LDA
LDA简介:
LDA的全称是Linear Discriminant Analysis(线性判别分析),是一种supervised learning。因为是由Fisher在1936年提出的,所以也叫Fisher’s Linear Discriminant。
LDA通常作为数据预处理阶段的降维技术,其目标是将数据投影到低维空间来避免维度灾难(curse of dimensionality)引起的过拟合,同时还保留着良好的可分性。
LDA的引出:
经常经过特征提取以后,我们需要进行降维。首先我们简化一下问题便于阐述其原理:
假设在二维特征空间中,有两类样本,那么我们的目标就是对给定的数据集,将其投影到一条直线上,但是投影的方法有千千万万种,那么我们改选择什么样的投影呢?
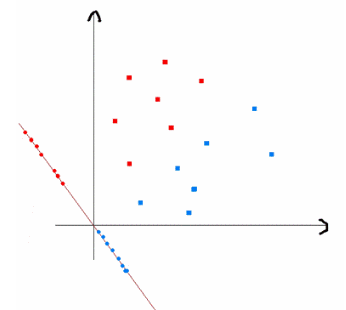
首先我们的任务是为了分类服务的,那么我们需要投影后的样本尽可能的分开,最简单的度量类别之间分开程度的方式就是类别均值投影之后的距离。
一种比较好的投影方式就是利用不同类别的数据的中心来代表这类样本在空间中的位置,考虑1个2分类问题。两类的均值向量为:
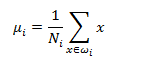
同时保证让投影之后的中心距离尽可能的大,也就是:
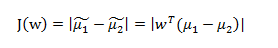
其中
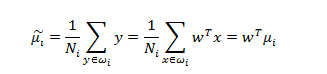
是来自类别 的投影数据的均值,
是我们的投影向量。但是,通过增大w,这个表达式可以任意增大。为了解决这个问题,我们可以将w限制为单位长度,即
。
使用拉格朗日乘数法来进行有限制条件的最大化问题的求解,我们可以发现 。这个方法还有一个问题,如下图所示:
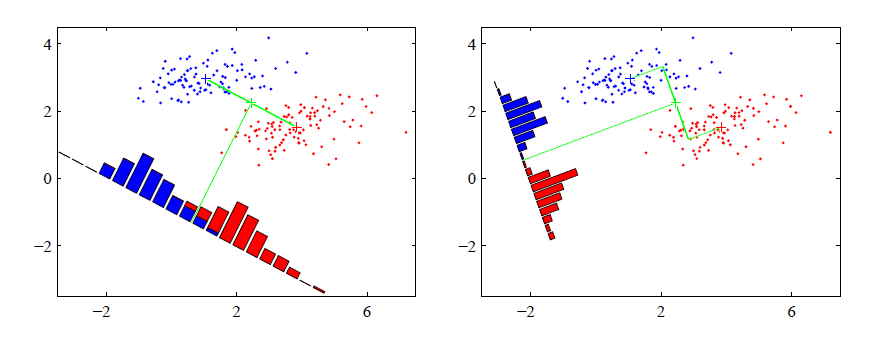
左图为最大间隔度量的降维结果,这幅图中的两个类别在原始空维空间(x1; x2)中可以完美地被分开,但是当投影到连接它们的均值的直线上时,就有了一定程度的重叠。
因此,Fisher提出的思想:最大化一个函数,这个函数能够让类均值的投影分开得较大,同时让每个类别内部的方差较小,从而最小化了类别的重叠(右图中的结果)。
这也是LDA的中心思想即:最大化类间距离,最小化类内距离。
LDA算法推导——2类:
接着上一段的引出,我们已经找到了一种不错的投影方式,现在只需要让其最小化类内的方差,我们假设投影结束后,样本的坐标为 ,即
,那么来自类别Ck的数据经过变换后的类内方差为:
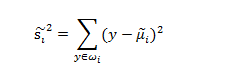
我们可以把整个数据集的总的类内方差定义为 。Fisher准则根据类间距离和类内方差的比值定义,即:
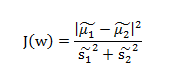
根据 ,以及
,对上式子进行改写,
通过:
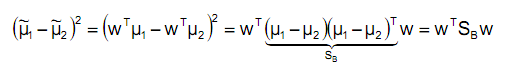
通过下式:
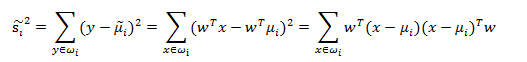
J(W)可以被重写为:
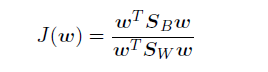
其中 是类间(between-class)散度矩阵,形式为
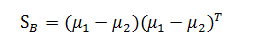
被称为类内(within-class)散度矩阵,形式为:
对公式J(W)关于w求导,并另之为0,我们发现J(w)取得最大值的条件为:
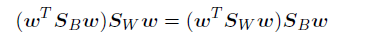
实际上恰好就是倒数的分母。由于 和
在简化的二分类问题中都是标量,因此我们可以把上式子看做:
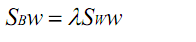
(或者将分母限定在模为1,利用拉格朗日求解也可以得到上式,具体参考周志华《机器学习》)
将求导后的结果两边都乘以 可得:
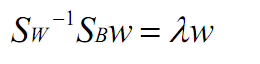
从这里就可以看出,是一个求特征值和特征向量的问题了。
具体的,对于我们在引出中提出的简化问题,由于:
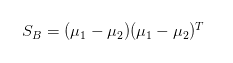
因此的方向始终为
,故可以用
来表示,因此我们可以得到:
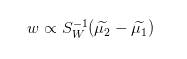
由于对w扩大缩小任何倍不影响结果,因此我们可得:
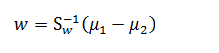
我们只需要求出原始样本的均值和方差就可以求出最佳的方向w,这就是Fisher于1936年提出的线性判别分析。
LDA完全体——对于多类多维:
之前讨论的是问题的简化版,我们把问题定义在了2类,同时降维后维度为1的情况,但是当遇到类别为多类的时候,维度为1已经不能满足要求了。现在我们把问题拓展为:
我们有C个类别,需要将特征降维到K维。
那么投影矩阵W自然就是 ,之前的
也依然成立。
同样的我们需要找到和之前一样的一个优化目标J(w)来衡量,考虑之前的目标,通过投影后的类内散度矩阵和类间的散度矩阵来定义,我们发现对于多类 的情况,类内散度矩阵依然存在。并且定义和之前一样基本保持不变,即Sw为:
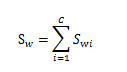
其中:
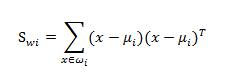
但是类间散度矩阵已经无法按照之前的定义来求,我们考虑下图:
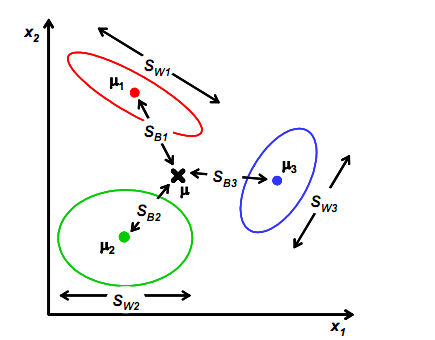
我们可以定义全局散度矩阵St,即 表示全局的散度,其中n表示数据集中所有的点
表示所有数据点的均值向量。
我们可以不是一般性的认为:全局散度矩阵=类内散度矩阵+类间散度矩阵
因此 ,有此可以得到:
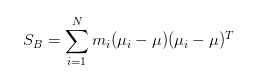
从这个式子我们可以看出,其物理意义就是定义了每个类别到全局中心的距离,我们要让类间分离的足够开,就需要让每个类别的样本再投影后,距离全局中心足够远。
显然,LDA可以有多种实现方法, 三者中任意两个都可以构建出优化目标。和之前保持一致,我们选择
,我们定义出了投影后的
和
:
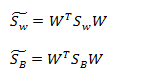
一种常见的的优化目标为:
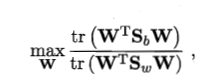
上式可以通过如下广义特征值问题求解:
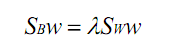
因此W的闭式解(closed-form)就是 的K个最大的广义特征值的特征向量组成的矩阵。将W看成一个投影矩阵,那么实际上就是将原来的特征空间投影到了K维空间中,可以缩小样本点的维度,而且利用了类别信息,是一种经典的有监督降维方法。

注意:由于 矩阵中的
的秩为1,因此SB的秩最多为N,即类别数目(矩阵的秩小于等于各个相加矩阵的秩的和)。又由于
和N个
不是线性无关的,
和前N-1个
可以表示出第N个
,或者说
可以通过
的线性组合表示出来,因此
的秩最多为N-1,那么K也最大为N-1,即特征向量最多有N-1个。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号