



机器学习&数据挖掘笔记_9(一些svm基础知识)
前言:
这次的内容是Ng关于machine learning关于svm部分的一些笔记。以前也学过一些svm理论,并且用过libsvm,不过这次一听Ng的内容,确实收获不少,隐约可以看到从logistic model到svm model的过程。
基础内容:
使用linear模型进行分类时,可以将参数向量看成一个变量,如果代价函数用MSE表示,则代价函数的图形类似抛物线(以新的变量为自变量);如果代价函数用交叉对数公式表示时,则其代价函数曲线如下:
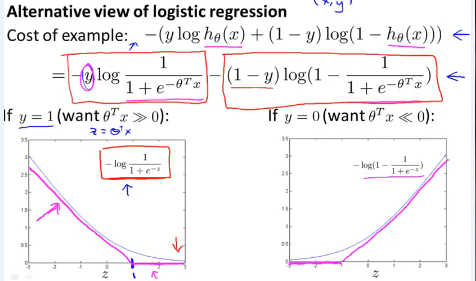
在Logistic回归中其代价函数可以表示为如下:
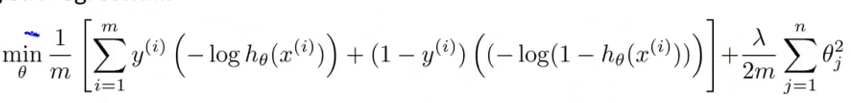
其中第一项是训练样本的误差,第二项是权值系数的惩罚项,λ为权值惩罚系数,其中的m为训练样本的个数,我们的目标是找到合适的θ使代价函数值最小,很明显这个优化过程和m无关。因此我们可以将m去掉,另外将权衡预测误差和权值惩罚的变量λ放在第一项的前面,并将其改为C时,其代价函数就变成了svm的代价函数了,公式如下:
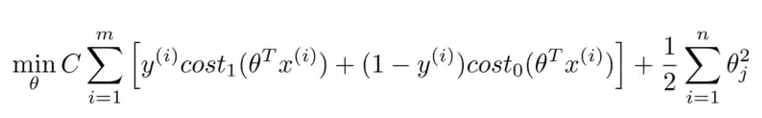
其中的cost1和cost0函数表示当训练样本的标签为1和0时对应的代价函数。
svm分类器通常也叫做large margine分类器。它的目标不仅是找出训练样本的分界面,而且需要使得用该分界面分开的样本距离最大,因为从直观意义上来看,这样的分类器泛化能力会更强,而前面的linear模型和logistic模型分类器就不具备这种能力。
如果将svm中的代价函数中的C值取很大的话(成千上百),就可以让训练样本的准确率非常高,甚至可以将第一项的误差可以变为0,这时候的代价函数优化可以转换为:
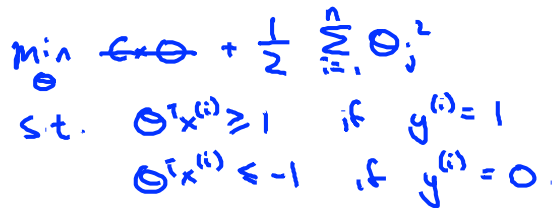
但是C太大也不一定是好事,C太大的话可能会去严重的考虑每一个outliers,反而使得泛化能力变差,当然这些只是宏观上的理解,要做到精确的调整还是离不开数学的。
Ng在介绍svm的数学理论时复习了一个数学基础知识点:向量u和v的内积可以这样计算:u’v=p*||v||,其中p为向量v在向量u上的投影,可以为正或负。
当C很大时,此时目标函数变成了参数平方和的一半,我们要求这个目标函数值最小,且满足参数与每个样本之间的内积值要大(正样本时,该值需满足大于1,负样本时则满足小于-1),由上面的数学知识可以知道需保证每个样本在参数θ上的投影距离要大,满足上述要求的θ向量即我们所对应的分界面的法向量,对应的分界面为我们所求,这个也就是可以从几何上给出svm分类器通常叫做large margine分类器的原因。
下面来看kernel方法的引入,首先看一个非线性分类问题,如下图所示:
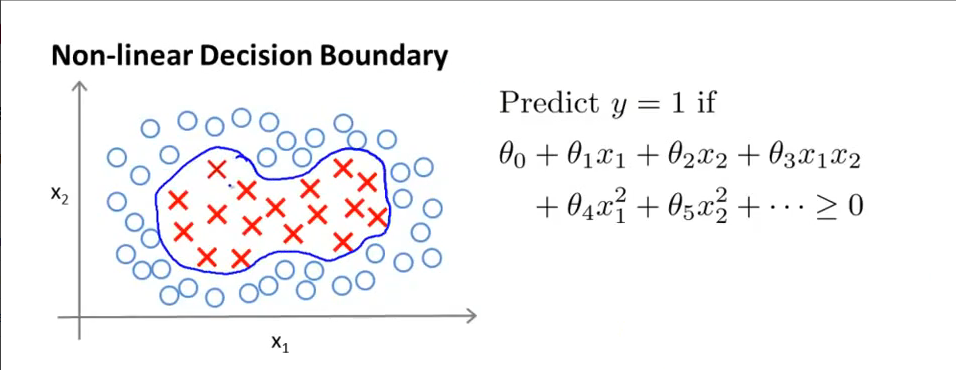
一般情况下我们会建立一个高维参数模型去拟合分界曲线,可以将图中右边模型公式中的x1,x2,x1x2,x1^2,x2^2等看做是原始样本的特征(这里的特征不再是简单的x1,x2了,而是它们乘积的各种组合等),参数θ仍然是我们需要学习的model参数。但是在svm理论框架中,我们需要用采用新的特征,将上面的x1,x2,x1x2,x1^2,x2^2…分别用f1,f2,f3…来表示,且新特征f的来源为:原始输入特征x与某个l(小写的L)的相似度,比如说:
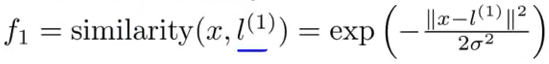
因此此时在训练svm模型时,当标签为1时,需满足下面成立:
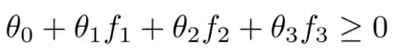
现在的问题就差该怎么确定L了,即:

在使用svm分类器时,一般的做法是将每个训练样本都当成一个l,而训练样本与每个l都可以计算一个f,因此假设有m个样本,每个样本x是n维的,则本来n维的特征x,现在变成了m维的新特征f了。因此此时svm的代价函数变成了:
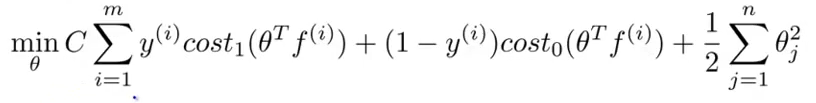
有很多svm的变种,其中一部分代价函数的表达式主要为后面权值的惩罚项稍有不同。
使用svm库时需要调整不少参数,以高斯核为例,此时至少需要考虑的参数有C和σ,其中C为训练样本误差项的惩罚系数,该值太大时,会对训练样本拟合很好(bias小),但对测试样本效果就较差(variance大),即属于过拟合现象,反之亦然。σ为高斯函数的方差系数,该值过大时,学习到的新特征比较smoth,属于欠拟合现象,反之亦然。
在svm中不使用kernel的意思其实表示的是使用线性kernel,这一般适用于当输入样本的特征x维数n较大,而训练样本的个数m又较小的时候。而当n比较小,而m比较大时一般会采用非线性kernel,常见的有高斯kernel。
当然还可以使用其它的kernel,但是需要满足Mercer定理,不然的话在使用svm库对其优化时其过程不会收敛。常见的核还有多项式核,表达式为(x’*θ+contant)^degree,它有2个参数需要选择;String kernel(多用于文本处理),chi-sqare kernel,histogram interection kernel等。不过据Ng本人介绍,他自己一生中都是用高斯kernel,其它的kernel几乎没用过,因为不同的核在一般的分类问题中区别不大(特殊问题可能会有不同)。
最后需要注意的是在使用svm时一定要将训练样本数据的进行归一化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号