分布式复习
1.RDD是什么,RDD的特点
RDD,弹性分布式数据集,它是Spark计算的核心。
弹性分布式数据集。他是spark运算的基本单位。特点是,弹性、分布式、不可变的、可分区、并行计算的。
2.窄依赖和宽依赖,窄依赖都有那些算子
深入解读 Spark 宽依赖和窄依赖(ShuffleDependency & NarrowDependency)-CSDN博客
窄依赖:每个父RDD的分区最多被子RDD的一个分区所依赖,一对多的关系。
宽依赖:父RDD的一个分区可能被子RDD的多个分区依赖,多对多的关系。

窄依赖的算子 :map、filter、union、join(hash-partitioned)、mapPartitions、mapValues;
宽依赖的算子 :groupByKey、partitionBy、join(非hash-partitioned);
为什么会有宽窄依赖?
因为每次转换操作都会得到一个新的RDD,前后的RDD(父/子RDD)就会形成联系(依赖)
新RDD每个分区只依赖旧RDD每个分区中的一部分。如果新RDD依赖旧RDD的一小部分,那么就是窄依赖;而如果新RDD依赖旧RDD的多个部分或者是全部,那么就是宽依赖。
3.创建RDD的方法,哪几种
两种。
1.从文件系统中加载数据创建(用textFile()方法)。可以用本地、也可以用DHFS上的数据。(外部存储系统)
2.从集合创建。(内存)
4.Spark Driver的功能是什么(有哪些)
Spark Driver 是 Apache Spark 应用程序的核心组件之一,负责协调整个应用程序的执行。它是 Spark 应用程序的"大脑",主要运行用户编写的 main() 函数。
主要职责
- 应用程序控制:负责将用户程序转换为作业(jobs)
- 任务调度:将任务(task)分发给 Executor 执行
- 资源管理:与集群管理器(如 YARN、Mesos 或 Standalone)通信,获取执行资源
- 状态监控:维护应用程序的状态和进度信息
- 结果收集:收集 Executor 返回的计算结果
5.Spark和Hadoop之间的关系
它们都是大数据处理领域的核心框架。
Hadoop速度较慢,主要使用磁盘。
Spark速度更快,优先使用内存。Spark在多数场景比Hadoop MapReduce性能更好。但Hadoop的生态系统(如HDFS、YARN)仍然是Spark部署的基础设施。
两者之间协同工作,更好的进行大数据处理工作。
6.分布式系统的目标是什么(有哪些)
资源共享和利用率(存储、CPU等)最大化
提高性能(横向扩展:多节点提升整体处理能力。并行运算:任务分解,多节点执行。高吞吐量:处理大规模请求或者数据)
高可用性和容错能力(多节点备份。主从节点。ACID)
可扩展性(水平扩展:添加节点。垂直扩展:单个节点能力提升。弹性伸缩和模块化设计:动态调整资源、组件可独立扩展)
透明性(对用户隐藏复杂性)
安全性、一致性······
7.C/S三层模型(构成/组成),是哪三层
表示层(界面)
业务逻辑层(服务端程序、服务器)
数据访问层(数据库)
8.DNS是属于哪一层的协议
应用层
9.Scala程序编译之后的后缀名是什么
源文件:.scala
编译后的字节码文件:.class
10.什么是TCP协议、UDP协议,它们的区别
| TCP(传输控制协议) | UDP(用户数据报协议) |
|---|---|
| 面向连接 | 无连接 |
| 可靠 | 不可靠 |
| 流量控制(滑动窗口) | 无流量控制 |
| 拥塞控制(多种算法) | 无拥塞控制 |
| 有序传输 | 无序传输 |
| 全双工通信 |
11.什么是分布式事务,有哪些特点
一群小操作看成一次大操作(事务),这些操作要么全成功,要么全失败。
分布式事务是部署在多个节点上的事务,要么全成功,要么全失败。
事务的ACID特性:原子性、一致性、隔离性、持久性
这时想要操作就要进行远程调用(RPC)
12.计算机系统架构有哪些分类
对等模式 Peer to Peer?
客户端-服务器 Client-server?
冯诺依曼架构:程序与数据共享存储空间
哈佛架构:程序与数据存储分离
答案👇
- 集中式体系结构
- 非集中式体系结构
- 混合组织结构
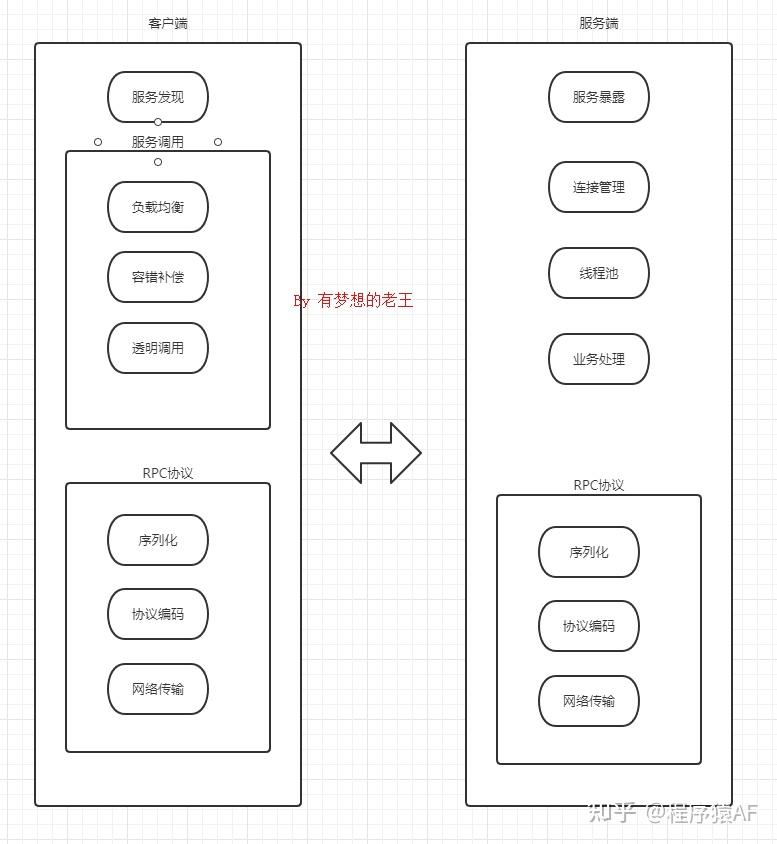
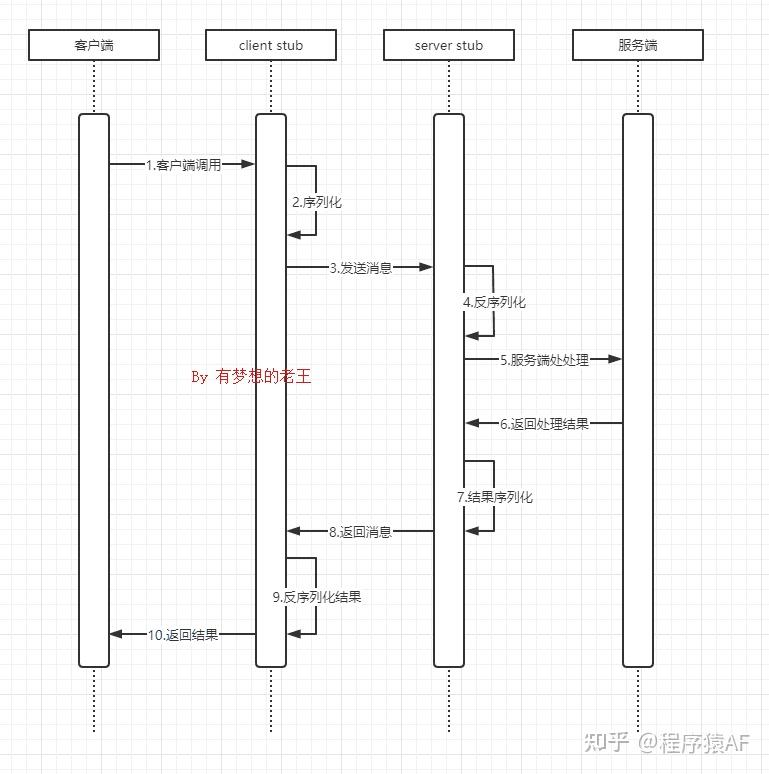
13.RPC的工作原理
RPC:远程过程调用。远程调用像调用本地一样。
- 客户端调用本地 Stub(代理)方法
- Stub 负责将调用信息(方法名、参数等)序列化
- 客户端通过网络将数据发送到服务端
- 服务端收到请求后反序列化,调用对应服务方法
- 方法执行完成后将结果返回,经过相同的序列化/反序列化过程回传给客户端
家人们累了,不想写了。ai
14. 进程、程序、线程,区别与联系
程序(Program):
- 是存储在磁盘上的静态可执行文件,包含一系列指令和数据。
- 是代码的集合,尚未运行。
进程(Process):
- 是程序的动态执行实例。程序运行时,操作系统会为其创建一个进程。
- 进程是资源分配的基本单位,拥有独立的内存空间(代码段、数据段、堆栈等)、文件描述符、环境变量等。
- 进程之间相互隔离,通信需要通过进程间通信(IPC)机制(如管道、消息队列、共享内存等)。
线程(Thread):
- 是进程内的执行单元,一个进程可以包含多个线程。
- 线程共享进程的资源(如内存、文件描述符),但拥有独立的栈和程序计数器。
- 线程切换开销比进程小,适合需要并发执行的场景。
联系与区别:
- 程序是静态的,进程是动态的。
- 进程是资源分配的单位,线程是CPU调度的单位。
- 线程比进程更轻量级,创建和切换开销更小。
- 多线程共享同一进程的资源,而多进程资源独立。
15. 如何实现消息的实时同步
消息的实时同步通常用于分布式系统中,确保数据或状态在不同节点间快速一致。常见方法:
-
消息队列(MQ):
- 使用Kafka、RabbitMQ等消息中间件,生产者发布消息,消费者订阅并实时处理。
- 支持高吞吐、低延迟。
-
长轮询(Long Polling):
- 客户端发起请求后,服务器保持连接直到有新消息才返回响应。
-
WebSocket:
- 全双工通信协议,建立持久连接后,服务器可主动推送消息给客户端。
-
发布/订阅模型(Pub/Sub):
- 如Redis Pub/Sub,订阅者实时接收发布者的消息。
-
实时数据库:
- 如Firebase Realtime Database,数据变更时自动同步到所有客户端。
-
Gossip协议:
- 节点间随机传播消息,最终达成一致(适合大规模分布式系统)。
16. 什么是最终一致性
最终一致性(Eventual Consistency):
- 是分布式系统的一种数据一致性模型,指在没有新更新的情况下,经过一段时间后,所有副本的数据会达到一致状态。
- 不保证强一致性(立即一致),但保证最终一致。
特点:
- 允许短暂的不一致(如读写分离时,写主库后从库可能延迟同步)。
- 适合高可用、分区容忍性(CAP中的AP系统)的场景。
例子:
- DNS系统、电商库存缓存。
17. 在分布式系统中,怎么样实现最终一致性
实现最终一致性的常见方法:
-
读写分离:
- 写操作到主节点,读操作可从从节点读取,从节点异步同步主节点数据。
-
异步复制:
- 主节点更新后,异步将变更传播到其他副本。
-
冲突解决机制:
- 如向量时钟(Vector Clock)、CRDT(Conflict-Free Replicated Data Types)解决冲突。
-
消息队列:
- 通过消息队列异步处理数据同步任务。
-
版本号或时间戳:
- 每次更新携带版本号,合并时按版本解决冲突。
-
定期同步:
- 如Merkle Tree比对差异并修复。
18. MapReduce模型与Spark计算模型的比较
| 特性 | MapReduce | Spark |
|---|---|---|
| 计算模型 | 批处理 | 批处理、流处理、交互式查询 |
| 速度 | 慢(磁盘IO频繁) | 快(内存计算) |
| 容错 | 通过重新执行任务实现 | RDD血缘关系 + 检查点 |
| API | 低级(需实现Map/Reduce) | 高级(RDD/DataFrame/Dataset) |
| 迭代计算 | 效率低(每次迭代需读写磁盘) | 效率高(内存缓存中间结果) |
| 资源管理 | 依赖YARN/Mesos | 支持Standalone/YARN/Mesos |
| 适用场景 | 离线大规模数据批处理 | 实时流处理、机器学习、图计算 |
19. 多计算机系统的主要通信方式是什么
- 消息传递(Message Passing):
- 节点间通过发送/接收消息通信,如MPI、RPC。
- 共享内存(Shared Memory):
- 通过共享内存区域通信(需物理多核或分布式共享内存系统)。
- 远程过程调用(RPC):
- 像调用本地函数一样调用远程服务。
- 消息队列:
- 如Kafka、RabbitMQ解耦生产者和消费者。
- HTTP/REST:
- 基于网络的API调用。
ai总结:人话版👇
多计算机系统(比如服务器集群、分布式系统)通信,主要靠这几种方式,简单说就是:
-
消息传递(最常用)
- 计算机之间直接发"小纸条"(消息),比如TCP/IP网络通信。
- 例子:微信发消息、Spark节点间传数据。
-
共享内存(高效但难搞)
- 多台机器共用一块内存(像黑板),速度快但容易冲突。
- 例子:GPU集群训练AI模型时常用。
-
远程调用(像点外卖)
- 让别的计算机帮你干活(比如调用另一台机器的函数)。
- 例子:网页访问后台服务器(HTTP请求)。
-
数据流(流水线作业)
- 数据像流水线一样在不同计算机间连续传递。
- 例子:实时视频处理系统。
人话总结:
计算机们要么互相发消息(你一句我一句),要么共用黑板(容易吵架),要么让别人代劳(远程帮忙),要么搞流水线(一个传一个)。实际中经常混着用。
20. Spark支持哪几种资源管理器
- Standalone:
- Spark自带的简单集群管理器。
- Apache Hadoop YARN:
- 与Hadoop生态集成。
- Apache Mesos:
- 通用的集群资源管理器。
- Kubernetes:
- 容器化部署(Spark 2.3+支持)。
ai.关于Kubernetes(简称k8s)👇
Kubernetes(简称 K8s)就是个“容器管家”
简单来说:
- 管什么? —— 管你的软件(打包成容器,比如 Docker)。
- 干嘛用? —— 自动帮你部署、扩容、修故障,保证服务不挂。
- 怎么管? —— 比如:
- 你说“我要 3 个淘宝服务器”,它立马给你搞出来。
- 如果一台挂了,它自动重启或换机器,用户无感知。
类比:
- 容器 = 集装箱(装软件的标准化包裹)
- Kubernetes = 港口调度系统(自动装卸、调配集装箱到不同轮船/机器)
一句话:有了它,你的服务就像有 24 小时待命的运维团队,省心! 🚢
ai.关于k8s与Docker的区别👇
K8s 和 Docker 的区别,用大白话解释:
1. Docker = 打包工具(快递箱)
- 把软件和它的环境(比如 Python、MySQL)打包成一个“集装箱”(容器),这样在哪都能运行,不会缺依赖。
- 只管单机:比如你电脑上跑一个 Docker 容器,就像开一个独立的小房间运行程序。
2. K8s = 集装箱调度系统(港口总管)
- Docker 只能管一台机器,K8s 管一群机器(集群)。
- 自动决定把 Docker 容器放哪台机器、开几个副本、坏了怎么重启,完全不用人操心。
- 比如:双十一淘宝要扩容 1000 台服务器,K8s 直接自动搞定,人工只需要说一句“我要 1000 个”。
类比:
- Docker = 造集装箱的工厂(单个包裹)。
- K8s = 顺丰物流中心(调度全国快递,自动装车、补货、换路线)。
总结:
- 小项目用 Docker 就够了(比如本地开发)。
- 大项目必须上 K8s(比如淘宝、抖音,成百上千台服务器要管理)。
他俩是搭档关系,不是竞争对手!🚚💨
21. 软件架构设计中,有哪些典型模式
- 分层架构:
- 如MVC(Model-View-Controller)。
- 微服务架构:
- 服务拆分为小型独立单元。
- 事件驱动架构:
- 通过事件触发异步处理。
- 管道-过滤器架构:
- 数据流经一系列过滤器处理。
- 客户端-服务器:
- 经典的两层架构。
- Peer-to-Peer:
- 节点对等通信(如区块链)。
22. 分布式计算框架中,控制节点的核心职责是什么
控制节点(如Spark的Driver、MapReduce的JobTracker)的核心职责:
- 任务调度:
- 将任务分发给工作节点。
- 资源管理:
- 分配CPU、内存等资源。
- 状态监控:
- 跟踪任务执行状态,处理失败任务。
- 协调通信:
- 管理节点间的数据交换。
- 容错处理:
- 重启失败任务或重新分配资源。
ai.大白话👇
在分布式计算框架(比如Hadoop、Spark这种)里,控制节点就像工地的“包工头”或“总指挥”,核心职责用大白话说就这几件事:
1. 派活儿(任务调度)
- 把大任务拆成小任务,分给各个 worker 节点(干活的小弟们)
例子:要统计100G文件里的单词数,控制节点会把文件切成100份,每台机器处理1G。
2. 盯进度(监控状态)
- 实时盯着所有 worker 有没有在干活:
- 谁干完了?
- 谁卡住了?
- 谁崩溃了?
例子:如果某个 worker 宕机了,控制节点会立刻把它的任务转给别人。
3. 管资源(资源分配)
- 决定给每个任务分配多少CPU、内存等资源,避免有的机器撑死、有的饿死。
例子:像食堂阿姨打饭,保证每个人都能吃到,不浪费也不不够。
4. 当和事佬(协调通信)
- 让所有 worker 之间能互相配合,避免冲突。
例子:多个 worker 同时写同一个文件时,控制节点会协调顺序,防止乱套。
5. 兜底救火(容错处理)
- 如果任务失败,自动重试或换人干。
例子:就像快递送不到就换快递员,保证包裹最终送达。
6. 存元数据(记小本本)
- 记录所有任务和数据的分布信息(比如数据存在哪台机器上)。
例子:像图书管理员,知道哪本书在哪个书架。
附:常见框架的控制节点
- Hadoop:
JobTracker(老版本)或YARN里的ResourceManager- Spark:
Driver程序- Kubernetes:
Master节点一句话总结:控制节点就是分布式系统的“大脑”,负责 指挥、监控、救场,让一堆机器能井井有条地干活。
23. 为什么网课可以支持多人同时观看视频
- CDN(内容分发网络):
- 视频内容缓存到全球边缘节点,用户就近访问,减少源站压力。
- 流媒体协议:
- 如HLS、DASH将视频分片传输,适应不同带宽。
- 负载均衡:
- 请求分散到多台服务器,避免单点过载。
- P2P技术:
- 用户间共享数据(如WebRTC)。
- 分布式存储:
- 视频文件存储在多个节点,支持高并发读取。
- 异步处理:
- 播放器缓冲机制缓解实时压力。
ai.人话版👇
网课能支持多人同时看视频,就像“食堂开饭”一样,背后有一套分工明确的流程。用大白话解释原理:
1. 视频不是“独一份”(内容分发)
- 原始操作:如果视频只存在一台服务器上,万人同时访问会像“独木桥挤爆”。
- 实际做法:把视频复制多份,放到全国各地的服务器(CDN节点),就像在小区里开了分食堂,大家就近取餐,不用全挤到总店。
2. 拆分传输(流媒体技术)
- 视频被切成无数小片段(比如每2秒一个文件),像把电影拆成连环画。
- 你的手机边下载边播放,看完第1段立刻加载第2段,不用等整个视频下载完。
3. 智能分配线路(负载均衡)
- 有个“调度员”(负载均衡器)根据你的网络情况,分配最流畅的服务器给你。
- 例子:电信用户走电信服务器,移动用户走移动服务器,避开拥堵。
4. 压缩视频(编码优化)
- 视频被压缩成不同清晰度(如720P/1080P),网速慢自动降画质,保证不卡顿。
- 就像快递大箱子可以拆成小包裹,适应不同收货条件。
5. P2P互助(人人为我,我为人人)
- 部分平台(如直播课)会让学员之间互相传数据。比如你看完前10分钟,系统会悄悄用你的网络帮别人传这段,减轻服务器压力。
6. 预加载缓冲
- 提前加载未来几秒的视频到本地(进度条灰色部分),即使网络波动也能短暂顶住,像水库先存水再放水。
附:为什么有时候还会卡?
- 高峰期拥堵:像节假日高速公路,即使有分流也会慢。
- 设备性能差:旧手机处理视频速度跟不上。
- 运营商限速:某些地区网络带宽不足。
总结:网课不卡顿,全靠 多备份+智能调度+压缩传输,本质是用空间(多地服务器)换时间(即时播放)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号