【Java使用手册】-02 Byte Streams与java.io.FileNotFoundException
本文包含两部分内容:
-
Oracle官网Java教程-Byte Streams 和译文(译文属于个人理解);
-
实践中遇到的问题:
2.1. java.io.FileNotFoundException: xxx.txt (系统找不到指定的文件)问题的原因与解决方法。
2.2. File was loaded in the wrong encoding: 'UFT-8',及文件乱码的原因与解决方法。
正文:
part1. 教程及翻译
Byte Streams
Programs use byte streams to perform input and output of 8-bit bytes. All byte stream classes are descended from
InputStreamandOutputStream.There are many byte stream classes. To demonstrate how byte streams work, we'll focus on the file I/O byte streams,
FileInputStreamandFileOutputStream. Other kinds of byte streams are used in much the same way; they differ mainly in the way they are constructed.
译:程序使用字节流来进行8位字节的输入和输出。所有字节流的类都是从
InputStream和OutputStream派生出来的。有很多字节流的类。为了演示字节流是如何工作的,我们将重点讨论文件 I/O 字节流
FileInputStream和FileOutputStream。其他类型的字节流的使用方式大致相同;他们的区别主要在于他们的构造方式。
Using Byte Streams
We'll explore
FileInputStreamandFileOutputStreamby examining an example program namedCopyBytes, which uses byte streams to copyxanadu.txt, one byte at a time.
译:使用字节流
我们将通过查看一个名为
CopyBytes的示例程序来研究FileInputStream和FileOutputStream,该程序使用字节流来复制xanadu.txt,一次一个字节。
import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; public class CopyBytes { public static void main(String[] args) throws IOException { FileInputStream in = null; FileOutputStream out = null; try { in = new FileInputStream("xanadu.txt"); out = new FileOutputStream("outagain.txt"); int c; while ((c = in.read()) != -1) { out.write(c); } } finally { if (in != null) { in.close(); } if (out != null) { out.close(); } } } }
CopyBytesspends most of its time in a simple loop that reads the input stream and writes the output stream, one byte at a time, as shown in the following figure.
译:
CopyBytes花费大多数时间在一个简单循环里,读取输入流和写入输出流,一次一个字节,如下图所示。
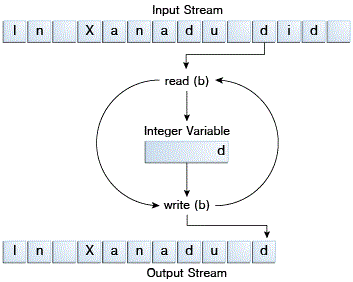
Always Close Streams
Closing a stream when it's no longer needed is very important — so important that
CopyBytesuses afinallyblock to guarantee that both streams will be closed even if an error occurs. This practice helps avoid serious resource leaks.One possible error is that
CopyByteswas unable to open one or both files. When that happens, the stream variable corresponding to the file never changes from its initialnullvalue. That's whyCopyBytesmakes sure that each stream variable contains an object reference before invokingclose.
译:总是要关闭流
关闭不再需要的流是非常重要的——因此
CoptBytes使用finally块来保证即使出现错误,两个流也会被关闭。这种做法有助于避免严重的资源泄露。一个可能的错误是
CopyBytes无法打开一个或两个文件。当这种情况发生时,与文件对应的流变量永远不会改变其初始null值。这就是为什么CopyBytes确保每个流变量在调用close方法之前都包含一个对象引用。
When Not to Use Byte Streams
CopyBytesseems like a normal program, but it actually represents a kind of low-level I/O that you should avoid. Sincexanadu.txtcontains character data, the best approach is to use character streams, as discussed in the next section. There are also streams for more complicated data types. Byte streams should only be used for the most primitive I/O.So why talk about byte streams? Because all other stream types are built on byte streams.
译:何时不适用字节流
CopyBytes看起来像一个普通的程序,但它实际上代表了一种你应该避免的低级 I/O。一旦xanadu.txt包含了字符数据,最好的方法是使用下一节要讨论的字符流,还有很多用于更复杂数据类型的流。字节流应该只被用于最基本的 I/O。所以为什么讨论字节流?因为所有其他流类型都基于字节流。
part2.
2.1 java.io.FileNotFoundException: xxx.txt (系统找不到指定的文件)问题的解决办法
写读取文件功能的时候,报了如下错误:
Exception in thread "main" java.io.FileNotFoundException: xanadu.txt (系统找不到指定的文件。)
at java.io.FileInputStream.open0(Native Method)
at java.io.FileInputStream.open(FileInputStream.java:195)
at java.io.FileInputStream.<init>(FileInputStream.java:138)
at java.io.FileInputStream.<init>(FileInputStream.java:93)
at com.timewhite.basicIO.IOStrams.CopyBytes.main(CopyBytes.java:14)
原始代码如下:
package com.timewhite.basicIO.IOStrams;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class CopyBytes {
public static void main(String[] args) throws IOException {
FileInputStream instream = null;
FileOutputStream outstream = null;
try{
instream = new FileInputStream("xanadu.txt");
outstream = new FileOutputStream("outagain.txt");
int c;
while ((c = instream.read()) != -1){
outstream.write(c);
}
}finally {
if (instream != null) {
instream.close();
}
if (outstream != null) {
outstream.close();
}
}
}
}
并且在上层目录有 xanadu.txt 文件,然后将文件拉到当前目录一样报错,后来去查api,结果如下:
Constructor Summary
Constructor and Description FileInputStream(File file)Creates aFileInputStreamby opening a connection to an actual file, the file named by theFileobjectfilein the file system.FileInputStream(FileDescriptor fdObj)Creates aFileInputStreamby using the file descriptorfdObj, which represents an existing connection to an actual file in the file system.FileInputStream(String name)Creates aFileInputStreamby opening a connection to an actual file, the file named by the path namenamein the file system.
译:构造方法摘要:
FileInputStream(File file):通过打开一个到实际文件的连接来创建一个
FileInputStream,该文件通过文件系统中File类型的对象file指定。
FileInputStream(FileDescriptor fdObj):通过使用文件描述符
fdObj来创建一个FileInputStream, 文件描述符表示文件系统中到一个实际文件现有的连接。
FileInputStream(String name):通过打开一个到实际文件的连接来创建一个
FileInputStream,该文件通过文件系统中的路径名指定。
结论:问题是由于Java平台没有找到文件系统(如windows)的文件造成的,程序里两个文件改成绝对路径地址就可以了。
instream = new FileInputStream("D:\\WorkSpace\\xanadu.txt");
outstream = new FileOutputStream("D:\\WorkSpace\\outagain.txt");
2.2 File was loaded in the wrong encoding: 'UFT-8',及文件乱码的原因与解决方法。
先说原因和结论:windows记事本的编码格式造成的上述问题。解决方式是使用如notepad 等文本编辑器,设置编码为"UTF-8"。

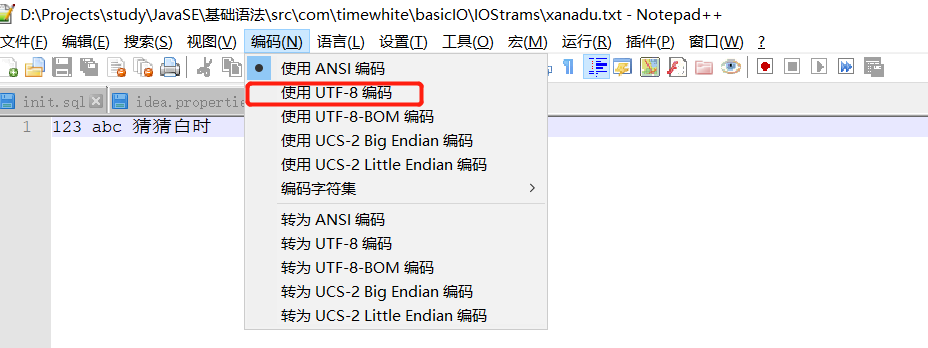
分析:Windows 记事本的 ANSI、Unicode、UTF-8 这三种编码模式有什么区别?
分析链接文章摘要:
如果是为了跨平台兼容性,只需要知道,在 Windows 记事本的语境中:
- 所谓的「ANSI」指的是对应当前系统 locale 的遗留(legacy)编码。[1]
- 所谓的「Unicode」指的是带有 BOM 的小端序 UTF-16。[2]
- 所谓的「UTF-8」指的是带 BOM 的 UTF-8。[3]
GBK 等遗留编码最麻烦,所以除非你知道自己在干什么否则不要再用了。
UTF-16 理论上其实很好,字节序也标明了,但 UTF-16 毕竟不常用。
UTF-8 本来是兼容性最好的编码但 Windows 偏要加 BOM 于是经常出问题。所以,跨平台兼容性最好的其实就是不用记事本。
建议用 Notepad++ 等正常的专业文本编辑器保存为不带 BOM 的 UTF-8。另外,如果文本中所有字符都在 ASCII 范围内,那么其实,记事本保存的所谓的「ANSI」文件,和 ASCII 或无 BOM 的 UTF-8 是一样的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号