
Kafka学习笔记——存储结构
1,由cdh安装的kafka的默认存储路径如图所示在/var/local/kafka/data,一般会进行修改

kafka配置参考:apache kafka系列之server.properties配置文件参数说明
路径下文件如下

如果是多个路径的话,使用,进行分隔,比如/data01/kafka/data,/data02/kafka/data,注意data的权限需要是kafka用户和kafka组
对应kafka manager上的topic

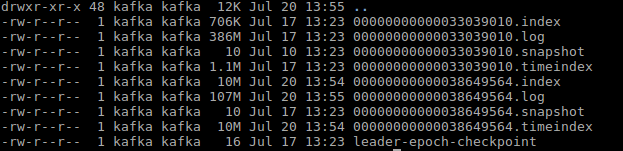
具体的topic的目录下的文件
lintong@master:/var/local/kafka/data/test_topic-0$ ls 00000000000000000187.index 00000000000000000187.snapshot leader-epoch-checkpoint 00000000000000000187.log 00000000000000000187.timeindex
其中
187就是这个日志数据文件开始的offset
00000000000000000187.log是日志数据文件
可以使用解码命令查看日志片段中的内容
/opt/cloudera/parcels/KAFKA/bin/kafka-run-class kafka.tools.DumpLogSegments --files ./00000000000000000187.log 20/07/19 17:28:55 INFO utils.Log4jControllerRegistration$: Registered kafka:type=kafka.Log4jController MBean Dumping ./00000000000000000187.log Starting offset: 187 baseOffset: 187 lastOffset: 187 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0 CreateTime: 1595149737820 size: 71 magic: 2 compresscodec: NONE crc: 1738564593 isvalid: true baseOffset: 188 lastOffset: 188 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 71 CreateTime: 1595149744449 size: 74 magic: 2 compresscodec: NONE crc: 3794338178 isvalid: true baseOffset: 189 lastOffset: 189 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 145 CreateTime: 1595149757514 size: 75 magic: 2 compresscodec: NONE crc: 3084259622 isvalid: true
log.segment.bytes设置是1G,如果log文件的大小达到1G之后会生成另外一个log文件

该参数在1.0.1及以下的kafka有bug,可能会影响消费者消费topic的数据,但是不影响生产者,参考:https://issues.apache.org/jira/browse/KAFKA-6292
当kafka的broker读取segment文件的时候,会判断当前当前读取的segment的偏移量position在继续读取一段HEADER_SIZE_UP_TO_MAGIC之后和该segment文件最大可读取的偏移量end之间的大小
当调高了log.segment.bytes=2G,注意此处2G=有符号INT的最大值=2147483647,有可能导致position+HEADER_SIZE_UP_TO_MAGIC的大小超过int最大值,从而成为负数,小于end,返回null,并导致从log文件的末尾开始读取数据
参考kafka 1.0.1版本源码:https://github.com/apache/kafka/blob/1.0.1/clients/src/main/java/org/apache/kafka/common/record/FileLogInputStream.java

flume消费者报错:
24 Mar 2020 01:55:05,055 WARN [PollableSourceRunner-KafkaSource-source1] (org.apache.kafka.clients.consumer.internals.Fetcher.handleFetchResponse:600) - Unknown error fetching data for topic-partition xxxx-17
kafka端报错:
2020-03-24 15:57:60,265 ERROR kafka.server.ReplicaManager: [ReplicaManager broker=xxx] Error processing fetch operatio
n on partition xxx-17, offset 4095495430
org.apache.kafka.common.KafkaException: java.io.EOFException: Failed to read `log header` from file channel `sun.nio.ch
.FileChannelImpl@73e125b5`. Expected to read 18 bytes, but reached end of file after reading 0 bytes. Started read from
position 2147454346.
at org.apache.kafka.common.record.RecordBatchIterator.makeNext(RecordBatchIterator.java:40)
at org.apache.kafka.common.record.RecordBatchIterator.makeNext(RecordBatchIterator.java:24)
at org.apache.kafka.common.utils.AbstractIterator.maybeComputeNext(AbstractIterator.java:79)
at org.apache.kafka.common.utils.AbstractIterator.hasNext(AbstractIterator.java:45)
at org.apache.kafka.common.record.FileRecords.searchForOffsetWithSize(FileRecords.java:287)
at kafka.log.LogSegment.translateOffset(LogSegment.scala:174)
at kafka.log.LogSegment.read(LogSegment.scala:226)
at kafka.log.Log$$anonfun$read$2.apply(Log.scala:1002)
at kafka.log.Log$$anonfun$read$2.apply(Log.scala:958)
at kafka.log.Log.maybeHandleIOException(Log.scala:1669)
at kafka.log.Log.read(Log.scala:958)
at kafka.server.ReplicaManager.kafka$server$ReplicaManager$$read$1(ReplicaManager.scala:900)
at kafka.server.ReplicaManager$$anonfun$readFromLocalLog$1.apply(ReplicaManager.scala:962)
at kafka.server.ReplicaManager$$anonfun$readFromLocalLog$1.apply(ReplicaManager.scala:961)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at kafka.server.ReplicaManager.readFromLocalLog(ReplicaManager.scala:961)
at kafka.server.ReplicaManager.readFromLog$1(ReplicaManager.scala:790)
at kafka.server.ReplicaManager.fetchMessages(ReplicaManager.scala:803)
at kafka.server.KafkaApis.handleFetchRequest(KafkaApis.scala:601)
at kafka.server.KafkaApis.handle(KafkaApis.scala:99)
at kafka.server.KafkaRequestHandler.run(KafkaRequestHandler.scala:65)
at java.lang.Thread.run(Thread.java:748)
00000000000000000187.index是偏移量索引文件
因为index文件中key存储是的offset,而value存储的是对应log文件中的偏移量,所以index文件的作用是通过二分查找帮助client更快地找到所需offset的message在log文件中的位置
参考:https://mrbird.cc/Kafka%E5%AD%98%E5%82%A8%E6%9C%BA%E5%88%B6.html
/opt/cloudera/parcels/KAFKA/bin/kafka-run-class kafka.tools.DumpLogSegments --files ./00000000000000000187.index 20/07/19 19:05:08 INFO utils.Log4jControllerRegistration$: Registered kafka:type=kafka.Log4jController MBean Dumping ./00000000000000000187.index offset: 187 position: 0
00000000000000000187.timeindex是时间戳索引文件
/opt/cloudera/parcels/KAFKA/bin/kafka-run-class kafka.tools.DumpLogSegments --files ./00000000000000000187.timeindex 20/07/19 18:47:31 INFO utils.Log4jControllerRegistration$: Registered kafka:type=kafka.Log4jController MBean Dumping ./00000000000000000187.timeindex timestamp: 0 offset: 187 Found timestamp mismatch in :/var/local/kafka/data/test_topic-0/./00000000000000000187.timeindex Index timestamp: 0, log timestamp: 1595149737820 Index timestamp: 0, log timestamp: 1595149737820 Found out of order timestamp in :/var/local/kafka/data/test_topic-0/./00000000000000000187.timeindex Index timestamp: 0, Previously indexed timestamp: 0
1595149737820毫秒转换成unix时间是2020/7/19 17:8:57,即这个日志文件开始的时间戳
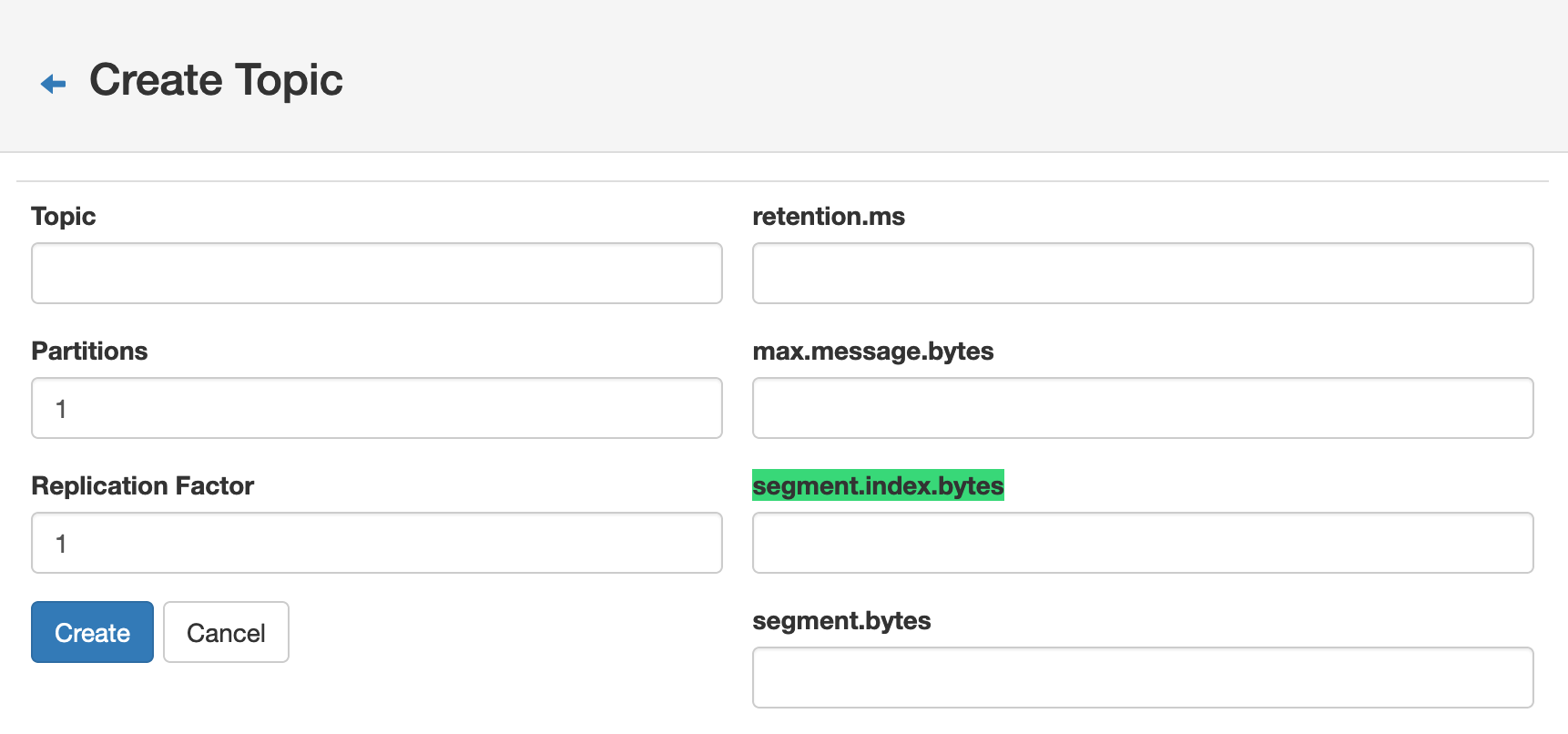
index文件和log文件的大小还可以在创建topic的时候设置,如下
segment.index.bytes参数决定了index文件大小达到多大之后进行切分,默认大小是10M,如下
segment.bytes参数决定了log文件大小达到多大之后进行切分
可能还会有其他文件,比如:
.snapshot(快照文件)、.deleted()、.cleaned(日志清理临时文件)、.swap(Log Compaction之后的临时文件)、leader-epoch-checkpoint(保存了每一任leader开始写入消息时的offset,会定时更新。 follower被选为leader时会根据这个确定哪些消息可用)
kafka在写入和读取上都做了优化
参考:https://juejin.im/post/5cd2db8951882530b11ee976
写入:顺序写入、MMFile(Memory Mapped Files,内存映射文件)
读取:基于sendfile实现Zero Copy、批量压缩
其中介绍了跳表
本文只发表于博客园和tonglin0325的博客,作者:tonglin0325,转载请注明原文链接:https://www.cnblogs.com/tonglin0325/p/13340351.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号