

python-transformers库
python-transformers库
transformers是一个用于自然语言处理(NLP)任务,如文本分类、命名实体识别,机器翻译等,提供了预训练的语言模型(如BERT、GPT)同时用于模型训练、评估和推理的工具和API的Python库。
Transformers由三个流行的深度学习库(Jax, PyTorch, TensorFlow)提供支持的预训练先进模型库,
用于 自然语言处理(文本),计算机视觉(图像)、音频和语音处理。
BERT-Large, Uncased.(Whole Word Masking): 24-layer, 1024-hidden, 16-heads, 340M parameters
BERT-Large, Cased(Whole Word Masking) : 24-layer, 1024-hidden, 16-heads, 340M parameters
BERT-Base, Uncased: 12-layer, 768-hidden, 12-heads, 110M parameters
BERT-Large, Uncased: 24-layer, 1024-hidden, 16-heads, 340M parameters
BERT-Base, Cased: 12-layer, 768-hidden, 12-heads , 110M parameters
BERT-Large, Cased: 24-layer, 1024-hidden, 16-heads, 340M parameters
BERT-Base, Multilingual Cased (New, recommended): 104 languages, 12-layer, 768-hidden, 12-heads, 110M parameters
BERT-Base, Multilingual Uncased (Orig, not recommended) (Not recommended, use Multilingual Cased instead): 102 languages, 12-layer, 768-hidden, 12-heads, 110M parameters
BERT-Base, Chinese: Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parameters
前6个为英文模型,Multilingual代表多语言模型,最后一个是中文模型 (字级别)
Uncased 代表将字母全部转换成小写,而Cased代表保留了大小写
安装测试
# 安装库
pip install transformers
pip install torch torchvision torchaudio
# 查看版本信息
pip show transformers
# 验证PyTorch安装,以及GPU是否可用
import torch
import transformers
print("transformers version:", transformers.__version__)
print("torch version:", torch.__version__)
print("cuda is available:", torch.cuda.is_available())
print("cuDNN is available:", torch.backends.cudnn.enabled)
print("GPU numbers:", torch.cuda.device_count())
print("GPU name:", torch.cuda.get_device_name(0))
print("GPU capability:", torch.cuda.get_device_capability(0))
print("GPU memory:", torch.cuda.get_device_properties(0).total_memory)
print("GPU compute capability:", torch.cuda.get_device_properties(0).major, torch.cuda.get_device_properties(0).minor)
# ----------------------------------------------------------------------------------
# transformers version: 4.36.2
# torch version: 1.13.0+cu116
# cuda is available: True
# cuDNN is available: True
# GPU numbers: 8
# GPU name: NVIDIA A800-SXM4-80GB
# GPU capability: (8, 0)
# GPU memory: 85197979648
# GPU compute capability: 8 0
功能和优势
transformers库的主要功能包括:
提供丰富的预训练模型
支持主流任务:文本分类、实体识别、情感分析、机器翻译、文本摘要、问答系统等。
提供简洁的API接口,无需关注模型的底层实现细节。
支持多种深度学习框架,如PyTorch和TensorFlow
提供高效的性能,支持多GPU和分布式训练,满足大规模数据处理的需求。
Transformers术语
token: 可以理解为最小语义单元,翻译的话可以是词元、令牌、词,也可以是 word/char/subword,单理解就是单词和标点
tokenization: 是指分词过程,目的是将输入序列划分成一个个词元(token),保证各个词元拥有相对完整和独立的语义,以供后续任务
tokenizer: 就是实现 tokenization 的对象,每个 tokenizer 会有不同的 vocabulary
input_IDs: 本质是 tokens 索引
将输入文本序列转换成 input_ids,即输入编码过程,数值对应的是 tokenizer 词汇表中的索引
from transformers import BertTokenizer
sequence = "A Titan RTX has 24GB of VRAM"
tokenizer = BertTokenizer.from_pretrained("bert-base-multilingual-cased")
tokenized_sequence = tokenizer.tokenize(sequence) # 将输入序列转换成tokens,tokenized 过程
inputs = tokenizer(sequence) # 将输入序列转化成符合模型输入要求的 input_ids,编码过程
encoded_sequence = inputs["input_ids"]
print(tokenized_sequence)
print(encoded_sequence)
print("[INFO]: length of tokenized_sequence and encoded_sequence:", len(tokenized_sequence), len(encoded_sequence))
"""
['A', 'Titan', 'RT', '##X', 'has', '24', '##GB', 'of', 'VR', '##AM']
[101, 138, 28318, 56898, 12674, 10393, 10233, 32469, 10108, 74727, 36535, 102]
[INFO]: length of tokenized_sequence and encoded_sequence: 10 12
"""
模型与分词器
加载预训练模型
from transformers import BertModel
# 加载一个预训练的BERT模型
# bert-base-uncased是BERT模型的一个变体,它使用小写字母进行训练,具有较小的模型大小和计算复杂度
model = BertModel.from_pretrained("bert-base-uncased")
# model.config是一个包含模型配置
print(model.config)
# -------------------------------------------------------------------------------------------------
# BertConfig {
# "architectures": [
# "BertForMaskedLM"
# ],
# "attention_probs_dropout_prob": 0.1,
# "classifier_dropout": null,
# "gradient_checkpointing": false,
# "hidden_act": "gelu",
# "hidden_dropout_prob": 0.1,
# "hidden_size": 768,
# "initializer_range": 0.02,
# "intermediate_size": 3072,
# "layer_norm_eps": 1e-12,
# "max_position_embeddings": 512,
# "model_type": "bert",
# "num_attention_heads": 12,
# "num_hidden_layers": 12,
# "pad_token_id": 0,
# "position_embedding_type": "absolute",
# "transformers_version": "4.36.2",
# "type_vocab_size": 2,
# "use_cache": true,
# "vocab_size": 30522
# }
所有存储在 HuggingFace Model Hub 上的模型都可以通过 Model.from_pretrained() 来加载权重
Model.from_pretrained() 会自动缓存下载的模型权重,默认保存到 ~/.cache/huggingface/transformers
保存模型
保存模型通过调用 Model.save_pretrained() 函数实现,例如保存加载的 BERT 模型
from transformers import AutoModel
model = AutoModel.from_pretrained("bert-base-cased")
model.save_pretrained("./models/bert-base-cased/")
# 再次加载模型
# Model.from_pretrained() 加载,只需要传递保存目录的路径。
AutoModel.from_pretrained("./models/bert/")
这会在保存路径下创建两个文件:
- config.json:模型配置文件,存储模型结构参数,例如 Transformer 层数、特征空间维度等;
- pytorch_model.bin:又称为 state dictionary,存储模型的权重。
分词器
由于神经网络模型不能直接处理文本,在使用预训练模型处理文本之前,我们需要将文本转换为模型可以理解的格式,这个过程被称为编码 (Encoding)。
-
使用分词器 (tokenizer) 将文本按词、子词、字符切分为 tokens;
-
将所有的 token 映射到对应的 token ID
词表就是一个映射字典,负责将 token 映射到对应的 ID(从 0 开始)。神经网络模型就是通过这些 token ID 来区分每一个 token。
# 使用BERT的tokenizer进行文本编码
from transformers import BertTokenizer
# 预训练的BERT
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
text = "here is some text to encode"
encoded_input = tokenizer(text, return_tensors='pt')
print(encoded_input)
# ---------------------------------------------------------------------------
{'input_ids': tensor([[ 101, 2182, 2003, 2070, 3793, 2000, 4372, 16044, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1]])}
- input_ids:对应于句子中每个 token 的索引。
- token_type_ids:当存在多个序列时,标识 token 属于那个序列。
- attention_mask:表明对应的 token 是否需要被注意(1 表示需要被注意,0 表示不需要被注意。涉及到注意力机制)
编码和解码
# 编码: 将句子text映射成token IDs, 包含了两部分,分词,映射
# 分词:使用分词器按某种策略将文本切分为 tokens;
# 映射:将 tokens 转化为对应的 token IDs
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
# 分词器分词
sequence = "Using a Transformer network is simple"
tokens = tokenizer.tokenize(sequence)
print(tokens)
# ['Using', 'a', 'Trans', '##former', 'network', 'is', 'simple']
# 切分出的 tokens 转换为对应的 token ID
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
# [7993, 170, 13809, 23763, 2443, 1110, 3014]
# 可以通过 encode() 函数将这两个步骤合并
sequence = "Using a Transformer network is simple"
sequence_ids = tokenizer.encode(sequence)
print(sequence_ids)
# [101, 7993, 170, 13809, 23763, 2443, 1110, 3014, 102]
# 其中 101 和 102 分别是 起始[CLS] 和 终点[SEP]对应的 token IDs。
# 实际编码文本时,最常见的是直接使用分词器进行处理
text = "here is some text to encode"
encoded_input = tokenizer(text, return_tensors='pt')
print(encoded_input)
# -----------------------------------------------------------------------
# {'input_ids': tensor([[ 101, 2182, 2003, 2070, 3793, 2000, 4372, 16044, 102]]),
# 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0]]),
# 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1]])}
# 文本解码 将 token IDs 转换回原来的字符串
# 可以使用 tokenizer 将 input_ids 解码为原始输入
from transformers import BertTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
text = "here is some text to encode"
encoded_input = tokenizer(text, return_tensors='pt')
print(encoded_input)
# -----------------------------------------------------------------------
# {'input_ids': tensor([[ 101, 2182, 2003, 2070, 3793, 2000, 4372, 16044, 102]]),
# 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0]]),
# 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1]])}
decoded_input = tokenizer.decode(encoded_input["input_ids"][0])
# -----------------------------------------------------------------------
# [CLS] here is some text to encode [SEP]
填充Pad
当我们处理一批句子时,它的长度并不总是相同的,但是模型的输入需要具有统一的形状shape,
填充是实现此需求的一种策略,即为 token 较少的句子添加特殊的填充 token。
batch_sentences = ["今天天气真好",
"今天天气真好,适合出游"]
encoded_inputs = tokenizer(batch_sentences, padding=True)
print(encoded_inputs)
# --------------------------------------------------------------------
# {'input_ids':
# [[101, 791, 1921, 1921, 3698, 4696, 1962, 102, 0, 0, 0, 0, 0],
# [101, 791, 1921, 1921, 3698, 4696, 1962, 8024, 6844, 1394, 1139, 3952, 102]], 'token_type_ids':
# [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
# [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
#'attention_mask':
# [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0],
# [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
pipeline
pipeline简介
Pipeline是一个简捷的NLP任务接口,作用就是跨不同模式使用。使用预训练模型进行推断,它支持从这里下载所有模型
执行流程
执行Input -> Tokenization -> Model Inference -> Post-Processing (Task dependent) -> Output一系列操作
支持许多常见任务
Transformers 库将目前的 NLP 任务归纳为几下几类:
- 文本分类:例如情感分析、句子对关系判断等;
- 对文本中的词语进行分类:例如词性标注 (POS)、命名实体识别 (NER) 等;
- 文本生成:例如填充预设的模板 (prompt)、预测文本中被遮掩掉 (masked) 的词语;
- 从文本中抽取答案:例如根据给定的问题从一段文本中抽取出对应的答案;
- 根据输入文本生成新的句子:例如文本翻译、自动摘要等。
Transformers 库最基础的对象就是 pipeline() 函数,它封装了预训练模型和对应的前处理和后处理环节。我们只需输入文本,就能得到预期的答案。目前常用的 pipelines 有:
feature-extraction (获得文本的向量化表示)
fill-mask (填充被遮盖的词、片段)
ner(命名实体识别)
question-answering (自动问答)
sentiment-analysis (情感分析)
summarization (自动摘要)
text-generation (文本生成)
translation (机器翻译)
zero-shot-classification (零训练样本分类)
| 任务 | 描述 | 模态 | Pipeline |
|---|---|---|---|
| 文本分类 | 为给定的文本序列分配一个标签 | NLP | pipeline(task="sentiment-analysis") |
| 文本生成 | 根据给定的提示生成文本 | NLP | pipeline(task="text-generation") |
| 命名实体识别 | 为序列里的每个token分配一个标签(人, 组织, 地址等等) | NLP | pipeline(task="ner") |
| 问答系统 | 通过给定的上下文和问题, 在文本中提取答案 | NLP | pipeline(task="question-answering") |
| 掩盖填充 | 预测出正确的在序列中被掩盖的token | NLP | pipeline(task="fill-mask") |
| 文本摘要 | 为文本序列或文档生成总结 | NLP | pipeline(task="summarization") |
| 文本翻译 | 将文本从一种语言翻译为另一种语言 | NLP | pipeline(task="translation") |
| 图像分类 | 为图像分配一个标签 | Computer vision | pipeline(task="image-classification") |
| 图像分割 | 为图像中每个独立的像素分配标签(支持语义、全景和实例分割) | Computer vision | pipeline(task="image-segmentation") |
| 目标检测 | 预测图像中目标对象的边界框和类别 | Computer vision | pipeline(task="object-detection") |
| 音频分类 | 给音频文件分配一个标签 | Audio | pipeline(task="audio-classification") |
| 自动语音识别 | 将音频文件中的语音提取为文本 | Audio | pipeline(task="automatic-speech-recognition") |
| 视觉问答 | 给定一个图像和一个问题,正确地回答有关图像的问题 | Multimodal | pipeline(task="vqa") |
文本生成
我们首先根据任务需要构建一个模板 (prompt),然后将其送入到模型中来生成后续文本
from transformers import pipeline
generator = pipeline("text-generation", model="distilgpt2")
results = generator(
"In this course, we will teach you how to",
max_length=30,
num_return_sequences=2,
)
print(results)
[{'generated_text': 'In this course, we will teach you how to use React in any form, and how to use React without having to worry about your React dependencies because'},
{'generated_text': 'In this course, we will teach you how to use a computer system in order to create a working computer. It will tell you how you can use'}]
pipeline原理
以情感分析为例
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
result = classifier("I've been waiting for a HuggingFace course my whole life.")
print(result)
# -------------------------------------------------------------------
# [{'label': 'POSITIVE', 'score': 0.9598048329353333}]
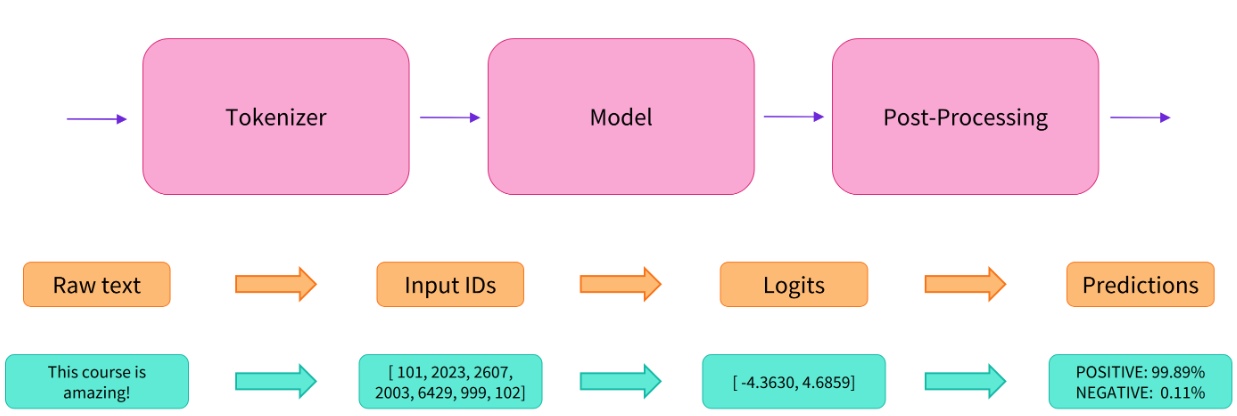
执行步骤
- 预处理 (preprocessing),将原始文本转换为模型可以接受的输入格式;
- 将处理好的输入送入模型;
- 对模型的输出进行后处理 (postprocessing),将其转换为人类方便阅读的格式。
参考资料
Transformer快速入门 官方详细

 浙公网安备 33010602011771号
浙公网安备 33010602011771号