2. Synchronization
本篇讲述同步问题。
互斥访问
#include <iostream>
__device__ int cnt1 = 0, cnt2 = 0; // GPU上的全局变量
__global__ void kernal(int type) {
if (type == 0) {
printf("int parameter <<<2, 1>>>, grid.shape=(2,), block.shape(1,)\tcnt1=%d\n", ++cnt1);
}
else {
printf("dim3 parameter <<<dim3(2, 2), dim3(3, 3)>>>, grid.shape=(2, 2),"
"block.shape=(3, 3)\tcnt2=%d\n", ++cnt2);
}
}
/*
__global__ void kernal(int type, int& cnt, const char* str) {
printf("%s\tcnt%d=%d\n", str, type + 1, ++cnt);
}
*/
int main() {
kernal<<<2, 1>>>(0);
dim3 gridshape(2, 2);
dim3 blockshape(3, 3);
kernal<<<gridshape, blockshape>>>(1);
cudaDeviceSynchronize();
return 0;
}
再看该代码,cnt1和cnt2原本想用于计数kernal执行了多少次,但执行代码后会发现严重不符预期。这就是没有互斥访问资源导致的结果。
CUDA提供了十分方便的互斥访问API:
| API | 说明 |
|---|---|
| atomicAdd(&address, val); | 原子性地执行 address += val 操作 |
| atomicSub(&address, val); | 原子性地执行 address -= val 操作 |
| atomicExch(&address, val); | 原子性地将 address 的值替换为 val |
| atomicCAS(&address, cmp, val); | 原子性地比较 address 与 cmp 的值,如果相等,则将 address 的值更新为 val |
修改后的代码:
#include <iostream>
__device__ int cnt1 = 1, cnt2 = 1; // GPU上的全局变量
__global__ void kernal(int type) {
if (type == 0) {
printf("int parameter <<<2, 1>>>, grid.shape=(2,), block.shape(1,)\tcnt1=%d\n", atomicAdd(&cnt1, 1));
}
else {
printf("dim3 parameter <<<dim3(2, 2), dim3(3, 3)>>>, grid.shape=(2, 2),"
"block.shape=(3, 3)\tcnt2=%d\n", atomicAdd(&cnt2, 1));
}
}
/*
__global__ void kernal(int type, int& cnt, const char* str) {
printf("%s\tcnt%d=%d\n", str, type + 1, ++cnt);
}
*/
int main() {
kernal<<<2, 1>>>(0);
dim3 gridshape(2, 2);
dim3 blockshape(3, 3);
kernal<<<gridshape, blockshape>>>(1);
cudaDeviceSynchronize();
return 0;
}
使用atomicAdd后可正确执行对cnt1和cnt2的互斥访问。
由于atomicAdd返回的是原本的值,所以改了一下cnt1和cnt2的初始值。
同步
Block内同步
__syncthreads函数用于阻塞Block,等待Block内的所有线程完成。
__share__用于声明共享内粗暴,每个Block内部共享,速度快。
以下程序使用共享内存和线程块同步,实现了每个线程生成一个随机数,并计算同Block的线程生成的随机数之和。
#include <iostream>
#define MAX_THREAD_NUM 256
__device__ int rand(long long seed) {
const unsigned long long a = 1664525;
const unsigned long long c = 1013904223;
const unsigned long long m = 1LL << 31;
seed = (a * seed + c) % m;
return seed;
}
__global__ void kernal() {
__shared__ int data[MAX_THREAD_NUM];
data[threadIdx.x] = rand(threadIdx.x * 114 + blockIdx.x * blockDim.x + 514) % 100 + 1;
__syncthreads(); // 等待其他线程完成数据加载
if (threadIdx.x == 0) {
// 用一个线程完成求和
int sum = 0;
for (int i = 0; i < blockDim.x; ++i) {
sum += data[i];
}
printf("Block%d sum=%d\n", blockIdx.x, sum);
}
}
int main() {
kernal<<<3, 128>>>();
cudaDeviceSynchronize();
return 0;
}
设备同步
我们一直在使用的cudaDeviceSynchronize函数就是设备同步API。主机端调用该函数后,阻塞主机端直至GPU上所有任务执行完毕。
下面的程序实现了矩阵相加,其中Init1和Init2函数用于初始化矩阵,Add执行相加任务,print打印矩阵。显然这里每一个任务都要等待上一个任务完成才可以继续。
#include <iostream>
#include <cuda_runtime.h>
__global__ void init1(int** A, int** B, int* A2, int* B2, int row, int col) {
A[0] = A2;
B[0] = B2;
for (int i = 1; i < row; ++i) {
A[i] = A[i - 1] + col;
B[i] = B[i - 1] + col;
}
}
__global__ void init2(int** A, int** B, int row, int col) {
int x = (blockIdx.y * blockDim.y) / row * col / 2 +
blockIdx.x * blockDim.x + threadIdx.x;
// (blockIdx.y * blockDim.y) / row 和 (blockIdx.y * blockDim.y + threadIdx.y) / row 是一样的
int y = (blockIdx.y * blockDim.y + threadIdx.y) % row;
if (y < row && x < col) {
A[y][x] = x * col + y;
B[y][x] = row * col - x * col - y - 1;
}
}
__global__ void add(int** A, int** B, int row, int col) {
int x = (blockIdx.y * blockDim.y) / row * col / 2 +
blockIdx.x * blockDim.x + threadIdx.x;
int y = (blockIdx.y * blockDim.y + threadIdx.y) % row;
if (y < row && x < col) {
A[y][x] += B[y][x];
}
}
__global__ void print(int** arr, int row, int col) {
for (int x = 0; x < row; ++x) {
for (int y = 0; y < col; ++y) {
printf("%d ", arr[x][y]);
}
printf("\n");
}
}
int main() {
int **A, **B, *A2, *B2;
int row = 16, col = 16;
dim3 grid(4, 8);
dim3 block(2, 4);
cudaMalloc((void**)&A, sizeof(int*) * row);
cudaMalloc((void**)&B, sizeof(int*) * row);
cudaMalloc(&A2, sizeof(int) * row * col);
cudaMalloc(&B2, sizeof(int) * row * col);
init1<<<1, 1>>>(A, B, A2, B2, row, col);
cudaDeviceSynchronize();
init2<<<grid, block>>>(A, B, row, col);
cudaDeviceSynchronize();
add<<<grid, block>>>(A, B, row, col);
cudaDeviceSynchronize();
print<<<1, 1>>>(A, row, col);
cudaDeviceSynchronize();
cudaFree(A);
cudaFree(B);
cudaFree(A2);
cudaFree(B2);
return 0;
}
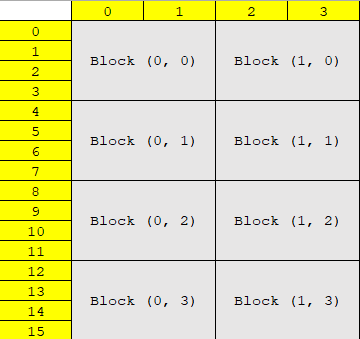
思考题:
- 该程序是怎样为二维数组分配内存的?为什么要使用A2、B2,能不能直接
cudaMalloc(&A[0], sizeof(int) * row * col)?(提示:CUDA Runtime API只能在主机端调用) - 该程序中,线程与矩阵元素的映射关系是怎样的?在这种映射方式下,代码第14行中的
col / 2是怎么得来的?
提示:
流同步
CUDA流表示GPU的操作队列。默认GPU上的操作属于NULL流(默认流),可以用cudaError_t cudaStreamCreate(cudaStream_t* pStream)创建CUDA流。要使用CUDA流,我们增加核函数调用的参数。
具体来说,调用核函数时的语法为func<<<X, Y, M, S>>>(),其中M是共享内存的大小,不用的话设置为0即可,而S就是CUDA流。
在主机端调用cudaError_t cudaStreamSynchronize(cudaStream_t stream)即可阻塞指定stream,实现同步。
#include <iostream>
#include <cuda_runtime.h>
__device__ int arr[] = {1, 2, 3};
__global__ void ADD() {
extern __shared__ int sum;
atomicAdd(&sum, ++arr[threadIdx.x]);
__syncthreads();
if (threadIdx.x == 0) {
printf("sum = %d\n", sum);
}
}
__global__ void print() {
printf("arr[%d] = %d\n", threadIdx.x, arr[threadIdx.x]);
}
int main() {
cudaStream_t addStream; // 把arr元素全部加上1 并加入到共享内存sum中 由一个线程输出sum
cudaStream_t printStream; // 把arr元素打印出来
cudaStreamCreate(&addStream);
cudaStreamCreate(&printStream);
int grid = 1, block = 3;
ADD<<<grid, block, sizeof(int), addStream>>>();
cudaStreamSynchronize(addStream); // 等待add任务完成
// cudaDeviceSynchronize() 会阻塞所有GPU任务 注意区分
print<<<grid, block, 0, printStream>>>();
cudaStreamSynchronize(printStream);
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号