
Scrapy框架学习
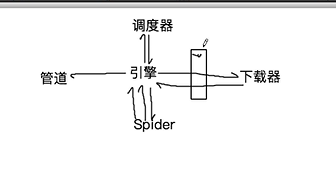
五大核心组件作用
引擎(Scrapy):用来整个系统的数据流处理,触发事物(框架核心)
调度器(Sheduler):用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回,可以想象成一个URL的优先队列,由它来决定下一个要抓取的网址,同时去除重复网址
下载器(Downloader):用于下载网页,并将网页内容返回给蜘蛛(Scrapy下载器是建立在twiisted这个高效的异步模型上的
爬虫(Spiders):爬虫是主要干活的,用于从特定的网页中提取自己需要的信息,即所谓的实体(Item),用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline):负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体,验证实体的有效性,清除不需要的信息,当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据
详细流程如下:
Spider将URL封装成请求对象给引擎,引擎把请求对象给调度器,调度器使用过滤器对请求对象进行去重,并将去重后的请求对象装到队列当中,并从队列中调度出请求对象给引擎。
引擎再将请求对象经过下载中间件给到下载器,下载器将下载到的数据封装到response里,并将response经过下载中间件给到引擎, 引擎将对应的请求对象再给到Spider。Spider解析了请求对象后,将数据封装到item中,并传给引擎,引擎将item给管道,管道最后做持久化存储。
下载中间件middlewares.py
# 拦截所有(正常&异常)的请求 # 参数:request就是拦截到的请求,spider就是爬虫累实例化的对象 def process_request(self, request, spider): request.headers['User-Agent'] = 'xxx' return None # 拦截所有的响应对象 # 参数:response拦截到的响应对象,request响应对象对应的请求对象 def process_response(self, request, response, spider): response # 拦截异常的请求 # 参数:request就是拦截到的发生异常的请求 # 作用:想要将异常的请求进行修正,将其变成正常的请求,然后对其进行发送 def process_exception(self, request, exception, spider): # 请求的ip被禁掉,该请求就会变成一个异常的请求 request.meta['proxy'] = 'http://ip:port' #设置代理 return request #将异常的请求修正后将其进行重新发送
settings.py中的常用配置
增加并发:默认scrapy开启的并发线程为32个,可以适当进行增加,在settings配置文件中修改
CONCURRENT_REQUESTS值即可
降低日志级别:在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率,可以设置log输出信息为INFO或者ERROR,在配置文件中编写:LOG_LEVEL = 'ERROR'
禁止cookie:如果不是真的需要cookie,则在scrapy爬取数据时可以禁止cookie从而减少CPU的使用率,提升爬取效率,在配置文件中编写:COOKIES_ENABLED = False
禁止重试:对失败的HTTP进行重新请求(重试)会减慢爬取速度,因此可以禁止重试,在配置文件中编写:RETRY_ENABLED = False
减少下载超时:如果对一个非常慢的链接进行爬取,减少下载超时可以能让卡住的链接快速被放弃,从而提升效率,在配置文件中编写:DOWNLOAD_TIMEOUT = 10 //超时时间为10秒
爬取数据时,需要关注云服务端的CC防护机制,尤其需要了解对应设置的访问频次,以下是腾讯云的建议与设置:
访问频次:根据业务情况设置访问频次。建议输入正常访问次数的3倍 - 10倍,例如,网站人平均访问20次/分钟,可配置为60次/分钟 - 200次/分钟,可依据被攻击严重程度调整。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号