


8gu-xxxjob
XXXJOB
好的,我们来详细介绍一下 XXL-JOB 的基本原理,并提供一个可以直接在 Draw.io 中导入的框架图文件。
XXL-JOB (XXXJob) 基本原理
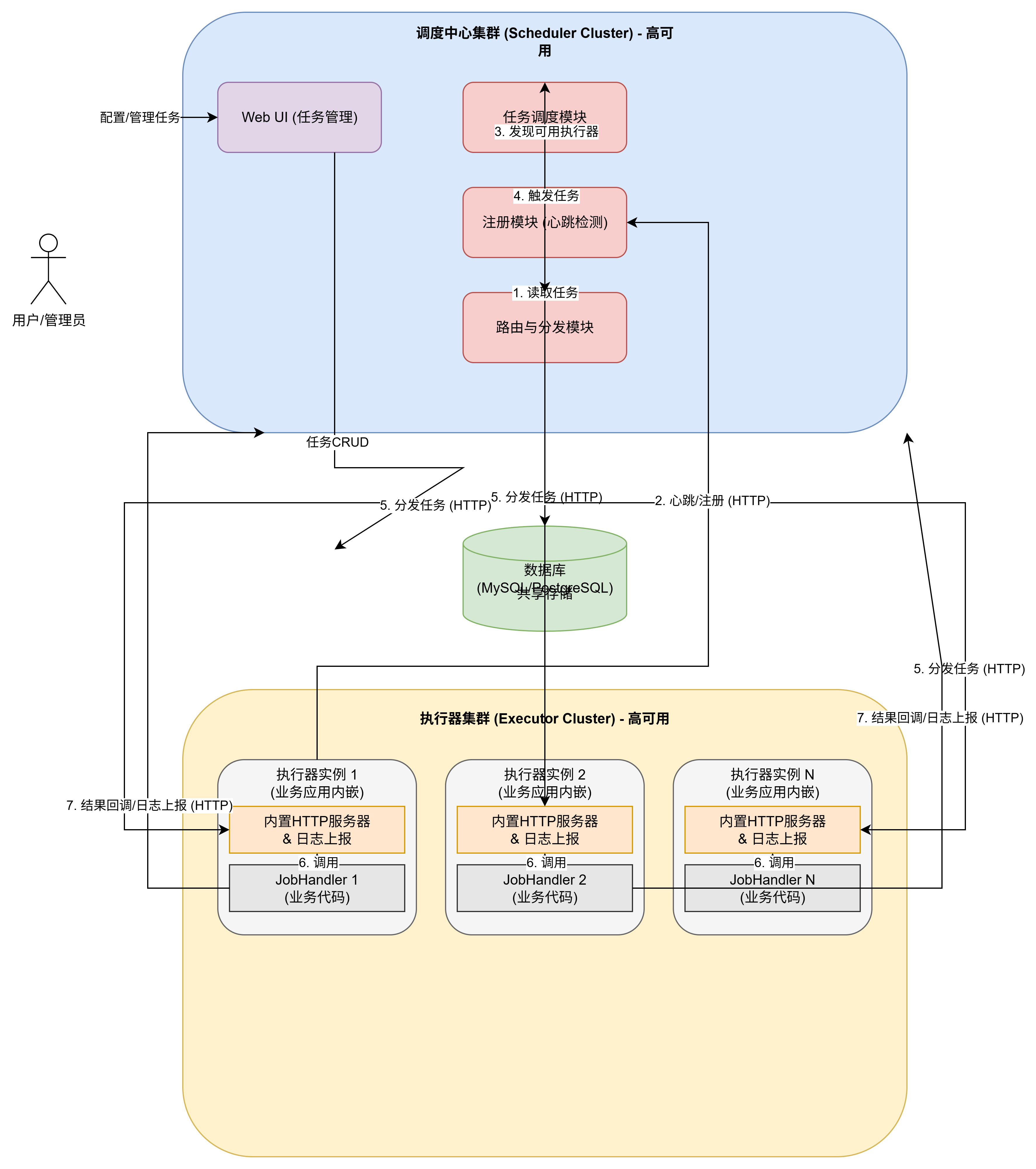
XXL-JOB 是一个轻量级的分布式任务调度平台,其核心设计思想是“中心化调度,去中心化执行”,将调度与任务执行彻底解耦,使得系统更加稳定、易于扩展和维护。
它的架构主要由调度中心 (Scheduler) 和 执行器 (Executor) 两大核心部分组成。
1. 调度中心 (Scheduler)
调度中心是整个系统的“大脑”,是一个独立的、可视化的 Web 应用(通常是 Spring Boot 项目)。它不执行任何业务逻辑,只负责调度和管理。
- 核心职责:
- 任务管理: 提供一个统一的 Web 管理界面(Admin 后台),让用户可以方便地对任务进行新增、修改、删除、启动/停止、手动触发等操作。
- 执行器管理: 调度中心扮演了“注册中心”的角色。所有执行器启动后,都会主动向调度中心注册,并周期性地发送心跳来维持在线状态。调度中心通过此机制来管理所有可用的执行器实例。
- 任务调度: 内置调度引擎(早期基于 Quartz),根据任务配置的 CRON 表达式,在预定时间精准地触发任务。
- 任务分发: 当任务触发时,调度中心会根据预设的“路由策略”(如轮询、随机、分片广播等)从可用的执行器列表中选择一个或多个实例。
- 远程调用: 通过 HTTP 协议向选定的执行器发送任务执行请求。
- 监控与日志: 接收执行器的任务执行回调结果和执行日志,并将其持久化到数据库中,方便用户在后台实时查看任务状态和排查问题。
2. 执行器 (Executor)
执行器是任务的实际承载和处理单元。它不是一个独立的应用,而是以一个 Jar 包(SDK)的形式被集成到用户的业务应用中。
- 核心职责:
- 服务注册与心跳: 执行器启动时,会根据配置的调度中心地址,主动发起注册,并将自己的地址、应用名等信息上报。随后会启动一个定时线程,持续向调度中心发送心跳。
- 接收调度: 执行器内部嵌入了一个轻量级的 Web 服务器(如 Netty),用于监听来自调度中心的 HTTP 调度请求。
- 任务执行: 收到请求后,执行器会通过一个专用的线程池来异步执行具体的业务逻辑代码(即用户编写的
JobHandler)。 - 结果回调: 任务执行完成后,无论成功或失败,执行器都会将执行结果(包括日志)通过 HTTP 回调给调度中心。
核心工作流程
- 启动与注册: 业务应用(内嵌执行器)启动,向调度中心发起注册和心跳。
- 定时触发: 调度中心的调度线程按时触发一个任务。
- 路由与分发: 调度中心根据任务配置的路由策略,从在线的执行器列表中选择一个,并向其发送 HTTP 执行请求。
- 执行任务: 执行器接收到请求,在本地线程池中执行对应的
JobHandler。 - 回调结果:
JobHandler执行完毕后,执行器将结果和日志上报给调度中心。 - 记录与展示: 调度中心收到回调,将结果存入数据库,并在 Web 界面上更新任务状态。
框架 Draw.io 文件
Elastic JOB
Elastic-Job 原理
Elastic-Job 是一个由当当网开源的分布式调度解决方案,专注于数据分片和弹性扩缩容。它并非一个独立的调度平台,而是一个轻量级的、无中心化的作业框架,以 Jar 包的形式提供给应用嵌入使用。它强依赖于注册中心(通常是 ZooKeeper)来完成协调工作。
核心组件
-
注册中心 (Registry Center):通常是 ZooKeeper。它是整个框架的协调核心,负责:
- 服务注册与发现:所有运行的作业节点(Job Instance)都会在 ZK 上注册为临时节点。
- 主节点选举 (Leader Election):在所有作业节点中,通过 ZK 的选举机制(抢占式创建临时节点)选举出一个主节点(Leader)。
- 状态同步与存储:存储作业的配置信息、分片信息、作业状态等。
- 分布式锁:确保某些操作(如重新分片)的原子性。
-
作业节点 (Job Instance):就是您集成了 Elastic-Job 框架的业务应用实例。每个作业节点都是一个潜在的执行者和调度者。
- 内嵌调度器:每个节点内部都包含一个调度器(如 Quartz),根据 CRON 表达式独立计时。
- 执行业务逻辑:负责执行被分配到的分片任务。
-
管控端 (Console):一个独立的 Web 应用,提供可视化的作业管理界面。它不参与核心的调度流程,其所有操作(如修改配置、触发作业)都是通过读写注册中心(ZK)来完成的。
核心工作流程与原理
Elastic-Job 的设计精髓在于其去中心化和自协调的机制。
-
启动与注册:
- 当一个集成了 Elastic-Job 的应用实例启动时,它会连接到 ZooKeeper。
- 它会在 ZK 上对应的作业名下,创建一个临时的 ZNode 节点,标志着自己“上线”。
-
主节点选举 (Leader Election):
- 所有上线的作业节点会尝试在 ZK 的特定路径下(如
/job-name/leader/election/instance)创建一个唯一的临时节点。 - 根据 ZooKeeper 的特性,只有一个节点能成功创建。这个成功的节点就成为了当前作业的 主节点 (Leader)。其他节点则成为从节点 (Follower) 并监听该主节点。
- 所有上线的作业节点会尝试在 ZK 的特定路径下(如
-
调度与分片 (Sharding):
- 所有节点(包括 Leader 和 Follower)内部的 Quartz 调度器都在独立运行,当时机到达时,它们都会被唤醒。
- 但是,只有 Leader 节点会执行核心的调度逻辑。它会:
a. 从 ZK 获取当前所有存活的作业节点列表。
b. 获取作业配置的总分片数(shardingTotalCount)。
c. 执行分片算法(如平均分配),将所有分片项(0, 1, 2...)分配给所有存活的节点。
d. 将分片结果写回 ZooKeeper,每个节点的分片信息都存储在各自对应的 ZNode 下。
-
任务执行:
- 所有节点(包括 Leader 和 Follower)都在监听 ZK 上自己对应的 ZNode。
- 当节点发现自己的分片信息被更新后,它就会获取分配给自己的分片项(如
shardingItem=0,2)。 - 随后,该节点开始执行业务逻辑,只处理属于自己分片的数据。
-
弹性扩缩容 (Elasticity & Rebalancing):
- 扩容:当一个新的应用实例启动并注册到 ZK 后,Leader 节点会监听到这个变化,并立即触发一次“重新分片”(Re-sharding),将分片项重新分配给包括新节点在内的所有节点。
- 缩容/宕机:当某个实例宕机或正常下线时,它在 ZK 上的临时节点会消失。Leader 节点同样会监听到这个变化,并触发“重新分片”,将宕机节点的分片“认领”回来,重新分配给其他存活的节点。这个过程是全自动的,保证了任务的高可用性。
-
主节点故障转移 (Leader Failover):
- 如果 Leader 节点宕机,它在 ZK 上创建的 Leader 临时节点也会消失。
- 其他 Follower 节点会监听到这个变化,并立即开始新一轮的 Leader 选举。
- 新的 Leader 产生后,会接管调度和分片的职责,整个系统恢复正常。
Elastic-Job 与 XXL-JOB (XXXJob) 的差异
这两者是目前最主流的两种分布式任务调度框架,但它们的设计哲学和适用场景有显著不同。
| 特性/方面 | Elastic-Job | XXL-JOB |
|---|---|---|
| 核心架构 | 去中心化 (Decentralized) | 中心化 (Centralized) |
| 调度中心 | 无。调度逻辑由 Leader 节点执行,依赖外部注册中心 (ZK/Nacos) 进行协调。 | 有。一个独立的“调度中心”集群,负责任务的统一触发、管理和监控。 |
| 注册中心 | 强依赖。ZK 是其协调、选举、分片、故障转移的命脉。 | 调度中心自带注册功能。执行器向调度中心注册和心跳,不依赖第三方组件。 |
| 调度触发方式 | 作业节点本地触发(内嵌 Quartz),但由 Leader 节点统一协调分片。 | 由调度中心远程触发,通过 RPC (HTTP) 调用执行器。 |
| 核心优势 | 数据分片和弹性扩缩容。为处理海量数据而生,具备极强的自愈和动态伸缩能力。 | 通用任务调度和易用性。功能全面,管理方便,上手快,侵入性低。 |
| 分片策略 | 动态、自动。节点增减会自动触发重新分片(Rebalance)。 | 手动、静态。在调度中心配置好分片数,调度中心根据路由策略下发分片参数。节点增减不会自动重分片。 |
| 故障转移 | 自动、高效。Leader 宕机自动重选;执行节点宕机,其分片会被自动分配给其他节点。 | 策略驱动。调度中心集群高可用;执行器宕机后,调度中心可根据“故障转移”策略(如轮询)重试其他节点。 |
| 依赖与运维 | 较重。必须部署和维护一套高可用的 ZooKeeper 或 Nacos 集群。 | 较轻。调度中心只需依赖一个数据库(如 MySQL),运维相对简单。 |
| 适用场景 | 适用于需要处理海量数据的任务,如批量数据处理、数据迁移、定时结算等。对系统的高可用和弹性伸缩有极高要求的场景。 | 适用于绝大多数通用定时任务,如定时发邮件、生成报表、清理缓存、业务状态轮询等。追求开发简单、管理方便的场景。 |
| 资源消耗 | 作业节点需要与 ZK 保持长连接和 Watcher,会有一定的资源开销。 | 执行器在空闲时非常轻量,仅需响应心跳和任务调度请求。 |
总结:如何选择?
-
选择 Elastic-Job:
- 当你的核心需求是处理大数据,需要将一个大任务切分成无数小片,让多台机器并行处理时。
- 当你的应用部署在云上,需要频繁地弹性扩缩容,并希望任务能够自动适应节点变化时。
- 当你对任务的高可用性要求到极致,不希望因为单点问题导致任务中断时。
-
选择 XXL-JOB:
- 当你需要一个功能全面、操作简单的可视化调度平台来管理公司内各种类型的定时任务时。
- 当你的任务大多是业务逻辑型,而非数据处理密集型时。
- 当你希望快速落地一个稳定可靠的调度系统,且不希望引入 ZK 等额外的复杂组件时。
简单来说,Elastic-Job 更像一个专注于数据分片的“类库”,而 XXL-JOB 更像一个通用的“调度管理平台”。
场景问题
好的,我们来详细探讨 XXL-JOB 的分片调度,并解决一个非常关键的进阶问题:如何在并行分片的环境下实现任务的顺序执行。
一、 XXL-JOB 分片调度示例
XXL-JOB 的分片广播(Sharding Broadcast)是其核心功能之一,旨在将一个庞大的任务分割成多个小任务,交由一个执行器集群并行处理,从而极大地提升任务执行效率。
场景:假设我们有一个用户表,包含数百万用户。现在需要每天凌晨执行一个任务,为所有用户更新积分。如果单机执行,耗时会非常长。使用分片调度,我们可以让多台机器同时处理不同段的用户。
1. XXL-JOB 管理后台配置
- 新增任务,并填写基本信息(CRON 表达式、任务描述等)。
- 路由策略:必须选择
分片广播。这是实现分片的关键。 - JobHandler:填写执行器中定义的 JobHandler 名称,例如
shardingJobHandler。 - 阻塞处理策略:通常选择
SERIAL_EXECUTION(串行执行) 或DISCARD_LATER(丢弃后续)。
2. 执行器 (Executor) 代码实现
在你的业务应用中,创建一个 JobHandler 来处理分片逻辑。
import com.xxl.job.core.context.XxlJobHelper;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
@Component
public class ShardingJobHandler {
private static Logger logger = LoggerFactory.getLogger(ShardingJobHandler.class);
/**
* 分片广播任务
*/
@XxlJob("shardingJobHandler")
public void execute() throws Exception {
// 1. 获取分片参数
int shardingTotal = XxlJobHelper.getShardingTotal(); // 获取当前任务的总分片数
int shardingIndex = XxlJobHelper.getShardingItem(); // 获取当前执行器被分配到的分片序号(从 0 开始)
XxlJobHelper.log("开始执行分片任务... 总分片数: {}, 当前分片: {}", shardingTotal, shardingIndex);
// 2. 模拟从数据库获取需要处理的用户ID列表
// 在真实场景中,这里应该是数据库查询
List<Integer> allUserIds = fetchAllUserIdsFromDB();
// 3. 核心分片逻辑:根据分片序号筛选出当前执行器需要处理的数据
List<Integer> usersToProcess = allUserIds.stream()
.filter(userId -> userId % shardingTotal == shardingIndex)
.collect(Collectors.toList());
if (usersToProcess.isEmpty()) {
XxlJobHelper.log("分片 {} 没有需要处理的用户数据。", shardingIndex);
return;
}
XxlJobHelper.log("分片 {} 开始处理 {} 个用户, 用户ID示例: {}", shardingIndex, usersToProcess.size(), usersToProcess.stream().limit(5).collect(Collectors.toList()));
// 4. 执行业务逻辑
for (Integer userId : usersToProcess) {
// 模拟为用户更新积分
logger.info("分片 {} 正在为用户 {} 更新积分...", shardingIndex, userId);
Thread.sleep(10); // 模拟业务耗时
}
XxlJobHelper.log("分片 {} 处理完成。", shardingIndex);
}
// 模拟方法:从数据库获取所有用户ID
private List<Integer> fetchAllUserIdsFromDB() {
// In a real application, this would be: SELECT id FROM user;
return IntStream.rangeClosed(1, 1000).boxed().collect(Collectors.toList());
}
}
工作流程
假设有 3 台执行器实例在线:
- 调度中心触发任务,发现路由策略是“分片广播”,总共有 3 个执行器。
- 调度中心会同时向这 3 台执行器发送调度请求,并携带不同的分片参数:
- 执行器A 收到:
shardingTotal=3,shardingItem=0 - 执行器B 收到:
shardingTotal=3,shardingItem=1 - 执行器C 收到:
shardingTotal=3,shardingItem=2
- 执行器A 收到:
- 每个执行器根据
userId % 3 == shardingItem的逻辑,分别处理userId为 (0, 3, 6...)、(1, 4, 7...) 和 (2, 5, 8...) 的用户,实现了并行处理。
二、 如何实现分片执行有顺序的任务
这是一个非常关键且复杂的问题。首先必须明确一点:XXL-JOB 的分片广播天生是为了并行、无序处理而设计的,其核心目的就是打乱顺序、并行执行以提升效率。 强行让分片任务按顺序执行,违背了其设计初衷,并且会使实现变得复杂。
但是,业务场景是多样的,有时我们确实需要处理有依赖关系的阶段性任务。例如,必须先完成数据对账(任务A),然后才能进行数据结算(任务B)。
下面提供几种实现思路,从简单到复杂:
方法一:放弃分片,回归单体顺序执行(最简单)
如果任务的数据量不大,或者对执行时间不敏感,最简单的办法就是不要使用分片。
- 路由策略:选择
第一个或轮询。 - 实现:在 JobHandler 的
execute方法内部,按顺序调用你的业务方法。
@XxlJob("sequentialJobHandler")
public void execute() {
XxlJobHelper.log("开始执行顺序任务...");
// 步骤1:数据对账
stepA_checkData();
// 步骤2:数据结算
stepB_settleData();
XxlJobHelper.log("顺序任务执行完毕。");
}
- 优点:实现简单,逻辑清晰。
- 缺点:无法利用集群优势,性能差,有单点风险。
方法二:任务编排,化整为零(推荐)
这是处理此类问题的最佳实践。不要试图在一个任务内控制顺序,而是将有顺序依赖的步骤拆分成多个独立的 XXL-JOB 任务,然后通过触发机制将它们串联起来,形成一个工作流(Workflow)。
实现步骤:
- 创建多个任务:
- 任务A (
taskA_checkData):负责数据对账。 - 任务B (
taskB_settleData):负责数据结算。
- 任务A (
- 使用 API 触发后续任务:XXL-JOB 调度中心提供了 RESTful API,允许你通过 HTTP 请求来触发一个任务。
- 在任务A的 JobHandler 代码执行成功后,调用调度中心的 API 来触发任务B。
任务A 的代码示例:
@XxlJob("taskA_checkData")
public void execute() {
boolean success = false;
try {
XxlJobHelper.log("任务A:开始执行数据对账...");
// ... 执行对账业务逻辑 ...
XxlJobHelper.log("任务A:数据对账完成。");
success = true;
} catch (Exception e) {
XxlJobHelper.log("任务A:执行失败", e);
}
// 如果任务A成功,则触发任务B
if (success) {
triggerNextJob("taskB_settleData");
}
}
// 封装一个触发下游任务的HTTP客户端方法
private void triggerNextJob(String jobHandlerName) {
// 找到任务B在调度中心配置的ID
int jobId = findJobIdByHandlerName(jobHandlerName);
if (jobId > 0) {
XxlJobHelper.log("准备触发下游任务,Job ID: {}", jobId);
// 调用XXL-JOB Admin的API: /jobinfo/trigger
// 你需要自己实现一个HttpClient来发送POST请求
// 请求地址: http://{admin_address}/jobinfo/trigger
// 请求参数: {"id": jobId, "executorParam": "triggered by taskA"}
// 注意:API调用需要登录凭证,你需要处理Cookie或Token认证
}
}
// 模拟方法,实际应通过API或数据库查询
private int findJobIdByHandlerName(String handlerName) {
// In a real scenario, you might query the XXL-JOB database or call another API
// to get the job ID based on its handler name. For this example, we'll hardcode it.
if ("taskB_settleData".equals(handlerName)) {
return 15; // 假设任务B的ID是15
}
return 0;
}
- 优点:逻辑解耦,职责单一,可维护性强,可以充分利用 XXL-JOB 的管理和重试机制。每个独立的任务(A或B)自身还可以配置为分片广播,实现阶段内的并行处理!
- 缺点:需要处理 API 调用的认证问题,增加了一点点编码工作。
方法三:分片任务的顺序编排(最复杂)
如果你的场景是:任务A必须完成,才能开始任务B,并且任务A和任务B自身都需要分片并行处理。
这时,你需要一个外部协调机制来判断“任务A的所有分片是否都已完成”。
实现思路:使用 Redis 作为分布式协调器
-
任务A (
shardingTaskA) 配置:- 路由策略:
分片广播。 - 任务开始前,在代码中设置一个 Redis 计数器,例如
SET task_a_total_shards 3(假设有3个分片)。
- 路由策略:
-
任务A 的 JobHandler 代码:
- 每个分片执行完成后,在 Redis 中原子性地递减一个“完成计数器”。
- 最后一个完成的分片负责触发任务B。
// 假设你已经注入了 RedisTemplate
@Autowired
private StringRedisTemplate redisTemplate;
@XxlJob("shardingTaskA")
public void execute() {
int shardingTotal = XxlJobHelper.getShardingTotal();
int shardingIndex = XxlJobHelper.getShardingItem();
// 在任务开始时(或者由第0个分片)设置总分片数
if (shardingIndex == 0) {
redisTemplate.opsForValue().set("job:shardingTaskA:total", String.valueOf(shardingTotal));
// 初始化完成计数器
redisTemplate.opsForValue().set("job:shardingTaskA:completed_count", "0");
}
// ... 执行分片A的业务逻辑 ...
XxlJobHelper.log("分片 {} 的任务A执行完毕。", shardingIndex);
// 原子性增加完成计数
long completedCount = redisTemplate.opsForValue().increment("job:shardingTaskA:completed_count");
// 获取总分片数
String totalStr = redisTemplate.opsForValue().get("job:shardingTaskA:total");
long total = totalStr != null ? Long.parseLong(totalStr) : -1;
// 如果当前是最后一个完成的分片,则触发任务B
if (completedCount == total) {
XxlJobHelper.log("所有分片均已完成,准备触发任务B...");
triggerNextJob("shardingTaskB"); // 触发下游的分片任务B
// 清理Redis Key
redisTemplate.delete("job:shardingTaskA:total");
redisTemplate.delete("job:shardingTaskA:completed_count");
}
}
- 优点:实现了阶段性并行任务的宏观顺序执行,性能最高。
- 缺点:实现非常复杂! 引入了外部依赖(Redis),需要处理分布式环境下的各种边界情况(如某个分片失败如何处理?如何保证原子性?),容易出错,不推荐新手使用。
总结与建议
| 场景 | 推荐方法 | 理由 |
|---|---|---|
| 任务必须严格按步骤串行 | 方法一 (放弃分片) | 简单直接,如果性能不是瓶颈,这是最可靠的选择。 |
| 多个阶段性任务,各阶段可并行 | 方法二 (任务编排) | 强烈推荐。这是最符合分布式设计思想的方案,解耦、清晰、可维护性好。 |
| 对性能要求极致的复杂工作流 | 方法三 (分布式协调) | 仅在方法二无法满足性能要求时考虑,需要有处理分布式复杂性的经验。 |
针对上述的顺序任务的场景,需要处理分布式环境下的各种边界情况(如某个分片失败如何处理?如何保证原子性?)
当然,这是一个非常专业且关键的问题。当我们试图在并行的分片任务之间建立顺序依赖时,就踏入了分布式系统协调的领域。处理好边界情况是确保系统稳定可靠的核心。
下面,我们深入探讨在方法三:使用 Redis 作为分布式协调器的场景下,如何处理这些关键的边界情况。
核心挑战
在分布式环境中,我们必须假设任何事情都可能出错:
- 网络分区:节点与 Redis 或其他节点暂时失联。
- 节点宕机:某个执行器实例突然崩溃。
- 任务执行失败:业务逻辑抛出异常。
- 重复执行:由于网络问题,调度中心可能重试并下发同一个分片任务。
- 协调器故障:Redis 本身也可能出现故障。
一个健壮的方案必须能够应对以上所有情况。
一、 如何处理分片失败?
这是最常见也是最重要的问题。在之前简单的 Redis 计数器模型中,一旦某个分片失败(即使 XXL-JOB 自动重试后最终还是失败),completed_count 将永远无法达到 total,整个工作流就会被永久阻塞。
解决方案:变“计数”为“记状态”
我们不应该只关心完成了多少个,而应该关心每个分片的状态。使用 Redis 的 Hash 数据结构是解决这个问题的理想选择。
-
定义状态:为每个分片定义清晰的状态,例如:
PENDING:已分派,尚未执行。RUNNING:正在执行。SUCCESS:执行成功。FAILED:执行失败。
-
引入唯一的执行批次ID:为了防止上一次运行的脏数据影响本次运行,每次任务调度(由第0个分片发起)都应该生成一个唯一的
runId(例如 UUID 或时间戳-jobId)。所有相关的 Redis Key 都应包含这个runId。 -
工作流改造:
-
任务A启动 (分片0):
a. 生成runId。
b. 在 Redis 中创建一个 Hash,Key 为job:taskA:run:{runId}:status。
c. 初始化所有分片的状态为PENDING:HSET job:taskA:run:{runId}:status 0 PENDING,HSET ... 1 PENDING... -
每个分片执行时:
a. 从 Redis 读取runId。
b. 开始执行业务前,更新自己的状态为RUNNING:HSET job:taskA:run:{runId}:status {shardingIndex} RUNNING。
c. 执行成功后,更新状态为SUCCESS。
d. 执行失败后(即使重试也失败),更新状态为FAILED。
-
-
引入独立的“监控-触发”任务:
不要让最后一个完成的分片负责触发下游任务,这种方式非常脆弱。应该创建一个独立的、轻量级的 XXL-JOB 任务(monitorTaskA),它每分钟执行一次,负责检查任务A的总体状态。monitorTaskA的逻辑:
a. 找到当前活跃的runId。
b.HGETALL获取所有分片的状态。
c. 检查失败:如果发现任何一个分片的状态为FAILED,立即发送警报(邮件、钉钉等),并停止后续检查,整个流程失败。
d. 检查完成:如果发现所有分片的状态都为SUCCESS,则:
i. 通过 API 触发下游任务 B。
ii. 触发成功后,清理本次运行的所有 Redis Key(或将其归档)。
iii. 停止自身的运行(可以通过 API 停止)。
e. 检查超时:如果发现有分片长时间处于RUNNING或PENDING状态(例如超过30分钟),同样发送超时警报。
这种模式将执行和协调彻底分离,极大地增强了系统的健壮性。
二、 如何保证原子性?
在分布式系统中,多个节点同时操作一个共享资源(如 Redis),原子性至关重要。
问题场景:
INCR+GET的组合操作不是原子的。在高并发下,一个客户端在INCR之后和GET之前,可能会有其他客户端的操作插入。- “检查所有分片状态并触发下游任务”这个复合操作也必须是原子的,以防止被重复触发。
解决方案:使用 Lua 脚本
Redis 保证 Lua 脚本中的所有命令作为一个整体被原子性地执行,期间不会被其他客户端的命令打断。
示例:使用 Lua 脚本安全地检查并触发
monitorTaskA 在检查到可能“全部成功”时,不应该直接在客户端 GET 然后 IF/THEN,而应该执行一个 Lua 脚本。
-- check_and_trigger.lua
-- KEYS[1]: 存储状态的 Hash Key, e.g., 'job:taskA:run:12345:status'
-- KEYS[2]: 触发锁的 Key, e.g., 'job:taskA:run:12345:trigger_lock'
-- ARGV[1]: 预期的总分片数
-- 检查是否已经被触发过
if redis.call('GET', KEYS[2]) then
return 0 -- 已经被触发,直接返回
end
local statuses = redis.call('HVALS', KEYS[1])
local success_count = 0
local total_count = 0
for i, status in ipairs(statuses) do
if status == 'SUCCESS' then
success_count = success_count + 1
end
-- 如果有任何一个失败了,则直接返回-1,代表流程失败
if status == 'FAILED' then
return -1
end
total_count = total_count + 1
end
-- 如果状态总数不等于预期的分片数,或者成功的数量不等于总数,说明还没完成
if total_count ~= tonumber(ARGV[1]) or success_count ~= total_count then
return 0 -- 尚未全部成功,返回
end
-- 所有分片都成功了,且尚未被触发
-- 设置触发锁,并设置一个较短的过期时间,防止锁永久存在
redis.call('SET', KEYS[2], 'triggered', 'EX', 60)
return 1 -- 返回1,表示“可以触发”
Java 代码中调用此脚本:
// DefaultRedisScript<Long> script = new DefaultRedisScript<>();
// script.setScriptSource(new ResourceScriptSource(new ClassPathResource("lua/check_and_trigger.lua")));
// script.setResultType(Long.class);
//
// List<String> keys = Arrays.asList("job:taskA:run:12345:status", "job:taskA:run:12345:trigger_lock");
// Long result = redisTemplate.execute(script, keys, String.valueOf(shardingTotal));
//
// if (result != null && result == 1) {
// // 脚本返回1,说明是我拿到了触发权
// triggerNextJob("taskB");
// } else if (result != null && result == -1) {
// // 脚本返回-1,说明检测到失败,发送警报
// sendAlert("Job taskA failed!");
// }
这个 Lua 脚本通过一个分布式锁 (trigger_lock) 确保了即使 monitorTaskA 有多个实例在运行,下游任务也只会被触发一次。
总结:健壮的顺序分片方案
一个生产可用的、健壮的顺序分片执行方案应具备以下要素:
- 唯一执行ID (
runId):隔离每次任务运行,防止数据污染。 - 状态机模型 (State Machine):使用 Redis Hash 记录每个分片的详细状态(
PENDING,SUCCESS,FAILED),而不仅仅是计数。 - 职责分离 (Separation of Concerns):将业务执行(在分片任务中)与流程协调(在独立的监控任务中)分开。
- 原子操作 (Atomicity):对于“检查并更新”等关键的协调步骤,使用 Lua 脚本来保证原子性,避免竞态条件。
- 幂等性 (Idempotency):下游任务 B 应该被设计成幂等的。即使因为某些极端情况被重复触发,也不会产生错误的结果。
- 超时与告警 (Timeout & Alerting):监控任务必须有超时机制,能在流程卡住或失败时及时通知运维人员。
- 垃圾清理 (Garbage Collection):成功或失败后,都需要有机制清理 Redis 中的历史数据,可以设置 TTL 作为兜底。
虽然这套方案比简单的任务编排复杂得多,但它解决了分布式环境下的核心痛点,为需要高性能、高可用的大规模顺序批处理任务提供了坚实的基础。
如果分片任务有部分完成了,其他部分有失败的,按照上述方案说监控任务会报告错误,那怎么样保证数据回滚呢
您提出了一个直击分布式系统核心的绝佳问题。当一个批处理任务被分片并行执行时,如何保证整个批次的原子性(All-or-Nothing)是最大的挑战之一。
按照我们之前的方案,监控任务发现部分失败后会报警,但此时系统的数据处于一种不一致的中间状态:一部分数据被修改了(成功的A分片),另一部分没有(失败的B分片和未执行的C分片)。数据回滚,或者说“补偿”,是解决这个问题的关键。
首先,必须明确一点:在分布式系统中,传统的、跨多个节点的 ACID 数据库事务(如两阶段提交,2PC)通常因为性能和锁竞争问题,不适用于长时间运行的批处理任务。因此,我们必须采用最终一致性的思路,通过补偿(Compensation)机制来实现逻辑上的“回滚”。
以下是几种主流的、可落地的解决方案,按复杂度和可靠性递增排序。
方案一:手动处理 + 幂等重跑(最简单,适用于非核心业务)
这是最直接的方案,依赖人工干预来恢复数据。
-
监控任务报警:
- 监控任务
monitorTaskA发现有分片失败,立即通过邮件、钉钉等方式发送详细警报。 - 警报内容必须包含:唯一的执行批次ID (
runId)、所有成功的分片号、所有失败的分片号以及失败的错误日志。
- 监控任务
-
人工介入:
- 分析失败原因:运维或开发人员根据日志分析失败原因。
- 如果是瞬时问题(如网络抖动、数据库死锁),可以尝试手动重跑失败的分片。XXL-JOB 后台支持手动触发任务并指定分片参数。
- 如果是数据或代码问题,需要先修复问题。
- 决定如何恢复:
- 向前修复 (Fix-Forward):如果问题修复后,可以重新运行失败的分片来完成整个批次,这是最理想的。这要求你的业务逻辑是幂等的(即同一个操作执行多次和执行一次的结果相同)。
- 向后回滚 (Rollback):如果无法向前修复,或者业务要求必须撤销已完成的操作,就需要手动执行一个反向SQL脚本或回滚程序,根据
runId和成功的分片号,将已修改的数据恢复到原始状态。
- 分析失败原因:运维或开发人员根据日志分析失败原因。
优点:
- 实现成本最低,无需开发复杂的回滚逻辑。
- 对于很多非核心的、允许延迟的离线任务来说,这已经足够。
缺点:
- 恢复时间长 (RTO高),完全依赖人工。
- 容易出错,手动操作存在风险。
方案二:SAGA 模式(自动化补偿,强烈推荐)
SAGA 模式是处理分布式长事务的经典模型。其核心思想是:将一个大的全局事务拆分成一系列本地子事务(Saga Step),每个子事务都有一个对应的补偿操作(Compensating Action)。如果任何一个子事务失败,系统会依次调用前面所有已成功子事务的补偿操作,从而实现逻辑上的回滚。
在我们的分片场景中,每个分片的执行都可以看作一个 Saga Step。
如何实现
-
记录“Undo Log”:
这是实现 SAGA 的关键前提。在每个分片执行其核心业务逻辑之前,必须先将“如何撤销这个操作”的信息持久化下来。- 创建一个
undo_log表,字段可能包括:
id,run_id,sharding_index,target_id(如用户ID),operation_type(如'ADD_POINTS'),before_data(JSON格式,记录操作前的数据),status('INITIAL', 'COMPLETED', 'COMPENSATED'),create_time。
- 创建一个
-
改造分片任务
shardingTaskA:- 在
execute方法中,对于要处理的每条数据:
a. 开启本地事务。
b. 查询当前数据,获取before_data。
c. 插入一条 Undo Log,状态为INITIAL。
d. 执行核心业务逻辑(例如,更新用户积分)。
e. 更新 Undo Log 状态为COMPLETED。
f. 提交本地事务。 - 这样保证了业务操作和 Undo Log 的记录是原子性的。
- 在
-
改造监控任务
monitorTaskA:- 当它检测到任何一个分片
FAILED时,它的职责不再仅仅是报警,而是触发一个新的补偿任务:compensateTaskA。 - 触发时,需要将失败的
runId作为参数传递给补偿任务。
- 当它检测到任何一个分片
-
创建补偿任务
compensateTaskA:- 这个任务也应该是一个分片任务,以实现高效并行回滚。
- 路由策略:
分片广播。 - JobHandler 逻辑:
a. 接收runId参数。
b. 每个分片根据自己的shardingIndex,去undo_log表里查询run_id匹配且status为COMPLETED的日志。
c. 遍历查询到的日志,执行补偿操作(例如,根据before_data将用户积分恢复到之前的值)。
d. 更新undo_log的status为COMPENSATED。
优点:
- 自动化回滚,无需人工干预。
- 可靠性高,所有操作都有据可查。
- 高并发,补偿任务本身也可以并行执行。
缺点:
- 实现复杂度中等,需要额外设计和维护
undo_log表和补偿逻辑。 - 最终一致性:在补偿完成前,数据会处于不一致状态。
方案三:TCC 模式(Try-Confirm-Cancel)
TCC 模式比 SAGA 更严格,它将每个操作分为三个阶段,提供准实时的回滚能力。
- Try 阶段:预留资源,执行业务检查。此阶段不真正修改业务数据,只是锁定资源并记录待办事项。例如,不直接修改用户积分,而是在
points_change_log表里插入一条status='PENDING'的记录。 - Confirm 阶段:如果所有分片的
Try阶段都成功,则执行Confirm。这个阶段才真正地执行业务逻辑(例如,根据 log 表更新用户积分,并将 log 状态改为CONFIRMED)。 - Cancel 阶段:如果任何一个分片的
Try阶段失败,则对所有已成功的Try执行Cancel操作,释放预留的资源(例如,将 log 状态改为CANCELED或直接删除)。
如何实现
shardingTaskA扮演Try角色:每个分片只做预留和检查,不提交最终数据。monitorTaskA扮演协调者:- 检查所有分片的
Try结果。 - 如果全部成功,触发
confirmTaskA。 - 如果有任何失败,触发
cancelTaskA。
- 检查所有分片的
- 创建
confirmTaskA和cancelTaskA:这两个都是分片任务,分别执行Confirm和Cancel逻辑。
优点:
- 一致性更高,在
Confirm之前,核心业务数据从未被“弄脏”。 - 回滚速度快,因为
Cancel只是释放预留资源。
缺点:
- 实现复杂度最高,对业务代码的侵入性极强,需要将一个简单的业务逻辑拆分成三个独立的方法。
- 性能开销大,整个流程需要多次 RPC 和数据库交互。
总结与建议
| 方案 | 复杂度 | 一致性 | 适用场景 |
|---|---|---|---|
| 手动处理 | 低 | 最终 (依赖人工) | 非核心、允许延迟、失败率低的离线任务。 |
| SAGA 模式 | 中 | 最终 (自动化补偿) | 绝大多数需要自动化回滚的分布式批处理任务。这是性能和复杂度的最佳平衡点。 |
| TCC 模式 | 高 | 准实时 | 对数据一致性要求极高、业务逻辑可以清晰拆分为三阶段的场景,更常见于在线微服务而非离线批处理。 |
对于您提出的场景,我强烈推荐采用 SAGA 模式。它提供了自动化的、可靠的数据补偿机制,虽然增加了一些开发工作量,但能极大地提升系统的健壮性和无人值守能力,是应对分布式环境下部分失败问题的标准工程实践。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号