop_by_offset(dragger, 300, 0).perform()#平行移动鼠标,此处直接设一个超出范围的值,这样拉到头后会报错从而结束这个动作
# except UnexpectedAlertPresentException:
# break
# time.sleep(5) #等待停顿时间
#browser.find_element_by_id('J_SubmitStatic').click()
#搜索商品
browser.find_element_by_id('q').send_keys('爬虫')
browser.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button').click()
#js事件,打开一个新的窗口
browser.execute_script('window.open()')
#js事件,选择窗口
browser.switch_to_window(browser.window_handles[1])
browser.get('https://www.baidu.com')
print(browser.window_handles)
time.sleep(1)
browser.switch_to_window(browser.window_handles[0])
browser.get('http://china.nba.com/')
browser.switch_to_window(browser.window_handles[1])
#time.sleep(1)
browser.find_element_by_name('wd').send_keys('张亚飞')
browser.find_element_by_class_name('s_ipt').click()
#browser.find_element_by_xpath('#page > a.n').click()
#解决方案1:显式等待
wait = ui.WebDriverWait(browser,10)
wait.until(lambda browser: browser.find_element_by_xpath('//div[@id="page"]/a[@class="n"]'))
##解决方案2:
#while 1:
# start = time.clock()
# try:
# browser.find_element_by_xpath('//div[@id="page"]/a[@class="n"]').click()
# print('已定位到元素')
# end=time.clock()
# break
# except:
# print("还未定位到元素!")
#print('定位耗费时间:'+str(end-start))
for i in range(1,10):
wait = ui.WebDriverWait(browser,10)
wait.until(lambda browser: browser.find_element_by_xpath('//div[@id="page"]/a[3]'))
browser.find_element_by_xpath('//div[@id="page"]/a[{}]'.format(i)).click()
time.sleep(2)
browser.close()
browser.switch_to_window(browser.window_handles[0])
browser.close()
#browser.find_element_by_xpath('//div[@id="page"]/a[3]').click()
#print(browser.page_source)
#browser = webdriver.Chrome()
##browser.get('https://www.baidu.com')
##browser.execute_script('window.open()')
#js操作
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
browser.execute_script('alert("to button")')
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 31 20:59:41 2018
@author: Zhang Yafei
"""
from selenium import webdriver
import time
import re
import urllib.request
import os
import traceback
#id='531501718059'
def spider(id):
rootdir = os.path.dirname(__file__)+'/images'
browser = webdriver.Chrome()
browser.get('https://detail.tmall.com/item.htm?id={}'.format(id))
time.sleep(20)
b = browser.find_elements_by_css_selector('#J_DetailMeta > div.tm-clear > div.tb-property > div > div.tb-key > div > div > dl.tb-prop.tm-sale-prop.tm-clear.tm-img-prop > dd > ul > li > a')
i=1
for a in b:
style = a.get_attribute('style')
try:
image = re.match('.*url\((.*?)\).*',style).group(1)
image_url = 'http:'+image
image_url = image_url.replace('"','')
except:
pass
name = a.text
print('正在下载{}'.format(a.text))
try:
name = name.replace('/','')
except:
pass
try:
urllib.request.urlretrieve(image_url,rootdir+'/{}.jpg'.format(name))
print('{}下载成功'.format(a.text))
except Exception as e:
print('{}下载失败'.format(a.text))
print(traceback.format_exc())
pass
finally:
i+=1
print('下载完成')
def main():
# id = input('请输入商品id:')
ids = ['570725693770','571612825133','565209041287']
for id in ids:
spider(id)
if __name__ == '__main__':
main()
九、scrapy框架
关于scrapy的xpath和css选择器,请点击这篇文章爬虫解析之css和xpath语法
建立项目:Scrapy startproject quotestutorial
创建爬虫:Cd quotestutorial
Scrapy genspider quotes quotes.toscrape.com
scrapy genspider -t crawl weisuen sohu.com
运行:Scrapy crawl quotes
Scrapy runspider quote
scrapy crawl lagou -s JOBDIR=job_info/001 暂停与重启
保存文件:Scrapy crawl quotes –o quotes.json
# -*- coding: utf-8 -*-
"""
@Datetime: 2018/9/1
@Author: Zhang Yafei
"""
from twisted.internet import reactor #事件循环(终止条件:所有的socket都已经移除)
from twisted.web.client import getPage #socket对象(如果下载完成,自动从事件循环中移出。。。)
from twisted.internet import defer #defer.Deferred 特殊的socket对象(不会发请求,手动移出)
class Request(object):
def __init__(self,url,callback):
self.url = url
self.callback = callback
class HttpResponse(object):
def __init__(self,content,request):
self.content = content
self.request = request
self.url = request.url
self.text = str(content,encoding='utf-8')
class ChoutiSpider(object):
name = 'chouti'
def start_requests(self):
start_url = ['http://www.baidu.com','https://v.qq.com/',]
for url in start_url:
yield Request(url,self.parse)
def parse(self,response):
# print(response.text) #response是HttpResponse对象
print(response.url)
# print(response.content)
# print(response.request)
# yield Request('http://www.cnblogs.com',callback=self.parse) #无限循环
#1.crawling 移除
#2.获取parse yield值
#3.再次去队列中获取
import queue
Q = queue.Queue()
class Engine(object):
def __init__(self):
self._close = None
self.max = 5
self.crawling = []
def get_response_callback(self,content,request):
self.crawling.remove(request)
rep = HttpResponse(content,request)
result = request.callback(rep) #调用parse方法
import types
if isinstance(result,types.GeneratorType):
for ret in result:
Q.put(ret)
#再次去队列中取值
def _next_request(self):
"""
去取request对象,并发送请求
最大并发限制
:return:
"""
if Q.qsize() == 0 and len(self.crawling) == 0:
self._close.callback(None)
return
if len(self.crawling) >= self.max:
return
while len(self.crawling) < self.max:
try:
req = Q.get(block=False)
self.crawling.append(req)
d = getPage(req.url.encode('utf-8'))
#页面下载完成,get_response_callback,调用用户spider中定义的parse方法,并且将新请求添加到调度器
d.addCallback(self.get_response_callback,req)
#未达到最大并发数,可以再次去调度器中获取Request
d.addCallback(lambda _:reactor.callLater(0,self._next_request))
except Exception as e:
return
@defer.inlineCallbacks
def crawl(self,spider):
#将初始Request对象添加到调度器
start_requests = iter(spider.start_requests()) #生成器转迭代器
while True:
try:
request = next(start_requests)
Q.put(request)
except StopIteration as e:
break
#去调度器里面取request,并发送请求
# self._next_request()
reactor.callLater(0, self._next_request)
self._close = defer.Deferred()
yield self._close
#yield一个defer对象或getPage对象
_active = set()
engine = Engine()#创建一个引擎对象
spider = ChoutiSpider()
d = engine.crawl(spider) #把每一个spider放入到引擎中
_active.add(d) #将每一个引擎放入到集合中
dd = defer.DeferredList(_active)
dd.addBoth(lambda _:reactor.stop()) #自动终止事件循环
reactor.run()
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ArticleSpider import settings
from ArticleSpider.items import LagouJobItemLoader,LagouJobItem
from utils.common import get_md5
from datetime import datetime
import random
class LagouSpider(CrawlSpider):
name = 'lagou'
allowed_domains = ['www.lagou.com']
start_urls = ['https://www.lagou.com/']
custom_settings = {
"COOKIES_ENABLED": True
}
rules = (
Rule(LinkExtractor(allow=('zhaopin/.*',)), follow=True),
Rule(LinkExtractor(allow=('gongsi/j\d+.html',)), follow=True),
Rule(LinkExtractor(allow=r'jobs/\d+.html'), callback='parse_job', follow=True),
)
def parse_start_url(self, response):
yield scrapy.Request(url=self.start_urls[0], cookies=settings.COOKIES, callback=self.parse)
def process_results(self, response, results):
return results
def parse_job(self, response):
#解析拉勾网的逻辑
item_loader = LagouJobItemLoader(item=LagouJobItem(),response=response)
item_loader.add_css('title', '.job-name::attr(title)')
item_loader.add_value('url',response.url)
item_loader.add_value('url_object_id', get_md5(response.url))
item_loader.add_css('salary_min', '.job_request .salary::text')
item_loader.add_css('salary_max', '.job_request .salary::text')
item_loader.add_xpath('job_city',"//dd[@class='job_request']/p/span[2]/text()")
item_loader.add_xpath('work_years',"//dd[@class='job_request']/p/span[3]/text()")
item_loader.add_xpath('degree_need',"//dd[@class='job_request']/p/span[4]/text()")
item_loader.add_xpath('job_type',"//dd[@class='job_request']/p/span[5]/text()")
item_loader.add_css('tags','.position-label li::text')
item_loader.add_css('publish_time','.publish_time::text')
item_loader.add_css('job_advantage','.job-advantage p::text')
item_loader.add_css('job_desc','.job_bt div')
item_loader.add_css('job_addr','.work_addr')
item_loader.add_css('company_name','.job_company dt a img::attr(alt)')
item_loader.add_css('company_url','.job_company dt a::attr(href)')
item_loader.add_value('crawl_time', datetime.now())
job_item = item_loader.load_item()
return job_item
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
from scrapy.loader.processors import MapCompose,TakeFirst,Join
import datetime
from scrapy.loader import ItemLoader
import re
from utils.common import extract_num
from settings import SQL_DATETIME_FORMAT, SQL_DATE_FORMAT
from w3lib.html import remove_tags
def add_jobbole(value):
return value+'zhangyafei'
def date_convert(value):
try:
value = value.strip().replace('·','').strip()
create_date = datetime.datetime.strptime(value, "%Y/%m/%d").date()
except Exception as e:
create_date = datetime.datetime.now().date
return create_date
def get_nums(value):
try:
if re.match('.*?(\d+).*', value).group(1):
nums = int(re.match('.*?(\d+).*', value).group(1))
else:
nums = 0
except:
nums = 0
return nums
def remove_comment_tags(value):
if "评论" in value:
return ''
return value
def return_value(value):
return value
class ArticleItemLoader(ItemLoader):
#自定义itemloader
default_output_processor = TakeFirst()
class JobboleArticleItem(scrapy.Item):
title = scrapy.Field(
input_processor=MapCompose(lambda x:x+'-jobbole',add_jobbole)
)
date = scrapy.Field(
input_processor=MapCompose(date_convert),
output_processor=TakeFirst()
)
url = scrapy.Field()
url_object_id = scrapy.Field()
img_url = scrapy.Field(
output_processor=MapCompose(return_value)
)
img_path = scrapy.Field()
praise_nums = scrapy.Field(
input_processor=MapCompose(get_nums)
)
fav_nums = scrapy.Field(
input_processor=MapCompose(get_nums)
)
comment_nums = scrapy.Field(
input_processor=MapCompose(get_nums)
)
content = scrapy.Field()
tags = scrapy.Field(
input_processor=MapCompose(remove_comment_tags),
output_processor = Join(',')
)
def get_insert_sql(self):
insert_sql = """
insert into article(title, url, create_date, fav_nums, img_url, img_path,praise_nums, comment_nums, tags, content)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s) ON DUPLICATE KEY UPDATE content=VALUES(fav_nums)
"""
img_url = ""
# content = remove_tags(self["content"])
if self["img_url"]:
img_url = self["img_url"][0]
params = (self["title"], self["url"], self["date"], self["fav_nums"],
img_url, self["img_path"], self["praise_nums"], self["comment_nums"],
self["tags"], self["content"])
return insert_sql, params
def replace_splash(value):
return value.replace("/", "")
def handle_strip(value):
return value.strip()
def handle_jobaddr(value):
addr_list = value.split("\n")
addr_list = [item.strip() for item in addr_list if item.strip() != "查看地图"]
return "".join(addr_list)
def get_salary_min(value):
salary = value.split('-')
salary_min = salary[0]
return salary_min
def get_publish_time(value):
time = value.split(' ')
return time[0]
def get_salary_max(value):
salary = value.split('-')
salary_max = salary[1]
return salary_max
class LagouJobItemLoader(ItemLoader):
#自定义itemloader
default_output_processor = TakeFirst()
class LagouJobItem(scrapy.Item):
title = scrapy.Field()
url = scrapy.Field()
url_object_id = scrapy.Field()
salary_min = scrapy.Field(
input_processor=MapCompose(get_salary_min),
)
salary_max = scrapy.Field(
input_processor=MapCompose(get_salary_max),
)
job_city = scrapy.Field(
input_processor=MapCompose(replace_splash),
)
work_years = scrapy.Field(
input_processor=MapCompose(replace_splash),
)
degree_need = scrapy.Field(
input_processor=