基于统计的无词典的高频词抽取(二)——根据LCP数组计算词频
接着上文【基于统计的无词典的高频词抽取(一)——后缀数组字典序排序】,本文主要讲解高频子串抽取部分。
如果看过上一篇文章的朋友都知道,我们通过 快排 或 基数排序算出了存储后缀数组字典序的PAT数组,以及PAT数组内,每每两个子串的最大公共前缀数组LCP。
我们可以通过LCP来计算出一个字符串在语料库中出现的次数。那怎么计算呢?我们先看看下面一个简单的例子:
【例】我们还是以上一篇文章中的字符串“abcba”为例,经过对后缀数组字典序排序(过程参照前一篇),可以得到以下的结果:
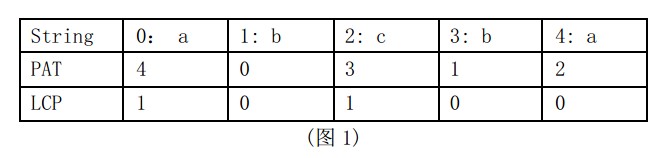
由上图中的PAT和LCP两个数组我们可以知道:“a”的频率为2,“b”的频率为2。
计算方式其实很简单,从左扫描LCP数组,如果LCP[i]>=n(n为自定义的两个字符串公共子串的长度的最小长度,上面例子中设置为1),LCP[0]=1符合候选规则,则看PAT[0]=4,意思是说“abcba”这个字符串中的第PAT[i]+1=5个后缀子串,也就是“a”,我们知道,LCP表示的是相邻的两个PAT间的最长公共前缀,故“a”的频率=LCP[0]+1=2次。同理,可以知道“b”出现两次(S[PAT[3]]=b,LCP[2]=1,所以b出现的次数为1+1=2,刚开始有点难理解,但其实很好理解的)
分析完上面的例子,我们应该更加清楚的了解了LCP的作用,就是计算一个字符串在一个语料库中出现的次数,现在我们就用伪代码(文字)一步一步分析这个过程:
① 设定c 的初值为0;
② 从LCP位置c开始扫描直至索引i,有LCP[i]≥n;
③ 记录LCP[i]的值,继续向前扫描,直至位置j,有LCP[j]<LCP[i]。如果存在位置x(i<x≤j),有LCP[x]>LCP[i],则令c=x,否则c=j;
④ 提取字符串S,其在T中的开始位置为PAT[i],长度为LCP[i],S出现的次数为j-k,记录串S出现的次数j-k;
⑤ 返回步骤②,提取下一个字符串,直至扫描完LCP数组;
⑥ 对所记录的所有字符串,按照出现次数进行排列,输出所有出现次数≥n的字符串序列;
这个过程中要注意存在这样这样的一种情况:假设LCP为:1,1,3,2,1,0,0,2,...,那么1,1,3,2,1 我们知道,第一个字符出现了6次,而中间的3那个串出现了2次,但是计算2那个串的时候,因为前面的3>2,所以我们必须往前回溯,也就是说这里2那个串出现的次数是2+1=3次;
代码实现过程如下(经测试,对30万的数组查找耗时12s左右,没做过多优化,大家可以根据此思路来做优化):
1 public static void ScanLCP(List < StringFrequency > stringFrequncy, int[] LCP, int count, int start, int minLen, int maxLen) 2 { 3 var _START = start; 4 while (_START <= count - 1) 5 { 6 var _LCP = _START; 7 var isFirst = true; 8 var isLarge = true; 9 var isContinue = true; 10 int j = 0; 11 int i = _START; 12 for (; i < count; i++) 13 { 14 if (LCP[_START] > maxLen) 15 { 16 _START += 1; 17 break; 18 } 19 if (isFirst) 20 { 21 if (i - 1 >= 0) 22 { 23 if (LCP[i - 1] >= LCP[i]) 24 { 25 for (var k = i - 1; k >= 0; k--) 26 { 27 if (LCP[k] >= minLen && LCP[k] != LCP[i]) 28 j += 1; 29 else 30 { 31 if (LCP[k] == LCP[i]) 32 { 33 isContinue = false; 34 j = 0; 35 } 36 break; 37 } 38 } 39 } 40 } 41 } 42 if (LCP[i] >= minLen && LCP[i] >= LCP[_LCP] && isContinue) 43 { 44 if (isFirst) 45 { 46 _LCP = i; 47 isFirst = false; 48 } 49 if (isLarge && LCP[i] > LCP[_LCP]) 50 { 51 _START = i; 52 isLarge = false; 53 } 54 } 55 else 56 { 57 if ((isFirst && LCP[i] < minLen) || !isContinue) 58 _START = i + 1; 59 else 60 { 61 if (isLarge && LCP[i] < LCP[_LCP]) 62 _START = i; 63 if (LCP[_LCP] <= maxLen) 64 { 65 var sf = new StringFrequency(); 66 sf.Position = _LCP; 67 sf.Times = (i - _LCP) + 1 + j; 68 stringFrequncy.Add(sf); 69 } 70 } 71 break; 72 } 73 } 74 } 75 }
看起来好像挺玄乎,其实,到这一步的时候,对语料库的分析抽词已经初见成效了,下图,是我对《人民日报》2012年8月份到11月份的报纸的分析抽取,进行了后缀数组排序,LCP计算后的结果:
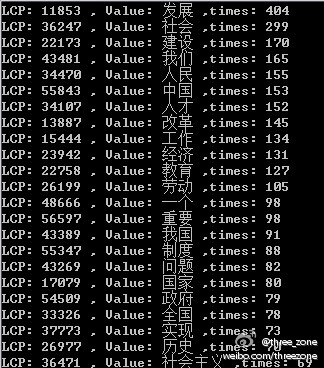
现在的结果还不够精确,等做完子串归并,最大熵模型后,可以获得更精准的结果(Ps:人民日报涉及的内容太片面,实际情况下,要采集涉及面广的语料库)
好了,第二部分就先讲到这里,如果觉得文章对您有用或者对其他人有帮助,请帮忙点文章下面的“推荐”;如果文章有任何纰漏,欢迎指正,谢谢!
多聚旅游 聚游宝 学友网

 浙公网安备 33010602011771号
浙公网安备 33010602011771号