


Spark Streaming工作原理
说起Spark Streaming,玩大数据的没有不知道的,但对于小白来说还是有些生疏,所以本篇文章就来介绍一下Spark Streaming,以期让同行能更清楚地掌握Spark Streaming的原理。
一:什么是Spark Streaming
官方对于Spark Streaming的介绍是这样的(翻译过来的):Spark Streaming是Spark Core API(Spark RDD)的扩展,支持对实时数据流进行可伸缩、高吞吐量及容错处理。数据可以从Kafka、Flume、Kinesis或TCP Socket等多种来源获取,并且可以使用复杂的算法处理数据,这些算法由map()、reduce()、join()和window()等高级函数表示。处理后的数据可以推送到文件系统、数据库等存储系统。
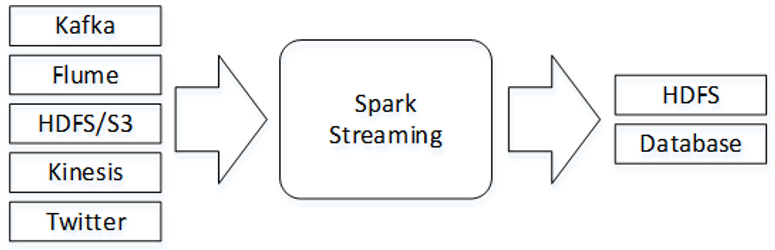
二:Spark Streaming工作原理
Spark Streaming接收实时输入的数据流,并将数据流以时间片(秒级)为单位拆分成批次(每个批次是一个RDD),然后将每个批次交给Spark引擎(Spark Core)进行处理,最终生成以批次组成的结果数据流。

Spark Streaming提供了一种高级抽象,称为DStream(Discretized Stream)。DStream表示一个连续不断的数据流,它可以从Kafka、Flume和Kinesis等数据源的输入数据流创建,也可以通过对其他DStream应用高级函数(例如map()、reduce()、join()和window())进行转换创建。在内部,对输入数据流拆分成的每个批次实际上是一个RDD,一个DStream则由多个RDD组成,相当于一个RDD序列。

DStream中的每个RDD都包含来自特定时间间隔的数据。

应用于DStream上的任何操作实际上都是对底层RDD的操作。例如,对一个DStream应用flatMap()算子操作,实际上是对DStream中每个时间段的RDD都执行一次flatMap()算子,生成对应时间段的新RDD,所有的新RDD组成了一个新Dstream。

对DStream中的RDD的转换是由Spark Core实现的,Spark Streaming对Spark Core进行了封装,提供了非常方便的高层次API。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号