


实用指南:FlashVSR:迈向实时基于扩散的流媒体视频超分辨率
2025-11-19 16:33 tlnshuju 阅读(4) 评论(0) 收藏 举报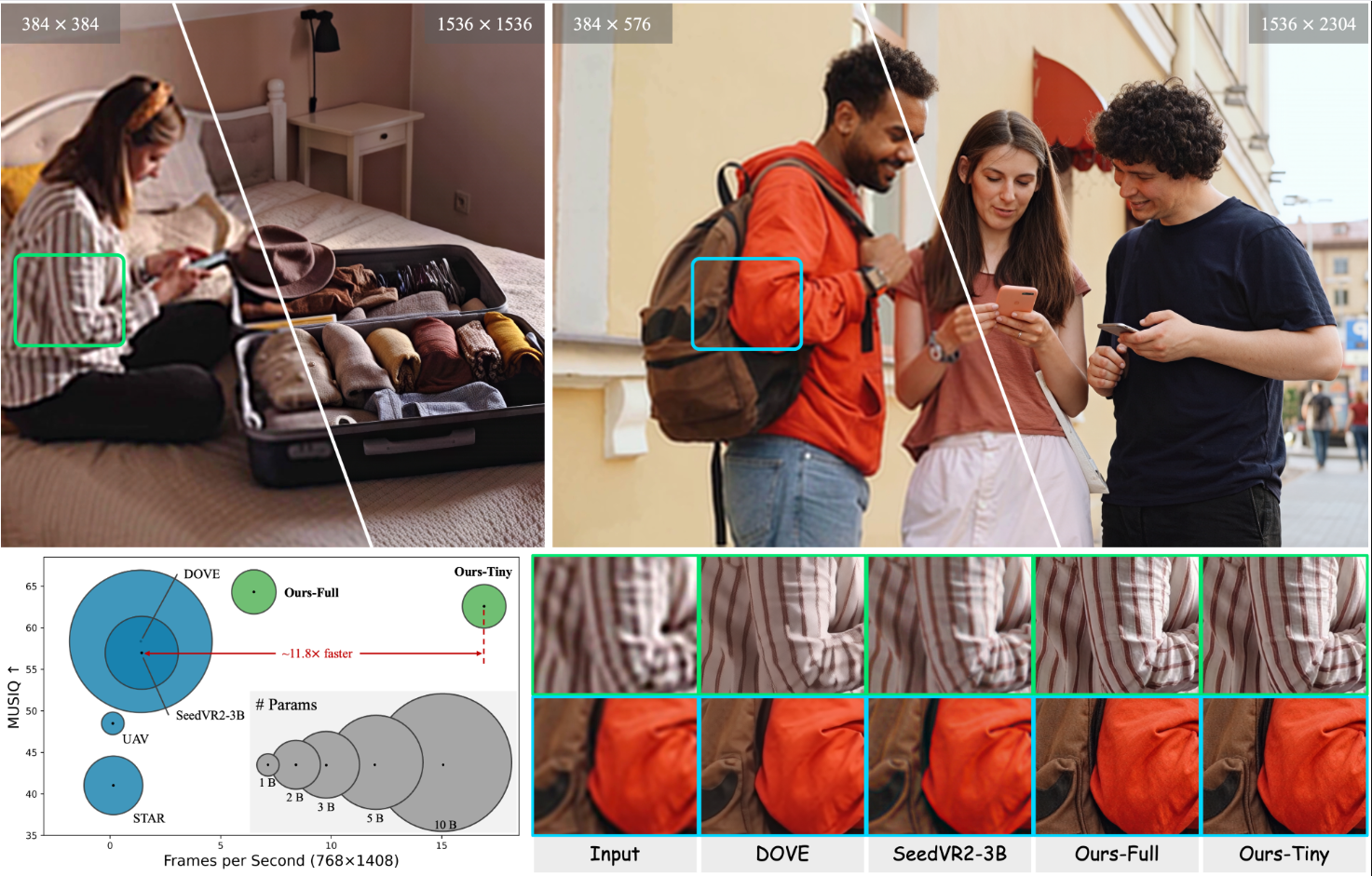
摘要
扩散模型近期推动了视频修复领域的进展,但将其应用于真实世界的视频超分辨率(VSR)仍面临高延迟、计算成本过高以及对超高分辨率泛化能力不足等挑战。本工作的目标是通过实现高效性、可扩展性和实时性能,使基于扩散模型的视频超分辨率技术走向实用化。为此,我们提出FlashVSR——首个基于扩散模型的一步式流式处理框架,可达到实时超分辨率效果。FlashVSR在单块A100 GPU上对768×1408分辨率视频的处理速度达到约17 FPS,其创新点包括:(1)支持流式超分辨率的三阶段可训练蒸馏管道;(2)局部约束稀疏注意力机制,在弥合训练-测试分辨率差距的同时减少冗余计算;(3)微型条件解码器,在不损失质量的前提下加速重建。为支持大规模训练,我们还构建了包含12万条视频和18万张图像的VSR-120K数据集。大量实验表明,FlashVSR能可靠地扩展到超高分辨率,相比现有一步式扩散超分辨率模型实现了最高约12倍的加速,同时保持最先进的性能。
新闻动态
- 发布日期: 2025年10月 —— 推理代码与模型权重现已发布!
- 即将推出: 大规模训练数据集(VSR-120K)释出计划。
待办事项
- ✅ 发布推理代码与模型权重
- ⬜ 发布数据集(VSR-120K)
快速开始
按照以下步骤在本地设备上配置并运行 FlashVSR:
1️⃣ 克隆仓库
git clone https://github.com/OpenImagingLab/FlashVSR
cd FlashVSR2️⃣ 设置Python环境
创建并激活环境(Python 3.11.13):
conda create -n flashvsr python=3.11.13
conda activate flashvsr安装项目依赖:
pip install -e .
pip install -r requirements.txt3️⃣ 安装Block-Sparse-Attention(必需)
FlashVSR 依赖Block-Sparse-Attention后端实现灵活动态的注意力掩码,以支持高效推理。
git clone https://github.com/mit-han-lab/Block-Sparse-Attention
cd Block-Sparse-Attention
pip install packaging
pip install ninja
python setup.py install⚠️ 注意: 当前块稀疏注意力(Block-Sparse Attention)后端仅在英伟达A100或A800显卡(Ampere架构)上能实现理想的加速效果。在H100/H800(Hopper架构)显卡上,由于硬件调度和稀疏计算内核行为的差异,可能无法达到预期的加速效果,某些情况下性能甚至可能慢于稠密注意力计算。
4️⃣ 从Hugging Face下载模型权重
模型权重通过Git LFS托管在Hugging Face平台,请先安装Git LFS:
# From the repo root
cd examples/WanVSR
# Install Git LFS (once per machine)
git lfs install
# Clone the model repository into examples/WanVSR
git lfs clone https://huggingface.co/JunhaoZhuang/FlashVSR克隆后,您应该拥有:
./examples/WanVSR/FlashVSR/
│
├── LQ_proj_in.ckpt
├── TCDecoder.ckpt
├── Wan2.1_VAE.pth
├── diffusion_pytorch_model_streaming_dmd.safetensors
└── README.md默认情况下,推理脚本会从 ./examples/WanVSR/FlashVSR/ 加载权重。
5️⃣ 运行推理
# From the repo root
cd examples/WanVSR
python infer_flashvsr_full.py # Full model
# or
python infer_flashvsr_tiny.py # Tiny model️ 方法
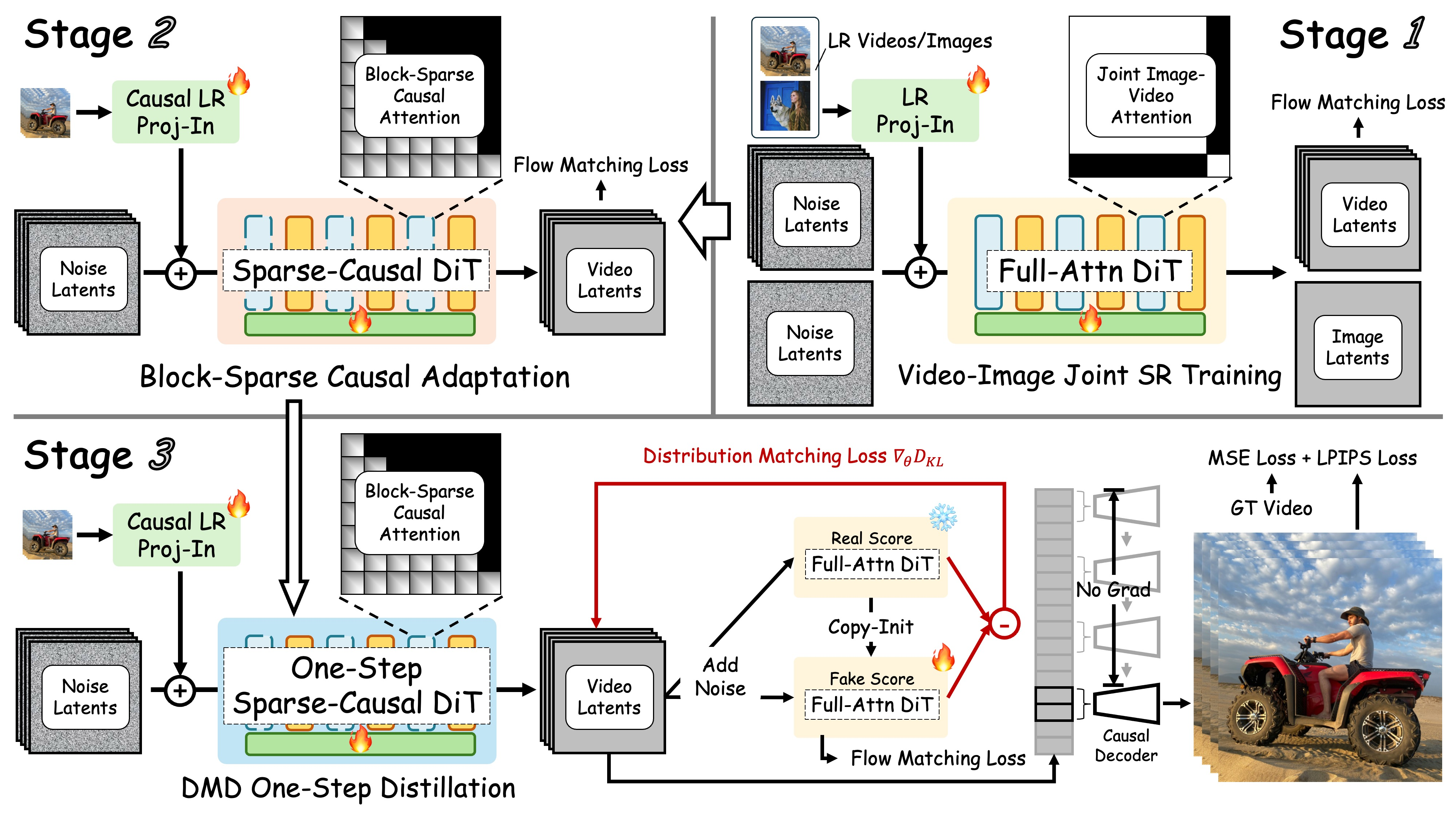
FlashVSR 概述。该框架包含以下特点:
- 三阶段蒸馏流程,用于流式视频超分辨率训练。
- 局部约束稀疏注意力,减少冗余计算并弥合训练-测试分辨率差异。
- 微型条件解码器,实现高效高质量重建。
- VSR-120K 数据集,包含 12 万条视频 和 18 万张图像,支持图像与视频联合训练。
反馈与支持
我们欢迎反馈与问题报告。感谢试用 FlashVSR!
致谢
我们诚挚感谢以下开源项目:
- DiffSynth Studio — https://github.com/modelscope/DiffSynth-Studio
- Block-Sparse-Attention — https://github.com/mit-han-lab/Block-Sparse-Attention
- taehv — https://github.com/madebyollin/taehv
联系方式
- Junhao Zhuang
Email: zhuangjh23@mails.tsinghua.edu.cn
引用
@misc{zhuang2025flashvsrrealtimediffusionbasedstreaming,
title={FlashVSR: Towards Real-Time Diffusion-Based Streaming Video Super-Resolution},
author={Junhao Zhuang and Shi Guo and Xin Cai and Xiaohui Li and Yihao Liu and Chun Yuan and Tianfan Xue},
year={2025},
eprint={2510.12747},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2510.12747},
}
 浙公网安备 33010602011771号
浙公网安备 33010602011771号