

初识LangChain - 教程
2025-10-24 15:16 tlnshuju 阅读(87) 评论(0) 收藏 举报首先我们来看看Langchain是个什么?
官网是这么说的
LangChain 是一个用于开发由大型语言模型 (LLM) 提供支持的应用程序的框架。
- 开发:使用 LangChain 的开源构建块和组件构建您的应用程序。使用第三方集成和模板开始运行。
- 生产化:使用 LangSmith 检查、监控和评估您的链条,让您充满信心地持续优化和部署。
- 部署:使用 LangServe 将任何链转换为 API。
Introduction | ️ LangChain 
按照豆包的说法是:
LangChain 就是帮开发者给大语言模型(比如 GPT)“搭手脚、补脑子” 的工具包。
它解决了直接用 AI 模型的痛点:比如模型记不住之前聊的内容(它给加 “记忆”),不知道最新信息或公司内部文档(它能连数据库、读文件,把有用信息挑出来喂给模型),不会自己查天气、算数据(它能让模型自己调用计算器、搜索引擎这些工具)。
简单说,不用它,你只能让 AI 写诗聊天;用了它,几天就能搭出一个能查公司资料、自动算报表、连贯陪聊的实用 AI 应用,省了大把从零写代码的功夫。
我们的Langchain有以下开源库组成:
- langchain-core:基本的LangChain表达式语言,
- langchain-community:第三方集成
- langchain:构成应用程序认知的架构的链,代理,节点,使用 LLM 构建健壮且有状态的多参与者应用程序
- langgraph:通过步骤建模为图中的边和节点
- langserve:将LangChain链部署为REST API
- langsmith:一个开发人员平台,可让您调试、测试、评估和监控 LLM 应用程序,并与 LangChain 无缝集成。
安装LangChain
pip install langchain -i https://pypi.tuna.tsinghua.edu.cn/simple什么是LLM链?
LLM链本质上是连串的自定义模块由“|”来表示输入输出的模块链,我会将它想象为一串项链,而项链中间连接的绳子就是“|”。
接下来让我们来举个例子看看LLM链在实际的工作当中是怎么用的吧
获取api
1.首先我们需要一个可以调用的大模型api,这里我们可以用通义来实现
大模型服务平台百炼控制台
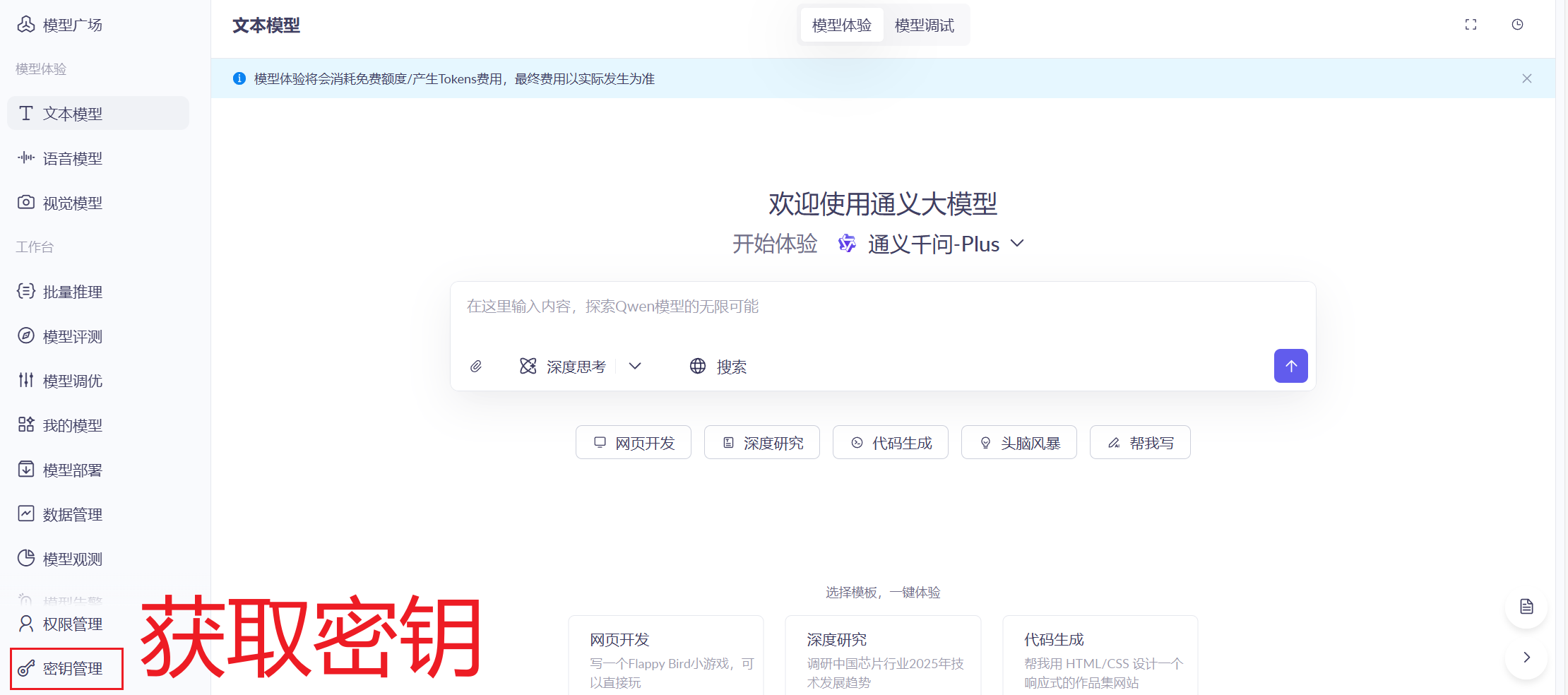

简单实现
我们用最简单的方法去调用我们的api先测试一下我们的api是否能够返回
from langchain_community.chat_models import ChatTongyi
llm = ChatTongyi(model="qwen-plus",
api_key="你的api"
)
"""
qwen-turbo:推理速度较快,适合对响应时间要求较高的场景
qwen-plus:平衡了推理速度和模型能力,是通用型选择
qwen-max:具有更强的推理能力,适合复杂任务
"""
print(f"{llm.invoke('你好')}")这里我们可以看到模型返回的结果(是一个可爱的大模型)

这里我想测试一下他的上下文记忆是否自带

看来还是要调用记忆功能才能实现上下文记忆
![]()
提示词模版
然后我们使用一个提示词模版,它的作用是帮你把提示词写得更加规范, 提示模板将原始用户输入转换为更好的 LLM 输入。

再通过一个![]() ,把我们的两个功能模块串联
,把我们的两个功能模块串联
那我们的完整代码就变成了这样
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.chat_models import ChatTongyi
llm = ChatTongyi(model="qwen-max",
api_key="你的api"
)
# print(f"{llm.invoke('你好')}")
# print(f"{llm.invoke('看到这句话请回复111')}")
# print(f"{llm.invoke('我上两句话说了啥')}")
prompt = ChatPromptTemplate.from_messages([
("system", "You are a world class technical documentation writer."),
("user", "{input}")
])
chain = prompt | llm
chain_invoke = chain.invoke({"input": "看到请回复111"})
print(f"{chain_invoke.content}")
StrOutput解析器
可以看到我们的chain_invoke.content的输出是要自己来选择输出的,我们接下来据介绍一个工具strOuput解析器,不用自己手动选择输出,放在LLM链上便可以自动选择自然语言输出。
from langchain_core.output_parsers import StrOutputParser
output_parser = StrOutputParser()当然在添加StrOutPutParser后,记得把“.content”删掉,否则会出现报错。
这样我们就简单实现了LLM链了
create_stuff_documents_chain是什么,结合webBaseLoader和数据库可以做快速RAG?
我们这次不一步一步来,直接先入为主让大家看看代码
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.chat_models import ChatTongyi
from langchain_core.output_parsers import StrOutputParser
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_huggingface import HuggingFaceEmbeddings # 新版
# 初始化通义千问大模型,使用指定的API密钥和模型名称
llm = ChatTongyi(model="qwen-max",
api_key="你的API"
)
# 定义一个聊天提示模板,用于指导模型生成技术文档风格的回答
prompt = ChatPromptTemplate.from_messages([
("system", "You are a world class technical documentation writer."),
("user", "{input}")
])
# 创建字符串输出解析器,用于将模型输出解析为字符串格式
output_parser = StrOutputParser()
# 创建网页加载器,用于从指定URL加载网页内容
loader = WebBaseLoader("https://www.cnfin.com/yb-lb/detail/20250926/4310044_1.html")
# 提取文档内容
docs = loader.load()
# 打印文档元数据和内容预览
for doc in docs:
print("URL:", doc.metadata["source"])
print("Title:", doc.metadata.get("title"))
print("Content preview:", doc.page_content[:1000])
print("-" * 50)
# 初始化HuggingFace嵌入模型,用于将文本转换为向量表示
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
# 创建递归字符文本分割器,用于将长文档分割成较小的块
text_splitter = RecursiveCharacterTextSplitter()
# 使用文本分割器分割文档
documents = text_splitter.split_documents(docs)
# 使用FAISS创建向量存储,用于高效检索相似文档
vector = FAISS.from_documents(documents, embeddings)
from langchain.chains.combine_documents import create_stuff_documents_chain
# 定义一个新的提示模板,用于基于上下文回答问题
prompt = ChatPromptTemplate.from_template("""Answer the following question based only on the provided context:
{context}
Question: {input}""")
# 创建文档链,用于结合文档内容生成回答
document_chain = create_stuff_documents_chain(llm, prompt)
# 组合文档链和输出解析器,形成完整的处理链
chain = document_chain | output_parser
# 创建检索器,用于从向量存储中检索相关文档
retriever = vector.as_retriever()
# 定义查询问题
query_1 = "排放权交易基础性制度是什么?"
# 检索与查询相关的文档
relevant_docs = retriever.invoke(query_1)
# 调用处理链,生成基于上下文的回答
chain_invoke = chain.invoke({
"input": query_1,
"context": relevant_docs # 添加 context 参数
})
print(f"{chain_invoke}")当然有很多的代码都是我们之前写好的代码
我们整体的思路是这样:
1.首先我们用WebBaseLoader对网页进行爬虫
2.提取文档内容存储到数据库中,由于我们只是演示所以我们还是用langchain使用文档推介的FAISS
3.检索与用户查询相关的文档
4.检索结果交给大模型最作为上下文输出
FAISS数据库下载
pip install faiss-cpu -i https://mirrors.aliyun.com/pypi/simple因为from langchain_community.vectorstores import FAISS依赖这个库
我们的FAISS库是一个当我们把通过模型或者 AI 应用处理好的数据喂给它之后(“一堆特征向量”),它会根据一些固定的套路,例如像传统数据库进行查询优化加速那样,为这些数据建立索引。避免我们进行数据查询的时候,需要笨拙的在海量数据中进行一一比对,这就是它能够实现“高性能向量检索”的秘密。
数据切分
关于数据切分,我们使用的是RecursiveCharacterTextSplitter()
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 创建递归字符文本分割器,用于将长文档分割成较小的块
text_splitter = RecursiveCharacterTextSplitter.split_documents()当我们需要切分文本的时候就用到他,当然也有其他的文本切分方法,比如大家都知道的“结巴”jieba分词
文本向量化
文本向量化我们选择HuggingFace的嵌入模型,文本向量化是指将文本转换成向量。因为HuggingFace向量化在Langchain中已经存在不用另外下载
from langchain_huggingface import HuggingFaceEmbeddings
# 初始化HuggingFace嵌入模型,用于将文本转换为向量表示
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2"
)结合我上面说的这些就能够组合成我们的超级简单小小RAG了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号