6.824 spanner
这是一个很少见的例子,提供了针对分布范围很广的分离数据的分布式,这些数据可能分散在整个internet下不同的数据中心。
希望使用的原因:
我们希望使用分布式事务,保证程序的正确性
并且希望将数据分散在网络上获得容错
以次确保每个想要使用该书记肚饿人的附近都有该数据的一分副本
spanner 至少使用了两个巧妙的思想
两阶段提交,为了防止失误协调器崩溃,使用Paxos
通过同步时间做到高效的只读事务
谷歌内部常用的技术spanner
他使得大范围事务成为了可能
设计spanner的原因:
谷歌内部使用很多大型数据库系统,广告系统中的数据存放在很多不同的mysql和bigTable数据库中,维护这些分片试试一个非常费时费力的过程
他们想将数据分散到不同服务器上获得更好的性能,并且想具备哎多个数据分片上使用数据的能力。
他们需要强一致性,想获得外部一致性,那么就要考虑分布式下的数据复制相关问题。
谷歌的数据遍布全世界,一份数据存在于多个数据中心
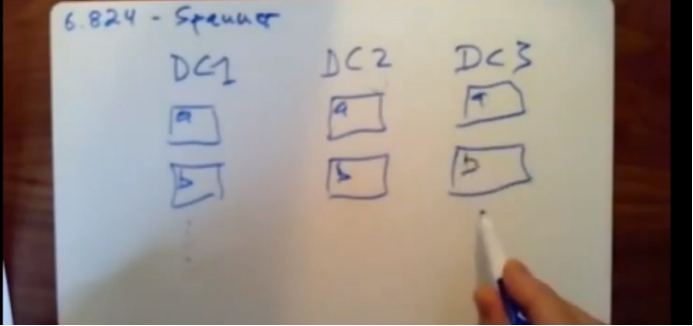
上图两份数据存在于三个数据中心。
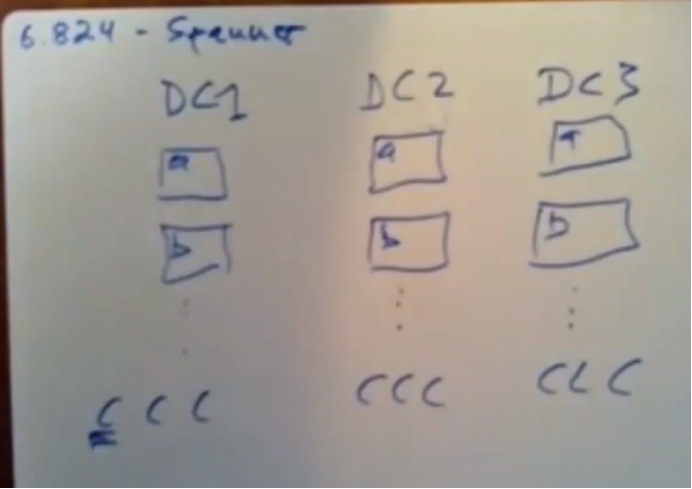
每个数据中心又有多个 spanner client,当你用户通过任何形式比如浏览器访问 数据中心时,链接的就是其中一个spanner client。
副本由 paxos 管理。
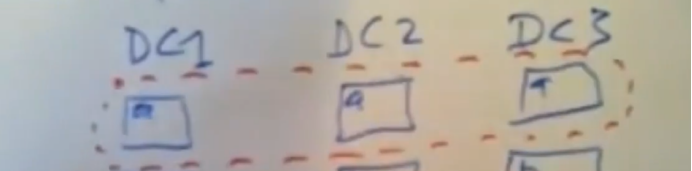
一份数据,包含该数据所有分片的所有replica组成一个paxos组
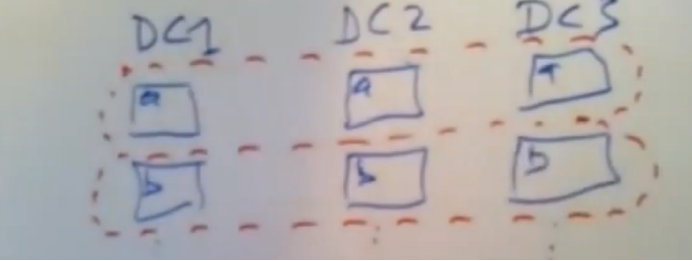
每个paxos 组都有自己的leader,各自维护自己的数据版本
这样对每个数据分片对应paxos彼此独立,可以对数据做并行加速粗粒,提供并行吞吐量
为了应对海量并发请求。
一个clidnet写入 得吧这个写请求发送给这个paxos的leader,然后复制。
这种一个数据分布在多个数据中心的实现,设计重点是为了让和离client最近的replica来处理读请求这样读取既快又准。
这样做解决了,可以在本地数据中心得到数据。可以提高速度。但是可能读到旧数据。
解决读取旧数据,需要通过某种方式处理本地replica上数据版本有点落后的情况,
出现了另一个问题,一个失误可能会涉及多个数据分片也就是多个paxos组,这个失误可能要对数据库中多个记录进行读写,这些记录被保存在多个数据分片和多个paxos组中,所以我们需要分布式事务。
本节课重点事务
spanner实现了读写型事务,这和只读事务不同。

现在我们有个事务,client希望数据库结束并提交该事务,我想去赘述spanner执行这个读写事务时候锁必须执行的所有步骤。

假设 X,Y在不同数据分片。每个数据被放在三个数据中心
和上周的课不用的是,事务协调器又Paxos组构成。
client会选择一个唯一的事务ID来给他所有发送的所有消息打上标记
这样系统就会根据事务id知道该事务所对应的所有这些不同的操作。
根据代码client 首先读取x,再对x进行写入,接着读取y,再对y进行写入。
然而对此事务我们需要重新组织下是为代码,首先它得去执行所有的读操作。
然后再同时去执行所有的写操作,本质上这是提交操作的一部分。
当你每次对一个data item 进行读取或写入负责处理该iterm的服务器得将一把锁和这个data item关联起来。
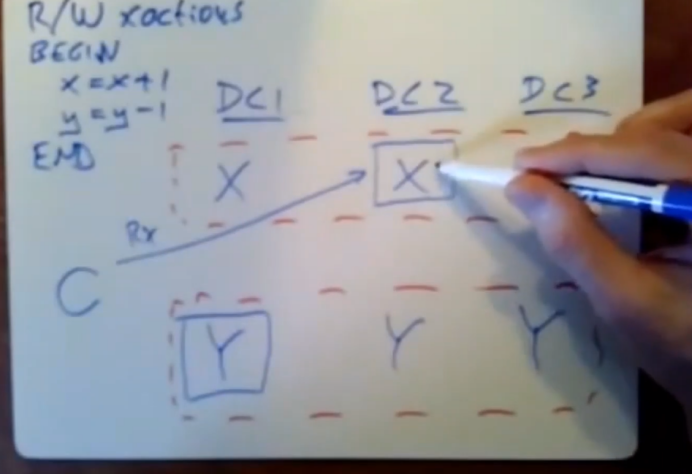
这些锁的类型是读锁,spanner会在paxos组的leader处对这些锁进行维护,当client想执行事务时,即他想去读取x,它会向数据分片x所属的paxos组中的leader发送第一个读请求,该数据分片所在的paxos组中的leader会返回x的当前值,并对x加锁,如果该值已经加锁,那么只有当前持有该数据锁对应的锁的事务提交并释放锁后,我们才能对在这个client进行响应,然后该分片的leader才会将x的值发送给client

client需要去读取y,假设client将读请求发送给数据中心1中的leader,该leader就在client附近的本地数据中心,这样读起来速度就快很多。该paxos组中的leader会对该数据加一个读锁,然后将数据返回给client,现在client已经将所有的读请求发送完毕了
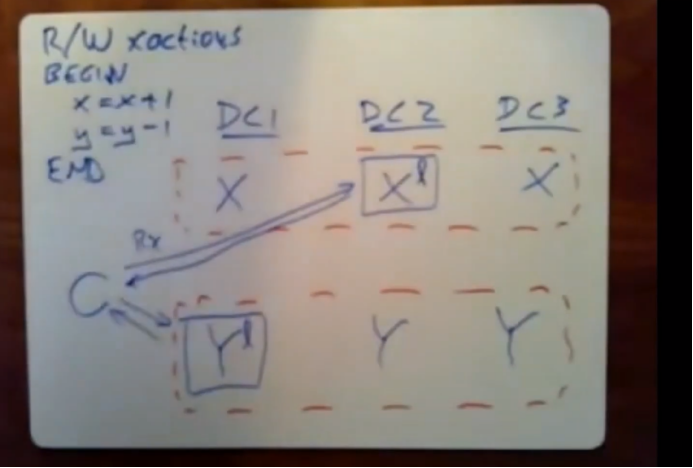
这个client会在内部进行计算,弄清楚相对x和y写入的值是什么。
client现在会将它要对该记录进行更新的值发送给leader。
client会在事务的最后将所有这些写操作一次性提交给paxos组,首先做的事client会选择其中一个paxos组来作为事务协调器使用。他会提前帮我们选出那个作为事务协调器使用的paxos组,他将作为事务协调器使用的那个paxos组的id发送出去,也就是下图中的两个方框的leader
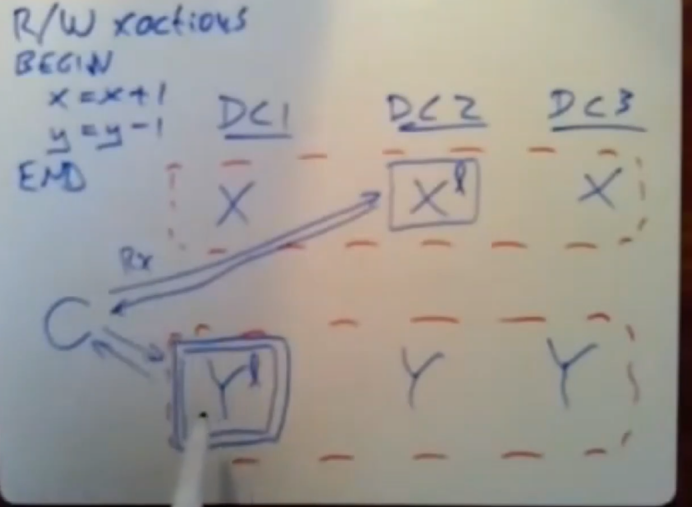
client将他想写入的更新值发送出去,client会发送个一个关于x的写请求给x的leader,
改请求中携带了他想写入的新值,以及该事务协调器的id
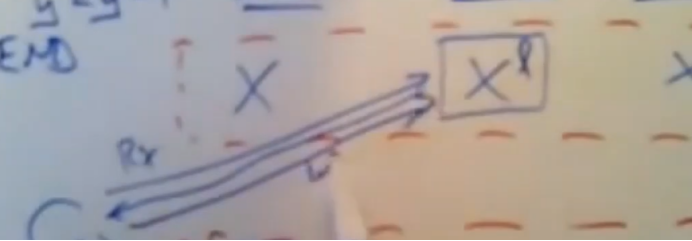
当每个paxos组中的leader收到携带写入值的这个写请求时,它会发送跳prepare消息给他的follower,并将他写入到paxos的日志中,
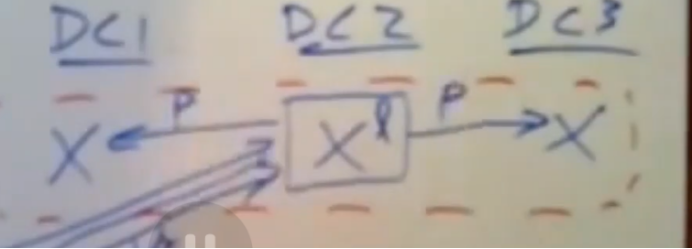
如果他没有发生崩溃和丢失锁的情况下,那么他就会能够去执行这个事务,
leader会将prepare消息发送给该paxos组中的follower,当他收到大多数follower响应后,这个paxos组中的leader就会发送一个yes给这个事务协调器,他会说yes,我能够去执行事务中我负责的这部分任务,并将结果告诉Y(事务协调器),
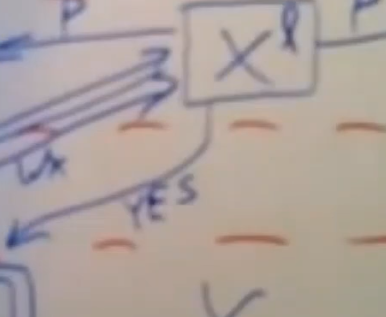
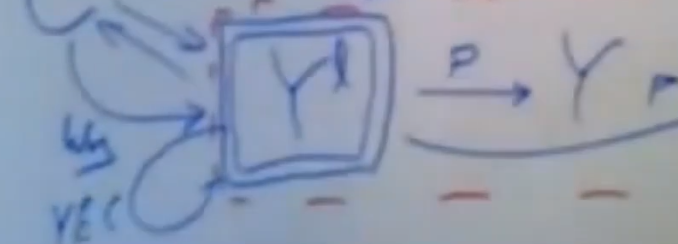
client也会发送一个值给y所属的paxos组中的leader

数据分片Y锁对应的这个paxos leader向与x所使用的同一个事务协调器(可能当下自己这台服务器),发送一个yes,表示可以它去提交事务
当事务协调器收到所有涉及该事务的数据分片所属的paxos组中的leader的响应后,如果他们回复的都是yes,那么事务协调器就会去提这个事务,此时事务协调器发送数据分片Y所属的paxos组中的follower一条commit消息,并说我们正在提交这个事务,请将这个事务落地到日志,
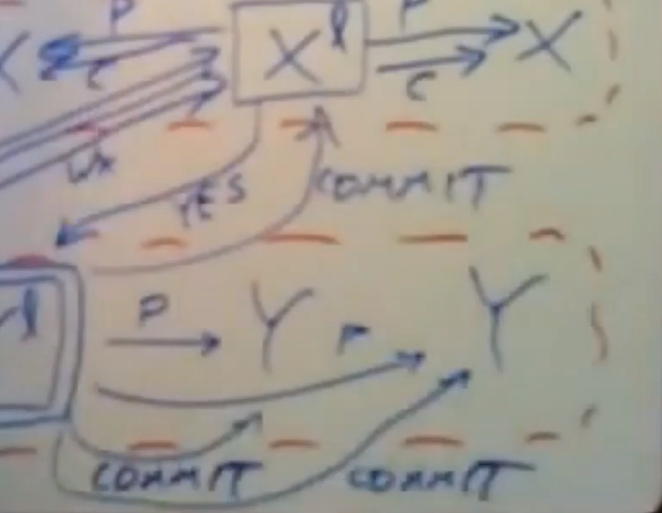
一旦这些commit消息都被提交到了不同数据分片的paxos log日志中,每个数据分片就可以去执行这些写擦操作,将这些数据写入,并释放这些data iterm上的锁,
只读事务要用锁保证正确性,那么其中一个事务可以在对该数据对线进行处理之前,它只能等另一个事务将锁释放。
spanner使用了完全标准的两阶段锁来获取有序性,并且也试用了完全标准的两阶段提交来获得使用分布式事务的能力。
两阶段锁会导致阻塞,影响性能。spnner通过对事务协调器进行复制,解决了这个问题,事务协调器自身基于paxos 的replicacted state machine.
,不管这个事务有没有被提交,他都会被复制到paxos log日志中,如果协调器leader崩溃就会有其他服务器接收,如果事务协调器决定去提交事务,那么他们在他们自己的log日志中就能看到这条commit消息。不管那个服务器接受了协调器leader工作,他就会在它的日志中看到这条提交消息,并能够告诉其他参与者该事务已经被提交。这学校除了两阶段提交所带来的问题:如果事务协调器在持有锁的情况下发生故障导致阻塞的问题,解决这个很重要,这个故障对于很多大型系统都是完全不可接受的。
这种数据分片paxos组之间的消息来往或者离client较远的数据中心的paxos组leader之间的消息来往,可能会花费很多时间。
如果我们能知道事务的操作只有读,那么对于只读事务来说,spanner就能使用速度更快,更加精简,并且不用发送那么多消息的方案。
只读事务的工作方式依赖于读写性事务的一些信息,它的设计和读写性事务中的读操作部分相当不同。在sapnner中,它消除两种在读写型事务中巨大的成本消耗。
①他从本地replica中读取数据,如果你有一个replica,只要该replica是该client一级事务执行所需要的,并且他在本地数据中心,那么你就可以从本地replica中读取数据,话费时间可能不到1毫秒,跨国读取说话时间就是数十毫秒,这里的风险是任何replica都可能提供旧的数据。
②只读事务中并没有使用两阶段锁,他不需要使用事务管理器进行管理,这样就可以避免跨数据中心读取书,即避免将读请求发送给跨数据中心的paxos组leader来处理这个事务。
没有使用锁,可以让只读事务速度更快,也可以避免降低读写型事务的执行速度。
因为他们不需要去等待由只读事务所持有的锁。这改善了10倍之多。降低了复杂性,大大提高吞吐量。
这里的挑战是只读事务所做的事情并不多,不像我们会要求读写型事务的执行要保证有序,我们需要保证正确性的情况下提升效率,他们想在只读事务中主要引入两个正确性约束,
①他们想让所有事务执行依然是有序的,因为要考虑前面是否有读写型事务,前面的读写型事务可能修改只读事务所需要的数据。即使这个系统会同时并行执行很多事务,这些并发事务执行所生成的结果,他们既得将这些结果返回给client,也得将这些修改落地到数据库。
这些并发执行的事务所生成的结果必须和一次或者连续执行这些事务时所得到的的结果一致。这意味着一个只读事务的所有读操作可以看到在它执行之前的那个事务中的所有写操作所执行的结果。它必然无法看到任何在他之后锁执行事务中的任何写操作所执行的结果。
我们需要通过一种方法来将一个夹在两个读写事务之间的只读事务的所有读操作都放在这两个读写事务中间。
paper中所讨论的另一个主要约束就是他们想要获取外部一致性能力等同于线性一致性,意味着当第一个事务结束后,另一个事务就会实时开始执行,那么我们就会要求第二个事务能够看到由第一个事务所做的所有写操作的结果。如果在已完成的事务中有已经提交的写操作存在那么它应该出现在只读事务执行之前我们要求这个只读事务看到这个写操作所做的修改。
我们可以通过配置mysql这样的标准数据库来获得这种一致性,
如果没有这种一致性如下图三个事务执行时间轴
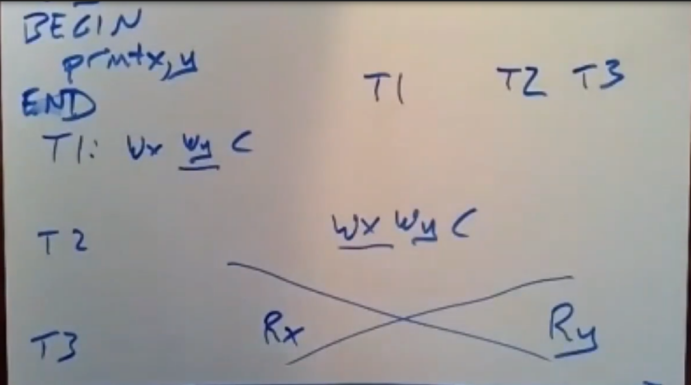
T1 T2 T3是3个事务执行,T3的事务执行可能在T1 和T3之间,拿到的x数据可能是T1修改的y数据是T2修改的,这会产生错误。
假设,我们给每个事务分配一个特定的时间戳,在这个简单的例子,时间戳就是事务提交的时间,对于只读事务,它的时间戳是开始时间。

我们想去设计一个这样的 snapshot ioslation系统,如果所有的事务都是按照时间戳顺序执行,那么它们锁生成的结果都是一样的。
我们会为每个事务分配一个时间戳,按照时间戳的顺序来执行事务,那么就会得到正确性结果
这里的只读事务的工作方式是,当每个replica保存数据时,实际上它保存了该数据的多个版本,
我们有一个多版本的数据库,如果我们队每条数据记录多次写入,它会在每次写入每条记录时,保存该记录的单独副本,他们中的每个副本都是和写入这些副本的事务的时间戳相关联的,
这里的基本策略是当只读事务执行读操作时,当该事务开始执行的时候,它就已经给它自己分配了一个时间戳,当它发送读请求时,他会让读请求携带一个时间戳。不管是哪台服务器保存了该事务所涉及数据的副本,它都会去这个多版本数据库中查看并找到它所要的那条记录,这条记录的时间戳得是最新的时间,但这条记录的时间戳要比该只读事务所执行的时间戳小。这意味着只读事务会根据发起的时间来读取时间戳最新的那个数据,spanner使用这种snapshot isolation的思路来解决只读事务所存在的问题,在读写锁事务方面,spanner依然用两阶段锁和两阶段提交来解决问题。读写型事务会给他们自己分配一个时间戳,这个时间戳就是该事务的提交时间。对于制度事务来说,它会去访问数据库中该数据对象的多个版本,并去获取时间戳最高的那个版本,但这个时间戳要比只读事务的时间戳低。只读事务会看到读写型事务中所有时间戳较老的写操作所做的结果。而不是读写型事务中那些时间戳教新的写操作所做的结果
snapshot isolation 该如何解决我们之前的问题呢?
即内部操作要在符合事务执行顺序的问题
因为那个读取事务读取数据的时间点并不在其他两个读写型事务之间。
这是一个使用snapshot isolation的例子
通过这个例子来展示快照隔离技术是如何解决只读事务的顺序执行问题。
这里我们有两个读写型事务T1、T2、T3

但现在,他们会在提交事务的时候给他们自己分配一个时间戳,此外为了使用二阶段提交和二阶段锁,spanner就给这些读写型事务分配了一个时间戳。在提交事务的时候,T1看了下时间,它发现了提交的时间是10点。T2看到的是20点。当T1还行完它的写操作时,spanner存储系统并不会将旧值用新值覆盖,而是去添加该记录的一个新副本,上面还会携带一个时间戳。数据库回去存储一条新的记录,即它在10点时所保存的x的值为9,记录y在10点时它的值是11。在20点的时候x的值变成了8,y的值变成了12.现在我们就拥有了每条记录在不同时间的两个副本

此时T3要开始执行了。他会在一个时间读取x 然后在很久后才会去读取y的值

当T3开始执行时,他回去根据当前时间来选择一个时间戳,因为我们知道T3实在T1执行完,T2开始执行前这段时间内开始执行的。因此我们就知道了我们得选择10点和20点之间这段时间内作为事务的执行时间。我们假设T3的开始时间时15点,所以我们我们选的时间戳也就是15点,当它要对X进行读取x的时候,他就会将请求发送给持有数据分片x的那个本地replica,它发送这个请求的时候,回让这个请求携带15点这个时间戳,它会说请给我15点时的最新数据,此时T2还没有被执行,但尽管如此,这里我们所能读到的时间戳最高的那个x的副本时由T1在10点时所写入的,我们所读到的x值为9,随着时间的流逝T2也被提交了,现在T3会执行第二次读取操作,即读取y的值,它会让这个读请求携带这个时间戳(15)并发送给服务器,但因为服务器收到T3的时间戳是15,它会去查看它上面保存的记录,并说15是10和20之间,的他回去返回这期间时间戳最高的x和y的记录。所以拿到的还是10点的y。
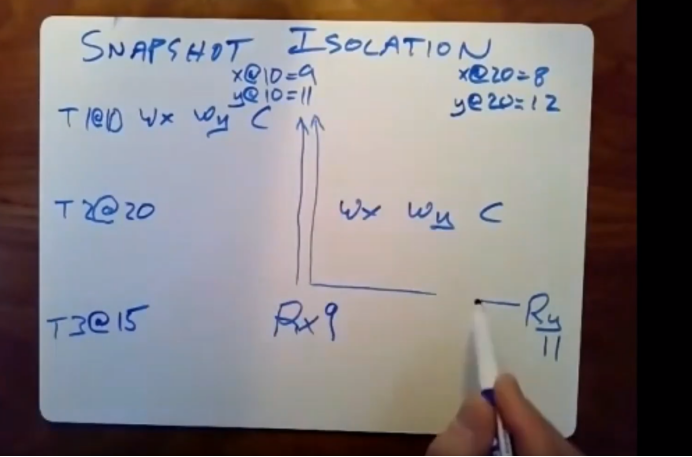
执行顺序T1 T3 T2这个执行顺序所产生的结果和我按照10 15 20这些时间戳顺序所产生的结果是相同的。
有一个问题 ,为什么在T3读取y的旧值是ok的呢?
T3是在这个时间点对Y进行读取的,此时y的最新值是12,但实际上这样T3读到的就是一个过时的值,而不是最新的为什么不适用该数据对象的最新数据是ok的呢
从技术上来讲这样做的理由是T2和T3是并发执行的,他们执行的时候时间上会有重叠。
对于线性一致性和外部一致性来说,他们的规则是如果两个事务并发执行,那么数据库所允许使用的执行顺序可以是任意的,即要么先执行第一个事务,再执行第二个事务,要么先执行第二个事务,再执行第一个事务,此处spanner决定将T3放在T2之前执行。
旧的数据一段时间后会被丢弃。paper中暗示,他们会支持去读取该数据对象不久之前的版本,比如该数据对象昨天的版本,但是他们没有提关于旧值垃圾回收这块的内容。
外部一致性所强加的条件是,如果一个事务已经完成,那么它之后开始执行的这个事务必须看到自己这个事务中所有写操作做的修改。根据外部一致性,我们没有义务让T3看到T2中写操作所做的修改。
T3需要去读取一个特定时间戳所对应的数据,它允许我们从同一个数据中心下所属的本地replica只读取数据。但这个本地的replica可能属于paxos follower中的少数派,即它并没有看到leader所发送给他的最新日志条目,我们所要读取的那个本地replica可能从来没见过对x和y所做的这些写操作,它上面保存的数据依然是5点、6点、7点时的版本,如果我们没做任何聪明的处理的话,当我们要去读取该记录的(15点以前的)最高版本时,我们可能会拿到该数据更古老的版本,实际上这可能并不是T1所产生的结果,也不是我们想要看到的数据,spnner使用了一种叫做安全时间的概念来解决在这个问题。
安全时间的范围时候每个replica会去记录它从它的paxos leader处所收到的日志记录,paper中表明,leader会严格安全时间戳的增加顺序来发送日志条目,replica可以根据它从leader处所拿到最后一个日志记录来进行更新,如果我们要去读取时间戳15所对应的值,但replica只从paxosleader处拿到了时间戳13所对应的日志条目,那么replica就会推迟给我们返回数据。直到它从leader处拿到了时间戳15所对应的日志条目时,它才会对我们进行响应(拿到时间戳大于等于15),这样做就确保了,对于一个给定时间点的请求来说,直到replica从leader哪里知道了该时间点钱所发生的一切事情,它才会对该请求进行响应,这样做可能造成延迟。对于读请求来说,这可能会造成延迟。在这场讨论中我所假设的下一个问题是,所有不同服务器上时钟都是完美同步的。但事实证明,你没法如此精确对时钟进行同步。理由很简单,我们所讨论的时间同步,即我们要确保不同服务器上时钟所读取的是同一个值。
这里要讲的一个常识问题是时间是由政府实验室中那些价格昂贵的高度精准的时钟所定义的,我们没法直接去读取这些值,虽然我们知道这些政府实验室可以通过不同的途径来传播时间,传播这些需要花一定的时间,知道过了一定时间后,我们才知道现在是几点。
因为延迟时间不同,这些服务器会在不同的时间收到这些时间,首先我们要思考的问题是,如果快照隔离的时间并不同步的话,会产生什么影响。
只读事务选择了一个很大的时间戳会怎样?
事务超时
只读事务时间戳过小,会发生什么?
这可能和时钟之前设置就是错的有关,或者说时钟原本设置的时间是正确的,但是时钟走的速度太慢了。因为这是一个多版本数据库,如果你给的时间戳太过久远,比如一小时前,这个版本的数据可能忽略了很多最近对它所做的修改,如果给事务分配的时间戳太小,这会导致我们地市最忌你已经提交落地的写操作,提交可能比较密集,同时只读服务有延迟,这会导致我们读到的数据可能是以前的数据,因为读服务是延迟的,也就说,正常这个读请求如果放在时间正确的服务器中,读到的数据时间戳更大,此时,在延迟服务器中,本应可以读取的最新数据可能就读不到了。这就没有遵守外部一致性。假设这些时钟都是同步的,除非我们做了某些处理,不然,该系统所得出的东西都是不正确的,我们能否让这些时钟完美同步呢?这是我们想要做的理想情况。
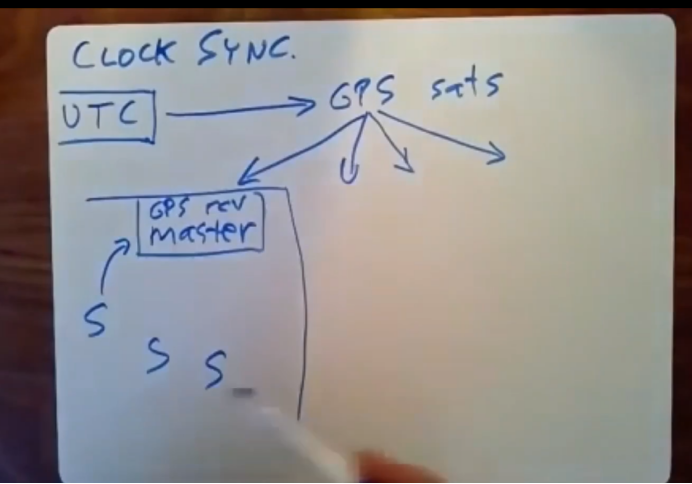
我们所获得时间是政府高精度设备的中间值,我们知道时间等方式是通过各种协议进行的广播,这就是GPS为spanner所做的事情,GPS扮演了雷达广播系统的角色,它把从政府实验室所收到的当前时间通过GPS卫星发送给谷歌机房中的GPS接收器,其中还有很多其他的雷达协议,比如wwb就是另一种比较老的用来广播当前时间的雷达协议,还有一些比较新的协议,比如NTP基于网络的时间协议。政府通过高精度设备定义了世界时间成为UTC,我们从某些实验室中收到了UTC时间,我们通过雷达或者网络将时间广播给Spanner,政府实验室将时间广播给GPS卫星,GPS卫星会将时间广播给数百万GPS接收器,你可以花1、2百美金买一个GPS接收器,它会对GPS信号中的时间戳进行解密,通过修正横幅实验室和GPS卫星间的传播延迟以及GPS卫星和我们当前所在地的传播延迟,来让我们的时间保存最新,在每个数据中心都有一个GPS接收器,他们和paper中提到的time master进行了连接,
其实就是和某台服务器建立了连接,为了避免出现故障,导致不能使用的情况,在每个数据中心里面可能会有多个time master服务器,在每个数据汇总新中会有数百台运行着spanner的服务器,有的是作为spanner server使用,有的是作为spanner client使用,每台服务器会定期向本地time master服务器发送一个询问时间的请求,通常它会向多个time master服务器发送这样的请求,防止其中一个服务器发生故障崩溃
time master 就会对我们进行回复说,我觉得我从GPS卫星那里收到的当前时间是XXX,当然这里还涉及一些不确定的时间误差,我觉得这种误差的主要来源我们不清楚我们距离GPS卫星的距离有多远,雷达信号传播需要一定时间进行传播,即使GPS卫星知道传播所需要的时间是多少,这些信号需要花点时间才能到达我们的GPS接收器处,我们不确定这段时间有多长,这意味着,当我们接受来自GPS卫星所发送来的消息时,它告诉我们的时间是12点,如果传播的时候延迟了数纳秒,这意味着,信号传播时实际的误差要远比传播延迟大得多,我们不清楚我们收到的时间实在12点前还是12点后,我们通过通信所拿到的所有时间都是存在误差的,其中最主要的误差来源是,当一个服务器发送了请求,之后它收到了该请求对应的响应,他返回的正好就是12点,但这里经历了两轮,即服务器发送请求和收到请求的这段时间内,所有服务器都知道,即使time master 处的时间是正确的,所有服务器都知道时间实在12点以内的,因为请求可能是瞬间就发出去了,但time mater的对服务器的响应则被延迟了,或者请求被延迟了1S,响应则是即时的。你所要知道的是误差实在12:00:00和12:00:01之间误差是始终存在的,我们没办法忽略误差,一万我们这里所讨论的误差是在毫秒级的,我们会发现时间上的误差取决于安全等待的持续时间以及提交等待的暂停时间,这种毫秒级误差是严重的问题。另一种主要误差是没爱服务器每个1分钟或者一定时间向time master请求当前时间,在发送请求并等待time master进行响应的这段时间里,每台服务器会运行自己的本地时钟,本地时钟是从time master以获取到的最后一次当前时间处开始走的,在服务器和time master进行通信的时候,本地时钟的时间会发生毫秒级偏移,因此系统必须将本地时钟运行时所产生的这种不确定的时间偏移量添加到时间的不确定性中,为了捕获这种不确定性,并解决它所带来的问题,spanner使用了这种true time 方案,当你询问时间的时候,你实际拿到了是一种叫做TT区间的东西,这个区间是由earliest time 和latest time 所组成,当应用程序通过这个库来查询时间时,当前时间位于合格TT范围内的某一个时间点,在这个例子中earliest time 可能是12:00:00,我们要保证正确时间是不早于earliest time,但也不能比latest time 大,但我们不清楚这个时间是在这个区间哪个位置。当一个事务系统询问系统时间的时候,这实际上就是事务从时间系统那里所得到的东西,让我们回到我们一开始的问题。如果时钟走的过慢,那么这只读事务所读取到的数据对象的版本可能就会太过久远,他不会读取一个最近你已经提交事务所修改后的数据,我们需要知道spanner是如何使用TT区间来消除这种时间上的误差并确保时间正确的。只读事务需要去遵守外部一致性,这保证了只读事务能看到在它之前已经完成的事务中写操作所做的所有修改,这篇paper中谈论了两条规则,一次来做到外部一致性。
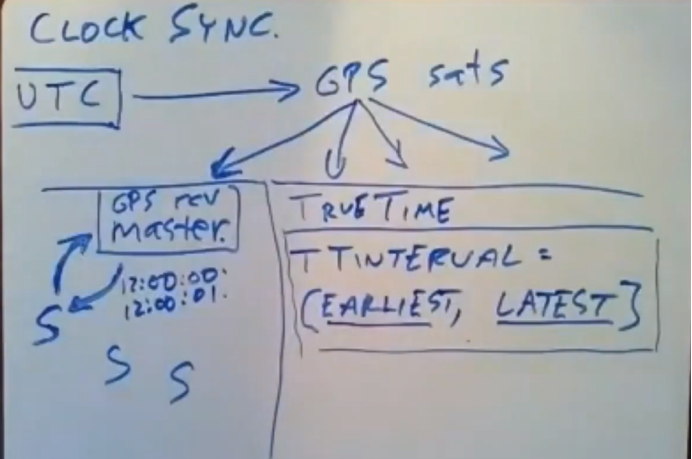
其中一条规则是start rule,另一条规则是commit wait。
start rule 会告诉我们事务所选的时间戳是什么,一个事务所选择的时间戳(TS)等于TTnow().latest ,它得保证这是一个还未发生的时间点,因为true time 实在earliest time和latest time 之间的时间点,对于一个只读事务来说,它的时间戳就是它开始执行时的时间戳,将latest time 设置给它,对于一个读写型事务来说,我们会将latest time 作为它的提交时间戳分配给它。start rule 中表示这就是spanner选择时间戳的方式,commitwait rule 只适用于读写型事务,事务协调器会去收集投票信息,并检查是否能够提交该事务,并未该事务选择一个提交时间戳,当它选完时间戳后,在我实际提交该事务(执行完写操作并释放锁)之前,它需要延迟等待一段时间(因为请求的真实时间介于earlist time 与latest time 之间,我们能确定的是它最晚不会超过latest time,为了保证分布式环境下各个数据分片master的时间协调性,选择latest time 作为提交时间,因为各个数据分片服务器也会找时间标准master服务器获取时间,到达latest时间后再作提交)。
对于一个读写型事务来说,它得等待,直到到达它选择的那个时间戳为止,进行事务提交,这个提交时间戳得小于下一个读事务当前时间的最早开始时间(earliest time,这里可以理解为在这个写事务后万一有个该数据的读事务紧跟着,那其实就是ts的时间戳必须不能在TS。now获取到的时间区间内,也就是它得小于这个TS。now 的earliest time,此处就简单将它译为该数据有紧跟着一个读事务,方便理解)

这里会有一个循环,它在循环里面调用TS.now(),他会在这个循环中进行等待,直到到达开始提交处理选择的时间戳,该时间戳小于下一个读事务当前时间的最早开始时间(earliest time),因为现在,下一个读事务的earliest time 要比该事物的时间戳来的大(这里的它是针对该数据所对应的事务),这意味着,当这个循环结束的时候,当commit wait结束的时候,它绝对保证该事务的时间戳时小于它下一个读事务的earliest time (这里的它是针对与该数据所对应的事务)
系统是如何通过这两条规则对只读事务做到强制外部一致性的?
我们假设每个事务只做一次写操作,假设这里有两个读写型事务T0和T1,他们都对x进行了写入操作。
这里我们还有个事务T2,他要去读取x,因为这里的时间戳上使用了快照隔离,所以我们向确保T2看到最新写入的值,假设T0对X进行了写入操作,即将X的值设置为1,T1对x进行写入操作,并将x设置为2,然后提交事务,我们需要去区分下prepare和commit,

这里T1准备去选择它的时间戳并在之后提交事务,接着我们假设T2实在T1完成后从才开始执行,T2会在之后去读取x,我们向确保它看到的x值为2

假设T0所选择的时间戳时1它在这个时间点将写操作落地到数据库。假设T1开始执行,此时它选择了一个时间戳它从truetime系统那里拿到了一个数字范围(时间范围),而不是一个数字,即earliest time 和latest time,假设此时它选择了时间戳,它所拿到的earliest time的值为1,latest time 的值为10,根据规则来看
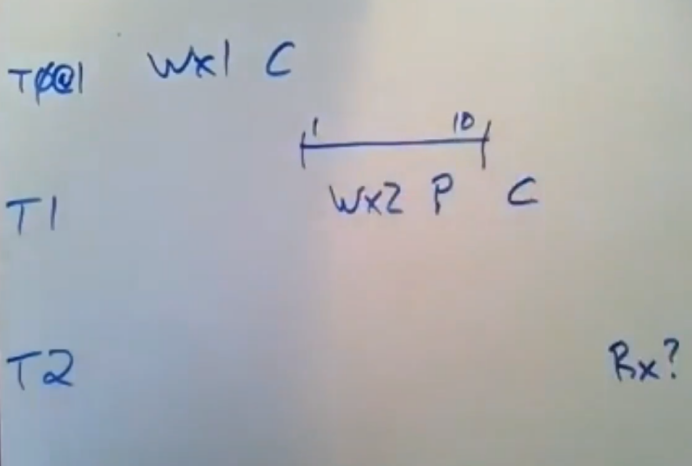
它必须选择latest time 10作为它的时间戳,T1的提交时间就是10,现在我们还不能提交这个事务,因为commit wait规则表示,我们得等到这个时间点才能进行提交,T1会一直去询问时间,直到它所拿到的时间范围里面不包括10为止,在某一个时间点,它回去询问现在几点了,接着它拿到的earliest 为11,latest time 为20,现在我就可以说,我知道我的时间戳(10)肯定是过时的了,我就可以去提交这个事务了。 此处就是T1的commit wait 范围,它在提交事务前,它会在这里等一会儿

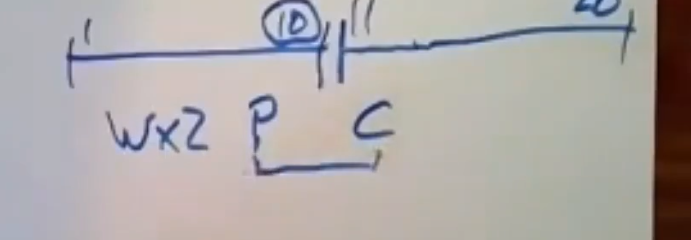
当它提交后,T2想去读取x,他也会去选择一个时间戳,我们假设T2是在T1结束后开始执行的,因为这是我们在外部一致性中所感觉兴趣的一种情况,假设T2是在11点后去询问时间的,它会拿到一个包含时间11的时间范围,假设它所拿到的earliest time 是10,latest time是12

我们知道这个latest time 至少也得是11,因为T2是在T1结束后开始执行的,这意味着,11必然小于latest time,T2会选择12作为它的时间戳。在这个例子中,当T2进行读操作的时候,他回去询问存储系统,并说我想读取时间戳12所对应的版本数据,因为T1提交的时间是10,这意味着这种safe time机制奏效的话,那么我们实际就会读取到正确的值,这里就恰好解决了这个问题,这就保证了当T1在这个时间点提交后,T2就会开始执行,我们队earliest time的值是什么并不清楚,但我们保证该事务的latest time是在当前时间之后,但我们知道当前时间是在T1的提交时间之后,这里保证了T2的latest time(即它所选择的时间戳)是在T1的提交时间之后,因为如果T2在T1结束后开始执行,那么这就保证了T2会获得一个更高的时间戳,快照隔离机制(数据对象会有多个版本) 会导致T2能够看到所有比它时间戳来的低的事务中的所有写操作所做的修改,这意味着T2会看到T所做的修改,这意味着,这就是spanner如果强制让它的事务保持外部一致性的方式了。快照隔离回味我们提供多版本的功能,并给每个事务都分配一个时间戳。快照隔离能够保证只读事务的有序执行,因为简单来讲,快照隔离意味着,我们通过时间戳(等同于执行顺序)和安全等待时间来确保只读事务能够看到他们开始执行前所有读写型事务所做的唏嘘该,并且它无法看到它(只读事务)开始时间之后的读写型事务所做的修改。
这里有两块内容,快照隔离技术不仅是spanner使用它,但一般来讲它无法保证外部一致性。但在分布式系统中会有很多不同的机器去选择时间戳,即使他们做到了线性一致性,我们也无安抚确定这些时间戳会遵守外部一致性,为了使用快照隔离技术,spanner也对你时间戳进行了同步,同步时间戳加上commit wait规则这才允许spanner去保证外部一致性以及线性一致性,这些东西领我们感兴趣的原因在于,因为程序员真的很喜欢事务,并且也很喜欢外部一致性,但是分布式系统中并没有提供这些,因为太慢了,spanner设法让只读事务的执行速度变得非常快,这点非常吸引我们,它里面没有所,也没有二阶段提交,对于一个只读事务来说,他们能够非常高效低从本地的replica中读取数据,而不是从距离他们很远的replica上读取数据,我们从paper中看到,这样做在延迟方面的性能改善了10倍左右,这样的机制只适用于只读事务,读写型事务的使用依然是两阶段提交和锁,因为安全等待时间和commit wait的原因,在很多时候spanner还是会遇上阻塞的情况,但只要他们的时间足够准确那么这些commi wait的时间就会变得相当小。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号