


一.centos7.0安装jdk
1.下载linux版本的jdk,下载地址https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html

2. 上传到centos下的/usr/local/src目录下
3.把jdk解压到/usr/local目录下.
进入jdk所在目录 cd /usr/local/src
使用命令 tar -zxvf jdk-8u172-linux-i586.tar.gz
把改目录下解压的jdk移植到/usr/local下 mv jdk1.8.0_172/ ../
4.配置jdk的环境命令如下
1.编辑etc/profile
vi /etc/profile
2.添加如下内容
export JAVA_HOME=/usr/local/jdk1.8.0_172
export CLASSPATH=$JAVA_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
3.更新etc/profile文件
source /etc/profile
4.输入java 和javac验证是否安装成功.
二.Hadoop2.7.3的安装
0.准备工作
0.1 修改主机名: vi /etc/hostname
0.2 修改主机名与ip的映射
使用 vi 编辑器打开 /etc/hosts 文件 # vi /etc/hosts 在文件尾部添加内容,格式:IP地址 主机名(中间用空格分隔),保存退出 192.168.242.130 Master 设置完成后,重启网路服务 # systemctl restart network 使用 ping 命令 ping 主机名 # ping Master
0.3 配置ssh免密登录
#生成ssh免密登录的密钥 Ssh-keygen -t rsa(四个回车) 执行完这个命令后,会生成id_rsa(私钥) .id_rsa.pub(公钥)将公钥拷贝到要免密登陆的目标机器上 ssh-copy-id master
0.4配置防火墙
查看防火墙状态 firewall-cmd --state • 1 停止firewall systemctl stop firewalld.service • 1 禁止firewall开机启动 systemctl disable firewalld.service
1.下载hadoop2.7.3 下载地址: https://hadoop.apache.org/releases.html
2.把下载的hadoop上传到centos下/usr/local/src下
3.把上传的hadoop进行解压命令如下
3.1 tar -zxvf hadoop-2.7.3.tar.gz
3.2 mv hadoop-2.7.3 ../
4.修改/usr/local/hadoop-2.7.3/etc/hadoop/hadoop-env.sh 文件的java环境,将java安装路径加进去:
命令如下:vi /usr/local/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
修改内容如下:
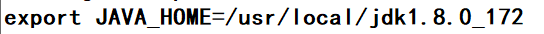
5.把hadoop添加到环境变量上
vi /etc/profile
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin
更新etc/profile文件
source /etc/profile
6.修改vi /usr/local/hadoop2.7.3/etc/hadoop/core-site.xml 文件,
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!--创建指定的目录-->
<value>/usr/hadoop/tmp</value>
</property>
</configuration>
7.修改vi /usr/local/hadoop2.7.3/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.name.dir</name>
<value>/usr/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
8.修改 mapred-site.xml
hadoop只有 mapred-site.xml.template没有mapred-site.xml,需要复制一个
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<!-- 指定mr运行在yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
9.修改yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>ykq4</value> </property> <!-- reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
10.预格式化namenode
hadoop namenode -format
11.启动
启动 HDFS
start-dfs.sh
启动YARN
start-yarn.sh
验证是否启动成功
[root@zhiyou01 sbin]# jps 3297 NodeManager 2866 SecondaryNameNode 2596 NameNode 3017 ResourceManager 2714 DataNode 3404 Jps

 浙公网安备 33010602011771号
浙公网安备 33010602011771号