

最近接到一个需求:公众号访问的链接太长了导致码点比较密集,做成二维码再嵌入到其他图片里面后,微信不能识别出链接。解决方案是做一个短链接,通过该链接服务端跳转到长链接去。功能很简单直接sendRedirect就完事了,理想很丰满现实很骨感,功能测试直接爆炸。内容受个人能力所限,如有错误,欢迎大家指正。
问题还原
问题:当访问“http://192.168.16.11:8282/Service/qr/8”时,希望跳转到“https://cn.bing.com/search?q=test,唯一#wechat_redirect”能正常访问,结果浏览器抛出错误码ERR_INVALID_HTTP_RESPONSE。
一般看到链接出现中文的时候,我们会猜测是中文编码的问题。老码农一猜即中,但是为什么不跳转出现乱码链接而是浏览器直接返回错误码呢?
问题追踪
首先,出现这种情况,我一般会通过Wireshark抓包看下HTTP协议内容,方便我们排查问题。

可以看到Location字段是这样的Location: https://cn.bing.com/search?q=test,/\000#wechat_redirect,明显这是一个不正常的链接。为什么会出现这个问题呢?
然后,我们从代码层面看下,服务器是怎么转换输出Location字段的。
项目是使用springboot开发的,http服务器配置了Undertow,Undertow使用Xnio做网络层框架。数据流转大致是这样的:
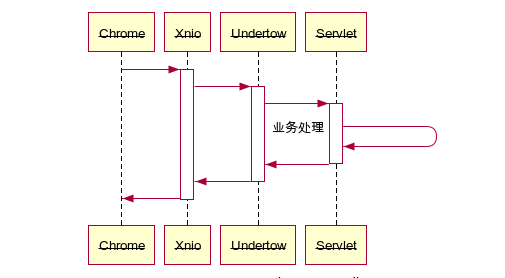
然后一层层翻阅代码后,最终找到Undertow HttpResponseConduit中输出Response Header是这样的:
private int processWrite(int state, final Object userData, int pos, int length) throws IOException {
...
HeaderMap headers = exchange.getResponseHeaders();
long fiCookie = headers.fastIterateNonEmpty();
while (fiCookie != -1) {
HeaderValues headerValues = headers.fiCurrent(fiCookie);
HttpString header = headerValues.getHeaderName();
int headerSize = header.length();
int valueIdx = 0;
while (valueIdx < headerValues.size()) {
...
writeString(buffer, string);
buffer.put((byte) '\r').put((byte) '\n');
}
...
}
buffer.put((byte) '\r').put((byte) '\n');
...
}
private static void writeString(ByteBuffer buffer, String string) {
int length = string.length();
for (int charIndex = 0; charIndex < length; charIndex++) {
//获取单个字符
char c = string.charAt(charIndex);
//强制转换为byte
byte b = (byte) c;
if(b != '\r' && b != '\n') {
buffer.put(b);
} else {
buffer.put((byte) ' ');
}
}
}
由此可以看出,响应头会被切成字符,再强制转换为byte输出。而"唯一"的unicode分别是0x552F,0x4e00。强制转换成一个字节后变成0x2F、0x00,对应的字符为/和NUL。猜想当Location中出现NUL字符chrome会解析出错。
我们设置Location下验证猜想,像这样response.sendRedirect("https://cn.bing.com/search?q=test,\0#wechat_redirect");,chrome直接报ERR_INVALID_HTTP_RESPONSE。
所以,Undertow输出响应头时将中文参数转换成单字节,这个过程中会将多字节字符的unicode去除高位转为单字节,这时候就会出现空字符(0x00)情况。当Location字段中带有空字符(NUL)时,chrome解析会报错ERR_INVALID_HTTP_RESPONSE。
解决方案
- Location字段中不使用多字节的字符,不能有空字符(0x00)。
- 将参数Base64之后再解析。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号