django模型层 关于单表的增删改查
关于ORM
- MTV或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,
通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的工作量,不需要面对因数据库变更而导致的无效劳动
- ORM '对象--关系--映射的简称' Object--relation--mapping

简析他们的对应关系 :
sql <----------------> python代码
表 <---------------> 类
字段 <-------------> 属性
约束条件 <------------> 类属性约束对象
表记录 <------------> 实例化对象


优点: 1 符合python规范,将sql解耦于python代码 2 操作简单 3 数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的工作量,不需要面对因数据库变更而导致的无效劳动 缺点:效率低一点
#sql中的表 #创建表: CREATE TABLE employee( id INT PRIMARY KEY auto_increment , name VARCHAR (20), gender BIT default 1, birthday DATA , department VARCHAR (20), salary DECIMAL (8,2) unsigned, ); #sql中的表纪录 #添加一条表纪录: INSERT employee (name,gender,birthday,salary,department) VALUES ("alex",1,"1985-12-12",8000,"保洁部"); #查询一条表纪录: SELECT * FROM employee WHERE age=24; #更新一条表纪录: UPDATE employee SET birthday="1989-10-24" WHERE id=1; #删除一条表纪录: DELETE FROM employee WHERE name="alex" #python的类 class Employee(models.Model): id=models.AutoField(primary_key=True) name=models.CharField(max_length=32) gender=models.BooleanField() birthday=models.DateField() department=models.CharField(max_length=32) salary=models.DecimalField(max_digits=8,decimal_places=2) #python的类对象 #添加一条表纪录: emp=Employee(name="alex",gender=True,birthday="1985-12-12",epartment="保洁部") emp.save() #查询一条表纪录: Employee.objects.filter(age=24) #更新一条表纪录: Employee.objects.filter(id=1).update(birthday="1989-10-24") #删除一条表纪录: Employee.objects.filter(name="alex").delete()
单表操作
操作顺序:
1. 在app中的models.py文件中创建表结构
class Book(models.Model):
id=models.AutoField(primary_key=True)
title=models.CharField(max_length=32)
price=models.DecimalField(maxdigits=5,decimal_place=2)
publish=models.CharField(max_length=32)
pub_date=models.DateField()
1> CharField 字符串字段, 用于较短的字符串. CharField 要求必须有一个参数 maxlength, 用于从数据库层和Django校验层限制该字段所允许的最大字符数. <2> IntegerField #用于保存一个整数. <3> FloatField 一个浮点数. 必须 提供两个参数: 参数 描述 max_digits 总位数(不包括小数点和符号) decimal_places 小数位数 举例来说, 要保存最大值为 999 (小数点后保存2位),你要这样定义字段: models.FloatField(..., max_digits=5, decimal_places=2) 要保存最大值一百万(小数点后保存10位)的话,你要这样定义: models.FloatField(..., max_digits=19, decimal_places=10) admin 用一个文本框(<input type="text">)表示该字段保存的数据. <4> AutoField 一个 IntegerField, 添加记录时它会自动增长. 你通常不需要直接使用这个字段; 自定义一个主键:my_id=models.AutoField(primary_key=True) 如果你不指定主键的话,系统会自动添加一个主键字段到你的 model. <5> BooleanField A true/false field. admin 用 checkbox 来表示此类字段. <6> TextField 一个容量很大的文本字段. admin 用一个 <textarea> (文本区域)表示该字段数据.(一个多行编辑框). <7> EmailField 一个带有检查Email合法性的 CharField,不接受 maxlength 参数. <8> DateField 一个日期字段. 共有下列额外的可选参数: Argument 描述 auto_now 当对象被保存时,自动将该字段的值设置为当前时间.通常用于表示 "last-modified" 时间戳. auto_now_add 当对象首次被创建时,自动将该字段的值设置为当前时间.通常用于表示对象创建时间. (仅仅在admin中有意义...) <9> DateTimeField 一个日期时间字段. 类似 DateField 支持同样的附加选项. <10> ImageField 类似 FileField, 不过要校验上传对象是否是一个合法图片.#它有两个可选参数:height_field和width_field, 如果提供这两个参数,则图片将按提供的高度和宽度规格保存. <11> FileField 一个文件上传字段. 要求一个必须有的参数: upload_to, 一个用于保存上载文件的本地文件系统路径. 这个路径必须包含 strftime #formatting, 该格式将被上载文件的 date/time 替换(so that uploaded files don't fill up the given directory). admin 用一个<input type="file">部件表示该字段保存的数据(一个文件上传部件) . 注意:在一个 model 中使用 FileField 或 ImageField 需要以下步骤: (1)在你的 settings 文件中, 定义一个完整路径给 MEDIA_ROOT 以便让 Django在此处保存上传文件. (出于性能考虑,这些文件并不保存到数据库.) 定义MEDIA_URL 作为该目录的公共 URL. 要确保该目录对 WEB服务器用户帐号是可写的. (2) 在你的 model 中添加 FileField 或 ImageField, 并确保定义了 upload_to 选项,以告诉 Django 使用 MEDIA_ROOT 的哪个子目录保存上传文件.你的数据库中要保存的只是文件的路径(相对于 MEDIA_ROOT). 出于习惯你一定很想使用 Django 提供的 get_<#fieldname>_url 函数.举例来说,如果你的 ImageField 叫作 mug_shot, 你就可以在模板中以 {{ object.#get_mug_shot_url }} 这样的方式得到图像的绝对路径. <12> URLField 用于保存 URL. 若 verify_exists 参数为 True (默认), 给定的 URL 会预先检查是否存在( 即URL是否被有效装入且 没有返回404响应). admin 用一个 <input type="text"> 文本框表示该字段保存的数据(一个单行编辑框) <13> NullBooleanField 类似 BooleanField, 不过允许 NULL 作为其中一个选项. 推荐使用这个字段而不要用 BooleanField 加 null=True 选项 admin 用一个选择框 <select> (三个可选择的值: "Unknown", "Yes" 和 "No" ) 来表示这种字段数据. <14> SlugField "Slug" 是一个报纸术语. slug 是某个东西的小小标记(短签), 只包含字母,数字,下划线和连字符.#它们通常用于URLs 若你使用 Django 开发版本,你可以指定 maxlength. 若 maxlength 未指定, Django 会使用默认长度: 50. #在 以前的 Django 版本,没有任何办法改变50 这个长度. 这暗示了 db_index=True. 它接受一个额外的参数: prepopulate_from, which is a list of fields from which to auto-#populate the slug, via JavaScript,in the object's admin form: models.SlugField (prepopulate_from=("pre_name", "name"))prepopulate_from 不接受 DateTimeFields. <13> XMLField 一个校验值是否为合法XML的 TextField,必须提供参数: schema_path, 它是一个用来校验文本的 RelaxNG schema #的文件系统路径. <14> FilePathField 可选项目为某个特定目录下的文件名. 支持三个特殊的参数, 其中第一个是必须提供的. 参数 描述 path 必需参数. 一个目录的绝对文件系统路径. FilePathField 据此得到可选项目. Example: "/home/images". match 可选参数. 一个正则表达式, 作为一个字符串, FilePathField 将使用它过滤文件名. 注意这个正则表达式只会应用到 base filename 而不是 路径全名. Example: "foo.*\.txt^", 将匹配文件 foo23.txt 却不匹配 bar.txt 或 foo23.gif. recursive可选参数.要么 True 要么 False. 默认值是 False. 是否包括 path 下面的全部子目录. 这三个参数可以同时使用. match 仅应用于 base filename, 而不是路径全名. 那么,这个例子: FilePathField(path="/home/images", match="foo.*", recursive=True) ...会匹配 /home/images/foo.gif 而不匹配 /home/images/foo/bar.gif <15> IPAddressField 一个字符串形式的 IP 地址, (i.e. "24.124.1.30"). <16> CommaSeparatedIntegerField 用于存放逗号分隔的整数值. 类似 CharField, 必须要有maxlength参数.
关于参数
(1)null 如果为True,Django 将用NULL 来在数据库中存储空值。 默认值是 False. (1)blank 如果为True,该字段允许不填。默认为False。 要注意,这与 null 不同。null纯粹是数据库范畴的,而 blank 是数据验证范畴的。 如果一个字段的blank=True,表单的验证将允许该字段是空值。如果字段的blank=False,该字段就是必填的。 (2)default 字段的默认值。可以是一个值或者可调用对象。如果可调用 ,每有新对象被创建它都会被调用。 (3)primary_key 如果为True,那么这个字段就是模型的主键。如果你没有指定任何一个字段的primary_key=True, Django 就会自动添加一个IntegerField字段做为主键,所以除非你想覆盖默认的主键行为, 否则没必要设置任何一个字段的primary_key=True。 (4)unique 如果该值设置为 True, 这个数据字段的值在整张表中必须是唯一的 (5)choices 由二元组组成的一个可迭代对象(例如,列表或元组),用来给字段提供选择项。 如果设置了choices ,默认的表单将是一个选择框而不是标准的文本框,<br>而且这个选择框的选项就是choices 中的选项。
2. 创建数据库
因为ORM没办法为我们创建数据库,所以我们必须自己利用DOS命令登录创建数据库 (这边我使用的mysql数据库)
#这边我们自己用命令创建了一个名bms的数据库,这个数据库的名字必须和待会配置所要用的名字一致

3. 配置 settings.py
#这边需要我们自己去配置要使用的是什么类型的数据库,端口等等信息,要不然就是Django默认的
#这是默认的
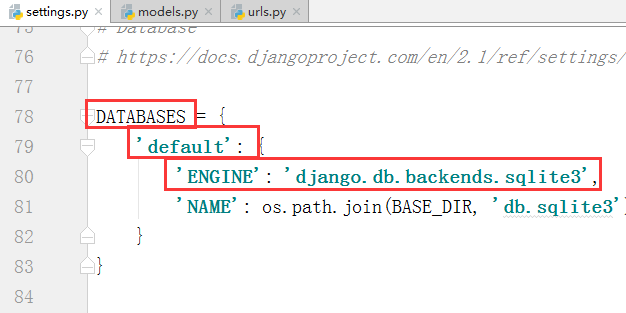
#我们自己要配置的
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME':'bms', # 要连接的数据库,连接前需要创建好
'USER':'root', # 连接数据库的用户名
'PASSWORD':'', # 连接数据库的密码
'HOST':'127.0.0.1', # 连接主机,默认本级
'PORT':3306 # 端口 默认3306
}
}
settings配置 若想将模型转为mysql数据库中的表,需要在settings中配置: 复制代码 DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME':'bms', # 要连接的数据库,连接前需要创建好 'USER':'root', # 连接数据库的用户名 'PASSWORD':'', # 连接数据库的密码 'HOST':'127.0.0.1', # 连接主机,默认本级 'PORT':3306 # 端口 默认3306 } } 复制代码 注意1:NAME即数据库的名字,在mysql连接前该数据库必须已经创建,而上面的sqlite数据库下的db.sqlite3则是项目自动创建 USER和PASSWORD分别是数据库的用户名和密码。设置完后,再启动我们的Django项目前,我们需要激活我们的mysql。然后,启动项目,会报错:no module named MySQLdb 。这是因为django默认你导入的驱动是MySQLdb,可是MySQLdb 对于py3有很大问题,所以我们需要的驱动是PyMySQL 所以,我们只需要找到项目名文件下的__init__,在里面写入: import pymysql pymysql.install_as_MySQLdb() 最后通过两条数据库迁移命令即可在指定的数据库中创建表 : python manage.py makemigrations python manage.py migrate 注意2:确保配置文件中的INSTALLED_APPS中写入我们创建的app名称 复制代码 INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', "book" ] 复制代码 注意3:如果报错如下: django.core.exceptions.ImproperlyConfigured: mysqlclient 1.3.3 or newer is required; you have 0.7.11.None MySQLclient目前只支持到python3.4,因此如果使用的更高版本的python,需要修改如下: 通过查找路径C:\Programs\Python\Python36-32\Lib\site-packages\Django-2.0-py3.6.egg\django\db\backends\mysql 这个路径里的文件把 if version < (1, 3, 3): raise ImproperlyConfigured("mysqlclient 1.3.3 or newer is required; you have %s" % Database.__version__) 注释掉 就OK了。 注意4: 如果想打印orm转换过程中的sql,需要在settings中进行如下配置: LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console':{ 'level':'DEBUG', 'class':'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level':'DEBUG', }, } }
4. 数据库迁移
#在pycharm中的terminal执行这个命令,启动
1. python manage.py makemigrations

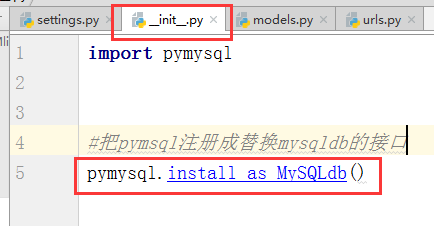
2.所以我们应该在整个项目的启动文件 __init__.py 中加入这么一句话
import pymysql
#把pymsql注册成替换mysqldb的接口
pymysql.install_as_MySQLdb()
3. 再执行一下第一步:
python manage.py makemigrations
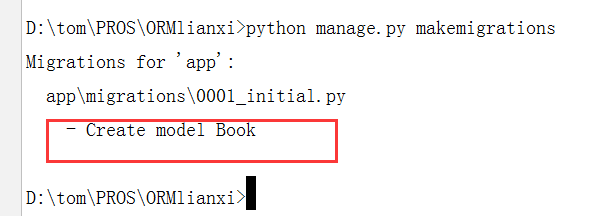
出现如上图的就说明执行成功了 (模型的名称就是你在models.py创建的类名)
但是这一步也只是生成了一个00001_inital.py临时过度文件,
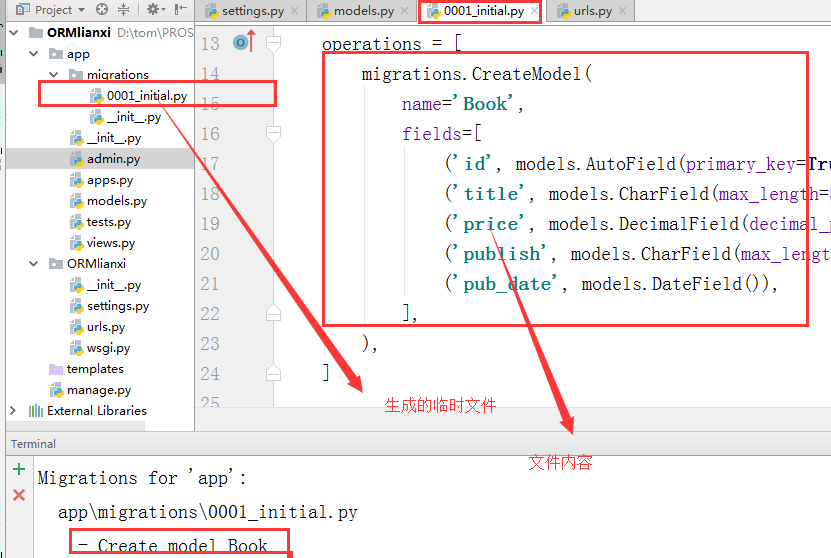
4. 接下来执行这个命令
python manage.py migrate

出现如上图说明执行成功了
5.我们通过DOS命令进入终端看看表是否创建成功
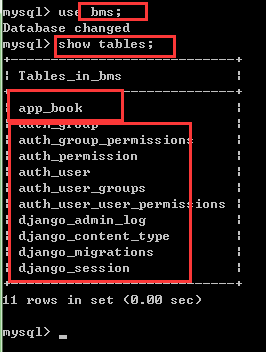
如上图,创建成功了,但是表有很多,不止我们创建的那个,
我们到settings.py去看看
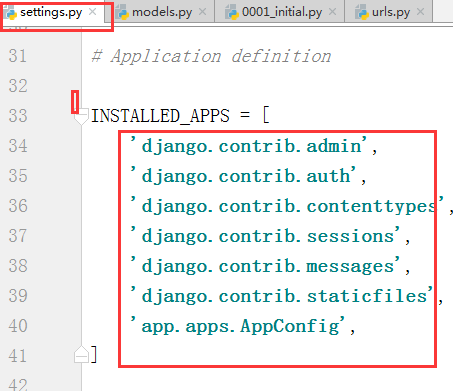
我们发现多出来的表和这边的一一对应,说明django只会为INSTALL_APPS的应用创建表,
那这些表是哪里来的?
这些都是django内置的应用.说明数据迁移命令执行的的时候只会为settings.py文件中的install_app的中的应用中的models
创建表结构.
看一下表结构:
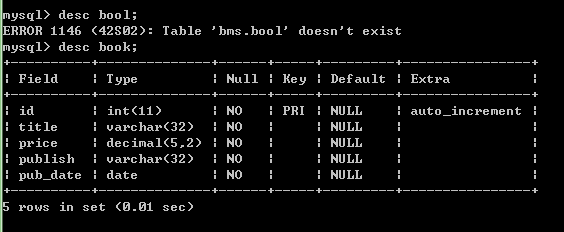
还有一个问题就是表名:我们并没有为表命名,所有django就把应用的名字和我们所创建的类名联合起来作为表名.
1.关于表更名,我们先去models.py文件中协商要更改的名字,
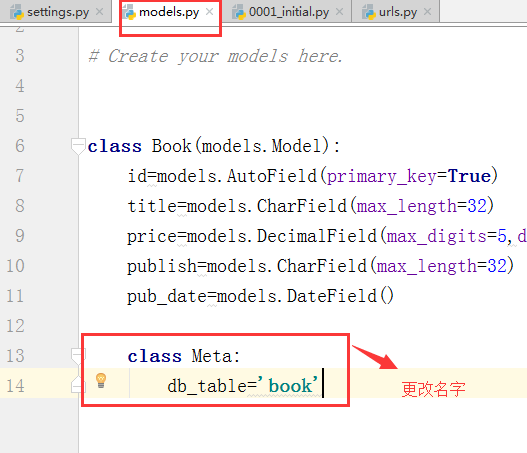
2. 我们再次执行
python manage.py makemigrations
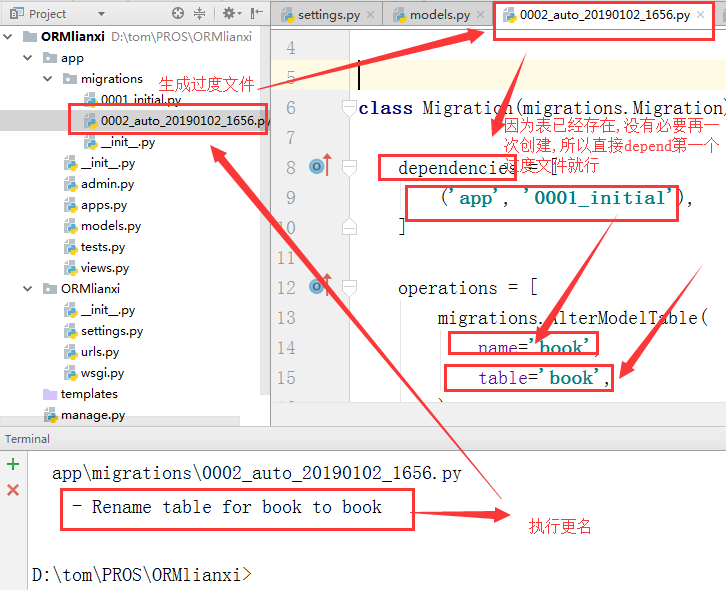
3. 再次执行命令进行迁移
python mange.py migrate
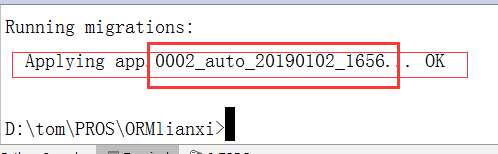
看到了把,应用生成的第二个过度文件成功了.
4.我们可以再去数据库检查一下
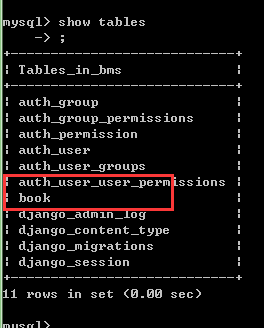
名字也改过来了!
5. 启动项目
python manage.py runserver
关于表的增删改查
1. 这边要先去url控制器分配路径,
2. 视图函数中定义一个添加数据到数据库操作的函数(要记得把在modls创建的类名导入进去)
from app.models import Book
添加表记录
def add(request): #添加记录 #方式1: # book1=Book(title='python',price=100,publish='深圳出版社',pub_date='2018-12-12') # book1.save() #方式2 比较常用,并且创建这种方式会有一个返回值,不需要保存 book2=Book.objects.create(title='linux',price=500,publish='我曹出版社',pub_date='2018-09-07') #注意,两种方式都是关键字传参 return HttpResponse('添加成功')
#这边要清楚的是,这里的每一个实例对象都是表的一条记录
查询表记录
查询API
<1> all(): 查询所有结果
<2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 <3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个, 如果符合筛选条件的对象超过一个或者没有都会抛出错误。 <4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象<5> order_by(*field): 对查询结果排序 <6> reverse(): 对查询结果反向排序 <8> count(): 返回数据库中匹配查询(QuerySet)的对象数量。 <9> first(): 返回第一条记录 <10> last(): 返回最后一条记录 <11> exists(): 如果QuerySet包含数据,就返回True,否则返回False<12> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列<13> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列<14> distinct(): 从返回结果中剔除重复纪录
from django.shortcuts import render,HttpResponse from app.models import Book # Create your views here. #单标操作,添加 def add(request): #添加记录 #方式1: # book1=Book(title='python',price=100,publish='深圳出版社',pub_date='2018-12-12') # book1.save() #方式2 比较常用,并且创建这种方式会有一个返回值 book2=Book.objects.create(title='linux',price=500,publish='我曹出版社',pub_date='2018-09-07') #注意,两种方式都是关键字传参 return HttpResponse('添加成功') #查询 def query(request): ''' #1 all()查询所有记录 #返回值是一个queryset集合对象(跟jquery很类似) ret=Book.objects.all() print(ret) #<QuerySet [<Book: Book object (1)>, <Book: Book object (2)>]> #queryset里面装的是模型类对象 for obj in ret: #循环把模型类对象拿出来,就可以拿到他的值 print(obj.title) #2 first last # book=Book.objects.all().first() # book = Book.objects.all().last() print(book.title) print(queryset[0].title) #queryset只用用自己类的方法 #3 filter queryset=Book.objects.all().filter(title='python').count() print(queryset) queryset = Book.objects.all().filter(title='python') queryset = Book.objects.all().filter(title='python',price=100) #这边是and #4 get obj=Book.objects.get(title='python') #只返回一个模型对象,超过一个或者没有都报错 print(obj.title) #有且只有一个 #5 排除方法 queryset=Book.objects.exclude(title='python').count() print(queryset) #6 order_by queryset=Book.objects.all() #默认是id升序排序 Book.objects.all().order_by('price') #按price升序排列 Book.objects.all().order_by('price','id')#当price一样,按id排 Book.objects.all().order_by('-price')#按price降序排列 print('queryset',queryset) #7 reverse翻转 Book.objects.all().reverse() #8 exists 判断是否存在 if Book.objects.all().exists():#只会判断第一条会不会存在 print('ok') #9 value 用的最多 # queryset=Book.objects.all().filter(price=500).values('title','price') #本身含有for循环 # print(queryset) #<QuerySet [{'title': 'linux', 'price': Decimal('500.00')}]> queryset = Book.objects.all().filter(price=500).values_list('title', 'price') print(queryset) #<QuerySet [('linux', Decimal('500.00'))]> ''' #10 distant 去重 Book.objects.all().values('price').distinct() return HttpResponse('查询成功') #和上面的区别是这是一个个的元组,上面是列表
qureyset可调用方法:
# 1 all() 方法:返回queryset
# ret=Book.objects.all()
# print(ret) # <QuerySet [<Book: GO>, <Book: linux>, <Book: 北京折叠>, <Book: 三体>, <Book: 追风筝的人>, <Book: 乱世佳人>]>
# 2 filter 方法:返回值queryset
# ret=Book.objects.filter(title="linux",price=111)
# print(ret) # <QuerySet [<Book: linux>]>
# 3 get方法:返回查询到model对象
# ret=Book.objects.get(price=111)
# ret=Book.objects.get(title="linux")
# print(ret.title) # linux
# 4 first() last()方法:queryset调用 返回model对象
# fbook=Book.objects.all()[0]
# fbook=Book.objects.all().first()
# lbook=Book.objects.all().last()
# 5 exclude:返回值一个queryset
# ret=Book.objects.exclude(price=111)
# print(ret)
# 6 order_by:排序 由queryset对象调用,返回值是queryset
# ret=Book.objects.all().order_by("-price","-nid").first()
# print(ret)
# 7 count :数数 :由queryset对象调用 返回int
# ret=Book.objects.all().count()
# print(ret)
# 8 reverse():由queryset对象调用,返回值是queryset
# Book.objects.all().order_by("price").reverse()
# 9 exists: 由queryset对象调用 返回值布尔值
# is_exist=Book.objects.all().exists()
# if is_exist:
# print("OK")
# 10 values方法:由queryset对象调用,返回值是queryset
# ret=Book.objects.all().values("title","price") # queryset [{"title":"linux"},{"title":"python"},...]
# print(ret) # <QuerySet [{'title': 'GO'}, {'title': 'linux'}, {'title': '北京折叠'}, {'title': '三体'}, {'title': '追风筝的人'}, {'title': '乱世佳人'}]>
#
# '''
# ret=[]
# for obj in Book.objects.all():
# temp={
# "title":obj.title
# "price":obj.price
# }
# ret.append(temp)
#
# '''
# # 11 values_list:由queryset对象调用,返回值是queryset
# ret=Book.objects.all().values_list("title","price")
# print(ret) # <QuerySet [('GO',), ('linux',), ('北京折叠',), ('三体',), ('追风筝的人',), ('乱世佳人',)]>
#
# # distinct: 由queryset对象调用,返回值是queryset
# ret=Book.objects.all().values("title").distinct()
# print(ret)
双下划线模糊查询
Book.objects.filter(price__in=[100,200,300]) #必须在三者之一 Book.objects.filter(price__gt=100) #大于 Book.objects.filter(price__lt=100) #小于 Book.objects.filter(price__range=[100,200]) #范围 Book.objects.filter(title__contains="python") #包含 Book.objects.filter(title__icontains="python") #包含,不区分大小写 Book.objects.filter(title__startswith="py") #以XX开头 Book.objects.filter(pub_date__year=2012,pub__date__month=12) #具体的某个值
双下划线连接类的字段和条件
单表之查询 明确的是:删改都要在查到的基础上面删除
#删除
# Book.objects.all().filter(price=500).delete()
# book=Book.objects.all().filter(id=4)
# book.delete()
#修改
Book.objects.update(price=900)
return HttpResponse('查询成功') #和上面的区别是这是一个个的元组,上面是列表
删除方法就是 delete()。它运行时立即删除对象而不返回任何值。例如: model_obj.delete() 你也可以一次性删除多个对象。每个 QuerySet 都有一个 delete() 方法,它一次性删除 QuerySet 中所有的对象。 例如,下面的代码将删除 pub_date 是2005年的 Entry 对象: Entry.objects.filter(pub_date__year=2005).delete() 在 Django 删除对象时,会模仿 SQL 约束 ON DELETE CASCADE 的行为,换句话说,删除一个对象时也会删除与它相关联的外键对象。例如: b = Blog.objects.get(pk=1) # This will delete the Blog and all of its Entry objects. b.delete() 要注意的是: delete() 方法是 QuerySet 上的方法,但并不适用于 Manager 本身。这是一种保护机制,是为了避免意外地调用 Entry.objects.delete() 方法导致 所有的 记录被误删除。如果你确认要删除所有的对象,那么你必须显式地调用: Entry.objects.all().delete() 如果不想级联删除,可以设置为: pubHouse = models.ForeignKey(to='Publisher', on_delete=models.SET_NULL, blank=True, null=True)
修改表纪录
Book.objects.filter(title__startswith="py").update(price=120) 此外,update()方法对于任何结果集(QuerySet)均有效,这意味着你可以同时更新多条记录update()方法会返回一个整型数值,表示受影响的记录条数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号