linux内存源码分析 - 内存回收(匿名页反向映射)
2016-04-17 15:01 tolimit 阅读(10587) 评论(7) 收藏 举报本文为原创,转载请注明:http://www.cnblogs.com/tolimit/
概述
看完了内存压缩,最近在看内存回收这块的代码,发现内容有些多,需要分几块去详细说明,首先先说说匿名页的反向映射,匿名页主要用于进程地址空间的堆、栈、还有私有匿名共享内存(用于有亲属关系的进程),这些匿名页所属的线性区叫做匿名线性区,这些线性区只映射内存,不映射具体磁盘上的文件。匿名页的反向映射对匿名页的回收起到了很大的作用。为了进行内存回收,内核为每个zone管理区的内存页维护了5个LRU链表(最近最少使用链表),它们分别是:LRU_INACTIVE_ANON、LRU_ACTIVE_ANON、LRU_INACTIVE_FILE、LRU_ACTIVE_FILE、LRU_UNEVICTABLE。
- LRU_INACTIVE_ANON:保存所属zone中的非活动匿名页,每次会从链表头部加入,这里的匿名页都是从LRU_ACTIVE_ANON链表中移动过来的。这个链表长度一般为所属zone的匿名页数量的25%
- LRU_ACTIVE_ANON:保存所属zone中的活动匿名页,每次会从链表头部加入,当LRU_INACTIVE_ANON的数量不足所属zone的25%时,会从LRU_ACTIVE_ANON链表末尾移动一些页到LRU_INACTIVE_ANON链表头部。
- LRU_INACTIVE_FILE:保存所属zone中的非活动文件页,同LRU_INACTIVE_ANON类似。
- LRU_ACTIVE_FILE:保存所属zone中的活动文件页,同LRU_ACTIVE_ANON类似。
- LRU_UNEVICTABLE:保存所属zone中的禁止回收的页,一般这些页通过mlock被锁在内存中。
这篇文章先不详细描述这几个LRU链表,主要先说匿名页的反向映射,在LRU_INACTIVE_ANON和LRU_ACTIVE_ANON这两个链表中,链入的是物理页框对应的页描述符。当要进行内存回收时,内存回收函数会扫描LRU_INACTIVE_ANON链表中的页,将一部分页放入swap,然后释放掉这个物理页框,这时候会有个问题,有些进程已经将这个页映射到了它们的页表中,如果要讲页换出就需要对映射了此页的进程页表进行处理,并且映射了此页的进程很多时候并不是只有一个。匿名页反向映射就是作用在这种场景,它能够通过物理页框的页描述符,找到所有映射了此页的匿名线性区vma和所属的进程,然后通过修改这些进程的页表,标记此页已被换出内存,之后这些进程访问到此页时,就能够进行相应的处理。
数据结构
关于反向映射,需要稍微说几个数据结构,分别是内存描述符struct mm_struct,线性区描述符struct vm_area_struct,页描述符struct page,匿名线性区描述符struct anon_vma,和匿名线性区结点描述符struct anon_vma_chain。
每个进程都有自己的内存描述符struct mm_struct,除了内核线程(使用前一个进程的mm_struct)、轻量级进程(使用父进程的mm_struct)。在这个mm_struct中,在反向映射中,我们比较关心的参数如下:
/* 内存描述符,每个进程都会有一个,除了内核线程(使用被调度出去的进程的mm_struct)和轻量级进程(使用父进程的mm_struct) */ /* 所有的内存描述符存放在一个双向链表中,链表中第一个元素是init_mm,它是初始化阶段进程0的内存描述符 */ struct mm_struct { /* 指向线性区对象的链表头,链表是经过排序的,按线性地址升序排列,里面包括了匿名映射线性区和文件映射线性区 */ struct vm_area_struct *mmap; /* list of VMAs */ /* 指向线性区对象的红黑树的根,一个内存描述符的线性区会用两种方法组织,链表和红黑树,红黑树适合内存描述符有非常多线性区的情况 */ struct rb_root mm_rb; u32 vmacache_seqnum; /* per-thread vmacache */ #ifdef CONFIG_MMU /* 在进程地址空间中找一个可以使用的线性地址空间,查找一个空闲的地址区间 * len: 指定区间的长度 * 返回新区间的起始地址 */ unsigned long (*get_unmapped_area) (struct file *filp, unsigned long addr, unsigned long len, unsigned long pgoff, unsigned long flags); #endif /* 标识第一个分配的匿名线性区或文件内存映射的线性地址 */ unsigned long mmap_base; /* base of mmap area */ unsigned long mmap_legacy_base; /* base of mmap area in bottom-up allocations */ unsigned long task_size; /* size of task vm space */ /* 所有vma中最大的结束地址 */ unsigned long highest_vm_end; /* highest vma end address */ /* 指向页全局目录 */ pgd_t * pgd; /* 次使用计数器,存放了共享此mm_struct的轻量级进程的个数,但所有的mm_users在mm_count的计算中只算作1 */ atomic_t mm_users; /* 初始为1 */ /* 主使用计数器,当mm_count递减时,系统会检查是否为0,为0则解除这个mm_struct */ atomic_t mm_count; /* 初始为1 */ /* 页表数 */ atomic_long_t nr_ptes; /* Page table pages */ /* 线性区的个数,默认最多是65535个,系统管理员可以通过写/proc/sys/vm/max_map_count文件修改这个值 */ int map_count; /* number of VMAs */ /* 线性区的自旋锁和页表的自旋锁 */ spinlock_t page_table_lock; /* Protects page tables and some counters */ /* 线性区的读写信号量,当需要对某个线性区进行操作时,会获取 */ struct rw_semaphore mmap_sem; /* 用于链入双向链表中 */ struct list_head mmlist; /* List of maybe swapped mm's. These are globally strung * together off init_mm.mmlist, and are protected * by mmlist_lock */ /* 进程所拥有的最大页框数 */ unsigned long hiwater_rss; /* High-watermark of RSS usage */ /* 进程线性区中的最大页数 */ unsigned long hiwater_vm; /* High-water virtual memory usage */ /* 进程地址空间的大小(页框数) */ unsigned long total_vm; /* Total pages mapped */ /* 锁住而不能换出的页的数量 */ unsigned long locked_vm; /* Pages that have PG_mlocked set */ unsigned long pinned_vm; /* Refcount permanently increased */ /* 共享文件内存映射中的页数量 */ unsigned long shared_vm; /* Shared pages (files) */ /* 可执行内存映射中的页数量 */ unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE */ /* 用户态堆栈的页数量 */ unsigned long stack_vm; /* VM_GROWSUP/DOWN */ unsigned long def_flags; /* start_code: 可执行代码的起始位置 * end_code: 可执行代码的最后位置 * start_data: 已初始化数据的起始位置 * end_data: 已初始化数据的最后位置 */ unsigned long start_code, end_code, start_data, end_data; /* start_brk: 堆的起始位置 * brk: 堆的当前最后地址 * start_stack: 用户态栈的起始地址 */ unsigned long start_brk, brk, start_stack; /* arg_start: 命令行参数的起始位置 * arg_end: 命令行参数的最后位置 * env_start: 环境变量的起始位置 * env_end: 环境变量的最后位置 */ unsigned long arg_start, arg_end, env_start, env_end; #ifdef CONFIG_MEMCG /* 所属进程 */ struct task_struct __rcu *owner; #endif /* 代码段中映射的可执行文件的file */ struct file *exe_file;
......
};
这里面需要注意的就是mmap链表和mm_rb这个红黑树,一个进程的所有线性区vma都会被链入此进程的mm_struct中的mmap链表和mm_rb红黑树,这两个都是为了查找线性区vma方便。
再来看看线性区vma描述符,线性区分为匿名映射线性区和文件映射线性区,如下:
/* 描述线性区结构 * 内核尽力把新分配的线性区与紧邻的现有线性区进程合并。如果两个相邻的线性区访问权限相匹配,就能把它们合并在一起。 * 每个线性区都有一组连续号码的页(非页框)所组成,而页只有在被访问的时候系统会产生缺页异常,在异常中分配页框 */ struct vm_area_struct { /* 线性区内的第一个线性地址 */ unsigned long vm_start; /* 线性区之外的第一个线性地址 */ unsigned long vm_end; /* 整个链表会按地址大小递增排序 */ /* vm_next: 线性区链表中的下一个线性区 */ /* vm_prev: 线性区链表中的上一个线性区 */ struct vm_area_struct *vm_next, *vm_prev; /* 用于组织当前内存描述符的线性区的红黑树的结点 */ struct rb_node vm_rb; /* 此vma的子树中最大的空闲内存块大小(bytes) */ unsigned long rb_subtree_gap; /* 指向所属的内存描述符 */ struct mm_struct *vm_mm; /* 页表项标志的初值,当增加一个页时,内核根据这个字段的值设置相应页表项中的标志 */ /* 页表中的User/Supervisor标志应当总被置1 */ pgprot_t vm_page_prot; /* Access permissions of this VMA. */ /* 线性区标志 * 读写可执行权限会复制到页表项中,由分页单元去检查这几个权限 */ unsigned long vm_flags; /* Flags, see mm.h. */ /* 链接到反向映射所使用的数据结构,用于文件映射的线性区,主要用于文件页的反向映射 */ union { struct { struct rb_node rb; unsigned long rb_subtree_last; } linear; struct list_head nonlinear; } shared; /* * 指向匿名线性区链表头的指针,这个链表会将此mm_struct中的所有匿名线性区链接起来 * 匿名的MAP_PRIVATE、堆和栈的vma都会存在于这个anon_vma_chain链表中 * 如果mm_struct的anon_vma为空,那么其anon_vma_chain也一定为空 */ struct list_head anon_vma_chain; /* Serialized by mmap_sem & * page_table_lock */ /* 指向anon_vma数据结构的指针,对于匿名线性区,此为重要结构 */ struct anon_vma *anon_vma; /* 指向线性区操作的方法,特殊的线性区会设置,默认会为空 */ const struct vm_operations_struct *vm_ops; /* 如果此vma用于映射文件,那么保存的是在映射文件中的偏移量。如果是匿名线性区,它等于0或者vma开始地址对应的虚拟页框号(vm_start >> PAGE_SIZE),这个虚拟页框号用于vma向下增长时反向映射的计算(栈) */ unsigned long vm_pgoff; /* 指向映射文件的文件对象,也可能指向建立shmem共享内存中返回的struct file,如果是匿名线性区,此值为NULL或者一个匿名文件(这个匿名文件跟swap有关?待看) */ struct file * vm_file; /* 指向内存区的私有数据 */ void * vm_private_data; /* was vm_pte (shared mem) */
......
#ifndef CONFIG_MMU struct vm_region *vm_region; #endif #ifdef CONFIG_NUMA struct mempolicy *vm_policy; #endif
};
对我们匿名页的反向映射来说,在vma中最重要的就是struct anon_vma * anon_vma和struct list_head anon_vma_chain。前者指向此一个匿名线性区的anon_vma结构,而anon_vma_chain用于整理一个所有属于本vma的anon_vma_chain链表。具体后面会分析。
我们再看看struct anon_vma结构,这个结构是几乎每个匿名线性区vma都会有的(除了两个相邻并且特征相同的匿名线性区会使用同一个anon_vma):
/* 匿名线性区描述符,每个匿名vma都会有一个这个结构 */ struct anon_vma { /* 指向此anon_vma所属的root */ struct anon_vma *root; /* Root of this anon_vma tree */ /* 读写信号量 */ struct rw_semaphore rwsem; /* W: modification, R: walking the list */ /* 红黑树中结点数量,初始化时为1,也就是只有本结点,当加入root的anon_vma的红黑树时,此值不变 */ atomic_t refcount; /* 红黑树的根,用于存放引用了此anon_vma所属线性区中的页的其他线性区,用于匿名页反向映射 */ struct rb_root rb_root; /* Interval tree of private "related" vmas */ };
这里面重要的是一个root指针,和一个rb_root红黑树,root指针指向此anon_vma的root(并不是指向其所属的vma),然后红黑树时用于将不同进程的anon_vma_chain加入进来。单这样看此结构现在看来比较难以理解,先不用管,之后慢慢分析。
再看看struct anon_vma_chain结构:
struct anon_vma_chain { /* 此结构所属的vma */ struct vm_area_struct *vma; /* 此结构加入的红黑树所属的anon_vma */ struct anon_vma *anon_vma; /* 用于加入到所属vma的anon_vma_chain链表中 */ struct list_head same_vma; /* 用于加入到其他进程或者本进程vma的anon_vma的红黑树中 */ struct rb_node rb; unsigned long rb_subtree_last; #ifdef CONFIG_DEBUG_VM_RB unsigned long cached_vma_start, cached_vma_last; #endif };
这个anon_vma_chain有两个重要的结点,一个anon_vma_chain链表结点,一个红黑树结点,anon_vma_chain链表结点用于加入到其所属的vma中,而rb红黑树结点加入到其他进程或者本进程的vma的anon_vma的红黑树中。
还有一个页描述符struct page,我们主要关心的就是它的mapping变量,如果此页是匿名页,它的mapping变量会指向第一个访问此页的vma的anon_vma:
struct page { /* First double word block */ /* 用于页描述符,一组标志(如PG_locked、PG_error),同时页框所在的管理区和node的编号也保存在当中 */ /* 在lru算法中主要用到两个标志 * PG_active: 表示此页当前是否活跃,当放到active_lru链表时,被置位 * PG_referenced: 表示此页最近是否被访问,每次页面访问都会被置位 */ unsigned long flags; /* Atomic flags, some possibly * updated asynchronously */ union { /* 最低两位用于判断类型,其他位数用于保存指向的地址 * 如果为空,则该页属于交换高速缓存(swap cache,swap时会产生竞争条件,用swap cache解决) * 不为空,如果最低位为1,该页为匿名页,指向对应的anon_vma(分配时需要对齐) * 不为空,如果最低位为0,则该页为文件页,指向文件的address_space */ struct address_space *mapping; /* If low bit clear, points to * inode address_space, or NULL. * If page mapped as anonymous * memory, low bit is set, and * it points to anon_vma object: * see PAGE_MAPPING_ANON below. */ /* 用于SLAB描述符,指向第一个对象的地址 */ void *s_mem; /* slab first object */ }; /* Second double word */ struct { union { /* 作为不同的含义被几种内核成分使用。例如,它在页磁盘映像或匿名区中标识存放在页框中的数据的位置,或者它存放一个换出页标识符 * 当此页作为映射页(文件映射)时,保存这块页的数据在整个文件数据中以页为大小的偏移量 * 当此页作为匿名页时,保存此页在线性区vma内的页索引或者是页的线性地址/PAGE_SIZE。 * 对于匿名页的page->index表示的是page在vma中的虚拟页框号(此页的开始线性地址 >> PAGE_SIZE)。共享匿名页的产生应该只有在fork,clone完成并写时复制之前。 */ pgoff_t index; /* Our offset within mapping. */ /* 用于SLAB和SLUB描述符,指向空闲对象链表 */ void *freelist; /* 当管理区页框分配器压力过大时,设置这个标志就确保这个页框专门用于释放其他页框时使用 */ bool pfmemalloc; /* If set by the page allocator, * ALLOC_NO_WATERMARKS was set * and the low watermark was not * met implying that the system * is under some pressure. The * caller should try ensure * this page is only used to * free other pages. */ }; ...... }
主要关注mapping和index,如果此页被分配作为一个匿名页,那么它的mapping会指向一个anon_vma,而index保存此匿名页在vma中以页的偏移量(比如vma的线性地址区间是12个页的大小,此页映射到了第8页包含的线性地址上)。需要注意的是,mapping保存anon_vma变量地址时,会执行如下操作:
page->mapping = (void *)&anon_vma + 1;
anon_vma分配时要2字节对齐,也就是所有分配的anon_vma其最低位都为0,经过上面的操作,mapping最低位就为1了,然后通过mapping获取anon_vma地址时,进行如下操作:
struct anon_vma * anon_vma = (struct anon_vma *)(page->mapping - 1);
这里需要着重说说虚拟页框号,我们知道在物理内存中,每个地址区间(0~4K,4K~8K,8K~12K...)都有它们的页框号,则在每个进程地址空间中,每个线性地址区间(0~4K,4K~8K,8K~12K...)也应该有它们对应的虚拟页框号,这个虚拟页框号的作用之后会说到,这里只需要记住对于匿名映射区,它的vma->vm_pgoff = vma开始地址对应的虚拟页框号。
这几个结构都看完了,后面我们具体分析内核是怎么把这几个结构组织起来,又怎么通过一个页的页描述符获得所有映射了此页的vma。我们将通过一条路径进程分析,这条路径是:一个空闲的匿名线性区访问了其所属线性地址区间的页 -> 这个匿名线性区所属的进程fork了一个子进程 -> 父子进程分别访问了线性区中的页。而这条路径中涉及到几个点:创建匿名页与匿名线性区的关联性、父子进程匿名线性区的关联性、父子进程继续访问此匿名线性区的页时的关联性。
建立反向映射流程
我们将通过一条路径进程分析,这条路径是:一个空闲的匿名线性区访问了其所属线性地址区间的页 -> 这个匿名线性区所属的进程fork了一个子进程 -> 父子进程分别访问了线性区中的页。选择这条路径是方便说明内核是如何组织匿名页反向映射的。
建立匿名线性区有两种情况,一种是通过mmap建立私有匿名线性区,另一种是fork时子进程克隆了父进程的匿名线性区,这两种方式有所区别,首先mmap建立私有匿名线性区时,应用层调用mmap时传入的参数fd必须为-1,即不指定映射的文件,参数flags必须有MAP_ANONYMOUS和MAP_PRIVATE。如果是参数是MAP_ANONYMOUS和MAP_SHARED,创建的就不是匿名线性区了,而是使用shmem的共享内存线性区,这种shmem的共享内存线性区会使用打开/dev/zero的fd。而mmap使用MAP_ANONYMOUS和MAP_PRIVATE创建,可以得到一个空闲的匿名线性区,由于mmap代码中更多的是涉及文件映射线性区的创建,这里就先不给代码,当创建好一个匿名线性区后,结果如下:

创建后anon_vma和anon_vma_chain都为空,并且此线性区对应的线性地址区间的页表项也都为空,但是此vma已经创建完成,之后进程访问此vma的地址区间时合理的,我们知道,内核在创建vma时并不会马上对整个vma的地址进行页表的处理,只有在进程访问此vma的某个地址时,会产生一个缺页异常,在缺页异常中判断此地址属于进程的vma并且合理,才会分配一个页用于页表映射,之后进程就可以顺利读写这个地址所在的页框。也就是说,我一个匿名线性区vma,开始地址是0,结束地址是8K,当我访问6k这个地址时,内核会做好4K~8K地址的映射(正好是一个页大小,四级页表中一个页表项映射的大小),而此匿名线性区0~4k的地址是没有进行映射的。只有在第一次访问的时候才会进行映射。
对于匿名线性区,还需要注意vma的vm_start和vm_pgoff,vm_start保存的是此vma开始的线性地址,而vm_pgoff保存的是vma的开始线性地址对应的虚拟页框号,比如vma的开始线性地址是10K,那么这个vm_pgoff就等于3(起始线性地址属于第3个页框的范围)。之后会说到这个有什么用作。
这时我们假设进程访问了此新建的线性区的线性地址区间,由于此线性区是新建的,它的线性地址区间对应的页表项并不会在创建的时候进行映射,所以会产生了缺页异常,在缺页异常中首先会判断此线性地址是否所属vma,如果此线性地址所属的vma是匿名线性区,会通过此进程的页表判断发送异常的线性地址的页表项,如果是第一次访问此线性地址,此页表项必定为空并且页也肯定不在内存中(都没有映射的页),则说明此线性地址是第一次访问到,会调用do_anonymous_page()函数进行处理,我们看看此函数是如何处理的:
/* 分配一个匿名页,并为此页建立映射和反向映射 * 进入此函数的条件,线性地址address对应的进程的页表项为空,并且address所属vma是匿名线性区 * 进入到此函数前,已经对address对应的页全局目录项、页上级目录项、页中间目录项和页表进行分配和设置 */ static int do_anonymous_page(struct mm_struct *mm, struct vm_area_struct *vma, unsigned long address, pte_t *page_table, pmd_t *pmd, unsigned int flags) { struct mem_cgroup *memcg; struct page *page; spinlock_t *ptl; pte_t entry; /* X86_64下这里没做任何事,而X86_32位下如果page_table之前用来建立了临时内核映射,则释放该映射 */ pte_unmap(page_table); /* Check if we need to add a guard page to the stack */ /* 如果vma是向下增长的,并且address等于vma的起始地址,那么将vma起始地址处向下扩大一个页用于保护页 * 同样,如果vma是向上增长的,address等于vma的结束地址,页将vma在结束地址处向上扩大一个页用于保护页 */ if (check_stack_guard_page(vma, address) < 0) return VM_FAULT_SIGBUS; /* Use the zero-page for reads */ /* vma中的页是只读的的情况,因为是匿名页,又是只读的,不会是代码段,这里执行成功则直接设置页表项pte,不会进行反向映射 */ if (!(flags & FAULT_FLAG_WRITE)) { /* 创建pte页表项,这个pte会指向内核中一个默认的全是0的页框,并且会有vma->vm_page_prot中的标志,最后会加上_PAGE_SPECIAL标志 */ entry = pte_mkspecial(pfn_pte(my_zero_pfn(address), vma->vm_page_prot)); /* 当(NR_CPUS >= CONFIG_SPLIT_PTLOCK_CPUS)并且配置了USE_SPLIT_PTE_PTLOCKS时,对pmd所在的页上锁(锁是页描述符的ptl) * 否则对整个页表上锁,锁是mm->page_table_lock * 并再次获取address对应的页表项,有可能在其他核上被修改? */ page_table = pte_offset_map_lock(mm, pmd, address, &ptl); /* 如果页表项不为空,则说明这页曾经被该进程访问过,可能其他核上更改了此页表项 */ if (!pte_none(*page_table)) goto unlock; goto setpte; } /* Allocate our own private page. */ /* 为vma准备反向映射条件 * 检查此vma能与前后的vma进行合并吗,如果可以,则使用能够合并的那个vma的anon_vma,如果不能够合并,则申请一个空闲的anon_vma * 新建一个anon_vma_chain * 将avc->anon_vma指向获得的vma(这个vma可能是新申请的空闲的anon_vma,也可能是获取到的可以合并的vma的anon_vma),avc->vma指向vma,并把avc加入到vma的anon_vma_chain中 */ if (unlikely(anon_vma_prepare(vma))) goto oom; /* 从高端内存区的伙伴系统中获取一个页,这个页会清0 */ page = alloc_zeroed_user_highpage_movable(vma, address); /* 分配不成功 */ if (!page) goto oom; /* 设置此页的PG_uptodate标志,表示此页是最新的 */ __SetPageUptodate(page); /* 更新memcg中的计数,如果超过了memcg中的限制值,则会把这个页释放掉,并返回VM_FAULT_OOM */ if (mem_cgroup_try_charge(page, mm, GFP_KERNEL, &memcg)) goto oom_free_page; /* 根据vma的页参数,创建一个页表项 */ entry = mk_pte(page, vma->vm_page_prot); /* 如果vma区是可写的,则给页表项添加允许写标志 */ if (vma->vm_flags & VM_WRITE) entry = pte_mkwrite(pte_mkdirty(entry)); /* 并再次获取address对应的页表项,并且上锁,锁可能在页中间目录对应的struct page的ptl中,也可能是mm_struct的page_table_lock * 因为需要修改,所以要上锁,而只读的情况是不需要上锁的 */ page_table = pte_offset_map_lock(mm, pmd, address, &ptl); if (!pte_none(*page_table)) goto release; /* 增加mm_struct中匿名页的统计计数 */ inc_mm_counter_fast(mm, MM_ANONPAGES); /* 对这个新页进行反向映射 * 主要工作是: * 设置此页的_mapcount = 0,说明此页正在使用,但是是非共享的(>0是共享) * 统计 * 设置page->mapping最低位为1 * page->mapping指向此vma->anon_vma * page->index存放此page在vma中的第几页 */ page_add_new_anon_rmap(page, vma, address); /* 提交memcg中的统计 */ mem_cgroup_commit_charge(page, memcg, false); /* 通过判断,将页加入到活动lru缓存或者不能换出页的lru链表 */ lru_cache_add_active_or_unevictable(page, vma); setpte: /* 将上面配置好的页表项写入页表 */ set_pte_at(mm, address, page_table, entry); /* No need to invalidate - it was non-present before */ /* 让mmu更新页表项,应该会清除tlb */ update_mmu_cache(vma, address, page_table); unlock: /* 解锁 */ pte_unmap_unlock(page_table, ptl); return 0; /* 以下是错误处理 */ release: /* 取消此page在memcg中的计数,这里处理会在mem_cgroup_commit_charge()之前 */ mem_cgroup_cancel_charge(page, memcg); /* 将此页释放到每CPU页高速缓存中 */ page_cache_release(page); goto unlock; oom_free_page: page_cache_release(page); oom: return VM_FAULT_OOM; }
这里面流程很简单:
- 调用anon_vma_prepare()获取一个anon_vma结构,这个结构可能属于此vma,也可能属于此vma能够合并的前后一个vma
- 通过伙伴系统分配一个页(在32位上,会优先从高端内存分配)
- 根据vma默认页表项参数vm_page_prot创建一个页表项,这个页表项用于加入到address对应的页表中
- 调用page_add_new_anon_rmap()给此page添加一个反向映射
- 将页表项和页表还有此页进行关联,由于页表已经在调用前分配好页了,只需要将页表项与新匿名页进行关联,然后将设置好的页表项写入address在此页表中的偏移地址即可。
着重看anon_vma_prepare()和page_add_new_anon_rmap()这两个函数,我们先看page_add_new_anon_rmap()函数,这个函数比较固定和简单:
/* 对一个新页进行反向映射 * page: 目标页 * vma: 访问此页的vma * address: 线性地址 */ void page_add_new_anon_rmap(struct page *page, struct vm_area_struct *vma, unsigned long address) { /* 地址必须处于vma中 */ VM_BUG_ON_VMA(address < vma->vm_start || address >= vma->vm_end, vma); SetPageSwapBacked(page); /* 设置此页的_mapcount = 0,说明此页正在使用,但是是非共享的(>0是共享) */ atomic_set(&page->_mapcount, 0); /* increment count (starts at -1) */ /* 如果是透明大页 */ if (PageTransHuge(page)) /* 统计 */ __inc_zone_page_state(page, NR_ANON_TRANSPARENT_HUGEPAGES); __mod_zone_page_state(page_zone(page), NR_ANON_PAGES, hpage_nr_pages(page)); /* 进行反向映射 * 设置page->mapping最低位为1 * page->mapping指向此vma->anon_vma * page->index存放此page在vma中的虚拟页框号,计算方法:page->index = ((address - vma->vm_start) >> PAGE_SHIFT) + vma->vm_pgoff; */ __page_set_anon_rmap(page, vma, address, 1); }
主要记住,如果页为匿名页并且是一个新页(没有进行过映射到进程),页描述符的mapping会指向第一次访问它的vma的anon_vma。并且page->index的计算公式需要记住,它等于第一次映射这个页的vma的起始虚拟页框号(vma->vm_pgoff)加上address相对于vma起始地址的页框偏移量,其实也就等于page映射到的vma所在进程地址空间的虚拟页框号。
主要看anon_vma_prepare(),在这个函数中,首先会检查此vma有没有anon_vma,其次会检查此vma能否与前后的vma进行合并,如果可以合并,则只创建一个anon_vma_chain做一定的关联,否则会创建一个anon_vma和一个anon_vma_chain进行一定的关联,先看代码:
/* 为vma准备反向映射条件 * 检查此vma能与前后的vma进行合并吗,如果可以,则使用能够合并的那个vma的anon_vma,如果不能够合并,则申请一个空闲的anon_vma * 创建一个新的anon_vma_chain * 将avc->anon_vma指向获得的vma(此vma可能是新建的,也可能是可以合并的vma的anon_vma),avc->vma指向vma,并把avc加入到vma的anon_vma_chain中 */ int anon_vma_prepare(struct vm_area_struct *vma) { /* 获取vma的反向映射的anon_vma结构 */ struct anon_vma *anon_vma = vma->anon_vma; struct anon_vma_chain *avc; /* 检查是否需要睡眠 */ might_sleep(); /* 如果此vma的anon_vma为空,则进行以下处理 */ if (unlikely(!anon_vma)) { /* 获取vma所属的mm */ struct mm_struct *mm = vma->vm_mm; struct anon_vma *allocated; /* 通过slab/slub分配一个struct anon_vma_chain */ avc = anon_vma_chain_alloc(GFP_KERNEL); if (!avc) goto out_enomem; /* 检查vma能否与其前/后vma进行合并,如果可以,则返回能够合并的那个vma的anon_vma,如果不可以,返回NULL * 主要检查vma前后的vma是否连在一起(vma->vm_end == 前/后vma->vm_start) * vma->vm_policy和前/后vma->vm_policy * 是否都为文件映射,除了(VM_READ|VM_WRITE|VM_EXEC|VM_SOFTDIRTY)其他标志位是否相同,如果为文件映射,前/后vma映射的文件位置是否正好等于vma映射的文件 + vma的长度 * 这里有个疑问,为什么匿名线性区会有vm_file不为空的时候,我也没找到原因 * 可以合并,则返回可合并的线性区的anon_vma */ anon_vma = find_mergeable_anon_vma(vma); allocated = NULL; /* anon_vma为空,也就是vma不能与前后的vma合并,则会分配一个 */ if (!anon_vma) { /* 从anon_vma_cachep这个slab中分配一个anon_vma结构,将其refcount设为1,anon_vma->root指向本身 */ anon_vma = anon_vma_alloc(); if (unlikely(!anon_vma)) goto out_enomem_free_avc; /* 刚分配好的anon_vma存放在allocated */ allocated = anon_vma; } /* 到这里,anon_vma有可能是可以合并的vma的anon_vma,也有可能是刚分配的anon_vma */ /* 对anon_vma->root->rwsem上写锁,如果是新分配的anon_vma则是其本身的rwsem */ anon_vma_lock_write(anon_vma); /* page_table_lock to protect against threads */ /* 获取当前进程的线性区锁 */ spin_lock(&mm->page_table_lock); /* 如果vma->anon_vma为空,这是很可能发生的,因为此函数开头获取的anon_vma为空才会走到这条代码路径上 */ if (likely(!vma->anon_vma)) { /* 将vma->anon_vma设置为新分配的anon_vma,这个anon_vma也可能是前后能够合并的vma的anon_vma */ vma->anon_vma = anon_vma; /* * avc->vma = vma * avc->anon_vma = anon_vma(这个可能是当前vma的anon_vma,也可能是前后可合并vma的anon_vma) * 将新的avc->same_vma加入到vma的anon_vma_chain链表中 * 将新的avc->rb加入到anon_vma的红黑树中 */ anon_vma_chain_link(vma, avc, anon_vma); /* 这两个置空,后面就不会释放掉 */ allocated = NULL; avc = NULL; } /* mm的页表的锁 */ spin_unlock(&mm->page_table_lock); /* 释放anon_vma的写锁 */ anon_vma_unlock_write(anon_vma); if (unlikely(allocated)) put_anon_vma(allocated); if (unlikely(avc)) anon_vma_chain_free(avc); } return 0; out_enomem_free_avc: anon_vma_chain_free(avc); out_enomem: return -ENOMEM; }
我们画图描述两种情况最后生成的结果:
这种是此vma没有与其前后的vma进行合并:
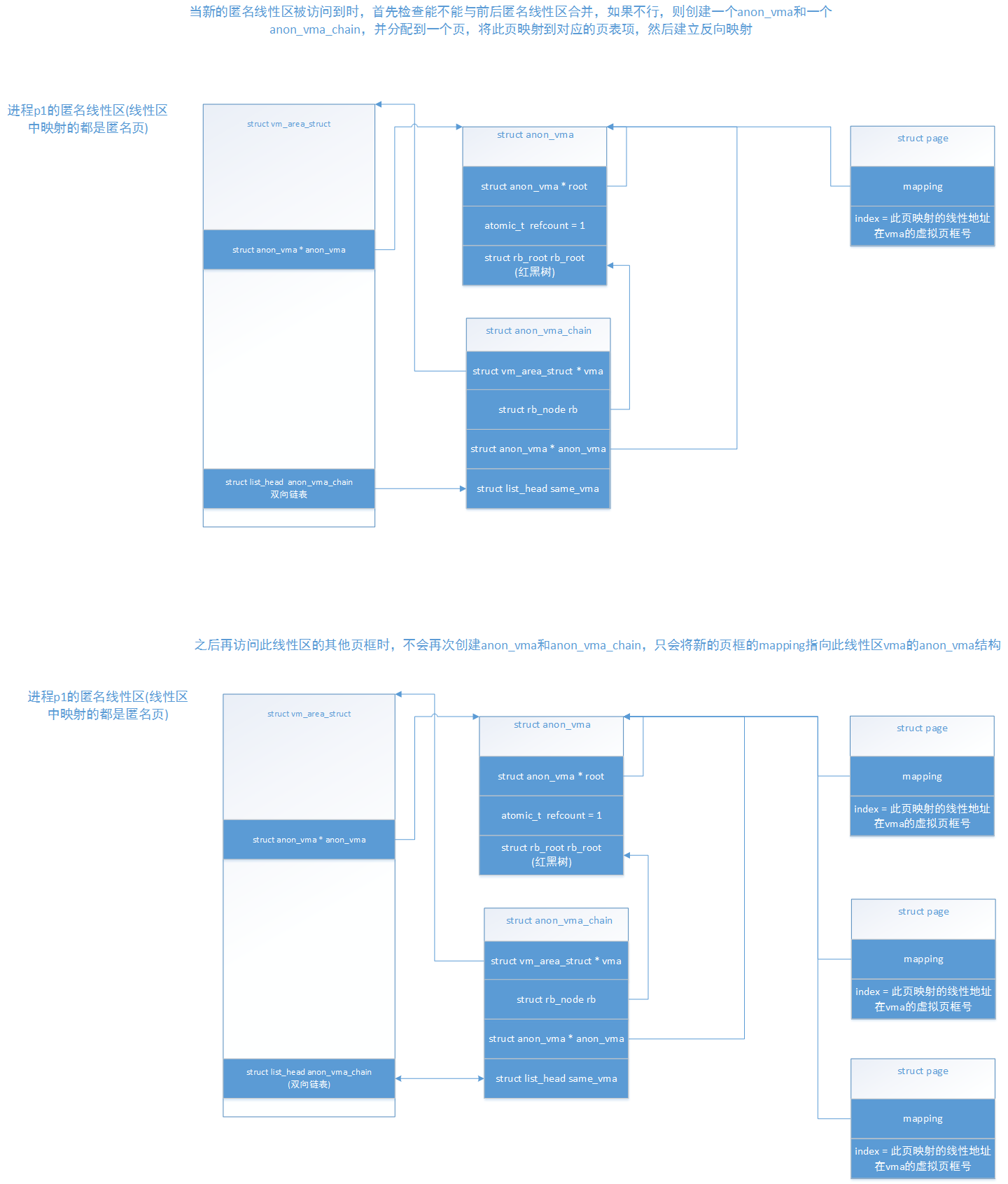
可以看出,当一个新的vma不能与前后相似vma进行合并是,会为此新vma创建专属的anon_vma和一个anon_vma_chain结构,然后将anon_vma_chain链入这个新的vma的anon_vma_chain链表中,并且加入到这个新的vma的anon_vma的红黑树中。而之后再次访问此vma中不属于已经映射好的页的其他地址时,就不需要再次为此vma创建anon_vma和anon_vma_chain结构了。
而另一种情况,是此vma能与前后的vma进行合并,系统就不会为此vma创建anon_vma,而是这两个vma共用一个anon_vma,但是会创建一个anon_vma_chain,如下:

这种情况,如果新的vma能够与前后相似vma进行合并,则不会为这个新的vma创建anon_vma结构,而是将此新的vma的anon_vma指向能够合并的那个vma的anon_vma。不过内核会为这个新的vma建立一个anon_vma_chain,链入这个新的vma中,并加入到新的vma所指的anon_vma的红黑树中。在这种情况中,匿名页的反向映射就能够找到新的vma,看到文章最后就会明白。好的,到这里,建立一个新的匿名线性区并且访问它的地址空间的逻辑已经理清,先别急着看懂这个图,现在看很难理解,慢慢往后面看,就会明白anon_vma和anon_vma_chain为什么要这样组织起来。
父子进程的匿名线性区关系
一些映射了相同匿名页的匿名线性区,它们的关系是怎么样的,首先,匿名线性区只有三种,堆、栈、mmap私有匿名映射,而我们知道,在fork过程中,子进程会拷贝父进程的vma(除了标记有VM_DONTCOPY的vma)和这些vma对应的页表项,即使这些vma是非共享的(如堆、栈),fork也会这样拷贝。这样做的原因是为了效率和降低内存的使用率。而之后,内核会使用写时复制技术,即使那些vma映射的页是共享的,当父进程或子进程对这些中的某个页进行写入时,内核会拷贝一份这个页的副本,并覆盖掉原先这个页所映射的页表项,这样就会隔离出来了。当然,父子进程对还没映射的页进行访问时,都是映射各自的页表,比如:父进程的匿名线性区vma的线性地址区间是0~8k,已经映射了4k~8k的区域,0~4k的区域没有映射。此时父进程fork了一个子进程,此子进程的此vma也是映射了4k~8k的区域,0~4k区域没有映射,当子进程访问0~4k这段地址时,内核会分配一个页,把这个页映射子进程页表中到0~4k这段地址对应的页表项,并不会映射到父进程的页表中。
所以,在fork完之后,内核需要能够通过页框,找到映射了此页的vma和进程,这里就需要了解在fork时,怎么组织父子进程的匿名线性区反向映射的结构anon_vma和anon_vma_chain。,这些代码主要都处于fork路径中的dup_mm()函数里,在这个函数中,会以父进程的mm_struct为标准,初始化子进程的mm_struct。然后遍历父进程的所有vma,在遍历父进程的所有vma过程中,为每个父进程的匿名线性区建立一个子进程对应的匿名线性区vma、一个anon_vma和一个或多个anon_vma_chain。并将它们建立关系,然后子进程页表对这些vma映射的页建立关系。特别是对可写vma的处理时,会将vma对应父子进程的页表项都设置为只读,具体详细看代码:
/* * mm: 子进程的mm_struct * oldmm: 父进程的mm_struct */ static int dup_mmap(struct mm_struct *mm, struct mm_struct *oldmm) { struct vm_area_struct *mpnt, *tmp, *prev, **pprev; struct rb_node **rb_link, *rb_parent; int retval; unsigned long charge; /* 获取每CPU的dup_mmap_sem这个读写信号量的读锁 */ uprobe_start_dup_mmap(); /* 获取父进程的mm->mmap_sem的写锁 */ down_write(&oldmm->mmap_sem); /* 这里x86下为空 */ flush_cache_dup_mm(oldmm); /* 如果父进程的mm_struct的flags设置了MMF_HAS_UPROBES,则子进程的mm_struct的flags设置MMF_HAS_UPROBES和MMF_RECALC_UPROBES */ uprobe_dup_mmap(oldmm, mm); /* * Not linked in yet - no deadlock potential: */ /* 获取子进程的mmap_sem,后面SINGLE_DEPTH_NESTING意思需要查查 */ down_write_nested(&mm->mmap_sem, SINGLE_DEPTH_NESTING); /* 复制父进程进程地址空间的大小(页框数)到子进程的mm */ mm->total_vm = oldmm->total_vm; /* 复制父进程共享文件内存映射中的页数量到子进程mm */ mm->shared_vm = oldmm->shared_vm; /* 复制父进程可执行内存映射中的页数量到子进程的mm */ mm->exec_vm = oldmm->exec_vm; /* 复制父进程用户态堆栈的页数量到子进程的mm */ mm->stack_vm = oldmm->stack_vm; /* 子进程vma红黑树的根结点,保存到rb_link中 */ rb_link = &mm->mm_rb.rb_node; rb_parent = NULL; /* 获取指向线性区对象的链表头,链表是经过排序的,按线性地址升序排列,但是mmap并不是list_head结构,是一个struct vm_area_struct指针,这里由于子进程的mm是刚创建的,mm->map为空,而pprev是一个指向指针的指针 */ pprev = &mm->mmap; /* 暂时不看,与ksm有关 */ retval = ksm_fork(mm, oldmm); if (retval) goto out; /* 也暂时不看 */ retval = khugepaged_fork(mm, oldmm); if (retval) goto out; prev = NULL; /* 遍历父进程所有vma,通过mm->mmap链表遍历 */ for (mpnt = oldmm->mmap; mpnt; mpnt = mpnt->vm_next) { /* mpnt指向父进程的一个vma */ struct file *file; /* 父进程的此vma标记了不复制 */ if (mpnt->vm_flags & VM_DONTCOPY) { /* 做统计,因为上面把父进程的total_vm、shared_vm、exec_vm、stack_vm都复制过来了,这些等于父进程所有vma的页的总和,这里这个vma不复制,要相应减掉此vma的页数量 */ vm_stat_account(mm, mpnt->vm_flags, mpnt->vm_file, -vma_pages(mpnt)); continue; } charge = 0; /* 此vma要求需要检查是否有足够的空闲内存用于映射 */ if (mpnt->vm_flags & VM_ACCOUNT) { /* 此vma的页数量, (mpnt->vm_end - mpnt->vm_start) >> PAGE_SHIFT */ unsigned long len = vma_pages(mpnt); /* 安全检查,是否有足够的内存 */ if (security_vm_enough_memory_mm(oldmm, len)) /* sic */ goto fail_nomem; charge = len; } /* 分配一个vma结构体用于子进程使用 */ tmp = kmem_cache_alloc(vm_area_cachep, GFP_KERNEL); /* 分配失败 */ if (!tmp) goto fail_nomem; /* 直接复制父进程的vma的数据到子进程的vma */ *tmp = *mpnt; /* 初始化子进程新的vma的anon_vma_chain为空 */ INIT_LIST_HEAD(&tmp->anon_vma_chain); /* 视情况复制父进程vma的权限,非vm_flags */ retval = vma_dup_policy(mpnt, tmp); if (retval) goto fail_nomem_policy; /* 将子进程新的vma的vm_mm指向子进程的mm */ tmp->vm_mm = mm; /* 对父子进程的anon_vma和anon_vma_chain进行处理 * 如果父进程的此vma没有anon_vma,直接返回,vma用于映射文件应该会没有anon_vma */ if (anon_vma_fork(tmp, mpnt)) goto fail_nomem_anon_vma_fork; tmp->vm_flags &= ~VM_LOCKED; tmp->vm_next = tmp->vm_prev = NULL; /* 获取vma所映射的文件,如果是匿名映射区,则为空 */ file = tmp->vm_file; /* 如果此vma是映射文件使用 */ if (file) { /* 文件对应的inode */ struct inode *inode = file_inode(file); /* 文件inode对应的address_space */ struct address_space *mapping = file->f_mapping; /* 增加file的引用计数 */ get_file(file); /* 如果此vma区被禁止写此文件,则减少文件对应inode的写进程的引用次数 */ if (tmp->vm_flags & VM_DENYWRITE) atomic_dec(&inode->i_writecount); mutex_lock(&mapping->i_mmap_mutex); if (tmp->vm_flags & VM_SHARED) atomic_inc(&mapping->i_mmap_writable); flush_dcache_mmap_lock(mapping); /* insert tmp into the share list, just after mpnt */ if (unlikely(tmp->vm_flags & VM_NONLINEAR)) vma_nonlinear_insert(tmp, &mapping->i_mmap_nonlinear); else vma_interval_tree_insert_after(tmp, mpnt, &mapping->i_mmap); flush_dcache_mmap_unlock(mapping); mutex_unlock(&mapping->i_mmap_mutex); } /* 此vma用于映射hugetlbfs中的大页的情况 */ if (is_vm_hugetlb_page(tmp)) reset_vma_resv_huge_pages(tmp); /* pprev是指向子进程的mm->mmap(用于vma排序存放的链表) * 第一次循环时将子进程的mm->mmap指向tmp * 后面的循环将前一个vma的vm_next指向当前mva */ *pprev = tmp; /* 虽然到这来tmp->vm_next,但是pprev指向tmp->vm_next,结合上面的*pprev = tmp,可以起到下次循环将tmp->vm_next指向tmp的作用 */ pprev = &tmp->vm_next; /* tmp的前一个vma是prev */ tmp->vm_prev = prev; /* 将tmp作为prev */ prev = tmp; /* 将vma加入到mm的mm_rb这个vma红黑树中 */ __vma_link_rb(mm, tmp, rb_link, rb_parent); rb_link = &tmp->vm_rb.rb_right; rb_parent = &tmp->vm_rb; /* 子进程mm的线性区个数++ */ mm->map_count++; /* 做页表的复制 * 将父进程的vma对应的开始地址到结束地址这段地址的页表复制到子进程中 * 如果这段vma有可能会进行写时复制(vma可写,并且不是共享的VM_SHARED),那就会对子进程和父进程的页表项都设置为映射的页是只读的(vma中权限是可写),这样写时会发生缺页异常,在缺页异常中做写时复制 */ retval = copy_page_range(mm, oldmm, mpnt); if (tmp->vm_ops && tmp->vm_ops->open) tmp->vm_ops->open(tmp); if (retval) goto out; } /* a new mm has just been created */ /* 与体系架构相关的dup_mmap处理 */ arch_dup_mmap(oldmm, mm); retval = 0; out: /* 释放子进程mm->mmap_sem这个读写信号量的写锁 */ up_write(&mm->mmap_sem); /* 刷新父进程的页表tlb */ flush_tlb_mm(oldmm); /* 释放父进程mm->mmap_sem这个读写信号量的写锁 */ up_write(&oldmm->mmap_sem); uprobe_end_dup_mmap(); return retval; fail_nomem_anon_vma_fork: mpol_put(vma_policy(tmp)); fail_nomem_policy: kmem_cache_free(vm_area_cachep, tmp); fail_nomem: retval = -ENOMEM; vm_unacct_memory(charge); goto out; }
在dup_mm()中会对父进程的所有vma进行复制到子进程的操作,由于我们只看匿名线性区,并且只需要分析一个,这里我们就主要看匿名线性区会做什么操作,可以看出来,对于匿名线性区的处理,dup_mm中一个最重要的函数就是anon_vma_fork(),在anon_vma_fork()中,首先判断传入的父进程是否有anon_vma,然后调用anon_vma_clone()处理,之后会为子进程的vma创建一个anon_vma和anon_vma_chain,之后再对这两个结构进行处理:
/* vma为子进程的vma,pvma为父进程的vma,如果父进程的此vma没有anon_vma,直接返回 */ int anon_vma_fork(struct vm_area_struct *vma, struct vm_area_struct *pvma) { struct anon_vma_chain *avc; struct anon_vma *anon_vma; int error; /* 父进程的此vma没有anon_vma,直接返回 */ if (!pvma->anon_vma) return 0; /* 这里开始先检查父进程的此vma是否有anon_vma,有则继续,而上面进行了判断,只有父进程的此vma有anon_vma才会执行到这里 * 这里会遍历父进程的vma的anon_vma_chain链表,对每个结点新建一个anon_vma_chain,然后 * 设置新的avc->vma指向子进程的vma * 设置新的avc->anon_vma指向父进程anon_vma_chain结点指向的anon_vma(这个anon_vma不一定属于父进程) * 将新的avc->same_vma加入到子进程的anon_vma_chain链表中 * 将新的avc->rb加入到父进程anon_vma_chain结点指向的anon_vma */ error = anon_vma_clone(vma, pvma); if (error) return error; /* 分配一个anon_vma结构用于子进程,将其refcount设为1,anon_vma->root指向本身 * 即使此vma是用于映射文件的,也会分配一个anon_vma */ anon_vma = anon_vma_alloc(); if (!anon_vma) goto out_error; /* 分配一个struct anon_vma_chain结构 */ avc = anon_vma_chain_alloc(GFP_KERNEL); if (!avc) goto out_error_free_anon_vma; /* 将新的anon_vma的root指向父进程的anon_vma的root */ anon_vma->root = pvma->anon_vma->root; /* 对父进程与子进程的anon_vma共同的root的refcount进行+1 */ get_anon_vma(anon_vma->root); /* Mark this anon_vma as the one where our new (COWed) pages go. */ vma->anon_vma = anon_vma; /* 对这个新的anon_vma上锁 */ anon_vma_lock_write(anon_vma); /* 新的avc的vma指向子进程的vma * 新的avc的anon_vma指向子进程vma的anon_vma * 新的avc的same_vma加入到子进程vma的anon_vma_chain链表的头部 * 新的avc的rb加入到子进程vma的anon_vma的红黑树中 */ anon_vma_chain_link(vma, avc, anon_vma); /* 对这个anon_vma解锁 */ anon_vma_unlock_write(anon_vma); return 0; out_error_free_anon_vma: put_anon_vma(anon_vma); out_error: unlink_anon_vmas(vma); return -ENOMEM; }
我们再看看anon_vma_clone():
/* dst为子进程的vma,src为父进程的vma */ int anon_vma_clone(struct vm_area_struct *dst, struct vm_area_struct *src) { struct anon_vma_chain *avc, *pavc; struct anon_vma *root = NULL; /* 遍历父进程的每个anon_vma_chain链表中的结点,保存在pavc中 */ list_for_each_entry_reverse(pavc, &src->anon_vma_chain, same_vma) { struct anon_vma *anon_vma; /* 分配一个新的avc结构 */ avc = anon_vma_chain_alloc(GFP_NOWAIT | __GFP_NOWARN); /* 如果分配失败 */ if (unlikely(!avc)) { unlock_anon_vma_root(root); root = NULL; /* 再次分配,一定要分配成功 */ avc = anon_vma_chain_alloc(GFP_KERNEL); if (!avc) goto enomem_failure; } /* 获取父结点的pavc指向的anon_vma */ anon_vma = pavc->anon_vma; /* 对anon_vma的root上锁 * 如果root != anon_vma->root,则对root上锁,并返回anon_vma->root * 第一次循环,root = NULL */ root = lock_anon_vma_root(root, anon_vma); /* * 设置新的avc->vma指向子进程的vma * 设置新的avc->anon_vma指向父进程anon_vma_chain结点指向的anon_vma(这个anon_vma不一定属于父进程) * 将新的avc->same_vma加入到子进程的anon_vma_chain链表头部 * 将新的avc->rb加入到父进程anon_vma_chain结点指向的anon_vma */ anon_vma_chain_link(dst, avc, anon_vma); } /* 释放根的锁 */ unlock_anon_vma_root(root); return 0; enomem_failure: unlink_anon_vmas(dst); return -ENOMEM; }
在调用完anon_vma_clone()结束后,整个结构会如下图:
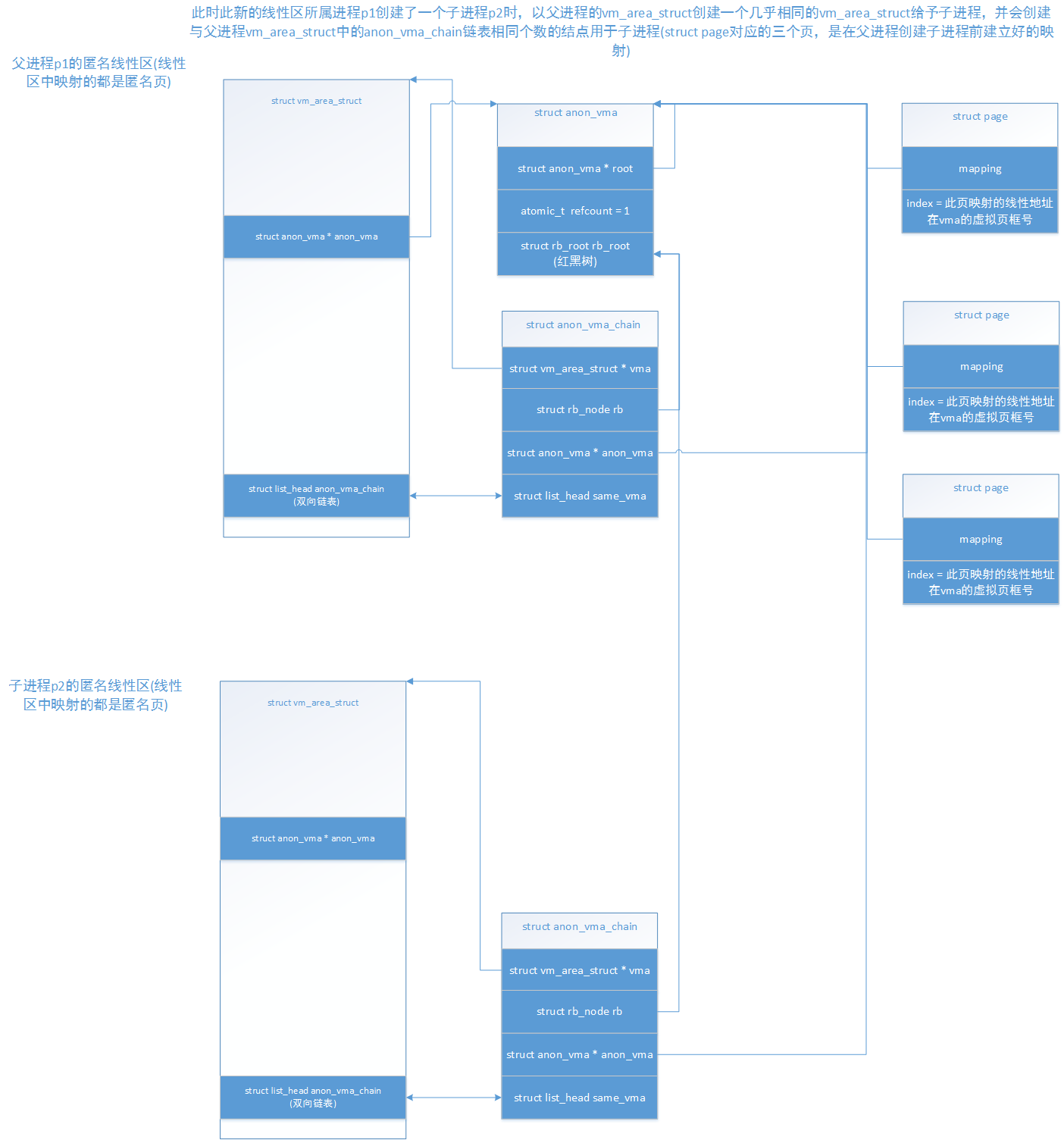
这张图是在anon_vma_fork()中调用anon_vma_clone()结束后父子进程匿名线性区的关系图,可以看出anon_vma_clone()做的工作只是创建了一个anon_vma_chain结构用于链入到子进程(因为父进程只有一个anon_vma_chain),并且加入到父进程的anon_vma红黑树中。需要注意,这里是因为父进程只有一个anon_vma_chain,所以才为子进程创建一个anon_vma_chain,如果父进程有N个anon_vma_chain,这里也会为子进程创建N个anon_vma_chain。同一条链上有多个anon_vma_chain,那么它们所属的vma是相同的,只是加入到的anon_vma的红黑树不同,之后会看到。
再看看anon_vma_clone()之后进行的处理,如下:
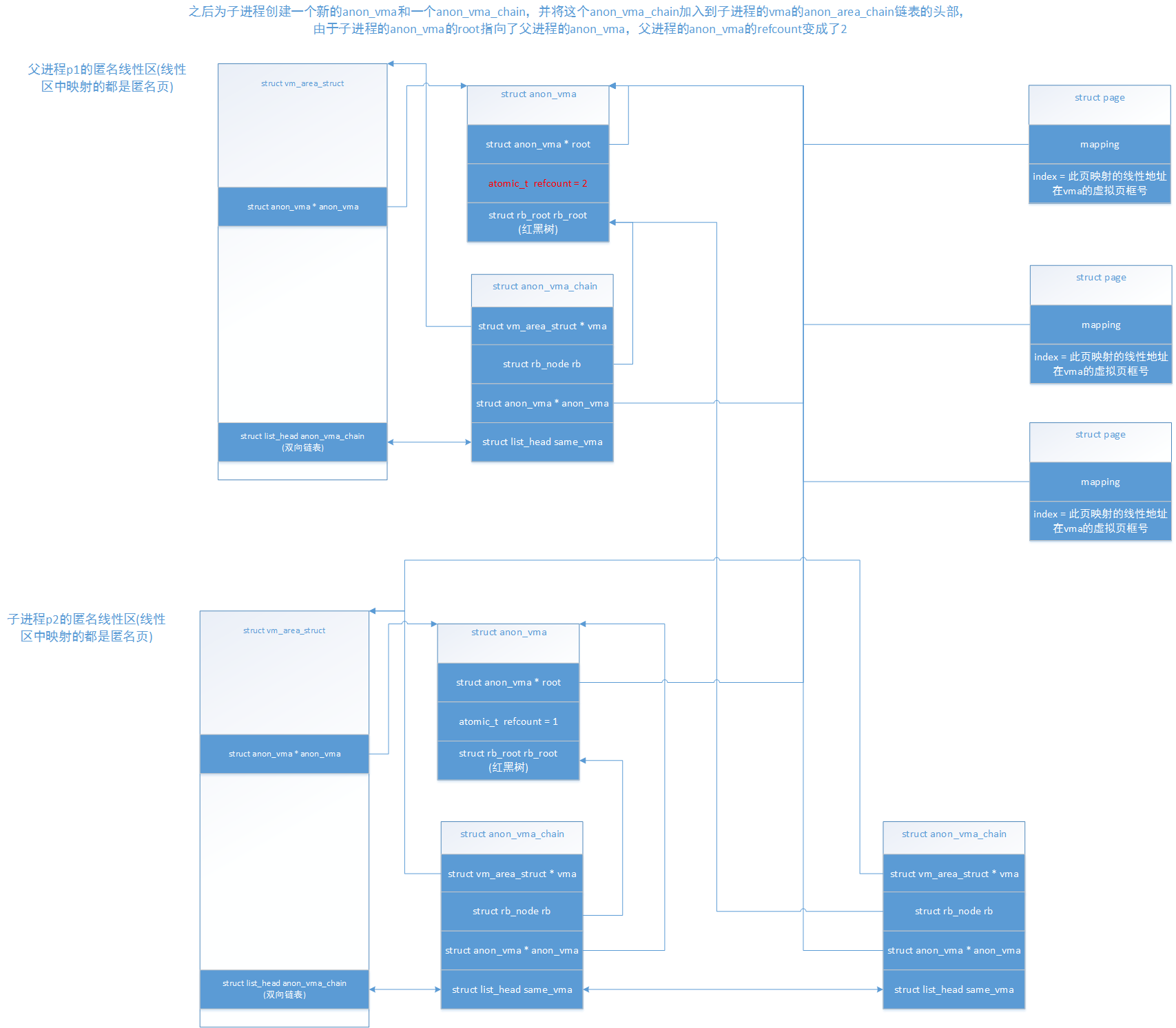
可以看到,子进程的anon_vma的root指向了父进程的anon_vma,并且父进程的anon_vma的refcount++。这时候父进程p1有一个anon_vma_chain,而子进程p2有两个anon_vma_chain,子进程这两个anon_vma_chain分别加入了父进程anon_vma的红黑树和子进程anon_vma的红黑树,但是这两个anon_vma_chain都是属于子进程p2的。我们看看父进程的红黑树,里面现在有两个anon_vma_chain,一个是父进程自己的,一个是子进程的,这样已经映射好的页就可以通过父进程的anon_vma的红黑树分别访问到父进程和子进程。
整个过程完成之后,最终结构如此图,但是即使到这里,子进程对这些已经映射的页还是不能访问的,原因是还没有为这些vma映射好的页建立页表,这个工作在dup_mm()对父进程每个vma遍历的最后的copy_page_range()函数,此函数如下:
int copy_page_range(struct mm_struct *dst_mm, struct mm_struct *src_mm, struct vm_area_struct *vma) { pgd_t *src_pgd, *dst_pgd; unsigned long next; /* 开始地址 */ unsigned long addr = vma->vm_start; /* 结束地址 */ unsigned long end = vma->vm_end; unsigned long mmun_start; /* For mmu_notifiers */ unsigned long mmun_end; /* For mmu_notifiers */ bool is_cow; int ret; /* 这里只会处理匿名线性区或者包含有(VM_HUGETLB | VM_NONLINEAR | VM_PFNMAP | VM_MIXEDMAP)这几种标志的vma */ if (!(vma->vm_flags & (VM_HUGETLB | VM_NONLINEAR | VM_PFNMAP | VM_MIXEDMAP))) { if (!vma->anon_vma) return 0; } /* 如果是使用了hugetlbfs中的大页的情况 vma->vm_flags & VM_HUGETLB */ if (is_vm_hugetlb_page(vma)) return copy_hugetlb_page_range(dst_mm, src_mm, vma); if (unlikely(vma->vm_flags & VM_PFNMAP)) { ret = track_pfn_copy(vma); if (ret) return ret; } /* 检查是否可能会对此vma进行写入(要求此vma是非共享vma,并且可能写入) (flags & (VM_SHARED | VM_MAYWRITE)) == VM_MAYWRITE */ is_cow = is_cow_mapping(vma->vm_flags); mmun_start = addr; mmun_end = end; /* 此vma可能会进行写时复制的处理 */ if (is_cow) /* 如果此vma使用了mm->mmu_notifier_mm这个通知链,则初始化这个通知链,通知的地址范围是addr ~ end */ mmu_notifier_invalidate_range_start(src_mm, mmun_start, mmun_end); ret = 0; /* 获取子进程对于开始地址对应的页全局目录项 */ dst_pgd = pgd_offset(dst_mm, addr); /* 获取父进程对于开始地址对应的页全局目录项 * 实际这两项在页全局目录的偏移是一样的,只是项中的数据不同,子进程的页全局目录项是空的 */ src_pgd = pgd_offset(src_mm, addr); do { /* 获取从addr ~ end,一个页全局目录项从addr开始能够映射到的结束地址,返回这个结束地址 * 循环后会将addr = next,这样下次就会从 next ~ end,一步一步以pud能映射的地址范围长度减小 */ next = pgd_addr_end(addr, end); /* 父进程的页全局目录项是空的的情况 */ if (pgd_none_or_clear_bad(src_pgd)) continue; /* 对这个页全局目录项对应的页上级目录项进行操作 * 并会不停深入,直到页表项 * 里面的处理与这个循环几乎一致,不过会在里面判断是否要对dst_pgd的各层申请页用于页表 */ if (unlikely(copy_pud_range(dst_mm, src_mm, dst_pgd, src_pgd, vma, addr, next))) { ret = -ENOMEM; break; } } while (dst_pgd++, src_pgd++, addr = next, addr != end); if (is_cow) mmu_notifier_invalidate_range_end(src_mm, mmun_start, mmun_end); return ret; }
当这个函数对vma的线性地址区间的页表项映射完成后,子进程的vma已经可以正确进行访问了。我们看看已经映射好的页框怎么通过反向映射,找到父子进程映射了此页的vma,如下:
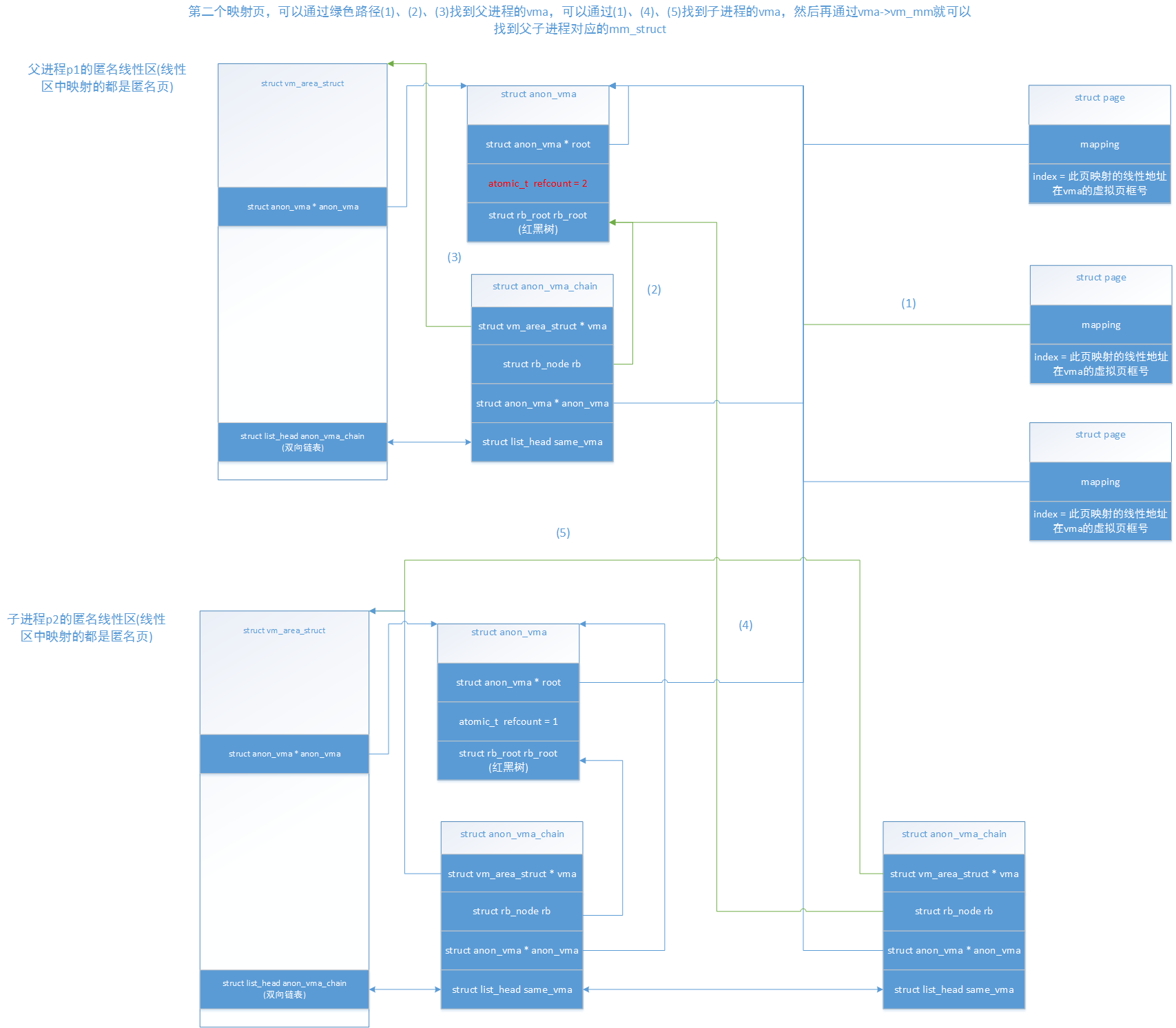
可以很清楚看出来,一个映射了的匿名页,主要通过其指向的anon_vma里的保存anon_vma_chain的红黑树进行访问各个映射了此页的vma。需要注意,这种情况只是发生在父进程映射好了这几个页之后,才创建的子进程。
接下来看看父进程创建子进程完毕后,父子进程映射没有访问过的页时发生的情况,并看看反向映射的结果。
首先我们先看子进程此时访问了此vma里没有被映射的线性地址,可以根据之前分析的do_anonymous_page()函数,得出如下结果:

会将此新的页的mapping指向子进程p2的anon_vma,并且会为子进程p2建立此页的页表映射,其他并没有任何改变,我们再看看此时对新映射的页进行反向映射:
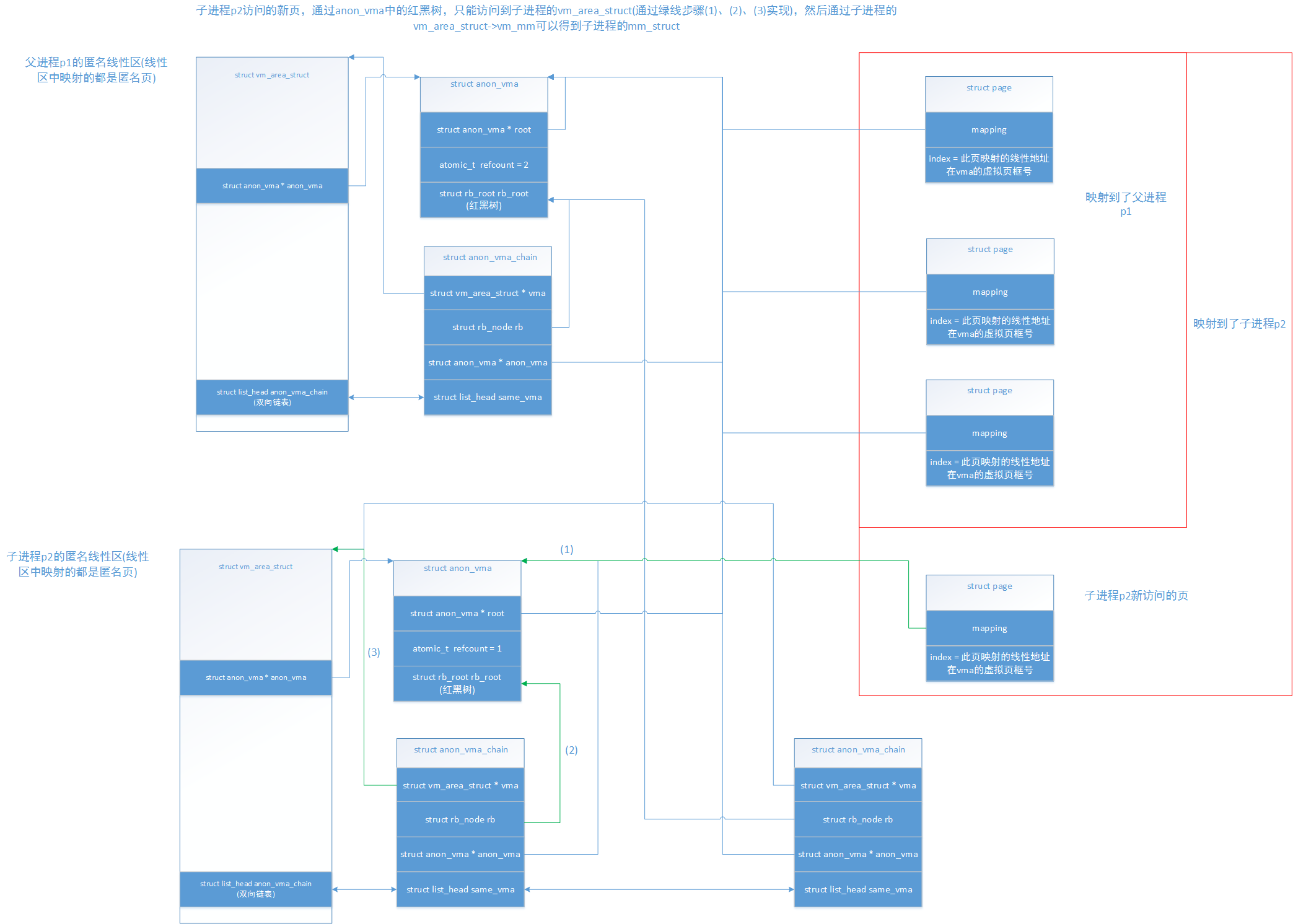
可以清楚看出来,子进程新映射的页,通过反向映射,只能访问到子进程,不能访问的父进程,这就是为什么子进程会有两个anon_vma_chain的原因。如果此时子进程p2创建一个子进程p3,那么子进程p3的此vma就会有3个anon_vma_chain,它们都属于子进程p3的此vma,只是分别加入了祖父进程p1,父进程p2,和本身进程p3的vma的红黑树中。
我们继续结合之前分析的do_anonymous_page(),再来看看如果是父进程映射了一个新页的情况是怎么样的:
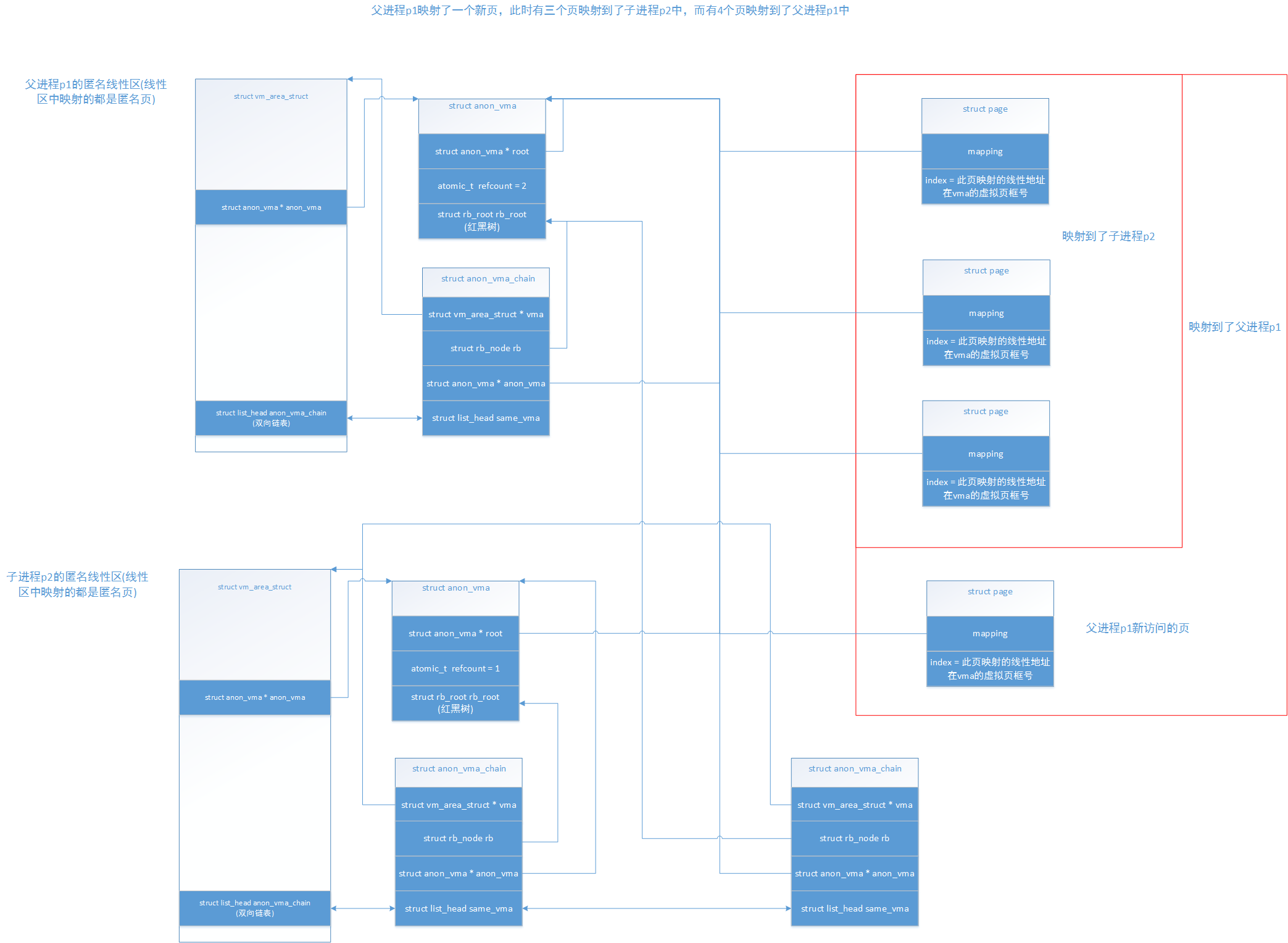
可以看到父进程新访问的匿名页,它的mapping指向了父进程的anon_vma,再看看父进程访问的新页进行反向映射,结果如下:
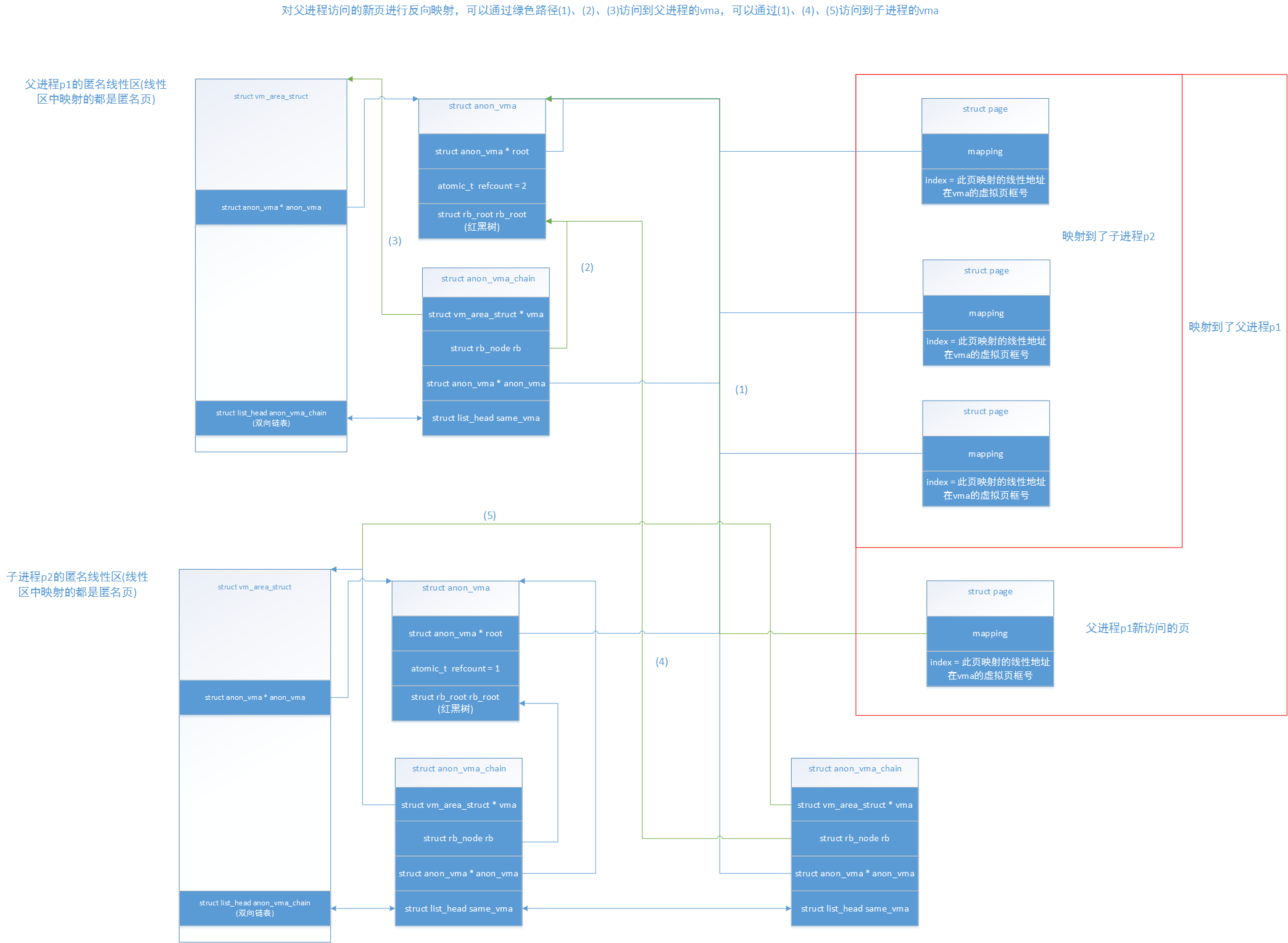
发现没,一个很奇怪的问题,父进程新映射的页能够通过反向映射访问的子进程的vma,所以在反向映射时都要对遍历到的vma所属进程的页表进行检查,检查是否有映射此页,具体方法是:通过页描述符中的index(记录有此页是是vma中的虚拟页框号),通过以下函数计算,即可获得此匿名页的起始线性地址:
static inline unsigned long __vma_address(struct page *page, struct vm_area_struct *vma) { /* 获取此页在vma所属进程地址空间的线性地址 * 如果是匿名线性区,page->index中保存的是此页映射到了匿名线性区中的虚拟页框号 */ pgoff_t pgoff = page_to_pgoff(page); /* vma->vm_pgoff保存vma起始地址所在的虚拟页框号 * pgoff保存的是page在此vma的进程地址空间的虚拟页框号 * vma->vm_start保存的是vma的起始地址 */ return vma->vm_start + ((pgoff - vma->vm_pgoff) << PAGE_SHIFT); }
这样就获得了page在vma所属的进程空间的线性地址,然后通过此线性地址找到进程页表中对应的页表项,再通过检查页表项中映射的物理页框号是否与此反向映射的物理页框号相同,如果是,则说明此页表项映射了此物理页,否则说明此页表项并不是映射了此物理页,具体代码在page_check_address(),这里就不列出来了。
回过头,我们再看看进程创建一个新的vma,然后这个vma能够与前/后的vma进行合并的情况,在这种情况中,新的vma会与能够合并的vma共用一个anon_vma,如果这个新的vma访问了一个页的时候,这个页的mapping会指向这个能够合并的vma的anon_vma,然后通过上面反向映射的步骤,通过anon_vma的红黑树找遍历链接到此的vma,发现此页并不属于能够合并的vma(因为page->index肯定不在能够合并的vma的地址区间对应的虚拟页框号区间中),但是遍历到新的vma时就能够判断出此page是映射到了新的vma中。注意,以上所说情景的全都是基于堆和栈以及私有匿名mmap的匿名页反向映射,而共享匿名mmap共享内存(其实就是shmem)实际并不是基于匿名页反向映射的,可以说是基于文件页的反向映射的。
关于vma是向下增长的类型(栈)
如上,先考虑一种理想情况,在系统中所有进程的栈大小都是足够使用的,,那么所有进程的栈的vma的开始线性地址和结束线性地址都会相同(见dup_mm()),而当某个进程的栈不够用了,需要向下扩大时,会调用expand_downwards():
/* 扩大进程栈大小,进程栈向下增长的情况 * vma: 当前进程栈的vma * address: 产生缺页异常的address,并且 address < vma->vm_start */ int expand_downwards(struct vm_area_struct *vma, unsigned long address) { int error; /* 为vma准备反向映射条件 * 检查此vma能与前后的vma进行合并吗,如果可以,则使用能够合并的那个vma的anon_vma,如果不能够合并,则申请一个空闲的anon_vma * 创建一个新的anon_vma_chain * 将avc->anon_vma指向获得的vma(此vma可能是新建的,也可能是可以合并的vma的anon_vma),avc->vma指向vma,并把avc加入到vma的anon_vma_chain中 */ /* 如果栈已经在使用中,是栈空间不足导致需要向下增长的,那么这里基本不做任何工作,因为栈的vma已经有了anon_vma */ if (unlikely(anon_vma_prepare(vma))) return -ENOMEM; /* 获取目标address线性地址对应的页的起始地址 */ address &= PAGE_MASK; /* 检查此地址是否合理 */ error = security_mmap_addr(address); if (error) return error; /* 对anon_vma->root->rwsem上锁 */ vma_lock_anon_vma(vma); /* 因为是向下扩展,address一定会小于vma->vm_start,因为外面一层函数判断过了才会调用到此函数 */ if (address < vma->vm_start) { unsigned long size, grow; /* address到进程栈结束的大小范围,也就是栈扩大后最小的大小 */ size = vma->vm_end - address; /* address到进程栈开始地址中间空出的大小(以页为单位) */ grow = (vma->vm_start - address) >> PAGE_SHIFT; error = -ENOMEM; if (grow <= vma->vm_pgoff) { /* 做检查 */ error = acct_stack_growth(vma, size, grow); if (!error) { /* 对该进程页表上锁 */ spin_lock(&vma->vm_mm->page_table_lock); /* 将此vma的anon_vma_chain链表上的结点从它们加入的红黑树中移除 */ anon_vma_interval_tree_pre_update_vma(vma); /* 将此vma的开始线性地址设置为address */ vma->vm_start = address; /* 将此vma的开始线性地址对应的虚拟页框号更新 */ vma->vm_pgoff -= grow; /* 将此vma的anon_vma_chain链表上的结点重新加入到它们原本所属的红黑树中(通过avc->anon_vma->rb_root) */ anon_vma_interval_tree_post_update_vma(vma); vma_gap_update(vma); /* 解锁 */ spin_unlock(&vma->vm_mm->page_table_lock); perf_event_mmap(vma); } } } vma_unlock_anon_vma(vma); khugepaged_enter_vma_merge(vma, vma->vm_flags); /* 更新vma所属mm_struct的vma红黑树 */ validate_mm(vma->vm_mm); return error; }
可以看到这里更新了vma->vm_start和vma->vm_pgoff。这样对反向映射就没有什么影响了,即使栈的vm_start改变了,一样可以通过vma_address()函数获取物理页框对应的线性地址。
文件页的反向映射
文件页有两种模式:
- 没有进程地址映射的文件页: 单纯的存在于文件的address_space空间中, 进程通过read/write等IO系统调用去读写这些文件页.
- 有进程地址映射的文件页: 这些文件页也还是存在于文件的address_space空间中, 并且同时被映射到了一个或多个进程的虚拟地址空间, 进程可以通过内存读写的形式修改这些文件页.
对于第一种没有进程地址映射的文件页来说, 它是不需要进行反向映射的, 因为它只属于文件, 这些页的mapping指向address_space, 当需要回收这些页时, 可以通过page->mapping找到对应的address_space, 然后从address_space中的radix_tree中将它们删除即可.
而对于第二种文件页, 它在第一种文件页的基础上又被映射到了进程的虚拟地址空间中, 这种页就需要反向映射了, 但是实现方式并没有匿名页那么复杂, 实际上, address_space中有个i_map的红黑树, 里面存放的是所有映射了此文件的进程的vm_area_struct加入进来. 所以当需要对所有映射了此文件页的进程的页表做修改时, 可以通过这个address_space的i_map来访问这些进程, 不过需要注意的是, address_space代表的是整个文件的空间, 映射了文件的进程加入到i_map中, 在回收页框时, 虽然要遍历所有i_map中的所有进程, 但是不代表所有进程都映射了此页, 所以遍历过程中, 还是需要判断进程是否有映射此页.
总结
整篇文章写得并不好,这段内容实际上我也不知道该怎么写,涉及到太多东西,写得过于凌乱,如有不足欢迎指正,谢谢。
待研究解决的问题:
- 对于匿名线性区vma,它的vm_file指针是否会指向一个struct file结构,是否是swap file。
- 如果在父进程创建子进程完成后,父进程此vma中的映射的页全部取消掉映射,是否会把vma的anon_vma的红黑树中的anon_vma_chain都清除。
- 博客园有没有点击查看大图的功能?看不清楚图片的可以右键从新窗口打开图片。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号