
Generally capable agents emerge from open-ended play
Abstract
人工智能体在具有挑战性的模拟环境中已经取得了巨大的成功,不仅可以掌握训练的特定任务,其行为甚至可以推广到训练中从未遇到的地图和对手。在这项工作中,我们的智能体可以很好地完成除了单个任务之外的任务,并表现出更强的泛化能力,以应对更加巨大丰富的挑战空间。该环境原生支持多智能体,涵盖竞争、合作和单独运行的游戏,所有游戏都在程序生成的3D物理环境中实现。由此产生的空间对于智能体的挑战是丰富多样的,因此,衡量智能体的学习过程成为了一个开放性问题。我们提出了一种在代际智能体之间迭代优化的理念,而不是寻求最大化单一目标,这允许我们定量衡量优化,尽管达到的奖励不能直接用来比较。在这样一个大的任务空间里训练智能体是主要挑战,我们发现基于一个固定任务分布的纯粹强化学习无法成功。我们展示了通过构建一个开放式的学习过程,也就是动态调整训练任务的分布和训练的目标从而让智能体永久学习下去,就能持续学习到新的行为。由此产生的智能体可以在每一个人类可解决的评估等级中获得奖励,并泛化到所有任务中的其他学习点。这种对从未见到的任务的泛化性的例子如在Hide and Seek、Capture the Flag和Tag上的良好表现。通过分析和手动编写的测试任务,我们分析了智能体的行为,发现了有趣的新的启发式的行为,如尝试试验、简单的工具使用、切换选项和合作。最后,我们证明了这种智能体的通用能力可以通过简单的微调实现更大规模的行为泛化。
Introduction
2 XLand Environment Space
为了促进强化学习中泛化能力的出现,我们寻求一种可以展示任务间维度的连续性和变化的平滑性的环境。
开发这样一种环境的核心是使其具有平滑一致的广泛性,因此,我们提出了XLand环境。XLand是一个3D环境,由静态拓扑、具备刚体物理特性的物体、具备第一人称视角和自我中心运动(类似于DM-Lab和QuakeIII:Arena )的多玩家(由玩家或智能体控制)组成。玩家可以自由使用不同的小工具来影响环境,也可以携带或者举起动态物体,并在每一时间点可以根据环境状态得到相应奖励,包括玩家、物体、拓扑结构之间的关系。环境使用 Ward et al.(2020)的Unity框架开发和模拟,如图2所示。
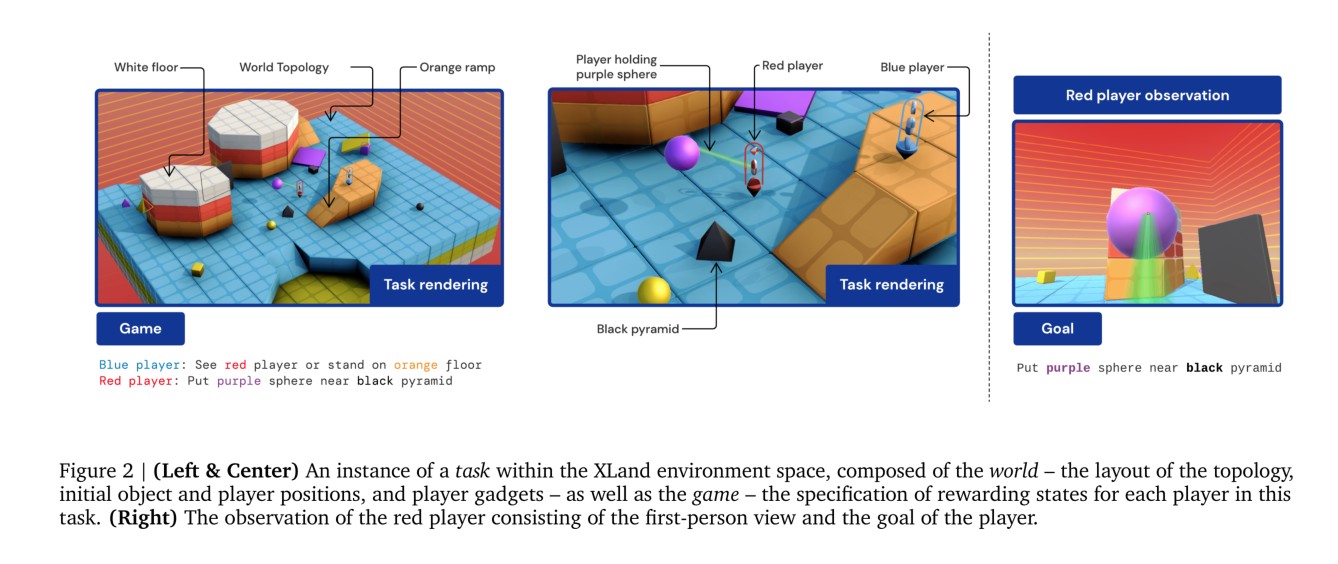
环境的一致性来自于:玩家有一致的控制接口、观测空间、工具动力学、移动动力学;仿真物体有相似的物理特性;及有限的拓扑构建块。然而,环境的其他属性是很大但变化平滑的变量:拓扑构建块的布局和结构、物体的位置、光照条件、尤其是每个玩家奖励状态的设置。最后,从单一玩家的角度看,其他玩家的策略变化很大但很平滑。
从特定玩家(如一个智能体)来看,XLand的任务空间,标记为\(\mathcal{X}\),是所有可能的World \(w\in\mathcal{W}\), game \(G\in\mathfrak{G}\)(定义为n个玩家中每个玩家的一个目标 \(g\in\mathcal{G}\))和剩余n-1个玩家(除当前玩家外的其他玩家)的策略 \(\pi \in \Pi\)的笛卡尔积。如公式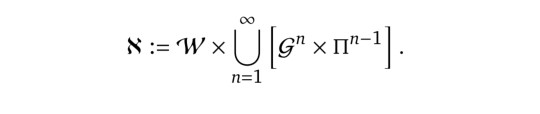
在这个定义下,每个XLand任务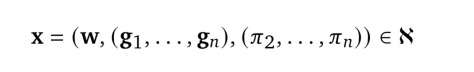
可以看做一个仿真状态空间\(\mathcal{S}\)下的POMDP。为了简化符号表示我们通常用\(\pi\)或\(\pi_1\)表示目标玩家的策略。在每个时间点t,每个玩家\(\pi_i\)得到以其自身为中心的观测\(O_{t}^{i} :=(f_{i}(s_{t}), g_{i})\),\(f_{i}\)用来解析一个从玩家\(i\)观测到的世界状态的角度基于像素的渲染画面,同时提供一些初始信息(如玩家是否拿了什么东西)。值得注意的是,环境的奖励不包括在玩家的观测中。基于这些观测,每个玩家的一个动作\(a_{t}^{i}\)是从其相关的策略\(a_{t}^{i} \sim \pi_{i}(h_{t}^{i})\)采样得到的,其中\(h_{t}^{i}=(o_{1}^{i}, ..., o_{t}^{i})\)是到时间t的观测序列。仿真的初始状态由\(\mathbb{w}\)唯一决定。仿真在固定时常\(T=900(两分半钟)\)后终止。转移状态方程来自于仿真的物理引擎,该引擎从当前状态\(s_{t}\)中所有玩家参与到特定任务的同步动作\((a_{t}^{i})_{i=1}^{n}\)计算新的状态\(s_{t+1}\),和其他多智能体实时环境类似。从一个单独的玩家角度看(如一个学习的智能体),其他所有的玩家的动作都可以看做转移状态方程的一部分。奖励方程\(r_{t}:\mathcal{S}\rightarrow\{0,1\}\)当且仅当一个玩家的目标实现时返回1。因此,对于一个给定的任务,一个玩家的目标是最大化预期的奖励的期望,表示为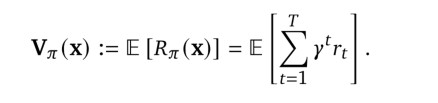
现在,我们将更详细地描述XLand环境的构成,将物理环境空间(世界)的初始条件从每个玩家(游戏)的奖励状态规范中分离出来。我们将重点介绍XLand的这些组件的广度和平滑度,以及这些组件如何组合和交互以形成一个庞大而复杂的任务空间,如图3。
2.1 World Space
世界定义了游戏的初始状态,包括Topology,Objects,Players三部分。
XLand中的任务嵌入到三维物理模拟世界中,如图2所示。拓扑布局、对象的初始位置、玩家的初始位置以及每个玩家可以使用的小工具对于任务中有能力的玩家的行为至关重要。例如,考虑由单个玩家组成的简单游戏,玩家在靠近紫色球体时接收奖励。如果玩家最初位于紫色球体旁边,玩家只需站着不动。如果紫色球体最初位于玩家看不见的地方,玩家必须搜索该对象。该拓扑可能会给该搜索带来导航挑战,需要分析连接的路径和记忆以快速找到对象。球体的初始位置与拓扑或其他对象之间的物理交互可能导致球体滚动,要求玩家在找到球体后拦截球体,如果玩家有冻结小工具,这将允许玩家通过冻结球体的运动来停止球体滚动。
模拟世界的初始条件定义了玩家在某种程度上独立于游戏所面临的可能挑战,即玩家的目标。因此,我们将世界\(\mathbb{w}\)定义为模拟3D世界及其组成部分的初始状态,即每集游戏开始时的状态。世界的三个主要组成部分是拓扑、对象和玩家。世界是按程序生成的。
- Topology
Topology定义了基础环境,是一个有四面墙壁包围的可玩区域,在该区域中有不同的地形和物体,而且环境的光照条件可以变化,玩家在其中进行导航和执行任务。Topology是分层构建的,首先构建出一个被四面包围的矩形区域,然后在其中添加各种预设的3D物体,这些物体以一定的物理约束条件放置,以保证玩家可以正常在其中通行。
- Objects
Ojbects定义了玩家在环境中可以操作的物体,如下表所示。
| 形状 | 颜色 | 特性 |
|---|---|---|
| 立方体 球体 棱锥体 平板 |
黑色 紫色 黄色 |
可操纵 物理特性 |
- Player
Players是由agent控制的,用来在环境中执行任务,XLand中,环境最多可以三个玩家存在,最少有一个,每个玩家除了可以在环境中导航移动外,也有特定的技能,如下表所示。
| 种类 | 技能(gadget) |
|---|---|
| 蓝色 红色 绿色 |
freeze gadget: 只能操作物体,将物体冻结5s,使其失去物理特性 tagging gadget:可以操作物体和玩家,使对象在世界中消失3s,在初始位置重生。 |
因此,世界\(\mathbb{w}\)的一个实例是一个特定的拓扑,它与一组具有位置的对象以及一组具有位置和小工具的特定玩家组合在一起。一个在世界\(\mathbb{w}\)中比赛的智能体总是会具有相同的初始条件。
我们生成世界的过程导致了一个广阔而平滑的世界空间,第3.1节将进一步探讨这些属性。关于这个过程的更多细节,请参见A.1.1和Figure 32。
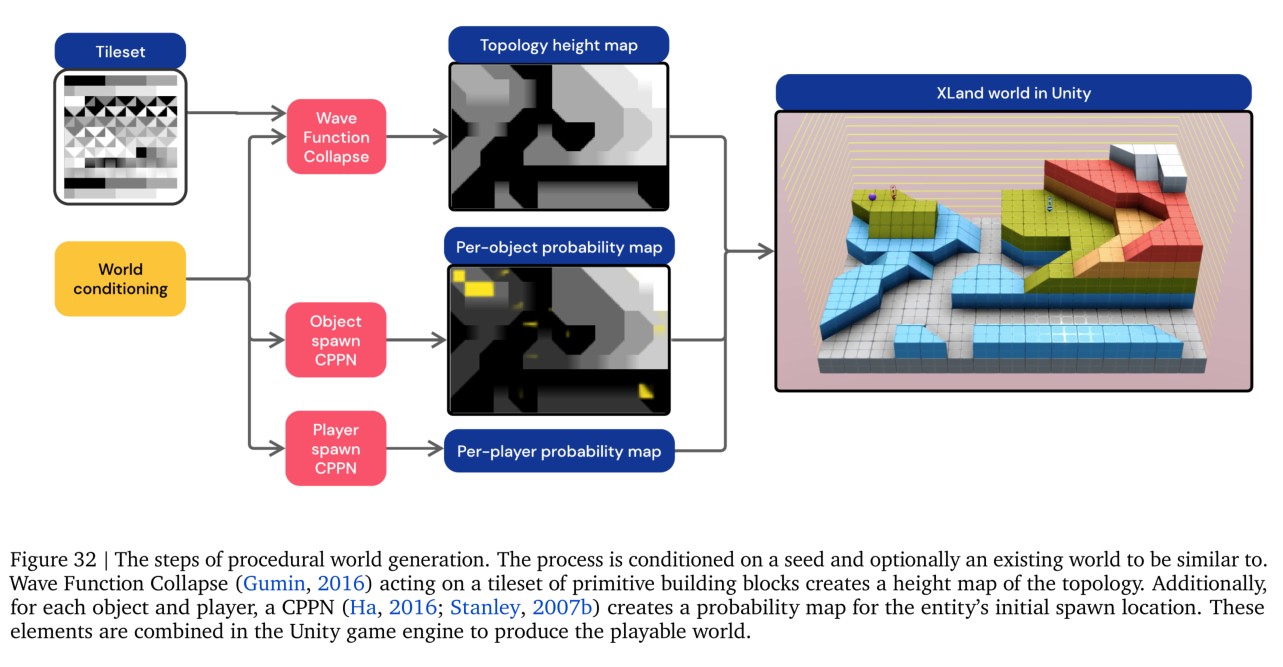
2.2 Game Space
2.3 Task Space
4 Goal and Metric
在第2节中,我们介绍了XLand环境,并在第3节中探讨了该空间的一些特性,如任务之间的广度、多样性和平滑性。我们现在将注意力转向在XLand上训练智能体。在像XLand这样的情景环境中训练智能体\(\pi\),我们要最大化智能体的期望奖励
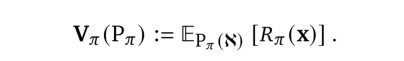
4.1 Normalised Percentiles
我们不去单纯通过期望回报评估智能体,而是考虑其在一个可数的任务空间下的回报分布。
通常这样的任务分布是很高维度的。
而且,由于任务间回报范围很大,我们需要对每个独立任务进行衡量。通常只需要通过正则化做到,但实际中,由于
- 最优策略不是先验的
- 我们希望在整个环境空间中使用这些标准化,这意味着我们需要知道整个空间的单个最佳策略,然后根据每个任务的分数标准化。
两个简化:
首先先针对每个任务独立正则化,然后将它们结合到一个全局正则化器中。
其次,即使通过上述方法也不能在每个任务上达到最优策略,但可以借用多智能体学习的思想让其收敛到纳什均衡。我们迭代地构建一系列智能体来解决特定目标,然后用它们的最佳混合(纳什均衡)作为正则化常数。当智能体在特定任务上的表现提高,会打破这个纳什均衡从而提高正则化常数。这种动态为我们提供了一个多任务环境的迭代改进概念,而不是一个描述过程的固定数值。这与理论结果类似,理论结果表明,在多智能体问题中,不可能有固定的目标,因为找到更好的智能体和提高评估质量是同一个问题。这些标准化器为我们提供了每个任务的标准化分数。
最后,为了缓解高维标准化分数分布的问题,我们根据标准化分数的百分位数来描述分布特征,最多为第50个百分位数(标准化分数中值):
4.2 Evaluation Task Set
对跨越XLand任务较小但具有代表性的子空间的任务进行采样,并进行倾斜采样,以确保对有趣世界和游戏功能的统一覆盖。最后,我们将这些评估世界和游戏与预先训练的评估策略结合起来,为我们提供一个评估任务集。
- Evaluation worlds
- Evaluation games
因此,以析取范式表示游戏的目标,我们限制评估游戏每个目标最多有三个选项,每个选项最多由三个谓词组成,所有目标最多使用六个唯一谓词。评估集中只考虑两人和三人游戏。此外,我们确保游戏的评估集涵盖了竞争力和平衡的范围。我们在竞争-平衡空间中创建离散点,其中一些点对应于这些度量的极值。对评估博弈进行抽样,确保每个竞争-平衡点的博弈数量相等,每个竞争-平衡点在博弈中不同数量的选项和谓词上的博弈数量相等。结果是一个游戏评估集,它在平衡点、竞争力点、选项数量和谓词数量上是均衡的。 - Evaluation co-players
每个评估任务都必须包含充当任务共同参与者的策略,为任务中的某个智能体的评估留出一个参与者的位置。为了这项工作的目的,我们使用了一组预训练的智能体。其中包括始终发出noop动作(对应于不移动)的noop智能体和从整个动作空间均匀采样发出动作的随机智能体。此外,我们使用在评估空间的更简单化身上训练的智能体,以及评估空间的子空间(如只在单谓词游戏上训练的智能体)。这些智能体是在研究项目的早期阶段产生的。
我们将评估世界、游戏和合作玩家结合起来,以获得测试和验证集。我们首先生成评估任务的测试集。接下来,以相同的方式生成评估任务的验证集,但是明确地将所有游戏和世界显示在距离测试集一定距离内(4.3节) 同样地,除了生成的noop和随机策略之外,还保留了所有测试集的参与者。此外,所有手工编写的任务(第4.3节)都是从所有评估任务集中进行的。测试任务集由1678对世界游戏组成,共有11746项任务,共有7名合作玩家参与。验证任务集由2900对世界游戏组成,与越来越多的合作玩家一起玩:noop、random和前一代训练中的额外玩家。
4.3 Hand-authored Task Set
前面描述的任务评估集涵盖了XLand的不同子空间,但是这些任务的自动生成可能会使成功策略的解释变得困难——很难知道单个任务会带来什么挑战。我们创建了一组手工编写的任务,这些任务充当可解释的评估任务。此外,这些手工编写的评估任务中有许多在任务分布外,或者代表了极为罕见的挑战,从评估集的样本中可以看到,从而进一步测试代理的泛化能力。图11给出了手工编写的任务集中42个任务的示例(表7提供了完整的列表),其中包括一些众所周知的任务,如捕获旗帜、隐藏和搜索以及投射到XLand空间中的山中之王。其他示例包括物理挑战,如停止滚动和工具使用。手工编写的任务集也在所有训练中提供。
5 Learning Process
我们现在将注意力转向学习过程。我们希望在XLand中找到具有通用能力的智能体。目标的其中之一是我们希望智能体能在从未见过的测试集上得到泛化能力,并使用测试集上的归一化百分数来作为性能度量。
我们的训练过程包括三个主要部分:
1.用深度强化学习更新单个智能体的神经网络。用深度强化学习优化智能体在一个训练集分布上的性能来最大化回报。
2.使用动态任务生成和PBT(population based training)来为一个种群的智能体提供训练任务的分布。任务分布在整个训练过程中会不断变化,并进行自我优化来提升种群在测试集上的正则化百分数。
3.使用智能体种群的代际训练来链接有不同目标的多个学习过程。在每一代智能体都会有不同的学习目标,次代种群会通过自举的方式提升上代种群的表现,从而使下一代在验证集上的归一化百分数都得到提升。
我们现在更细节地讨论这三个部分。
5.1 Deep Reinforcement Learning
每个在一个XLand任务上游戏的智能体在每一时间步长的时候都会输入高维观测\(o_t\),并产生一个策略,从这个策略中采样动作\(a_{t}\sim \pi_{t}\),使得智能体能够在任务上最大化获得的奖励。我们使用一个神经网络来将这个策略参数化,然后用V-MPO强化学习算法来训练。和原始V-MPO的实现相似,我们使用单任务的PopArt价值函数的正则化。在每一次权重更新的时候,网络参数\(\pi\)可以更新以最大化当前任务上的期望折扣回报\(V_{\pi}(P_{\pi})\)。
神经网络用每一时间步长作为输入的观测\(o_t\)包括从智能体角度看到的一张RGB图\(o_{t}^{RGB}\),智能体玩家抓住物体使用力的本体感觉的数值\(o_{t}^{prio}\),和智能体在任务\(\mathbb{x}\)上的目标\(\mathbb{g}\)。一个循环神经网络处理信息来产生一个预测值\(\mathbb{v}_t\)和策略\(\pi_t\),这个策略用来采样每一个动作\(a_t\)。
Goal attention network 循环神经网络采用了一种结构,该结构是针对给定任务的最优策略值\(V^*\)的结构而定制的。为了简单起见,写作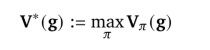
表示当我们保持世界、其他目标和合作者不变时的最优策略的价值。
定理 5.1
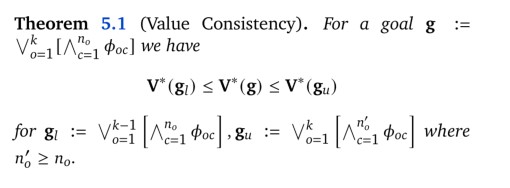
该属性表示,对于每个游戏,我们可以通过选择选项子集或连接超集,轻松构建另一个提供最优值上限或下限的游戏。因此对于\(\mathbb{g}:=\hat{\mathbb{g_1}}\vee ... \vee\hat{\mathbb{g_{n_{0}}}}\),我们有
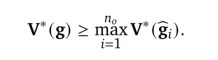
将\(\hat{\mathbb{g_0}}:=\mathbb{g}\)合并,因此得到了
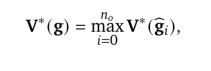
\(\mathbb{g}\)的最优值是包括每个选项\(\hat{\mathbb{g_{i}}}\)和整体目标\(\mathbb{g}\)本身的最大价值。
我们在神经网络结构中显示地编码了这个属性。在每个时间戳,智能体使用其观察的历史记录生成内部隐藏状态编码,但没有目标的任何信息。目标被单独编码并作为一个注意力机制的查询项来产生一个目标-注意力隐藏状态\(\hat{h}_t^{[0]}\)。同时,智能体为每个选项生成类似的编码\(\hat{h}_t^{[i]}\),并估计每个选项的当前价值\(\hat{v}_t^{[i]}\)。这就要求智能体预测如果在本回合结束前专注于选项\(i\),那么其预期回报\(\hat{v}_t^{[i]}\)是多少。通过注意机制,当且仅当所述选项的价值高于其当前对整个目标价值的估计时,智能体才会将其隐藏状态切换到另一个选项的隐藏状态。这样,内部鼓励智能体与游戏空间的值一致性属性保持一致。
更具体地,\(h_t\)是LSTM的隐状态,这个LSTM将处理后的像素和本体观测作为其输入。我们将一个原子谓词状态预测器附加到LSTM的输出:该预测器是一个简单的多任务二元分类器,输出\(p_t\),预测与\(\mathbb{g}\)相关的\(\phi(s_t)\)的维数,并作为辅助分类损失训练(i.e. 仅塑造内部表征,而不明确影响策略)。goal attention(GOAT)模块如下所示:



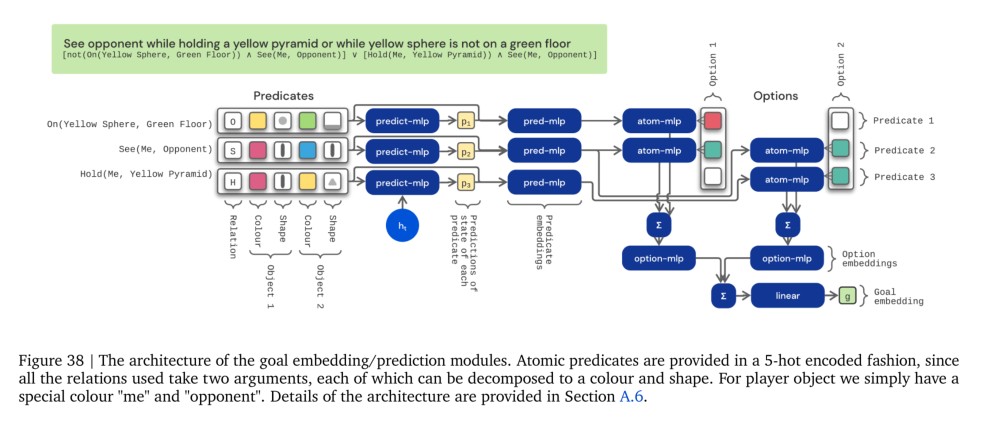

 浙公网安备 33010602011771号
浙公网安备 33010602011771号