

hive中的数据倾斜优化
# hive的倾斜种类比较多,下面主要分析join 时,key倾斜的情况,其他案例后续再补充
1. 大表mapjoin 小表时key值中出现null,空字符特别多,其他普通key特别少时,就会出现单个reduce的运行缓慢,远远超出其他reduce 的运行时间,例如
select a.id,b.id,a.xxxx from a left join b on a.id=b=id
2. 某个长时间运行reduce 日志如下, join 的过程超出了两个小时

3. 通过分析a 表的id 特征值后发现, null 值特别多
select a.id,count(1) cn from a group by id order by cn desc limit 100
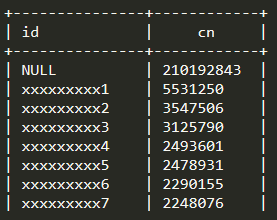
4. 通过调整sql 语句如下,重新运行后,时间大幅缩小
set hive.optimize.skewjoin = true; set hive.skewjoin.key = 100000; set hive.auto.convert.join=true; set hive.mapjoin.smalltable.filesize = 100000000; select a.id,b.id,a.xxxx from a left join b on a.id=b=id where a.id is null
union all select a.id,b.id,a.xxxx from a left join b on a.id=b=id where a.id is not null

 浙公网安备 33010602011771号
浙公网安备 33010602011771号