
Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning

文章简介
这是一篇关于元强化学习和多任务学习benchmark的文章,发表在PMLR 2020(Proceedings of Machine Learning Research)上。针对于目前元强化学习算法通常只能在简单的benchmark上测试,如在2d navigation的任务中,设置目标点坐标为一系列任务,或者在mujoco环境上,设置机器人的移动方向或移动速度为一系列任务,作者提出了一个包括50个独立任务的机械臂操作物体的benchmark,如Figure 1所示。

背景
定义
元强化学习
每个任务其实就是一个有限长度的MDP,通常用(\(\mathcal{S, A, P, R, H}\), \(\gamma\))表示。元强化学习的目的是,在一个训练任务集(meta-training tasks)\(\mathcal{T_{train}}\)上学习一个策略\(\pi\),然后在一个测试任务集(meta-test tasks)\(\mathcal{T_{test}}\)上把学习到的策略\(\pi\)作为一个初始策略,使得能够快速在\(\mathcal{T_{test}}\)上获得很高的return,也就是fast adaptation。这里的\(\mathcal{T_{train}}\)和\(\mathcal{T_{test}}\)来自于同一个任务分布\(\mathcal{p(\mathcal{T})}\)。相比于用传统RL算法从头训练测试任务集的任务,这样可以加速学习。
多任务学习
和元强化学习不同的是,多任务学习只需要一个训练任务集(meta-training tasks)\(\mathcal{T_{train}}\),不需要测试任务集(meta-test tasks)\(\mathcal{T_{test}}\)。这里是从\(\mathcal{T_{train}}\)学习一个策略\(\pi(a|s, z)\), 使得在\(\mathcal{T_{train}}\)的平均return达到最大。\(z\)是对任务的编码,可以采用one-hot或vector编码。
问题
当前的元强化学习算法测试的benchmark采集的任务分布\(\mathcal{p(\mathcal{T})}\)都特别小,通常只有一两维,如在2d navigation上,从二维空间中采样的目标点坐标作为任务目标,又比如在mujoco机器人移动任务上,从一维空间中采样的机器人的移动速度或者移动方向作为任务目标。
环境内容
参数化和非参数化变量
元强化学习任务的设置要在泛化和专一上进行trade off,使得agent能够学习到有用的东西,而不至于过拟合。具体来说,训练任务集和测试任务集都来自于同一个任务分布,该任务分布中的任务要有一些共性的结构,比如开门和关门这两种任务中,操作的物体是一个带旋转轴的物体。让智能体学习这些共性的结构是元强化学习的目标,这些通常是难以进行参数化的,我们称其为非参数化变量。相对的,参数化变量,如物体的位置坐标,对于智能体来说并不重要。参数化变量和非参数化变量的区别可以从Figure 2中看出。
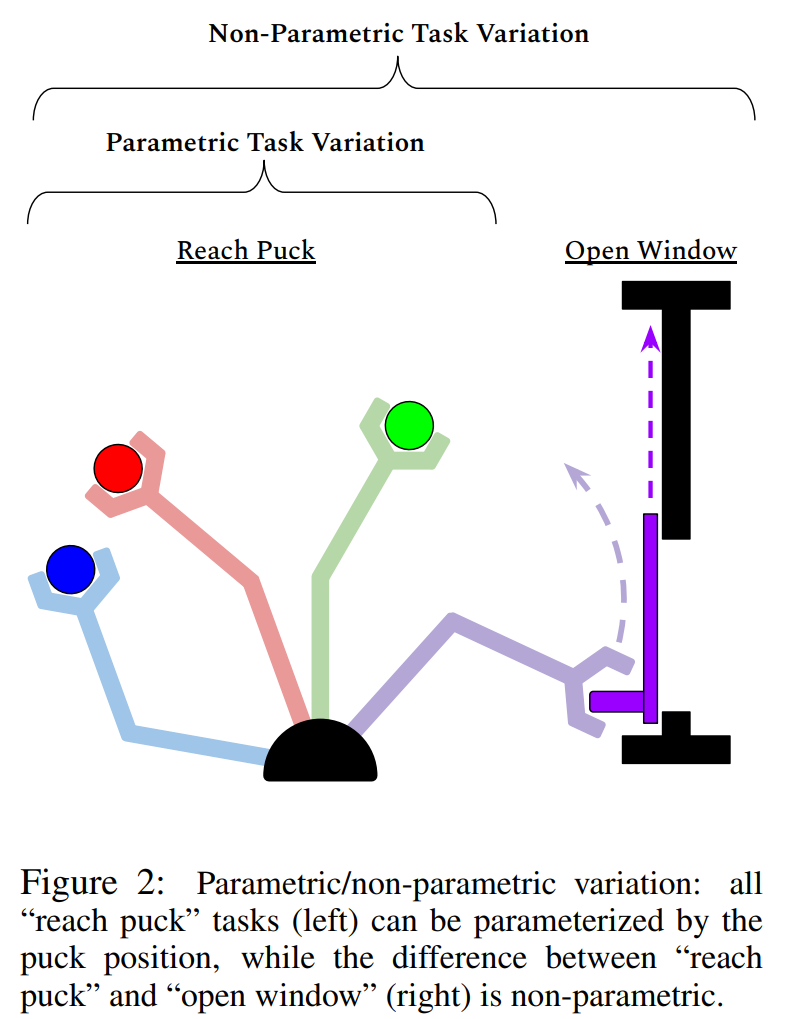
为了使学习过程能有效地学到任务共性的结构,我们可以通过随机初始化参数变量(如物体和目标位置的坐标),生成大量训练任务,这样,在训练的过程中,坐标这一维度的变量的影响程度就会显著降低。而另外一些非参数变量,也就是任务的共性结构,如物体的形状、不同的连接轴的形式(如门和抽屉),可以被有效学习到。
动作空间、观测空间、奖励函数
动作空间
动作空间有4维,包括2个tuple,第一个是机械臂的末端抓手在空间中的位移变化量\((x, y, z)\),第二个是抓手应该施加的力矩大小(正则化,1维),如0.6。动作空间是连续变化的,范围在\(-1\sim+1\)之间。
观测空间
观测空间有39维,包括三部分,当前观测,上一步观测,目标的空间位置\((x, y, z)\)。当前观测有18维,分别是末端抓手的空间位置\((x, y, z)\),抓手的开合程度(正则化,1维),第一个观测物体的空间位置\((x, y, z)\)第一个观测物体的四元数,第二个观测物体的空间位置及其四元数。上一步观测和当前观测内容一样。最后是目标的空间位置\((x, y, z)\)。
奖励函数
元强化学习和多任务学习的奖励函数也要兼容训练单个任务的算法的奖励函数,因此,根据任务类型的不同,可以设计一个奖励函数的集合,如reach奖励,grasp奖励,place奖励。
任务配置
meta world设置了50种小任务,如Table 2所示,这些任务都涉及到不同动作的组合,如turn on faucet要使抓手先到达水龙头的位置,然后反向转动水龙头,turn off faucet则要使抓手先到达水龙头的位置,然后正向转动水龙头。

meta world将元强化学习的大任务分为几个难度,最简单的是在一个小任务中随机参数化变量,如物体的坐标,生成一个任务子集,随着非参数变量数量的增加,也就是小任务种类的增加,元强化学习的难度也越来越大。难度最大的任务,将45个任务作为训练集,5个任务作为测试集,每个任务也会按照随机参数化变量生成n个任务子集,这样训练任务就有\(45n\)个。
具体地,有如下几种任务配置:Meta-Learning 1 (ML1)、 Multi-Task 1 (MT1)、Multi-Task 10, Multi-Task 50 (MT10, MT50)、Meta-Learning 10, Meta-Learning 45 (ML10, ML45)。ML和MT分别对应元强化学习和多任务学习。后面的数字代表这个任务中小任务的数量。在多任务学习中任务采用one-hot进行编码。
在每种大任务中,通过随机参数化变量,每个小任务会生成50个任务子集,这样,ML1就一共有50个训练任务,而ML45有\(45\times 50\)个任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号