

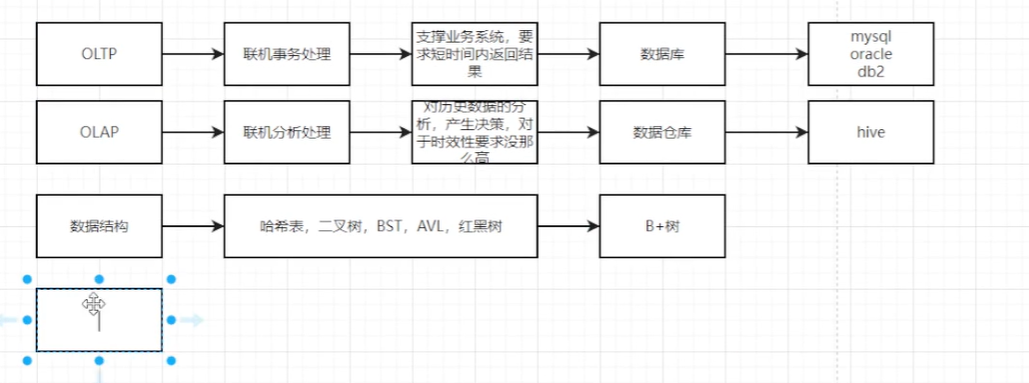
mysql细节知识
b-树和b+树的区别
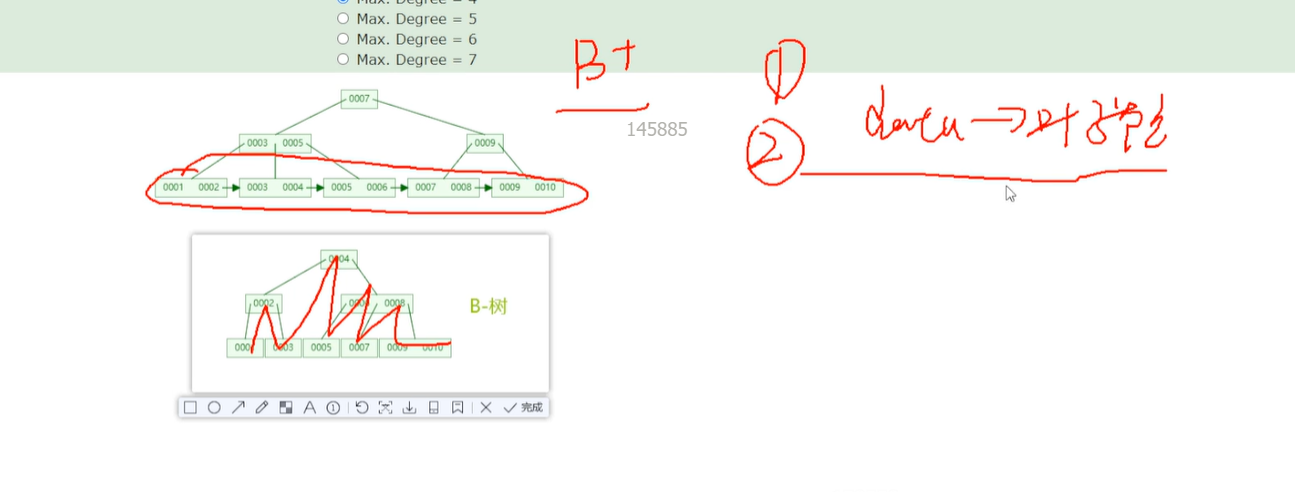
可以看出B+树可以放更多的数据,因为非叶子结点都是放的key+指针,不包括数据。假如一个页的大小是16kb,数据的大小是1kb,那么一个页能放的数据大概是16个。
先算第一层,假如指针+key大约为10字节,那么,一个页能放的个数为16*1024/10 ~= 1638
第一层就能放1638个,那么第二层呢,能放多少个呢,因每个页结点都能放1638,那么第二层能装的数据大小1638*1638,延展到第三层,
每页能放16个数据,那么最终能放的数据为:16*1638*1638~=42,928,704 4千多万个吧,那么显然,增加pageSize的大小,就能裝更多的数据。
mysql 设置页大小的参数:innodb_page_size=32K
1、数据迁移的时候需要删除索引,不然迁移的效率很低,因为没迁移一条数据会维护它对应的索引。
2、索引与B+树。
好的,用户现在在问关于MySQL InnoDB中一张表有一个聚簇索引和两个二级索引对应的B+树结构是怎样的。我需要详细解释清楚每个索引对应的B+树结构,以及它们之间的关系。
首先,用户之前已经问过关于页大小和索引的问题,可能对B+树有一定了解,但需要更深入的结构说明。用户可能正在设计数据库结构,或者优化查询性能,需要理解索引的物理结构来做出更好的决策。
我需要先确认聚簇索引和二级索引的区别。聚簇索引的叶子节点存储的是数据行,而二级索引的叶子节点存储的是主键值。每个索引都是独立的B+树,因此三个索引对应三个B+树。
接下来,需要详细描述每个B+树的结构。聚簇索引的结构,主键是如何组织的,叶子节点和数据行的关系。然后是两个二级索引的结构,它们的键值组成,以及叶子节点如何指向主键。可能需要用例子来说明,比如一个具体的表结构,比如用户表,有id作为主键,name和age作为二级索引。
还要注意页的结构,每个节点对应一个页,非叶子节点存储键值和指针,叶子节点存储数据或主键值。可能需要提到页分裂和合并的过程,但用户的问题主要是结构,不是操作细节。
需要确保用户理解为什么二级索引需要回表查询,以及为什么索引的数量会影响写操作的性能,因为每次插入都要更新多个B+树。
可能还需要图示,但文本描述需要足够清晰。例如,聚簇索引的B+树叶子层是数据页,二级索引的叶子层是主键值,这样在查询时通过二级索引找到主键,再通过聚簇索引找到数据行。
最后,总结三个B+树的关系,强调每个索引独立维护,以及它们如何协作。可能还要给出优化建议,比如避免过多索引,使用覆盖索引等。
和数据一起存的索引叫聚簇索引,就是存在叶子结点那个。B-树也叫多叉树。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号