

BERT模型
BERT模型
BERT(Bidirectional Encoder Representations from Transformers):由Google在2018年提出的预训练模型。BERT采用双向Transformer编码器结构,通过掩码语言模型(Masked Language Model,MLM)和下一个句子预测(Next Sentence Prediction,NSP)两种任务进行预训练。BERT在多种NLP任务上取得了显著的成果,成为了许多后续模型的基础。
BERT模型的目标是利用大规模无标注语料训练、获得文本的包含丰富语义信息的Representation,即:文本的语义表示,然后将文本的语义表示在特定NLP任务中作微调,最终应用于该NLP任务
论文地址:https://link.juejin.cn/?target=https%3A%2F%2Farxiv.org%2Fabs%2F1810.04805
代码地址:https://link.juejin.cn/?target=https%3A%2F%2Fgithub.com%2Fgoogle-research%2Fbert
BERT模型的基本框架用的是 Transformer 中的 Encoder blockBERT的基础结构仍然是Transformer,并且仅有Encoder部分,因为它并不是生成式模型
-
模型是基于Transformer中得Encoder并加上双向得结构
-
它提出了一种掩码语言模型-MLM(masked language model)
-
Bert为NLP任务提供了泛化性强、效果显著的预训练模型。
模型输入
BERT模型通过查询字向量表将文本中的每个字转换为一维向量,作为模型输入
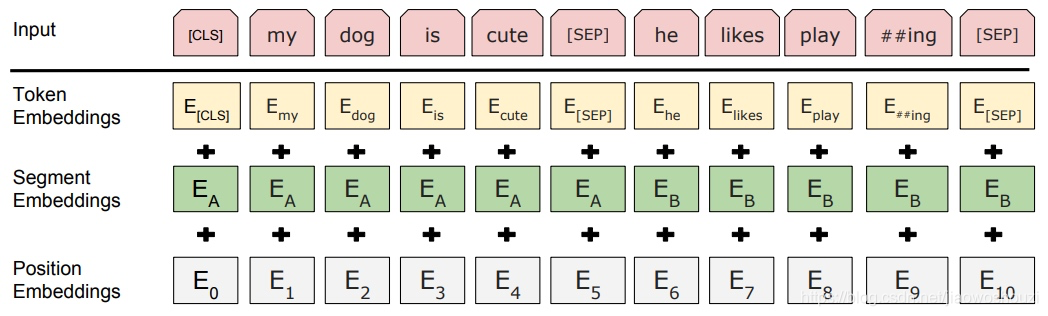
BERT模型的输入 : 输入词向量是三个向量之和
Token Embedding : 词向量
Segment Embedding : 段表征,表明这个词属于哪个句子,用于刻画文本的全局语义信息
Position Embedding:位置表征,学习出来的embedding向量
模型输出
对于不同的NLP任务,模型输入会有微调,对模型输出的利用也有差异,例如:
- 单文本分类任务:对于文本分类任务,BERT模型在文本前插入一个[CLS]符号,并将该符号对应的输出向量作为整篇文本的语义表示,用于文本分类。可以理解为:与文本中已有的其它字/词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个字/词的语义信息。
- 语句对分类任务:该任务的实际应用场景包括:问答(判断一个问题与一个答案是否匹配)、语句匹配(两句话是否表达同一个意思)等。对于该任务,BERT模型除了添加[CLS]符号并将对应的输出作为文本的语义表示,还对输入的两句话用一个[SEP]符号作分割,并分别对两句话附加两个不同的文本向量以作区分。
预训练模型
BERT的预训练阶段包括两个任务,一个是Masked Language Model,还有一个是Next Sentence Prediction。
- Masked Language Model MLM可以理解为完形填空,作者会随机mask每一个句子中15%的词,用其上下文来做预测,例如:my dog is hairy → my dog is [MASK] 此处将hairy进行了mask处理,然后采用非监督学习的方法预测mask位置的词是什么,但是该方法有一个问题,因为是mask15%的词,其数量已经很高了,这样就会导致某些词在fine-tuning阶段从未见过,为了解决这个问题,作者做了如下的处理:
- 80%的时间是采用[mask],my dog is hairy → my dog is [MASK]
- 10%的时间是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple
- 10%的时间保持不变,my dog is hairy -> my dog is hairy
- Next Sentence Prediction 给定一篇文章中的两句话,判断第二句话在文本中是否紧跟在第一句话之后。选择一些句子对A与B,其中50%的数据B是A的下一条句子,剩余50%的数据B是语料库中随机选择的,学习其中的相关性, 添加这样的预训练的目的是目前很多NLP的任务比如QA和NLI都需要理解两个句子之间的关系,从而能让预训练的模型更好的适应这样的任务。
为啥要以概率使用随机词
transformer要保持对每个输入token分布式的表征,否则Transformer很可能会记住这个[MASK]就是"hairy"。至于使用随机词带来的负面影响,文章中解释说,所有其他的token(即非"hairy"的token)共享15%*10% = 1.5%的概率,其影响是可以忽略不计的。Transformer全局的可视,又增加了信息的获取,但是不让模型获取全量信息。
模型结构
Attention机制
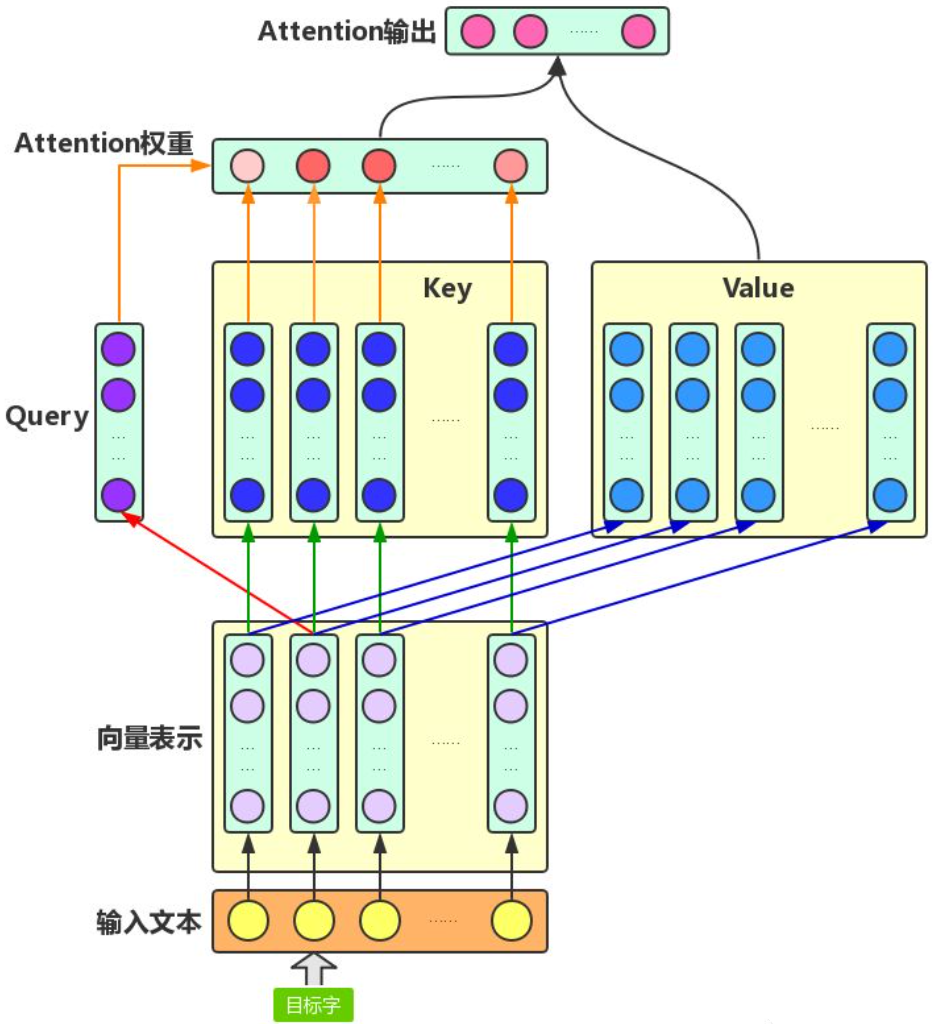
Attention机制主要涉及到三个概念:Query、Key和Value。针对文本中,目标字及其上下文的字都有各自的原始Value,Attention机制将目标字作为Query、其上下文的各个字作为Key,并将Query与各个Key的相似性作为权重,把上下文各个字的Value融入目标字的原始Value中。如下图所示,Attention机制将目标字和上下文各个字的语义向量表示作为输入,首先通过线性变换获得目标字的Query向量表示、上下文各个字的Key向量表示以及目标字与上下文各个字的原始Value表示,然后计算Query向量与各个Key向量的相似度作为权重,加权融合目标字的Value向量和各个上下文字的Value向量,作为Attention的输出,即:目标字的增强语义向量表示。
Self-Attention:对于输入文本,我们需要对其中的每个字分别增强语义向量表示,因此,我们分别将每个字作为Query,加权融合文本中所有字的语义信息,得到各个字的增强语义向量,如下图所示。在这种情况下,Query、Key和Value的向量表示均来自于同一输入文本,因此,该Attention机制也叫Self-Attention。
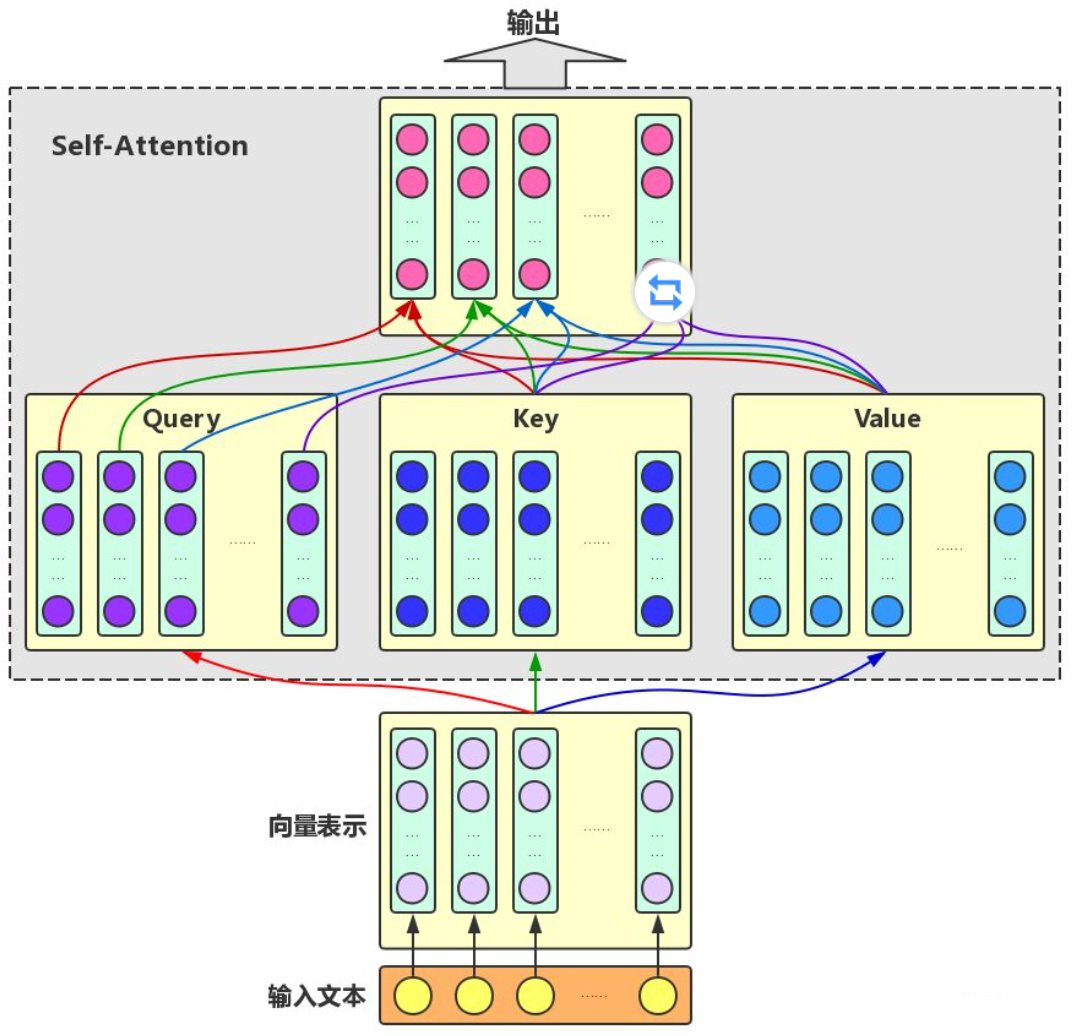
Multi-head Self-Attention:为了增强Attention的多样性,文章作者进一步利用不同的Self-Attention模块获得文本中每个字在不同语义空间下的增强语义向量,并将每个字的多个增强语义向量进行线性组合,从而获得一个最终的与原始字向量长度相同的增强语义向量。
Self-Attention旨在用文本中的其它字来增强目标字的语义表示。在不同的语义场景下,Attention所重点关注的字应有所不同。
例如:“南京市长江大桥”,在不同语义场景下对这句话可以有不同的理解:“南京市/长江大桥”,或“南京市长/江大桥”
因此,Multi-head Self-Attention可以理解为考虑多种语义场景下目标字与文本中其它字的语义向量的不同融合方式。可以看到,Multi-head Self-Attention的输入和输出在形式上完全相同,输入为文本中各个字的原始向量表示,输出为各个字融合了全文语义信息后的增强向量表示。
Transformer Encoder在Multi-head Self-Attention之上又添加了三种关键操作:
- 残差连接(ResidualConnection):将模块的输入与输出直接相加,作为最后的输出。这种操作背后的一个基本考虑是:修改输入比重构整个输出更容易(“锦上添花”比“雪中送炭”容易多了!)。这样一来,可以使网络更容易训练。
- Layer Normalization:对某一层神经网络节点作0均值1方差的标准化。
- 线性转换:对每个字的增强语义向量再做两次线性变换,以增强整个模型的表达能力。这里,变换后的向量与原向量保持长度相同。
Transformer Encoder的输入和输出在形式上还是完全相同,因此,Transformer Encoder同样可以表示为将输入文本中各个字的语义向量转换为相同长度的增强语义向量的一个黑盒。
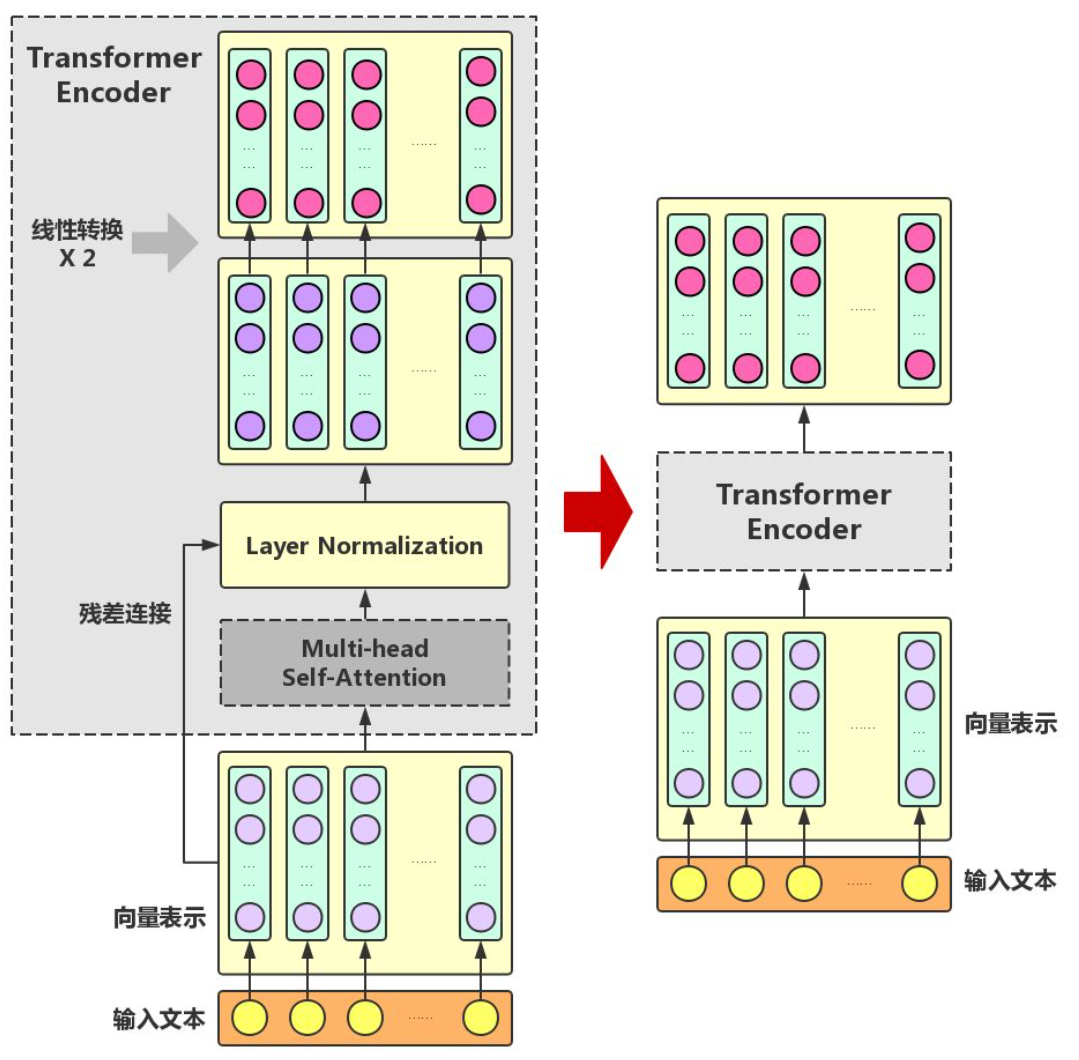
再把多个Transformer Encoder一层一层地堆叠起来,就是最后的BERT模型
在论文中,作者分别用12层和24层Transformer Encoder组装了两套BERT模型,两套模型的参数总数分别为110M和340M。
优缺点
-
双向的transformer作为编码器,在语言理解相关的文本表示效果很好
-
缺点是不能直接用于文本生成,上下文依赖
-
bert模型只能处理长度较短的文本,而不能直接处理超过512个标记的文本
-
作为一种预训练模型,在特定场景使用时不需要用大量的语料来进行训练,节约时间效率高效,泛化能力较强
适用场景
命名实体识别
机器阅读理解
情感计算
已有的预训练模型
BERT-Large, Uncased.(Whole Word Masking): 24-layer, 1024-hidden, 16-heads, 340M parameters
BERT-Large, Cased(Whole Word Masking) : 24-layer, 1024-hidden, 16-heads, 340M parameters
BERT-Base, Uncased: 12-layer, 768-hidden, 12-heads, 110M parameters
BERT-Large, Uncased: 24-layer, 1024-hidden, 16-heads, 340M parameters
BERT-Base, Cased: 12-layer, 768-hidden, 12-heads , 110M parameters
BERT-Large, Cased: 24-layer, 1024-hidden, 16-heads, 340M parameters
BERT-Base, Multilingual Cased (New, recommended): 104 languages, 12-layer, 768-hidden, 12-heads, 110M parameters
BERT-Base, Multilingual Uncased (Orig, not recommended) (Not recommended, use Multilingual Cased instead): 102 languages, 12-layer, 768-hidden, 12-heads, 110M parameters
BERT-Base, Chinese: Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parameters
前6个为英文模型,Multilingual代表多语言模型,最后一个是中文模型 (字级别)
Uncased 代表将字母全部转换成小写,而Cased代表保留了大小写
参考资料
图解BERT模型:从零开始构建BERT 图片来源
https://juejin.cn/post/7300875360371474471

 浙公网安备 33010602011771号
浙公网安备 33010602011771号