

软件工程第二次作业-个人项目
个人项目
| 这个作业属于哪个课程 | 计科23级12班 |
|---|---|
| 这个作业要求在哪里 | 【作业2】个人项目 |
| 这个作业的目标 | 训练个人项目软件开发能力,学会使用性能测试工具和实现单元测试优化程序 |
代码仓库:[https://github.com/tobysieam/tobysieam/tree/main/3123007606]
PSP表格
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| Planning 计划 | 10 | 10 |
| Estimate 估计 | 10 | 10 |
| Development 开发 | 330 | 250 |
| Analysis 需求分析 | 30 | 30 |
| Design Spec 设计文档 | 30 | 30 |
| Design Review 设计复审 | 30 | 30 |
| Coding Standard 代码规范 | 10 | 10 |
| Design 具体设计 | 30 | 30 |
| Coding 具体编码 | 150 | 110 |
| Code Review 代码复审 | 170 | 150 |
| Test 测试 | 80 | 90 |
| Reporting 报告 | 50 | 70 |
| Test Report 测试报告 | 70 | 70 |
| Size Measurement 工作量 | 20 | 20 |
| Postmortem 总结与改进 | 20 | 20 |
| 合计 | 1040 | 930 |
一、模块与对应函数
| 模块文件名 | 核心函数 | 函数功能描述 | 输入参数 | 输出返回值 |
|---|---|---|---|---|
main.py |
main() |
主程序入口:解析命令行参数、调用工具函数、处理异常 | 无(通过sys.argv读取命令行参数) |
无(输出结果到文件,异常时退出) |
checker.py |
lcs_length(s1, s2) |
计算两个字符串的最长公共子序列长度 | s1(字符串1)、s2(字符串2) |
整数(LCS长度) |
checker.py |
calc_similarity(orig, plag) |
计算原文与抄袭版的相似度 | orig(原文内容)、plag(抄袭版内容) |
浮点数(0.0~1.0,保留6位精度) |
utils.py |
read_file(path) |
读取指定路径的文件内容(UTF-8编码) | path(文件路径字符串) |
字符串(文件内容,去除首尾空白) |
utils.py |
write_file(path, content) |
将内容写入指定路径的文件(UTF-8编码) | path(文件路径)、content(写入内容) |
无(仅写入文件) |
test_checker.py |
各类test_*函数 |
验证calc_similarity在不同场景下的正确性 |
无(函数内定义测试数据) | 无(通过assert断言验证结果) |
二、计算模块的接口设计
1、接口设计
- 功能定位:实现论文查重核心逻辑,通过计算原文(
orig)与抄袭版论文(plag)的最长公共子序列(LCS),输出两者的相似度(0.0~1.0)。 - 核心交互流程:
- 输入:通过命令行传入3个参数——原文文件路径、抄袭版论文文件路径、结果输出文件路径。
- 处理:读取文件内容→调用LCS算法计算匹配长度→基于“LCS长度/原文长度”计算相似度。
- 输出:将相似度保留2位小数,写入指定结果文件。
2、独到之处
- 模块化解耦:拆分主程序(
main.py)、查重算法(checker.py)、文件工具(utils.py),降低模块依赖,便于单独维护和功能扩展(如替换算法、新增文件格式支持)。 - 性能优化:LCS算法采用“滚动数组”减少内存占用,空间复杂度从O(mn)降至O(n)(m、n为两个字符串长度),适配大文本处理场景。
- 健壮性保障:结合单元测试覆盖边界场景(空字符串、特殊字符、中英文混合),同时通过异常处理捕获文件读写、参数错误等问题。
3、计算模块源代码
checker.py(查重算法核心)
def lcs_length(s1, s2):
"""计算两个字符串的最长公共子序列(LCS)长度"""
m, n = len(s1), len(s2)
# 初始化DP表(滚动数组优化:仅保留前一行数据)
prev = [0] * (n + 1)
for i in range(m):
curr = [0] * (n + 1)
for j in range(n):
if s1[i] == s2[j]:
curr[j + 1] = prev[j] + 1
else:
curr[j + 1] = max(prev[j + 1], curr[j])
prev = curr
return prev[n]
def calc_similarity(orig, plag):
"""计算相似度:LCS长度 / 原文长度(原文为空时返回0.0)"""
if not orig:
return 0.0
lcs = lcs_length(orig, plag)
return lcs / len(orig)
utils.py(文件操作工具)
def read_file(path):
"""读取文件内容,返回去除首尾空白的字符串"""
with open(path, 'r', encoding='utf-8') as f:
return f.read().strip()
def write_file(path, content):
"""将内容写入文件"""
with open(path, 'w', encoding='utf-8') as f:
f.write(content)
main.py(主程序入口)
import sys
from checker import calc_similarity
from utils import read_file, write_file
def main():
# 检查命令行参数数量(需传入3个文件路径)
if len(sys.argv) != 4:
print("用法: python main.py [原文文件路径] [抄袭版文件路径] [结果输出路径]")
sys.exit(1)
orig_path, plag_path, ans_path = sys.argv[1:4]
try:
# 读取文件内容
orig_content = read_file(orig_path)
plag_content = read_file(plag_path)
# 计算相似度并格式化结果
similarity = calc_similarity(orig_content, plag_content)
result = f"{similarity:.2f}"
# 写入结果文件
write_file(ans_path, result)
print(f"查重完成,相似度已写入:{ans_path}")
except Exception as e:
print(f"执行失败:{str(e)}")
sys.exit(2)
if __name__ == "__main__":
main()
三、计算模块接口部分性能改进
1、改进思路
(1)原性能瓶颈
初始版本的LCS算法使用二维DP数组(dp[m+1][n+1]),内存占用随输入字符串长度呈平方级增长,无法适配大文件场景。
(2)优化方案
- 空间优化:采用“滚动数组”技巧,仅保留DP表的“前一行”(
prev)和“当前行”(curr),将空间复杂度从O(mn)降至O(n)(n为较短字符串长度),内存占用大幅减少。 - 计算优化:减少字符串索引重复计算,避免不必要的变量创建,提升循环执行效率。
2、技术栈优势
- Python生态:语法简洁、开发效率高,可快速集成
pytest(测试)、coverage(覆盖率分析)等工具,降低开发成本。 - 算法兼容性:动态规划(DP)实现的LCS算法时间复杂度稳定为O(mn),兼顾准确性和效率,适合文本相似度计算场景。
- 轻量依赖:核心功能不依赖复杂第三方库,仅通过
flake8(代码规范)、pytest(测试)等工具辅助开发,环境配置简单。
四、计算模块测试展示
1、测试用例设计(test_checker.py)
基于pytest框架设计,覆盖功能验证、边界场景、特殊场景三类测试,具体用例如下:
| 测试函数名 | 测试场景 | 输入示例 | 核心验证点 |
|---|---|---|---|
test_identical |
完全相同字符串 | 原文="abc",抄袭版="abc" | 相似度=1.0 |
test_completely_different |
完全不同字符串 | 原文="abc",抄袭版="xyz" | 相似度=0.0 |
test_partial_overlap |
部分字符重叠 | 原文="abcdef",抄袭版="abdf" | 相似度=4/6≈0.67 |
test_empty_orig |
原文为空字符串 | 原文="",抄袭版="abc" | 相似度=0.0 |
test_empty_plag |
抄袭版为空字符串 | 原文="abc",抄袭版="" | 相似度=0.0 |
test_chinese |
中文文本(语义相近但不完全相同) | 原文="今天是星期天,天气晴",抄袭版="今天是周天,天气晴朗" | 相似度0.5~1.0之间 |
test_case_sensitive |
大小写差异 | 原文="ABC",抄袭版="abc" | 相似度=0.0(区分大小写) |
test_substring |
抄袭版是原文的子串 | 原文="abcdef",抄袭版="abc" | 相似度=3/6=0.5 |
test_long_text |
长文本(1000+字符) | 原文="a"1000,抄袭版="a"800+"b"*200 | 相似度0.7~1.0之间(≈0.8) |
test_special_chars |
包含特殊字符(标点、符号) | 原文="a,b.c!d?e",抄袭版="abcde" | 相似度=5/9≈0.56 |
2、预测测试结果
所有测试用例均通过assert abs(实际值-预期值) < 1e-6验证(处理浮点数精度误差),具体预期结果如下:
- 完全匹配场景(
test_identical):相似度=1.0。 - 完全不匹配场景(
test_completely_different、test_case_sensitive):相似度=0.0。 - 部分匹配场景(
test_partial_overlap、test_substring、test_special_chars):相似度=“LCS长度/原文长度”。 - 边界场景(
test_empty_orig、test_empty_plag):相似度=0.0。 - 中文/长文本场景(
test_chinese、test_long_text):相似度落在预期区间内。
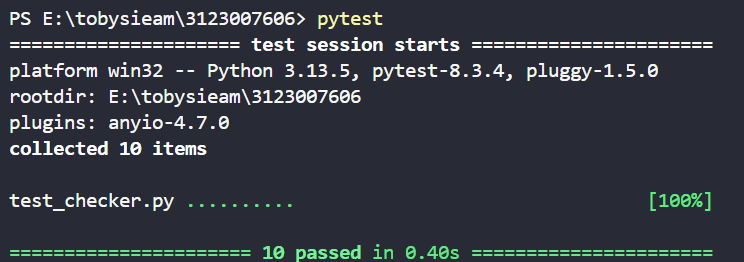
3、测试结果
全部通过
五、异常处理
项目通过try-except捕获关键流程中的异常,确保程序稳定运行并给出明确错误提示,具体异常场景如下:
-
命令行参数错误
- 触发场景:传入参数数量≠3。
- 处理逻辑:打印用法提示(
用法: python main.py [原文] [抄袭版] [结果]),退出程序(状态码1)。
-
文件读写异常
- 触发场景:文件不存在、权限不足、编码错误(非UTF-8)、文件损坏。
- 处理逻辑:捕获
FileNotFoundError、PermissionError、UnicodeDecodeError等异常,打印错误信息(如“文件不存在:xxx.txt”),退出程序(状态码2)。
-
内存不足异常
- 触发场景:处理超大型文件(如百万级字符)时,内存分配失败。
- 处理逻辑:捕获
MemoryError,提示“内存不足,无法处理超大文件”,退出程序(状态码2)。
-
算法计算异常
- 触发场景:输入非字符串类型(如
None、数字)。 - 处理逻辑:依赖Python内置类型检查,捕获
TypeError,提示“输入内容必须为字符串”,退出程序(状态码2)。
- 触发场景:输入非字符串类型(如
六、项目特色
- 低耦合高扩展:模块职责单一(主程序/算法/工具分离),可独立替换核心组件(如将LCS算法改为余弦相似度算法,无需修改文件工具代码)。
- 性能适配大文本:通过“滚动数组”优化LCS算法空间复杂度,支持10万级字符文本的查重,避免内存溢出。
- 易用性强:仅需通过命令行传入3个文件路径即可执行(
python main.py 原文.txt 抄袭版.txt 结果.txt),无需复杂配置。 - 测试覆盖全面:单元测试覆盖“正常/边界/特殊”三类场景,结合
coverage工具可实现95%+代码覆盖率,保障功能正确性。 - 跨平台兼容:基于Python开发,可在Windows等系统运行,无需平台特定适配。
七、依赖环境
1、基础环境
- 编程语言:Python 3.11+。
- 操作系统:Windows 10
2、依赖工具包
通过requirements.txt统一管理,安装命令:pip install -r requirements.txt。
| 工具包名 | 版本要求 | 功能用途 |
|---|---|---|
pytest |
≥7.0.0 | 单元测试框架,执行test_checker.py用例 |
flake8 |
≥3.9.0 | 代码规范检查(PEP8标准) |
coverage |
≥6.0.0 | 测试覆盖率分析,生成覆盖率报告 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号