CRAQ是对于一个叫链式复制(Chain Replication)的旧方案的改进。Chain Replication实际上用的还挺多的,有许多现实世界的系统使用了它,CRAQ是对它的改进。CRAQ采用的方式与Zookeeper非常相似,它通过将读请求分发到任意副本去执行,来提升读请求的吞吐量,所以副本的数量与读请求性能成正比。
CRAQ却可以从任意副本执行读请求,同时也保留线性一致性。
首先讨论 Chain Replication 系统
在Chain Replication中,有一些服务器按照链排列。第一个服务器称为HEAD,最后一个被称为TAIL。
当客户端想要发送一个写请求,写请求总是发送给HEAD。
HEAD根据写请求更新本地数据,我们假设现在是一个支持PUT/GET的key-value数据库。所有的服务器本地数据都从A开始。
当HEAD收到了写请求,将本地数据更新成了B,之后会再将写请求通过链向下一个服务器传递。
下一个服务器执行完写请求之后,再将写请求向下一个服务器传递,以此类推,所有的服务器都可以看到写请求
当写请求到达TAIL时,TAIL将回复发送给客户端,表明写请求已经完成了。这是处理写请求的过程。
对于读请求,如果一个客户端想要读数据,它将读请求发往TAIL,TAIL直接根据自己的当前状态来回复读请求。所以,如果当前状态是B,那么TAIL直接返回B。读请求处理的非常的简单。
![]()
Chain Replication本身是线性一致的
TAIL可以看到所有的写请求,也可以看到所有的读请求,它一次只处理一个请求,读请求可以看到最新写入的数据。如果没有出现故障的话,一致性是这么得到保证的,非常的简单。
从一个全局角度来看,除非写请求到达了TAIL,否则一个写请求是不会commit,也不会向客户端回复确认,也不能将数据通过读请求暴露出来。而为了让写请求到达TAIL,它需要经过并被链上的每一个服务器处理。所以我们知道,一旦我们commit一个写请求,一旦向客户端回复确认,一旦将写请求的数据通过读请求暴露出来,那意味着链上的每一个服务器都知道了这个写请求。
Chain Replication的故障恢复
如果HEAD出现故障,作为最接近的服务器,下一个节点可以接手成为新的HEAD,并不需要做任何其他的操作。对于还在处理中的请求,可以分为两种情况:
对于任何已经发送到了第二个节点的写请求,不会因为HEAD故障而停止转发,它会持续转发直到commit。
如果写请求发送到HEAD,在HEAD转发这个写请求之前HEAD就故障了,那么这个写请求必然没有commit,也必然没有人知道这个写请求,我们也必然没有向发送这个写请求的客户端确认这个请求,因为写请求必然没能送到TAIL。所以,对于只送到了HEAD,并且在HEAD将其转发前HEAD就故障了的写请求,我们不必做任何事情。或许客户端会重发这个写请求,但是这并不是我们需要担心的问题。
如果TAIL出现故障,处理流程也非常相似,TAIL的前一个节点可以接手成为新的TAIL。所有TAIL知道的信息,TAIL的前一个节点必然都知道,因为TAIL的所有信息都是其前一个节点告知的。
hain Replication与Raft进行对比,有以下差别:
从性能上看,对于Raft,如果我们有一个Leader和一些Follower。Leader需要直接将数据发送给所有的Follower。所以,当客户端发送了一个写请求给Leader,Leader需要自己将这个请求发送给所有的Follower。然而在Chain Replication中,HEAD只需要将写请求发送到一个其他节点。数据在网络中发送的代价较高,所以Raft Leader的负担会比Chain Replication中HEAD的负担更高。当客户端请求变多时,Raft Leader会到达一个瓶颈,而不能在单位时间内处理更多的请求。而同等条件以下,Chain Replication的HEAD可以在单位时间处理更多的请求,瓶颈会来的更晚一些。
另一个与Raft相比的有趣的差别是,Raft中读请求同样也需要在Raft Leader中处理,所以Raft Leader可以看到所有的请求。而在Chain Replication中,每一个节点都可以看到写请求,但是只有TAIL可以看到读请求。所以负载在一定程度上,在HEAD和TAIL之间分担了,而不是集中在单个Leader节点。
Chain Replication并不能抵御网络分区,也不能抵御脑裂。在实际场景中,这意味它不能单独使用。Chain Replication是一个有用的方案,但是它不是一个完整的复制方案。它在很多场景都有使用,但是会以一种特殊的方式来使用。总是会有一个外部的权威(External Authority)来决定谁是活的,谁挂了,并确保所有参与者都认可由哪些节点组成一条链,这样在链的组成上就不会有分歧。这个外部的权威通常称为Configuration Manager。
Configuration Manager的工作就是监测节点存活性,一旦Configuration Manager认为一个节点挂了,它会生成并送出一个新的配置,在这个新的配置中,描述了链的新的定义,包含了链中所有的节点,HEAD和TAIL。Configuration Manager认为挂了的节点,或许真的挂了也或许没有,但是我们并不关心。因为所有节点都会遵从新的配置内容,所以现在不存在分歧了。
现在只有一个角色(Configuration Manager)在做决定,它不可能否认自己,所以可以解决脑裂的问题。
Configuration Manager通告给所有参与者整个链的信息,所以所有的客户端都知道HEAD在哪,TAIL在哪,所有的服务器也知道自己在链中的前一个节点和后一个节点是什么。现在,单个服务器对于其他服务器状态的判断,完全不重要。假如第二个节点真的挂了,在收到新的配置之前,HEAD需要不停的尝试重发请求。节点自己不允许决定谁是活着的,谁挂了。
不使用Paxos或者Raft,是因为Chain Replication更加的高效,
某些场合可能更适合用Raft或者Paxos,因为它们不用等待一个慢的副本。而当有一个慢的副本时,Chain Replication会有性能的问题,因为每一个写请求需要经过每一个副本,只要有一个副本变慢了,就会使得所有的写请求处理变慢。
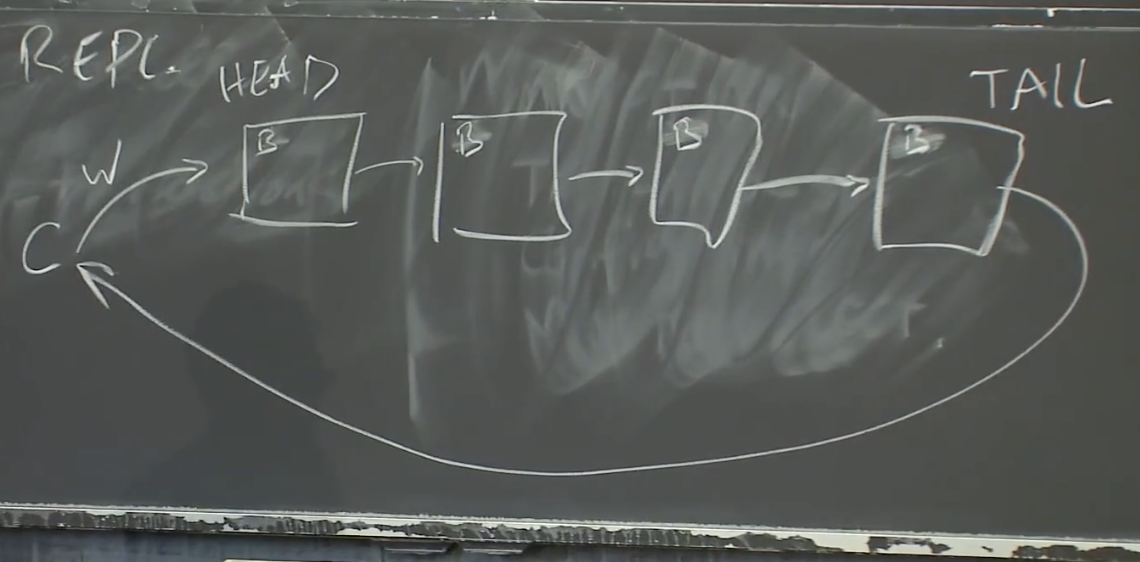


 浙公网安备 33010602011771号
浙公网安备 33010602011771号