BUAA-OO-2019 第一单元总结
第一次作业
第一次作业需要完成的任务为简单多项式导函数的求解。
思路
因为仅仅是简单多项式的求导,所以求导本身没有什么可说的,直接套用幂函数的求导公式就行了,主要的精力是花在了正则表达式上。这里推荐两个网站:
https://github.com/ziishaned/learn-regex
前者可以用来学习正则表达式的语法,后者则提供实时的正则表达式匹配,方便进行调试和验证。尤其是后者,能大幅提高编写正则表达式的效率和正确性,省去了每次都得在IDEA里运行一遍的麻烦。
用正则时有一点需要注意,那就是大正则是不可取的。我一开始就是企图用一大串正则匹配整个输入,结果当时是爆栈了。合理的做法应当是每次只find()一个Term,以及通过Term与Term之间的连接关系判断合法性。
在数据结构方面,我一开始用的是ArrayList,但在后来优化的时候发现合并非常麻烦,于是果断放弃,学习并采用了HashMap。通过将指数作为Key,可以快速地找到指数相同的项,以实现合并同类项的目的。
程序结构分析
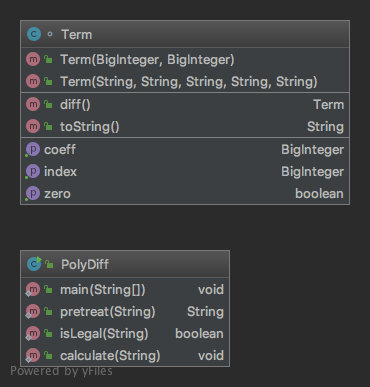
由于刚接触Java语言,也不太懂什么是面向对象思想,所以程序整体来说还是比较C type的。也可能是由于本次作业比较简单,所以也并没有用到继承、接口之类的东西。从类图中可以看到,一共也就两个类,其中PolyDiff完成主函数、预处理、合法性判断等任务,而Term则实例化出多项式中的每一项,保存系数和指数,并提供diff()求导方法。
度量分析
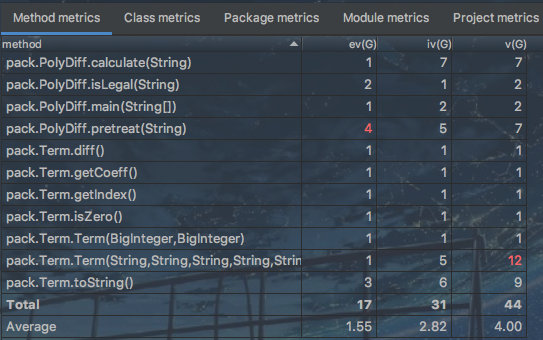
可以看出个别方法复杂度过高,这很不OO。下次应当多注意抽象以及代码重用,避免一个方法或者类的过于臃肿。
关于BUG
公测未被查出bug。在互测阶段,我第一个发现的bug是自己的bug,其原因在于,我判断合法性的做法是将匹配了的每一项用"#"替换掉,最后看除了" "、" \t"、"#"之外是否没有其他的字符。然而,我忽略了输入一开始就含有"#"的可能,但这种可能性非常小,以至于我认为只要不仔细阅读我的代码,基本上是不可能歪打正着的。遗憾的是,最终还是有一位十分认真的同学,(我猜)在一行一行通读了我的整个代码后,居然还真的发现了这个bug……我是服气的,真的太强了orz
至于我查别人的bug,都是用的我写作业时自测发现了bug的样例,因为我相信这样的样例会具有一定的杀伤力和普适性。事实证明,我的确能用这种方法测出很多别人的bug,于是也就没有再结合他人的代码设计结构来设计更多的测试样例。
第二次作业
第二次作业需要完成的任务为包含简单幂函数和简单正余弦函数的导函数的求解。
思路
第二次作业新引入了正余弦函数,乍看复杂了许多,但其实还是可以用套公式的办法死做,然而代价就是毫无扩展性可言。
对于每一项及其导函数,都可以化为幂函数和正余弦函数的幂次的乘积这种标准形式,那么Term就相应拥有了系数、幂函数及正余弦函数的指数这四个属性。除了正则表达式匹配和求导规则有一些变化,其余与第一次作业并无太大区别。
值得注意的是,这次HashMap的Key我采用的是将幂函数及正余弦函数的指数拼接成一个字符串,并在相邻指数之间用"|"分隔。如此一来,便可省去重写equals()和hashcode()的麻烦,然后像第一次作业一样合并同类项。
程序结构分析
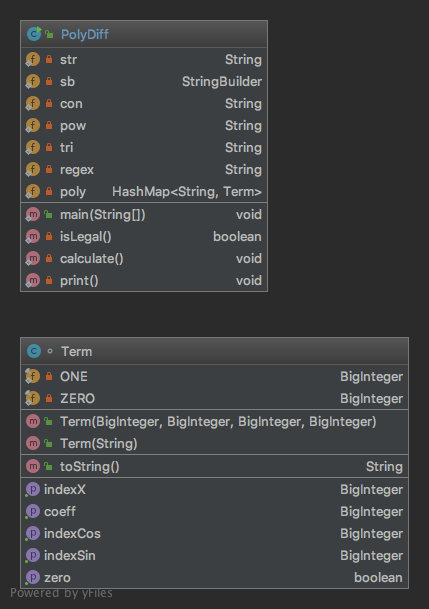
程序结构大体类似于第一次作业。
度量分析
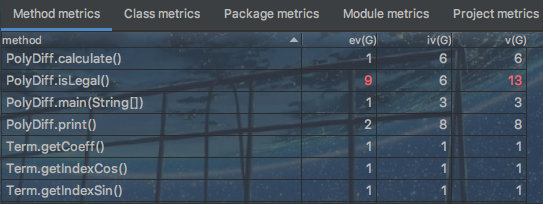
合法性判断的方法还是有些冗长了,可能是因为其中包含了一些对输入进行预处理的操作,可以考虑将这部分单独抽离出来。
关于BUG
在吸取了上一次作业的教训后,我舍弃了替换捕获组方法,而是根据本次匹配起点是否为上一次匹配的终点,以及最后一次匹配的终点是否为字符串的末尾,来判断输入的合法性。最终在公测和互测中都未发现bug。
发现别人程序的bug依然采用上一次作业的方法,果然又查出了不少bug,大多是对于非法的输入没有输出WRONG FORMAT!
第三次作业
第三次作业需要完成的任务为包含简单幂函数和简单正余弦函数的导函数的求解(支持因子嵌套在三角函数因子中)。
思路
正如之前所说的,套公式的做法是无法解决任意层嵌套的问题的,因此整个程序架构必须重构。在这里我采用的是递归下降的方法,规定好每种函数、组合的求导法则,将嵌套的内容看做一个整体,留给下一层递归处理,每次只判断当前层的合法性并进行相应的求导。
在优化方面,仅仅是剔除了冗余的0、1、括号、正负号等等,在同类项合并和恒等变换方面未能进行更多的处理,其原因和求导方法的返回值有关。由于我在一开始设计的时候就直接把每个因子的求导结果当作字符串保存,所以整个表达式求导的过程就相当于是字符串按一定规则转化和拼接的过程。这样做的好处在于简答、直观、不易出错,但弊端也很明显,那就是很难做进一步优化,因为对字符串中的内容是无法进行插入、删除、替换、排序或合并等操作的,除非像读取输入那样再一次对字符串进行分析。由于时间有限,我没有那样做。其实更好的方法是将求导的结果也作为某一个类的实例,方便对其做进一步的处理。
程序结构分析
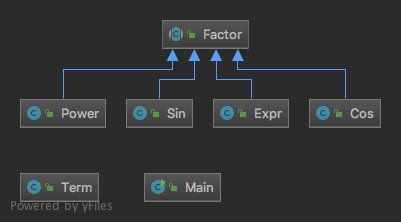
如图所示,本次作业我用到了面向对象中的继承,有必要这样做的原因有三:
- 每个子类都需要toString()方法,以返回该项因子自身的字符串。由于这个方法对于每种因子都一样,所以应该在父类中统一实现。
- 每个子类都需要实现各自的diff()方法,因为每种函数或组合都有自己的求导规则。
- 每个子类都继承于Factor类使得不同类型的因子可以放在一个ArrayList中一起处理。
至于Term,它并不是因子,只是Expr的组成部分,所以单独成为一类。
通过继承这种面向对象的思维方式,我们程序的结构更加清晰,功能更加强大,最重要的是,拥有了可扩展性。
度量分析
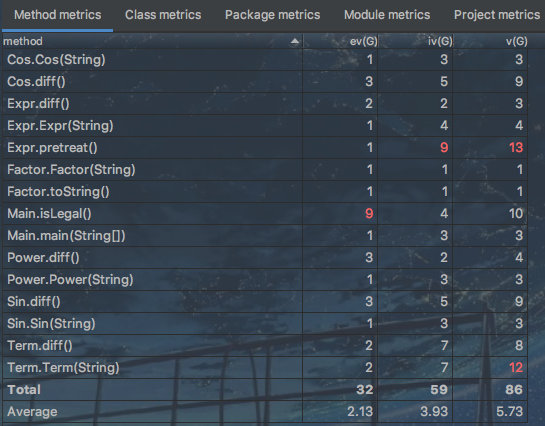
果然越复杂的程序,要做到均衡控制每个方法的复杂度就越难。主要的问题依然出在输入分析、预处理以及合法性判断上,尽管这次我将他们分离了开来。至于有没有必要以及如何进一步拆解,还有待研究。
关于BUG
本次作业依然没有被查出任何bug。
在查别人的bug方面,为了解放劳动力,这次我选择写脚本进行批量测试。我用到了Python中一个强大的第三方包——SymPy,可以进行复杂表达式的求导运算以及判断两式是否等价,这也是我的"简化版评测机"的主要原理,即将Java程序的输出与SymPy的输出进行比对。显然,该评测机无法对非法输入给出评判。而测试用例本身依然是我自测时手动构造的测试集,按行读取便可进行批量测试,威力极大,效率奇高。
总结与建议
第一单元总体还是比较入门的,重点在于熟悉Java语法特性、建立面向对象思维,为日后的多线程编程打好基础。
对于我个人而已,学习了Java正则表达式、BigInteger类、HashMap、重写与重载、继承与接口等等技术,并且慢慢开始理解了层次化架构和面向对象技术的优越性。总体感觉Java还是比C/C++要方便的多,基本上只要是你能想到的功能,总有类或者第三方包能为你提供解决方案。而这就需要我们有查找资料自学的能力,无论是看技术博客还是阅读官方文档,再加上自己多动手实践,相信很快就能掌握一项新的技术,并在作业中发挥其功能。
此外,通过Checkstyle对代码风格进行规范也是比较有效的措施,基本上不会再写出会令人抓狂的代码了。但是其中每行最多80个字符的限制我实在觉得不太合理,尤其是涉及正则表达式的时候,往往是硬生生地把一句逻辑连贯的代码拆成多行。个人认为在阅读代码时,莫名其妙的换行比一行稍长的代码体验更糟。建议将每行的字符数上限改为100~120。
对于面向对象的理解可能还是只是停留在表层,甚至会有一些误解,这就需要进一步的学习和练习,在一次次实践中总结经验与教训。希望以后能写出更加OO的程序。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号