


4.2 Aggregates 聚合体
Aggregates 聚合体
As said before, an Aggregate is a cluster of objects (entities and value objects) bound together by an Aggregate Root object. This section will introduce the principles and rules related to the Aggregates.
如前所述,一个聚合体是由聚合根对象绑定在一起的一组对象(实体和值对象)。本节将介绍与聚合体有关的原则和规则。
We refer the term Entity both for Aggregate Root and sub-collection entities unless we explicitly write Aggregate Root or sub-collection entity.
除非我们明确写出Aggregate Root或sub-collection entities,否则我们对Aggregate Root和sub-collection entity都使用Entity这个术语。
Aggregate / Aggregate Root Principles 聚合/聚合根的原则
Business Rules 业务规则
Entities are responsible to implement the business rules related to the properties of their own. The Aggregate Root Entities are also responsible for their sub-collection entities.
实体负责实现与其自身属性有关的业务规则。聚合根实体还负责其子集实体。
An aggregate should maintain its self integrity and validity by implementing domain rules and constraints. That means, unlike the DTOs, Entities have methods to implement some business logic. Actually, we should try to implement business rules in the entities wherever possible.
一个聚合体应该通过实现领域规则和约束来保持其自我完整性和有效性。这意味着,与DTO不同,实体有方法来实现一些业务逻辑。实际上,我们应该尽可能地在实体中实现业务规则。
Single Unit 单元
An aggregate is retrieved and saved as a single unit, with all the sub-collections and properties. For example, if you want to add a Comment to an Issue, you need to;
一个聚合体是被检索并保存为一个单元,包括所有的子集和属性。例如,如果你想给一个问题(Issue)添加一个评论(Comment),你需要做以下事情:
- Get the
Issuefrom database with including all the sub-collections (CommentsandIssueLabels). - 从数据库中取得问题
Issue,包括所有子集(评论Comments和问题标签IssueLabels)。 - Use methods on the
Issueclass to add a new comment, likeIssue.AddComment(...);. - 使用
Issue类的方法来添加一个新的评论,如Issue.AddComment(...);。 - Save the
Issue(with all sub-collections) to the database as a single database operation (update). - 将问题
Issue(连同所有子集)作为一个单一的数据库操作(更新)保存到数据库。
That may seem strange to the developers used to work with EF Core & Relational Databases before. Getting the Issue with all details seems unnecessary and inefficient. Why don't we just execute an SQL Insert command to database without querying any data?
对于以前使用EF Core和关系型数据库的开发者来说,这可能显得很奇怪。获取问题Issue的所有细节似乎没有必要,而且效率很低。为什么我们不直接执行一个SQL插入Insert命令到数据库而不用查询任何数据呢?
The answer is that we should implement the business rules and preserve the data consistency and integrity in the code. If we have a business rule like "Users can not comment on the locked issues", how can we check the Issue's lock state without retrieving it from the database? So, we can execute the business rules only if the related objects available in the application code.
答案是,我们应该在代码中实现业务规则并保持数据的一致性和完整性。如果我们有一个业务规则,如 "用户不能对锁定的问题发表评论",我们如何在不从数据库中检索的情况下检查问题Issue的锁定状态?所以,只有当应用程序代码中的相关对象可用时,我们才能执行业务规则。
On the other hand, MongoDB developers will find this rule very natural. In MongoDB, an aggregate object (with sub-collections) is saved in a single collection in the database (while it is distributed into several tables in a relational database). So, when you get an aggregate, all the sub-collections are already retrieved as a part of the query, without any additional configuration.
另一方面,MongoDB开发者会发现这个规则非常自然。在MongoDB中,一个聚合对象(包括子集)被保存在数据库中的一个集合中(而在关系数据库中它被分配到几个表中)。因此,当你得到一个聚合时,所有的子集已经作为查询的一部分被检索出来了,不需要任何额外的配置。
ABP Framework helps to implement this principle in your applications.
ABP框架帮助你在你的应用程序中实现这一原则。
Example: Add a comment to an issue 例子:添加一个问题评论
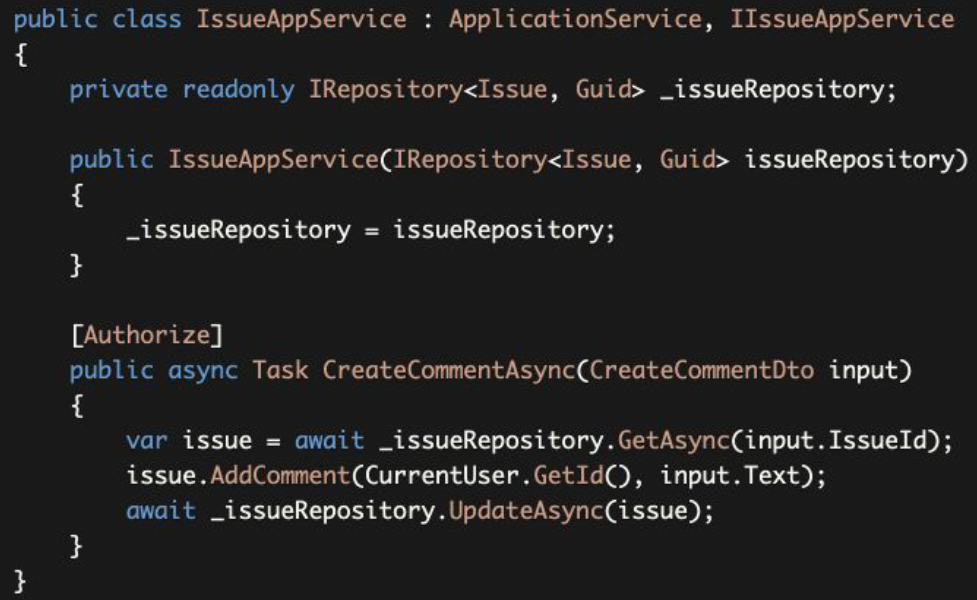
_issueRepository.GetAsync method retrieves the Issue with all details (sub-collections) as a single unit by default. While this works out of the box for MongoDB, you need to configure your aggregate details for the EF Core. But, once you configure, repositories automatically handle it. _issueRepository.GetAsync method gets an optional parameter, includeDetails, that you can pass false to disable this behavior when you need it.
issueRepository.GetAsync方法默认获取问题Issue及其所有细节(子集)作为一个单元。虽然这对MongoDB来说是开箱即用,但你需要为EF Core配置你的聚合细节。但是,一旦你配置了,存储库就会自动处理它。issueRepository.GetAsync方法得到一个可选的参数,includeDetails,你可以在需要时传入false来禁用这个行为。
See the Loading Related Entities section of the EF Core document for the configuration and alternative scenarios.
关于配置和备用方案,请参见EF Core文档的加载相关实体部分。
Issue.AddComment gets a userId and comment text, implements the necessary business rules and adds the comment to the Comments collection of the Issue.
Issue.AddComment得到一个userId和评论文本text,实现必要的业务规则,并将评论comment添加到问题Issue的评论集合中。
Finally, we use _issueRepository.UpdateAsync to save changes to the database.
最后,我们使用_issueRepository.UpdateAsync来保存变化到数据库。
EF Core has a change tracking feature. So, you actually don't need to call _issueRepository.UpdateAsync. It will be automatically saved thanks to ABP's Unit Of Work system that automatically calls DbContext.SaveChanges() at the end of the method. However, for MongoDB, you need to explicitly update the changed entity.
EF Core有一个变化跟踪功能。所以,你实际上不需要调用_issueRepository.UpdateAsync方法。它将被自动保存,由于ABP的工作单元系统在方法结束时自动调用DbContext.SaveChanges()。然而,对于MongoDB,你需要显式地更新改变的实体。
So, if you want to write your code Database Provider independent, you should always call the UpdateAsync method for the changed entities.
所以,如果你想写独立于数据库提供程序的代码,你应该总是为改变的实体调用UpdateAsync方法。
Transaction Boundary 事务边界
An aggregate is generally consideredl… as a transaction boundary. If a use case works with a single aggregate, reads and saves it as a single unit, all the changes made to the aggregate objects are saved together as an atomic operation and you don't need to an explicit database transaction.
一个聚合体通常被认为是......一个事务的边界。如果一个与一个聚合体一起工作的用例,将其作为一个单元进行读取和保存,那么对聚合体对象所做的所有改变都将作为一个原子操作进行保存,你不需要一个明确的数据库事务。
However, in real life, you may need to change more than one aggregate instances in a single use case and you need to use database transactions to ensure atomic update and data consistency. Because of that, ABP Framework uses an explicit database transaction for a use case (an application service method boundary). See the Unit Of Work documentation for more info.
然而,在现实生活中,你可能需要在一个用例中改变一个以上的聚合实例,你需要使用数据库事务来确保原子更新和数据一致性。正因为如此,ABP框架为一个用例(应用服务方法边界)使用了一个明确的数据库事务。更多信息请参见工作单元相关文档。
Serializability 可序列化
An aggregate (with the root entity and sub-collections) should be serializable and transferrable on the wire as a single unit. For example, MongoDB serializes the aggregate to JSON document while saving to the database and deserializes from JSON while reading from the database.
一个聚合体(包括根实体和子集)应该是可序列化的,并且可以作为一个单元在网上传输。例如,MongoDB在保存到数据库时将聚合体序列化为JSON文本,在从数据库读取时从JSON反序列化。
This requirement is not necessary when you use relational databases and ORMs. However, it is an important practice of Domain Driven Design.
当你使用关系型数据库和ORM时,这个要求是不必要的。然而,它是领域驱动设计的一个重要实践。
The following rules will already bring the serializability.
以下规则用于可序列化。
Aggregate / Aggregate Root Rules & Best Practices 聚合/聚合根的规则和最佳实践
The following rules ensures implementing the principles introduced above.
以下规则来确保实现上述介绍的原则。
Reference Other Aggregates Only by ID 只通过ID引用其他聚合体
The first rule says an Aggregate should reference to other aggregates only by their Id. That means you can not add navigation properties to other aggregates.
第一条规则说,一个聚合体应该只通过它们的Id来引用其他聚合体。这意味着你不能向其他聚合体添加导航属性。
- This rule makes it possible to implement the serializability principle.
- 这个规则使得实现可序列化原则成为可能。
- It also prevents different aggregates manipulate each other and leaking business logic of an aggregate to one another.
- 它还可以防止不同的聚合体相互操控,以及将聚合体的业务逻辑泄露给对方。
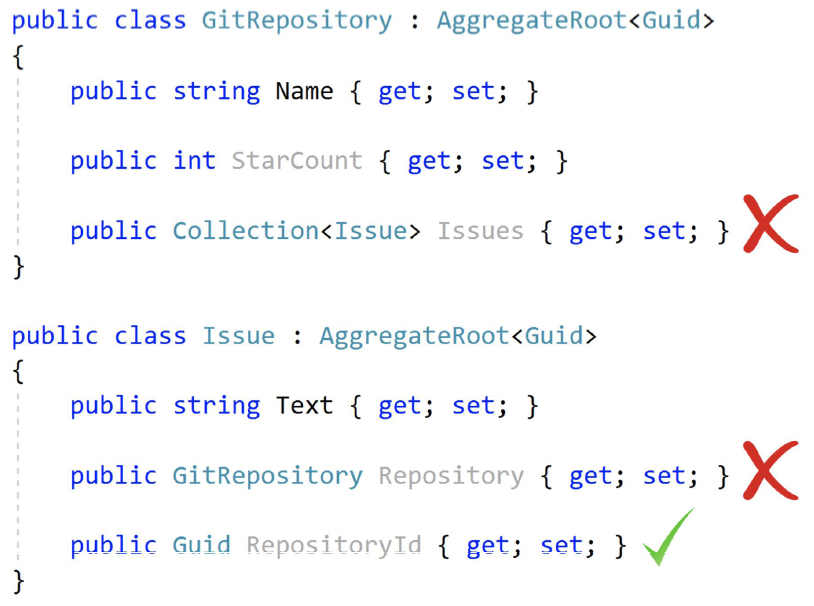
You see two aggregate roots,GitRepositoryandIssuein the example below;
在下面的例子中,你可以看到两个聚合根分别是GitRepository和Issue:
![image]()
GitRepositoryshould not have a collection of theIssues since they are different aggregates.GitRepository不应该有一个Issue的集合,因为它们是不同的聚合体。Issueshould not have a navigation property for the relatedGitRepositorysince it is a different aggregate.Issue不应该有关联的GitRepository的导航属性,因为它是一个不同的聚合体。Issuecan haveRepositoryId(as aGuid).Issue可以有RepositoryId(Guid类型)。
So, when you have anIssueand need to haveGitRepositoryrelated to this issue, you need to explicitly query it from database by theRepositoryId.
所以,当你有一个Issue,需要有与这个Issue相关的GitRepository,你需要显式地通过RepositoryId从数据库中查询。
For EF Core & Relational Databases 关于EF Core和关系型数据库
In MongoDB, it is naturally not suitable to have such navigation properties/collections. If you do that, you find a copy of the destination aggregate object in the database collection of the source aggregate since it is being serialized to JSON on save.
在MongoDB中,自然不适合有这样的导航属性/集合。如果你这样做,你会找到根据源聚合的数据库集合拷贝的目标聚合对象,因为它在保存时被序列化为JSON。
However, EF Core & relational database developers may find this restrictive rule unnecessary since EF Core can handle it on database read and write. We see this an important rule that helps to reduce the complexity of the domain prevents potential problems and we strongly suggest to implement this rule. However, if you think it is practical to ignore this rule, see the Discussion About the Database Independence Principle section above.
然而,EF Core和关系型数据库的开发者可能会发现这个限制性的规则是不必要的,因为EF Core可以在数据库的读写中处理它。我们认为这是一条重要的规则,有助于降低领域的复杂性防止潜在的问题,我们强烈建议实现这条规则。然而,如果你认为忽略这条规则是切实可行的,请参阅上面关于数据库独立原则部分的讨论。
Keep Aggregates Small 保持聚合体简单
One good practice is to keep an aggregate simple and small. This is because an aggregate will be loaded and saved as a single unit and reading/writing a big object has performance problems. See the example below:
一个好的做法是让一个聚合体保持简单和小巧。这是因为一个聚合体将作为一个单元被加载和保存,读/写一个大的对象可能带来性能问题。请看下面的例子:
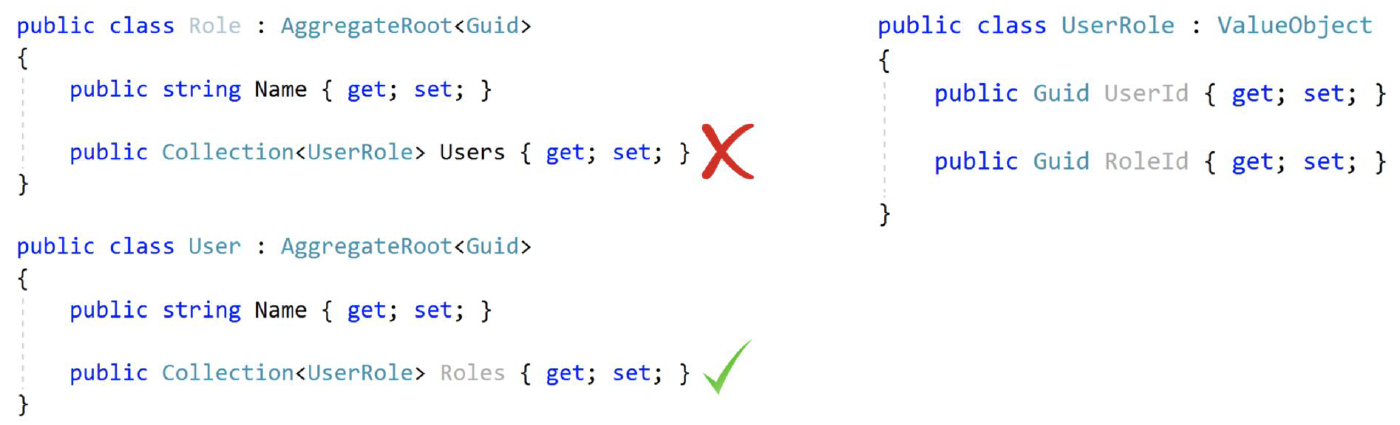
Role aggregate has a collection of UserRole value objects to track the users assigned for this role. Notice that UserRole is not another aggregate and it is not a problem for the rule Reference Other Aggregates Only By Id. However, it is a problem in practical. A role may be assigned to thousands (even millions) of users in a real life scenario and it is a significant performance problem to load thousands of items whenever you query a Role from database (remember: Aggregates are loaded by their sub-collections as a single unit).
Role聚合体有一个UserRole的值对象集合,用来跟踪为这个角色分配的用户。请注意,UserRole不是别的聚合体,对于只通过Id引用其他聚合体的规则来说,这不是问题。然而,这在实践中是一个问题。在现实生活中,一个角色可能被分配给数上千(甚至上百万)的用户,每当你从数据库中查询一个Role时,加载上千个个体是一个重要的性能问题(记住:聚合体是由它们的子集作为一个单元加载的)。
On the other hand, User may have such a Roles collection since a user doesn't have much roles in practical and it can be useful to have a list of roles while you are working with a User Aggregate.
另一方面,User可能有这样一个Roles集合,因为一个用户在实际工作中并没有太多的角色,当你在处理User Aggregate的时候,有一个角色列表是很有用的。
If you think carefully, there is one more problem when Role and User both have the list of relation when use a non-relational database, like MongoDB. In this case, the same information is duplicated in different collections and it will be hard to maintain data consistency (whenever you add an item to User.Roles, you need to add it to Role.Users too).
如果你仔细想想,当使用非关系型数据库(如MongoDB)时,当Role和User都有关系列表时还有一个问题。在这种情况下,相同的信息会在不同的集合中重复出现,这将很难保持数据的一致性(每当你在User.Roles中添加一个项目,你也需要将它添加到Role.Users中)。
So, determine your aggregate boundaries and size based on the following considerations;
因此,确定你的聚合体的界限和大小时请参考以下考虑因素:
- Objects used together.
- 一起使用的对象。
- Query (load/save) performance and memory consumption.
- 查询(加载/保存)性能和内存消耗。
- Data integrity, validity and consistency.
- 数据的完整性、有效性和一致性。
In practical;
实际上: - Most of the aggregate roots will not have sub-collections.
- 大多数聚合根不会有子集。
- A sub-collection should not have more than 100-150 items inside it at the most case. If you think a collection potentially can have more items, don't define the collection as a part of the aggregate and consider to extract another aggregate root for the entity inside the collection.
- 在最大限度下,一个子集不应该有超过100-150个项。如果你认为一个集合可能有更多的项目,就不要把这个集合定义为聚合体的一部分,并考虑为这个集合中的实体提取成为另一个聚合根。
Primary Keys on the Aggregate Roots / Entities 聚合根/实体上的主键
- An aggregate root typically has a single
Idproperty for its identifier (Primark Key: PK). We preferGuidas the PK of an aggregate root entity (see the Guid Genertation document to learn why). - 一个聚合根通常有一个
Id属性作为其标识符(Primark Key: PK)。我们更喜欢用Guid作为聚合根实体的PK(见Guid Genertation文档以了解原因)。 - An entity (that's not the aggregate root) in an aggregate can use a composite primary key.
- 聚合中的实体(不是聚合根)可以使用组合主键。
For example, see the Aggregate root and the Entity below:
例如,请看下面的聚合根和实体。
![image]()
Organizationhas aGuididentifier (Id).Organization有一个Guid类型的标识符(Id)。OrganizationUseris a sub-collection of anOrganizationand has a composite primary key consists of theOrganizationIdandUserId.OrganizationUser是一个Organization的子集,有一个由OrganizationId和UserId组成的组合主键。

That doesn't mean sub-collection entities should always have composite PKs. They may have single Id properties when it's needed.
这并不意味着子集实体应该总是有复合PK。必要时,他们可以有单一的Id属性。
Composite PKs are actually a concept of relational databases since the sub-collection entities have their own tables and needs to a PK. On the other hand, for example, in MongoDB you don't need to define PK for the sub-collection entities at all since they are stored as a part of the aggregate root.
组合主键实际上是关系型数据库的一个概念,因为子集实体有自己的表,需要一个主键。另一方面,例如在MongoDB中,你根本不需要为子集实体定义主键,因为它们是作为聚合根的一部分来存储的。
Constructors of the Aggregate Roots / Entities 聚合根/实体的构造函数
The constructor is located where the lifecycle of an entity begins. There are a some responsibilities of a well designed constructor:
构造函数位于一个实体的生命周期开始的地方。一个设计良好的构造函数应具有一下职责:
- Gets the required entity properties as parameters to create a valid entity. Should force to pass only for the required parameters and may get non-required properties as optional parameters.
- 获取所需的实体属性作为参数来创建一个有效的实体。应该强制只传递必要的参数,并可以将非必要的属性作为可选参数。
- Checks validity of the parameters.
- 检查参数的有效性。
- Initializes sub-collections.
- 初始化子集。
Example Issue (Aggregate Root) constructor Issue(聚合根)的构造函数示例:
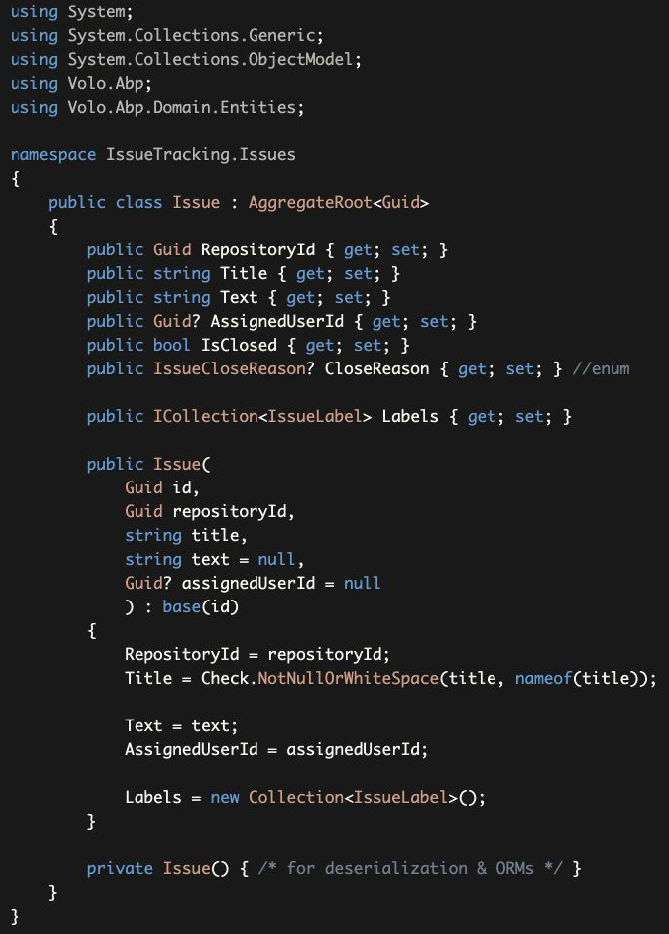
Issueclass properly forces to create a valid entity by getting minimum required properties in its constructor as parameters.Issue类通过在其构造函数中获得最小限度的所需属性作为参数,来强制创建一个正确有效的实体。- The constructor validates the inputs (
Check.NotNullOrWhiteSpace(...)throwsArgumentExceptionif the given value is empty). - 构造函数验证输入(
Check.NotNullOrWhiteSpace(...)如果给定值为空,则抛出ArgumentException)。 - It initializes the sub-collections, so you don't get a null reference exception when you try to use the
Labelscollection after creating theIssue. - 它对子集进行初始化,所以当你在创建
Issue之后试图使用Labels集合时,你不会得到一个空引用异常。 - The constructor also takes the
idand passes to thebaseclass. We don't generateGuids inside the constructor to be able to delegate this responsibility to another service (see Guid Generation). - 构造函数也接受
id并传递给基类。我们不在构造函数中生成Guids,以便能够将这个责任委托给其它服务处理(详见Guid Generation)。 - Private empty constructor is necessary for ORMs. We made it private to prevent accidently using it in our own code.
- 私有化空构造函数对ORM来说是必要的。我们把它变成私有的,以防止在我们自己的代码中意外地使用它。
See the Entities document to learn more about creating entities with the ABP Framework.
参见实体文档以了解有关用ABP框架创建实体的更多信息。
Entity Property Accessors & Methods 实体属性访问器和方法
The example above may seem strange to you! For example, we force to pass a non-null Title in the constructor. However, the developer may then set the Title property to null without any control. This is because the example code above just focuses on the constructor.
上面的例子对你来说可能很奇怪!例如,我们强制在构造函数中传递一个非空的Title。然而,开发人员可能会在没有任何控制的情况下将Title属性设置为null。这是因为上面的例子代码只是集中在构造函数上。
If we declare all the properties with public setters (like the example Issue class above), we can't force validity and integrity of the entity in its lifecycle. So;
如果我们用公共的设置器声明所有的属性(就像上面的Issue类的例子),我们就不能在实体的生命周期中强制保持其有效性和完整性。所以:
- Use private setter for a property when you need to perform any logic while setting that property.
- 当你需要在设置一个属性时执行任何逻辑,请为该属性使用私有设置器。
- Define public methods to manipulate such properties.
- 定义公共方法来操作这些属性。
Example: Methods to change the properties in a controlled way
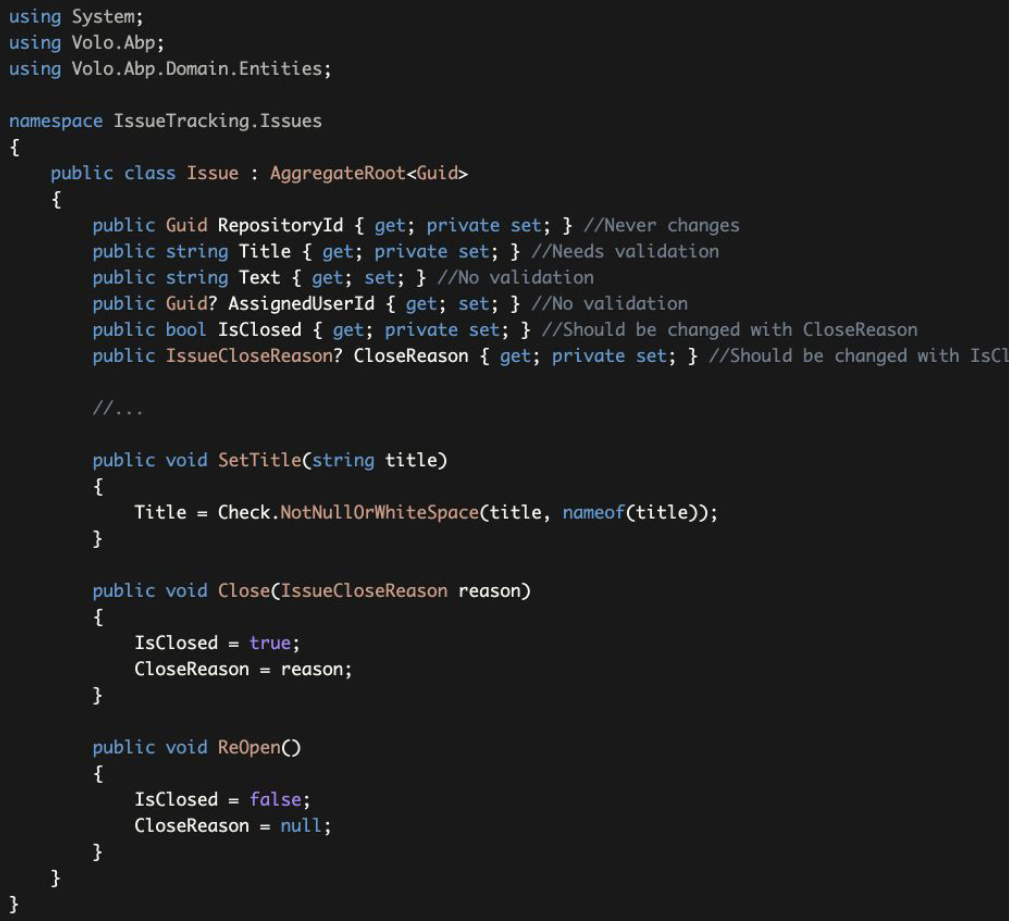
RepositoryIdsetter made private and there is no way to change it after creating anIssuebecause this is what we want in this domain: An issue can't be moved to another repository.RepositoryId设置器被做成私有的,在创建Issue后没有办法改变它,因为这就是我们在这个领域范围所希望的。一个Issue不能被转移到另一个资源库。Titlesetter made private andSetTitlemethod has been created if you want to change it later in a controlled way.- 如果你想以后以可控的方式改变它,将
Title设置器变成私有的,并创建SetTitle方法。 TextandAssignedUserIdhas public setters since there is no restriction on them. They can be null or any other value. We think it is unnecessary to define separate methods to set them. If we need later, we can add methods and make the setters private. Breaking changes are not problem in the domain layer since the domain layer is an internal project, it is not exposed to clients.Text和AssignedUserId有公有设置器,因为对它们没有任何限制。它们可以是null或任何其他值。我们认为没有必要单独定义方法来设置它们。如果我们以后需要,我们可以添加方法并使其设置器成为私有的。由于领域层是一个内层项目,它没有暴露给客户,所以破坏性的改变在域层中不是问题。IsClosedandIssueCloseReasonare pair properties. DefinedCloseandReOpenmethods to change them together. In this way, we prevent to close an issue without any reason.IsClosed和IssueCloseReason是一对属性。定义了Close和ReOpen方法来改变它们。通过这种方式,我们可以防止在没有任何原因的情况下关闭一个Issue。
Business Logic & Exceptions in the Entities 实体中的业务逻辑和异常处理
When you implement validation and business logic in the entities, you frequently need to manage the exceptional cases.
当你在实体中实现验证和业务逻辑时,你经常需要处理异常情况。
In these cases;
例如:
- Create domain specific exceptions.
- 生成领域的特例异常。
- Throw these exceptions in the entity methods when necessary.
- 必要时在实体方法中抛出这些异常。

There are two business rules here;
有以下两条业务规则:
- A locked issue can not be re-opened.
- 一个被锁定的
Issue不能被重新打开。 - You can not lock an open issue.
- 你不能锁定一个打开的
Issue。
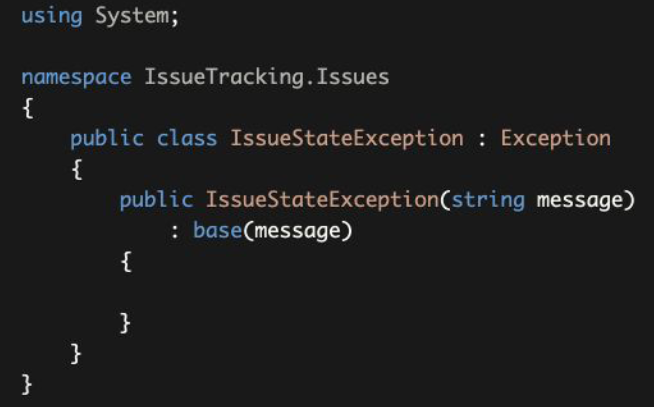
Issue class throws an IssueStateException in these cases to force the business rules:
在这些情况下,Issue类会抛出一个IssueStateException,以强制执行这条业务规则。
There are two potential problems of throwing such exceptions;
抛出这种异常有两个潜在的问题:
- In case of such an exception, should the end user see the exception (error) message? If so, how do you localize the exception message? You can not use the localization system, because you can't inject and use
IStringLocalizerin the entities. - 如果出现这样的异常,终端用户是否应该看到异常(错误)信息?如果可以看到,你如何将异常信息进行本地化?你不能使用本地化系统,因为你不能在实体中注入和使用
IStringLocalizer。 - For a web application or HTTP API, what HTTP Status Code should return to the client?
- 对于一个Web应用程序或HTTP API,应该向客户端返回什么样的HTTP状态代码?
ABP's Exception Handling system solves these and similar problems.
ABP的异常处理系统解决了这些以及类似的问题。
Example: Throwing a business exception with code 示例:用编码抛出一个业务异常
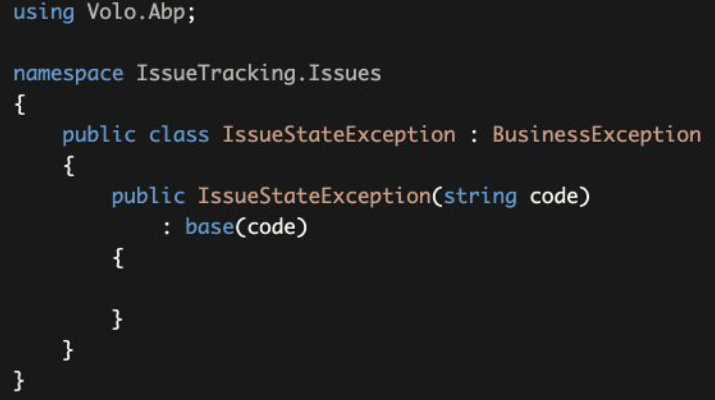
IssueStateExceptionclass inherits theBusinessExceptionclass. ABP returns 403 (forbidden) HTTP Status code by default (instead of 500 - Internal Server Error) for the exceptions derived from theBusinessException.IssueStateException类继承了BusinessException类。对于从BusinessException派生的异常,ABP默认返回403(禁止)HTTP状态代码(而不是500 - 内部服务器错误)。- The
codeis used as a key in the localization resource file to find the localized message. - 这个
code被用作本地化资源文件中的一个关键字,通过它可以找到本地化的信息。
Now, we can change the ReOpen method as shown below:
现在,我们可以改变ReOpen方法,如下图所示。
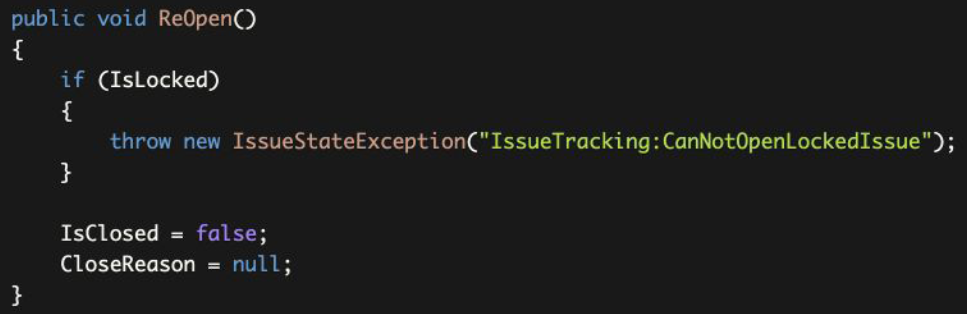
Use constants instead of magic strings.
使用常量而不是特殊的字符串。
And add an entry to the localization resource like below:
并在本地化资源中添加一个条目,如下所示:

- When you throw the exception, ABP automatically uses this localized message (based on the current language) to show to the end user.
- 当你抛出异常时,ABP自动使用这个本地化的消息(基于当前的语言)来显示给终端用户。
- The exception code (
IssueTracking:CanNotOpenLockedIssuehere) is also sent to the client, so it may handle the error case
programmatically. - 异常代码(此处为
IssueTracking:CanNotOpenLockedIssue)也会被发送到客户端,因此它可以通过程序化地处理这些错误信息。
For this example, you could directly throw BusinessException instead of defining a specialized IssueStateException. The result will be same. See the exception handling document for all the details.
对于这个例子,你可以直接抛出BusinessException而不是定义一个特定的IssueStateException。结果将是一样的。所有的细节见异常处理文档。
Business Logic in Entities Requiring External Services 实体中的业务逻辑需要外部服务
It is simple to implement a business rule in an entity method when the business logic only uses the properties of that entity. What if the business logic requires to query database or use any external services that should be resolved from the dependency injection system. Remember; Entities can not inject services!
当业务逻辑只使用该实体的属性时,在实体方法中实现业务规则很简单。如果业务逻辑需要查询数据库或使用任何从依赖注入系统中的外部服务来解决问题,该怎么办?请记住,实体不允许注入服务。
There are two common ways of implementing such a business logic:
有两种常见的方式来实现这样的业务逻辑:
- Implement the business logic on an entity method and get external dependencies as parameters of the method.
- 在一个实体方法上实现业务逻辑,并作为方法的参数获得外部依赖。
- Create a Domain Service.
- 创建一个领域服务。
Domain Services will be explained later. But, now let's see how it can be implemented in the entity class.
领域服务将在后面解释。但是,现在让我们看看如何在实体类中实现它。
Example: Business Rule: Can not assign more than 3 open issues to a user concurrently 示例:业务规则:不能给一个用户同时分配超过3个开放问题
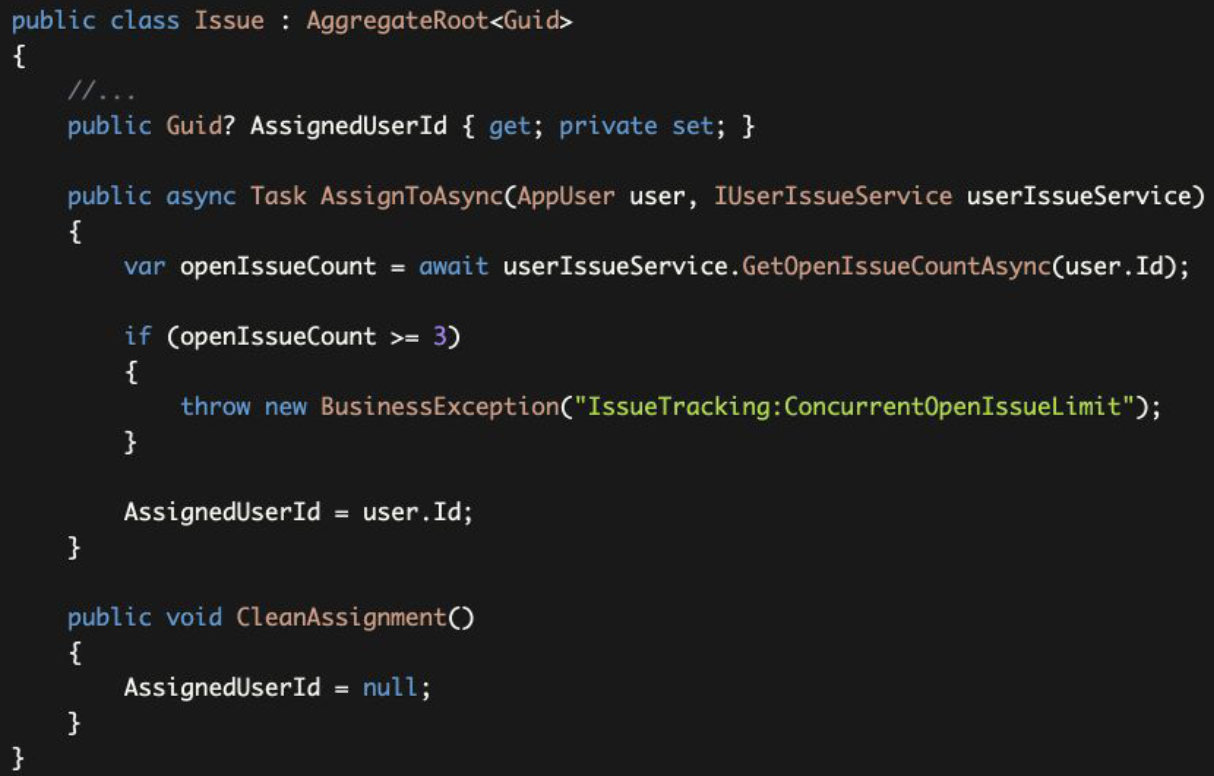
AssignedUserIdproperty setter made private. So, the only way to change it to use theAssignToAsyncandCleanAssignmentmethods.AssignedUserId属性设置器做成私有的。所以,改变它的唯一方法是使用AssignToAsync和CleanAssignment方法。AssignToAsyncgets anAppUserentity. Actually, it only uses the user.Id, so you could get aGuidvalue, likeuserId. However, this way ensures that theGuidvalue isIdof an existing user and not a randomGuidvalue.AssignToAsync获得一个AppUser实体。实际上,它只使用user.Id,所以你可以得到一个Guid值,比如userId。然而,这种方式可以确保Guid值是现有用户的Id,而不是一个随机的Guid值。IUserIssueServiceis an arbitrary service that is used to get open issue count for a user. It's the responsibility of the code part (that calls theAssignToAsync) to resolve theIUserIssueServiceand pass here.IUserIssueService是一个任意的服务,用于获取用户的开放问题计数值。代码部分(调用AssignToAsync)的职责就是解决IUserIssueService并在此传递它。AssignToAsyncthrows exception if the business rule doesn't meet.- 如果不满足业务规则
AssignToAsync会抛出异常。 - Finally, if everything is correct,
AssignedUserIdproperty is set. - 最后,如果一切正确,
AssignedUserId属性被设置。
This method perfectly guarantees to apply the business logic when you want to assign an issue to a user. However, it has some problems;
当你想把一个问题分配给一个用户时,这个方法可以完美地保证应用业务逻辑。然而,它也有一些问题,如下所示:
- It makes the entity class depending on an external service which makes the entity complicated.
- 它使实体类依赖于外部服务,从而使实体变得复杂。
- It makes hard to use the entity. The code that uses the entity now needs to inject
IUserIssueServiceand pass to theAssignToAsyncmethod. - 它使得很难使用实体。使用该实体的代码现在需要注入
IUserIssueService并传递给AssignToAsync方法。
An alternative way of implementing this business logic is to introduce a Domain Service, which will be explained later.
实现这一业务逻辑的另一种方法是引入一个领域服务,这将在后面解释。
本文来自博客园,作者:草叶睡蜢,转载请注明原文链接:https://www.cnblogs.com/tjubuntu/p/15442734.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号