
软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 福州大学2021春软件工程实践|W班 |
|---|---|
| 这个作业要求在哪里 | 寒假作业2/2 |
| 这个作业的目标 | 熟悉GitHub的使用 对软件工程学科有进一步的思考 |
| 其他参考文献 | pytest的使用 python3代码规范 冷知识 |
作业基本信息...
目录:
part1:阅读《构建之法》并提问
- 几个提问
我看了代码规范里的“这是移山公司的一家之言,如果碰到争执,关键是要本着‘保持简明,让代码更容易读’的原则”,有这个问题(旧的代码如何在适应新的代码规范中进行维护,还是直接重构)。我查了资料,了解到模块解耦的代码对于这个问题可以对新旧代码进行分开维护,我的实践项目体量都比较小,因此还存在对大项目的代码更新规范的疑惑。
我看了结对编程里的“在结对编程中,任何一段代码都至少被两双眼睛看过,两个脑袋思考过。代码被不断地复审,这样可以避免牛仔式的编程。同时,结对编程避免了‘我的代码’还是‘他的代码’的问题,使得代码的责任不属于某个人,而是属于两个人,进而属于整个团队,这样能够帮助建立集体拥有代码的意识,在一定程度上避免了个人英雄主义。”,有这个问题(个人英雄主义在某些方面可以提高完成效率的上限,如何在结对编程中与团队效率结合)。根据我的实践,组队编程的顺利程度取决于天花板。 因此对结对编程还存在以上的困惑。
读到“软件开发的工作量和质量怎么衡量”,有一个疑惑是如何在短时间内衡量代码的可拓展性和兼容性,如果是由外包团队完成的代码,后期维护或者重构的成本肯定更高。资料都是抽象的描述,并未查到实际的举例说明。
读到结对编程时想到,仅把结对编程运用到关键代码的实现上(重要算法或者逻辑链),会不会提高结对编程的效率,这个问题留到实践时验证。
读到软件作坊这个部分时,想起了读过的《黑客与画家》,里面举例了一种小而精的软件团队,通过三至六个月的开发周期将软件交付给运营公司,这种“作坊”在当今国内是处于潮流还是在一个高投入高风险的位置,它的模式会怎样改变来适应国内市场。
- 几个冷知识
Git使用了SHA-1并非是为了安全性,而是为了数据的完整性;它可以保证,在很多年后,你重新checkout某个commit时,一定是它多年前的当时的状态,完全一摸一样,完全值得信任。
历史上第一名程序员是位女性。她的名字是Ada Lovelace。在1843年,这位英国数学家Ada Lovelace,翻译了意大利工程师Luigi Menabreaw撰写的分析引擎文章。在翻译过程中,她把自己的理解都批注到每篇文章下,而这举动加快了计算机编程技术的发展。在这之后,她又设计出了第一种能够利用分析引擎计算伯努利数的算法,这也是第一个用电脑编写的算法。
part2:WordCount编程
-
GitHub项目地址
-
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 10 | 15 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 20 | 10 |
| • Design Spec | • 生成设计文档 | 无 | |
| • Design Review | • 设计复审 | 10 | 5 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 15 |
| • Design | • 具体设计 | 10 | 15 |
| • Coding | • 具体编码 | 40 | 60 |
| • Code Review | • 代码复审 | 10 | 20 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 30 | 40 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 20 | 10 |
| • Size Measurement | • 计算工作量 | 5 | 5 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 20 | 10 |
| 合计 | 185 | 185 |
- 解题思路描述
python的原生库对字符串的处理十分友好,并且代码简洁,重点在统计词频的功能上,使用python的dictionary进行计词统计,以value为依据排序后得到tuple,再转换成word和num两个list即为结果。
-
代码规范制定链接
-
设计与实现过程
代码一共有两个类,Main和CharDeal
Main实现文件的读写以及功能函数的调用,CharDeal实现具体的功能函数
def DealMethod(self,input,output):
CharDeals = CharDeal()
FIn = open(input,encoding='utf-8')
strling = FIn.read()
lines = CharDeals.LineCount(strling)
characters = CharDeals.CharCount(strling)
total_num, new_wordlist, word_num = CharDeals.WordsCount(characters,strling)
FOut = open(output,encoding='utf-8')
FOut.write("characters:" + characters + "\n")
FOut.write("words:" + total_num + "\n")
FOut.write("lines:" + lines + "\n")
for i in range(len(word_num)):
FOut.write(new_wordlist[i] + word_num[i] + "\n")
FIn.close()
FOut.close()
Main中唯一的函数,实例化CharDeal,调用LineCount,CharCount和WordsCount实现功能,包括open和close的文件读写
def WordsCount(self,characters,strling):
...
while i != characters - 1: #利用while循环进行切词
for i in range(end,characters):
if self.IsLetter(strling[i]) == True:
if i <= characters - 4:
if self.IsLetter(strling[i+1]) and self.IsLetter(strling[i+2]) and self.IsLetter(strling[i+3]):
key = i + 4
start = i
end = key + 1
for j in range(key,characters):
if self.IsSpace(strling[j]):
end = j
break
startlist.append(start)
endlist.append(end)
break
...
def WordCaculate(self,wordlist):
dic = {}
for i in range(len(wordlist)): #遍历list将单词和频数插入dic
if wordlist[i].upper() in dic.keys():
dic[wordlist[i].upper()] = dic[wordlist[i].upper()] + 1
else:
dic[wordlist[i].upper()] = 1
result = sorted(dic.items(),key=lambda item:item[1],reverse=False)
...
for i in range(len(new_wordlist)): #冒泡排序对top10频数的词进行编码排序
for j in range(len(new_wordlist)-1,i,-1):
if new_wordlist[j] < new_wordlist[j-1]:
temp = new_wordlist[j]
new_wordlist[j] = new_wordlist[j-1]
new_wordlist[j-1] = temp
temp = word_num[j]
word_num[j] = word_num[j-1]
word_num[j-1] = temp
return new_wordlist,word_num
WordCount进行分词处理,WordCaculate进行词频统计处理,最后返回一个new_wordlist和word_num即为高频单词以及对应的频数
- 性能改进
对于词频计算统计计算模块中按ascii编码顺序排列,原来的想法是对所有词的dictionary进行快排得到相应的tuple,优化的方法是先截取top10再冒泡排序,效率上因为已经进行过一次快排,所以性能的提升并不明显。
- 单元测试
单元测试函数的编写基于定义的几种异常,在异常处理说明中展示了异常测试代码,这里只展示正常运行测试代码
def test_normal():
main = Main()
result = main.DealMethod("./example.txt", "./1.txt")
# 使用assert判断结果
assert result == 3
def test_linecount(str):
c = CharDeal()
result = c.LineCount(str)
assert result != None
测试行数计算的测试函数
def test_charcount(str):
c = CharDeal()
result = c.CharCount(str)
assert result != None
测试字符数计算的测试函数
def test_wordcount(a,str):
c = CharDeal()
result = c.WordsCount(a,str)
assert result != None
测试单词数计算的测试函数
测试覆盖率截图
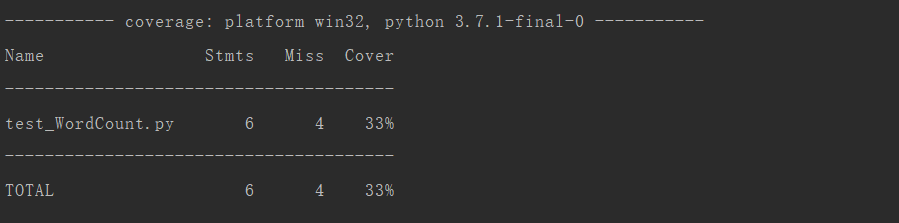
可以通过增加测试用例提高测试覆盖率
- 异常处理说明
可能存在的几种异常
文件路径错误无法打开
def test_input_file_open_error():
main = Main()
result = main.DealMethod("", "./1.txt")
# 使用assert判断结果
assert result == 3
def test_output_file_open_error():
main = Main()
result = main.DealMethod("./example.txt", "")
# 使用assert判断结果
assert result == 3
分别为输入文件和输出文件的打开错误,分别触发以下两种异常
input file open error
output file open error
文件无法关闭
触发以下异常
file close error
- 心路历程与收获
收获

 浙公网安备 33010602011771号
浙公网安备 33010602011771号