



Spark On YARN架构
Spark On YARN模式遵循YARN的官方规范,YARN只负责资源的管理和调度,运行哪种应用程序由用户自己决定,因此可能在YARN上同时运行MapReduce程序和Spark程序,YARN对每一个程序很好地实现了资源的隔离。这使得Spark与MapReduce可以运行于同一个集群中,共享集群存储资源与计算资源。
一:提交方式
Spark On YARN模式与Standalone模式一样,也分为client和cluster两种提交方式。
1. client提交方式
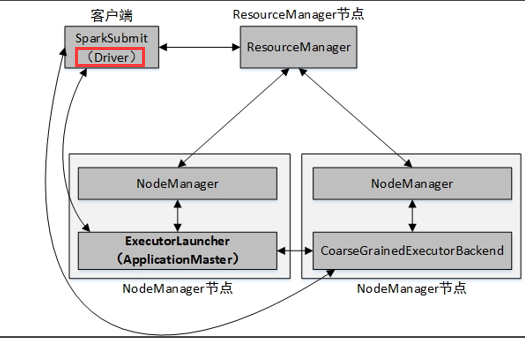
2. cluster提交方式
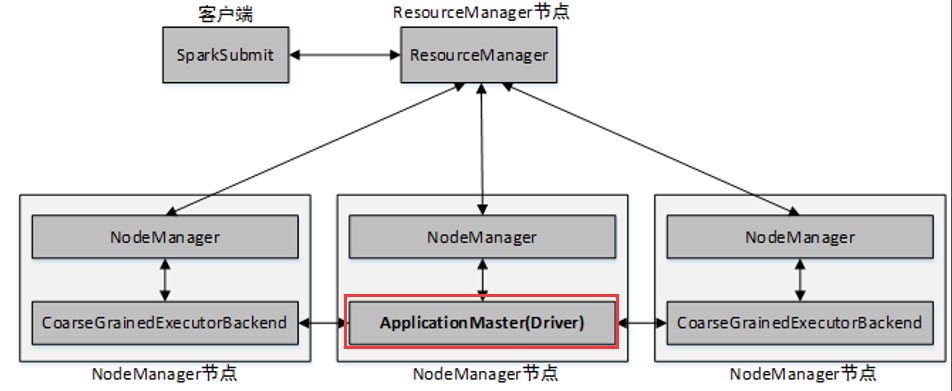
二:Spark On YARN模式的集群搭建
Spark On YARN模式的搭建仅需要在YARN集群的一个节点上安装Spark即可,该节点可作为提交Spark应用程序到YARN集群的客户端。Spark本身的Master节点和Worker节点不需要启动。
使用此模式需要修改Spark配置文件$SPARK_HOME/conf/spark-env.sh,添加Hadoop配置文件所在目录,例如:
HADOOP_CONF_DIR=/home/hadoop/app/hadoop-2.6.0-cdh5.15.1/etc/hadoop
因为这个Hadoop配置文件所在目录中包括了像hdfs-site.xml、mapred-site.xml、yarn-site.xml等配置文件。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号