
OO第一单元总结
OO第一单元总结
一.设计思路与bug分析
1.第一次作业
在第一次作业
在第一次作业中测试阶段,公测与强测没有出现bug,得分100,互测中被测出7个bug,全部是由于没有对非\t与<space>的其他不可见空白控制字符造成的。(当时对指导书理解出现了失误,认为空白字符只有\t space是基本限制条件)
通过在进行合法性检查时进行非法字符特判,将这7个bug一次性修复通过
2.第二次作业
在第二次作业的优化环节,我出现了重大失误,对本次化简的复杂度估计严重不足,盲目采取了带有剪枝的DFS进行遍历搜索,企图依靠穷举得出全局最优解,遭到了惨痛的失败
第二次作业的公测全部通过,强测得分93.33,有一个测试点死于DFS导致的stackOverflow引发的异常,互测也有一个测试点出现了DFS爆栈。
在BUG修复阶段,通过限制dfs的递归的深度一次性解决了被爆栈的问题
3.第三次作业
第三次作业我依然用了正则表达式结合括号的栈匹配与递归进行输入的解析。
第三次作业中公测,强测,互测中均未被发现bug,但强测性能分不佳,总分为96.17,教训一样十分惨痛
强测性能分丢失过于严重的两个主要原因是
1.对指导书阅读不细致导致设计上出现了严重冗余,后期修改过多,加之我所编写的优化函数与其他类耦合实在过于紧密,增加了优化难度
在进行最初的设计时,我未仔细阅读指导书,误认为形如0^0 sin(2*x)等因子均为合法,弄出了一个幂函数类,并且让三角函数类直接持有幂函数对象,怼优化造成了一定困难
2.缺少信心,对本次作业难度估计过高,一开始就没打算做太好的优化,结果导致设计未充分考虑优化需求,在最后发现还有较多时间时追悔莫及
在进行最初的设计时,我高估了本次作业难度,抱着“这么变态的作业,不无效就赚了”的心理,设计时处处牺牲优化来换取难度的降低(例如持有对象的容器上放弃了有利于优化的HashMap,选择了ArrayList,甚至连equals函数也没有override,更别说),结果周五一晚上马原课加周日一早上搞定之后,追悔莫及但已回天乏术
(重写是不可能重写的,这辈子是不可能重写了,就只有硬撑着再写了几个不彻底的同类项合并,维持着强测没有把我的脸丢绝这样子)
二.对三次作业代码的度量
0.概述
以下是对最后的第三次作业进行uml图绘制与复杂度分析的结果
在各个类的类方法中,simple0()方法普遍复杂度极高,这是由于在进行化简时的策略与对象的类型联系十分紧密,在必要时甚至直接获取了RTTI信息,读取其对应的类名,造成了极其高的耦合度。
在其他正常类功能中复杂度普遍处于正常水平,除部分类的构造函数出现了较高的模块设计复杂度
1.UML图
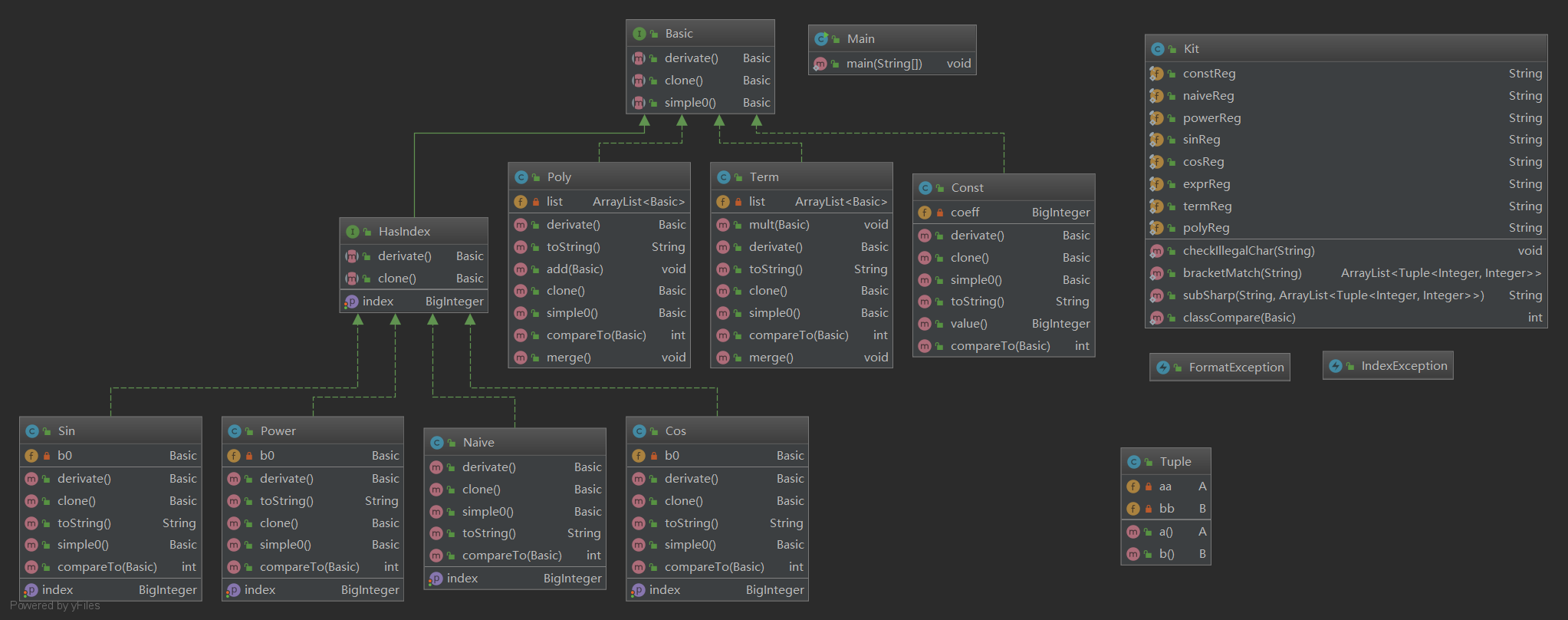
2.代码复杂度分析

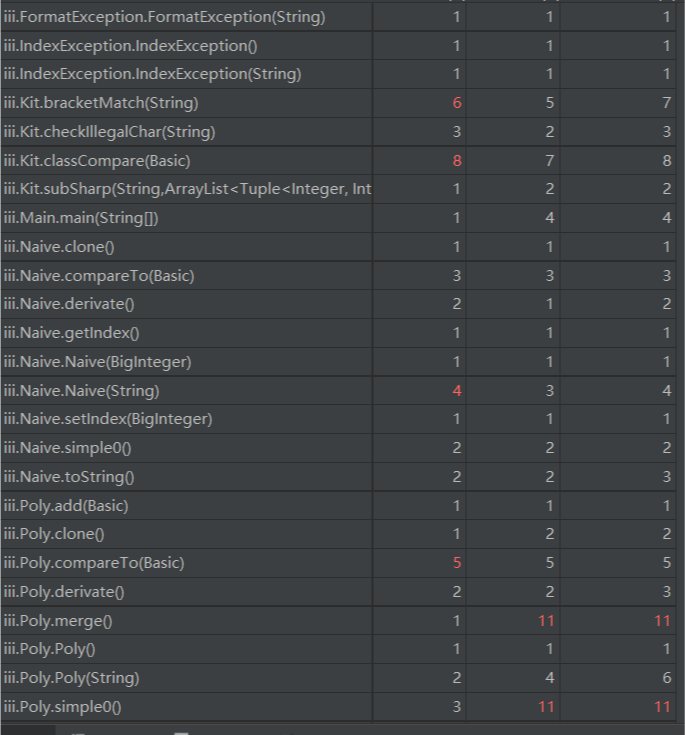

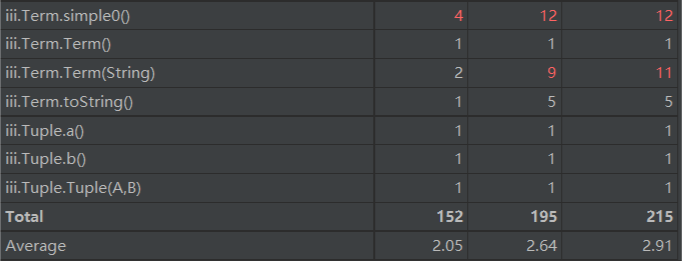
三.分析其他人bug的策略
我测试别人分三步:大致阅读代码,进行量身定制的测试,使用自动化评测脚本进行随机测试与自动化评判。
阅读代码时
第一步肯定是检查他的正则表达式,大致看一下他的输入逻辑,合法性检查的逻辑,以期抓住bug
再看看他的类图,看一下他持有各个对象的方式等
第二步是进行一些量身定制的bug(例如看到拿LIst的就给他来一个x-x试试,看看他考没考虑到list是空的情况等;根据其设计检查一下他对嵌套的处理是否正确等....)
第三步就是动用我的脚本,采用依托sympy的python脚本随机大量生成测试数据(一般来500个左右吧),依靠在 git bash下运行的shell脚本自动化执行,再利用python脚本进行正确性检验
(对于某些一main到底的同学直接到第三步加急,而且测试次数加倍........)
四:可能的设计模式的应用
emmmmm其实在生成各个对象的时候可以采取工厂设计模式
以及,事后诸葛亮一下,我在第三次作业发现我理解错了指导书时候,完全可以采取适配器模式重用(挽救)一下我最初的代码,使得原来多于的幂函数类可以适应新的设计(可惜我当时没想到)
