
Azure SQL 数据库仓库Data Warehouse (2) 架构
《Windows Azure Platform 系列文章目录》
在上一篇文章中,笔者介绍了MPP架构的基本内容
在本章中,笔者给大家介绍一下Azure SQL Data Warehouse数据仓库(SQL DW)的架构。
1.SQL DW分为Head Node和Work Node,下图用Control Node和Compute Node表示
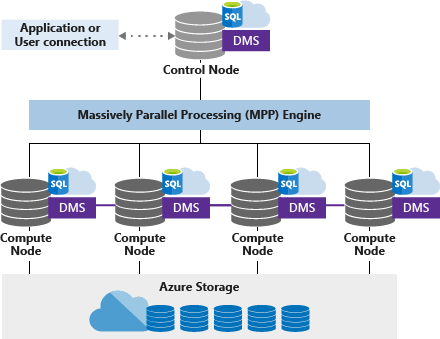
SQL DW是用多个Work Node横向扩展的方式,来支持PB级别的大量关系型数据。
应用程序将T-SQL命令发送给Head Node。Head Node使用MPP引擎,该引擎优化并行处理的查询,然后将查询发送给Work Node进行并行查询
Work Node将需要处理的数据保存到Azure Storage中,并进行并行查询
数据移动服务(DMS)是SQL DW的内部服务,可根据需要跨节点移动数据,以并行运行查询并返回准确的结果
2.SQL DW是计算和存储分离
用户的数据是保存在Azure Storage 中的,并不保存在Work Node的本地磁盘上。
SQL DW实现了Work Node和用户数据的逻辑依赖关系,数据并不移动
也就是说,当用户的Work Node从6台,横向扩展到10台后,SQL DW重新设置了10个Work Node到Azure Storage的逻辑关系
3.Azure Storage
SQL DW底层使用的是Azure Premium Storage,也就是SSD 固态硬盘存储。
同时用户也可以设置数据库表在SSD存储上的分布模式。SQL DW支持的数据表的分布模式有:
(1)轮询 Round Robin
(2)哈希 Hash
(3)复制 Replication
4.Head Node
Head Node是SQL DW的大脑。Head Node在最前端,处理应用程序的交互和链接。
在Head Node上的MPP引擎,优化和协调并行查询。
当用户提交了一个T-SQL查询,Head Node会将该查询转换,在所有的Work Node上并行查询
5.Work Node
Work Node是真正进行计算的节点。Work Node节点的数量范围是1-60.
每个Work Node都有一个在系统视图中可见的Node ID。我们可以可以通过查找名称以sys.pdw_nodes开头的系统视图中的node_id列来查看Compute节点ID
6.数据分区模式
分区是在分布式数据上运行的并行查询的基本存储和处理单元。
当SQL DW进行查询的时候,任务被分为60个并行执行的子查询。每个子查询都在1个数据分布上运行。
默认情况下,用户的数据被分为60份 (60个分区)。
当Work Node节点数量为1的时候,1个Work Node处理60个分区数据。
当Work Node节点数量为2的时候,2个Work Node处理60个分区数据,每个Work Node处理30个分区数据
当Work Node节点数量为3的时候,3个Work Node处理60个分区数据,每个Work Node处理20个分区数据
......
当Work Node节点数量为60的时候,60个Work Node处理60个分区数据,每个Work Node处理1个分区数据,这样并行度最高
举个例子,假设我们只有1个数据库,这个数据库只有1张表,这张表有6000万行数据
当Work Node节点数量为1的时候,1个Work Node处理6000万行数据,这样并行度最低
当Work Node节点数量为2的时候,2个Work Node处理6000万行数据,每个Work Node处理3000万行数据
当Work Node节点数量为3的时候,3个Work Node处理6000万行数据,每个Work Node处理2000万行数据
......
当Work Node节点数量为60的时候,60个Work Node处理6000万行数据,每个Work Node处理100万行数据,这样并行度最高
观察可以发现,设置SQL DW 分区模式是非常重要的
我们在上面介绍了,SQL DW支持的数据表的分区模式有三种:轮询 Round Robin,哈希 Hash,复制 Replication
7.轮训 Round Robin
轮询表是最简单的分布模式,一般用于临时表
轮询表中的数据是平均分布的,不进行任何优化。在使用轮训表的时候,SQL DW随机选择一个分布键,然后将数据随机的写入轮询表
与哈希分布表不同的是,值相等的行不一定分配到相同的分布区。
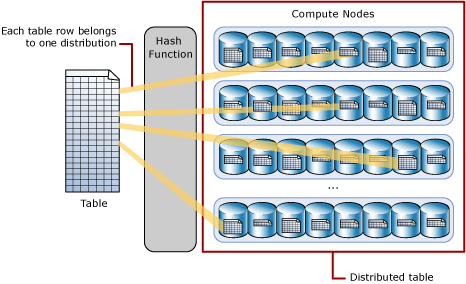
8.哈希 Hash
哈希表为大型数据库表提供表连接(join)和聚合查询(aggregation),提供最高的性能
在使用Hash表的时候,SQL DW使用Hash函数,将每一行都分配到同一个分区。
在数据库表中,定义其中一列为分区列,使用Hash函数将数据保存到同一个分区中
下图说明了Hash Table
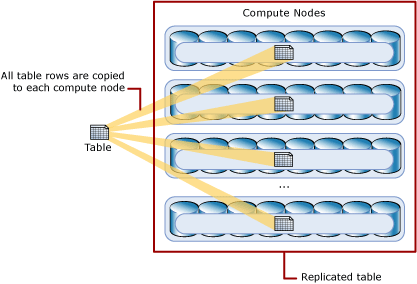
9.复制 Replica
复制表为数据量小的表,提供了最快的查询性能
复制表在每个Work Node上缓存表的完整副本。因此,在使用复制表进行表连接(join)和聚合查询(aggregation)的时候,不会产生数据在Work Node上移动
复制表最好用于数据量小的表,在表大小小于2GB时,复制表效果好
下图说明了复制Replica表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号