6.824 zookeeper 笔记
什么是线性一致性
是一种强一致性的标准,一个系统的执行历史是一系列的客户端请求,或许这是来自多个客户端的多个请求。如果执行历史整体可以按照一个顺序排列,且排列顺序与客户端请求的实际时间相符合,那么它是线性一致的。
线性一致是一个非常以客户端为中心的定义,它表明客户端应该看到怎样的请求顺序。
一个历史记录是不是线性一致的?这里有两种可能。
要么我们能构建一个序列,同时满足
1.序列中的请求的顺序与实际时间匹配
2.每个读请求看到的都是序列中前一个写请求写入的值
例子:https://mit-public-courses-cn-translatio.gitbook.io/mit6-824/lecture-08-zookeeper/8.1
执行历史有闭环不满足,说明客户端看到执行历史不同,不满足线性一致性:
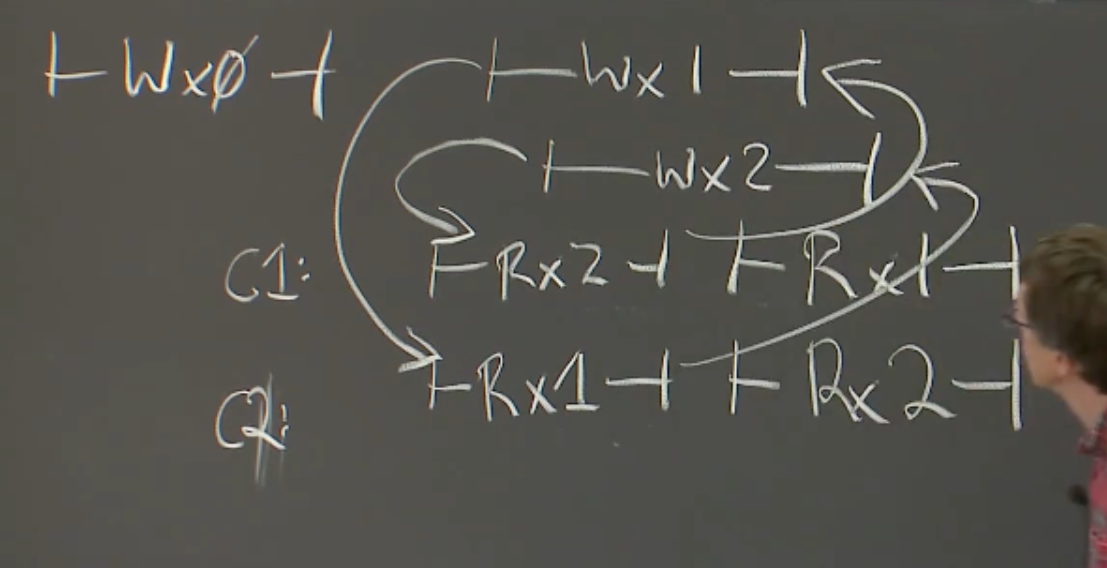
线性一致性系统对于读请求,线性一致系统只能返回最近一次完成的写请求写入的值。
zookeeper是通用的协调服务,提供了配置管理、分布式锁、集群服务等功能。
zookeeper运行于zab 之上,zab是类似于raft的算法。Zab所做的工作是维护用来存放一系列操作的Log,这些操作是从客户端发送过来的,这与Raft非常相似。每个副本都有自己的Log,并且会将新的请求加到Log中。
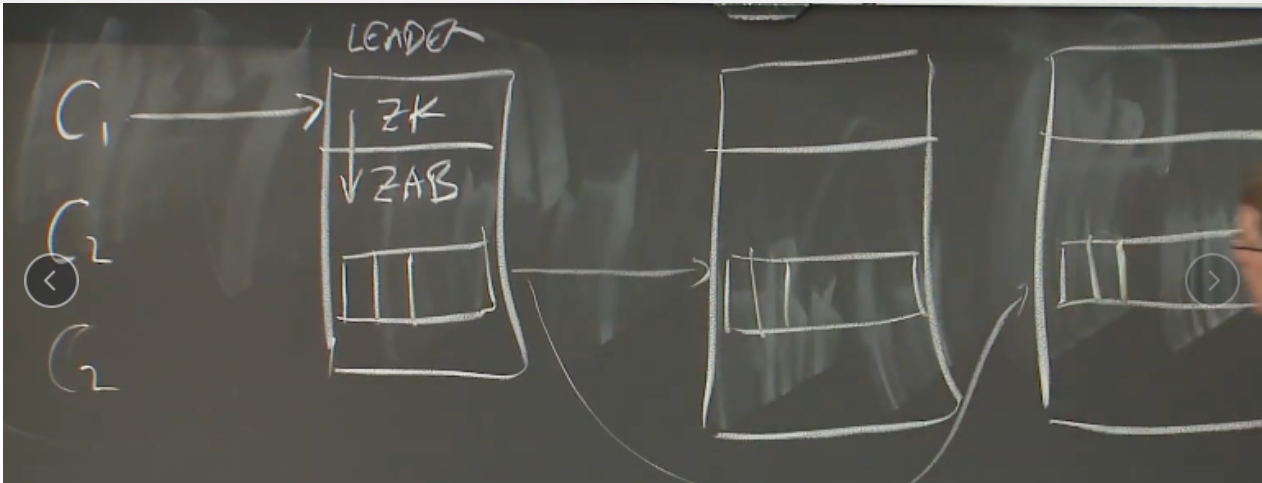
当增加服务器时并不会提高raft集群性能, leader服务器会成为性能瓶颈,甚至由于raft的关系导致变得更慢。
zookeeper 可以通过访问副本服务器来读取数据,这大服务提高了性能,但是这也可能导致客户端读取到旧的数据。
可能返回旧数据的服务值得信任吗?zookeeper对此做了一些保证
写请求是线性一致的
Zookeeper的另一个保证是,任何一个客户端的请求,都会按照客户端指定的顺序来执行,论文里称之为FIFO(First In First Out)客户端序列。也可以理解为对于一个单独客户端的同一个回话而言,读写是线性一致的。
读请求不需要经过Leader,只有写请求经过Leader,读请求只会到达某个副本。所以,读请求只能看到那个副本的Log对应的状态。这个实现的原理是每个Log条目都会被Leader打上zxid的标签,这些标签就是Log对应的条目号。任何时候一个副本回复一个客户端的读请求,首先这个读请求是在Log的某个特定点执行的,其次回复里面会带上zxid,对应的就是Log中执行点的前一条Log条目号。客户端会记住最高的zxid,当客户端发出一个请求到一个相同或者不同的副本时,它会在它的请求中带上这个最高的zxid。这样,其他的副本就知道,应该至少在Log中这个点或者之后执行这个读请求。这里有个有趣的场景,如果第二个副本并没有最新的Log,当它从客户端收到一个请求,客户端说,上一次我的读请求在其他副本Log的这个位置执行,如果这个副本连上了Leader,它会更新上最新的Log,到那个时候,这个副本就可以响应读请求了。好的,所以读请求都是有序的,它们的顺序与时间正相关。
更进一步,FIFO客户端请求序列是对一个客户端的所有读请求,写请求生效。所以,如果我发送一个写请求给Leader,在Leader commit这个请求之前需要消耗一些时间,所以我现在给Leader发了一个写请求,而Leader还没有处理完它,或者commit它。之后,我发送了一个读请求给某个副本。这个读请求需要暂缓一下,以确保FIFO客户端请求序列。读请求需要暂缓,直到这个副本发现之前的写请求已经执行了。这是FIFO客户端请求序列的必然结果,(对于某个特定的客户端)读写请求是线性一致的。
最明显的理解这种行为的方式是,如果一个客户端写了一份数据,例如向Leader发送了一个写请求,之后立即读同一份数据,并将读请求发送给了某一个副本,那么客户端需要看到自己刚刚写入的值。如果我写了某个变量为17,那么我之后读这个变量,返回的不是17,这会很奇怪,这表明系统并没有执行我的请求。因为如果执行了的话,写请求应该在读请求之前执行。所以,副本必然有一些有意思的行为来暂缓客户端,比如当客户端发送一个读请求说,我上一次发送给Leader的写请求对应了zxid是多少,这个副本必须等到自己看到对应zxid的写请求再执行读请求。
弥补非严格一致性的方式,使用sync方法,sync方法相当于先发送一个写请求再发送一个读请求,由于先写入所以我们必然拿到最新状态zxid,那下一个读请求就一定时读到最新状态。
Zookeeper的特点:
Zookeeper基于(类似于)Raft框架,所以我们可以认为它是,当然它的确是容错的,它在发生网络分区的时候,也能有正确的行为
当我们在分析各种Zookeeper的应用时,我们也需要记住Zookeeper有一些性能增强,使得读请求可以在任何副本被处理,因此,可能会返回旧数据。
另一方面,Zookeeper可以确保一次只处理一个写请求,并且所有的副本都能看到一致的写请求顺序。这样,所有副本的状态才能保证是一致的(写请求会改变状态,一致的写请求顺序可以保证状态一致)。
由一个客户端发出的所有读写请求会按照客户端发出的顺序执行。
Zookeeper的目标是解决什么问题,或者期望用来解决什么问题?
-
对于我来说,使用Zookeeper的一个主要原因是,它可以是一个VMware FT所需要的Test-and-Set服务(详见4.7)的实现。Test-and-Set服务在发生主备切换时是必须存在的,但是在VMware FT论文中对它的描述却又像个谜一样,论文里没有介绍:这个服务究竟是什么,它是容错的吗,它能容忍网络分区吗?Zookeeper实际的为我们提供工具来写一个容错的,完全满足VMware FT要求的Test-and-Set服务,并且可以在网络分区时,仍然有正确的行为。这是Zookeeper的核心功能之一。
-
使用Zookeeper还可以做很多其他有用的事情。其中一件是,人们可以用它来发布其他服务器使用的配置信息。例如,向某些Worker节点发布当前Master的IP地址。
-
另一个Zookeeper的经典应用是选举Master。当一个旧的Master节点故障时,哪怕说出现了网络分区,我们需要让所有的节点都认可同一个新的Master节点。
-
如果新选举的Master需要将其状态保持到最新,比如说GFS的Master需要存储对于一个特定的Chunk的Primary节点在哪,现在GFS的Master节点可以将其存储在Zookeeper中,并且知道Zookeeper不会丢失这个信息。当旧的Master崩溃了,一个新的Master被选出来替代旧的Master,这个新的Master可以直接从Zookeeper中读出旧Master的状态。
-
其他还有,对于一个类似于MapReduce的系统,Worker节点可以通过在Zookeeper中创建小文件来注册自己。Zookeeper的API某种程度上来说像是一个文件系统。它有一个层级化的目录结构,有一个根目录(root),之后每个应用程序有自己的子目录。比如说应用程序1将自己的文件保存在APP1目录下,应用程序2将自己的文件保存在APP2目录下,这些目录又可以包含文件和其他的目录。
这里的文件和目录都被称为znodes。Zookeeper中包含了3种类型的znode,了解他们对于解决问题会有帮助。
-
1.第一种Regular znodes。这种znode一旦创建,就永久存在,除非你删除了它。
-
2.第二种是Ephemeral znodes。如果Zookeeper认为创建它的客户端挂了,它会删除这种类型的znodes。这种类型的znodes与客户端会话绑定在一起,所以客户端需要时不时的发送心跳给Zookeeper,告诉Zookeeper自己还活着,这样Zookeeper才不会删除客户端对应的ephemeral znodes。
-
3.最后一种类型是Sequential znodes。它的意思是,当你想要以特定的名字创建一个文件,Zookeeper实际上创建的文件名是你指定的文件名再加上一个数字。当有多个客户端同时创建Sequential文件时,Zookeeper会确保这里的数字不重合,同时也会确保这里的数字总是递增的。Zookeeper以RPC的方式暴露以下API。
-
CREATE(PATH,DATA,FLAG)。入参分别是文件的全路径名PATH,数据DATA,和表明znode类型的FLAG。这里有意思的是,CREATE的语义是排他的。也就是说,如果我向Zookeeper请求创建一个文件,如果我得到了yes的返回,那么说明这个文件之前不存在,我是第一个创建这个文件的客户端;如果我得到了no或者一个错误的返回,那么说明这个文件之前已经存在了。所以,客户端知道文件的创建是排他的。在后面有关锁的例子中,我们会看到,如果有多个客户端同时创建同一个文件,实际成功创建文件(获得了锁)的那个客户端是可以通过CREATE的返回知道的。
-
DELETE(PATH,VERSION)。入参分别是文件的全路径名PATH,和版本号VERSION。有一件事情我之前没有提到,每一个znode都有一个表示当前版本号的version,当znode有更新时,version也会随之增加。对于delete和一些其他的update操作,你可以增加一个version参数,表明当且仅当znode的当前版本号与传入的version相同,才执行操作。当存在多个客户端同时要做相同的操作时,这里的参数version会非常有帮助(并发操作不会被覆盖)。所以,对于delete,你可以传入一个version表明,只有当znode版本匹配时才删除。
-
EXIST(PATH,WATCH)。入参分别是文件的全路径名PATH,和一个有趣的额外参数WATCH。通过指定watch,你可以监听对应文件的变化。不论文件是否存在,你都可以设置watch为true,这样Zookeeper可以确保如果文件有任何变更,例如创建,删除,修改,都会通知到客户端。此外,判断文件是否存在和watch文件的变化,在Zookeeper内是原子操作。所以,当调用exist并传入watch为true时,不可能在Zookeeper实际判断文件是否存在,和建立watch通道之间,插入任何的创建文件的操作,这对于正确性来说非常重要。
-
GETDATA(PATH,WATCH)。入参分别是文件的全路径名PATH,和WATCH标志位。这里的watch监听的是文件的内容的变化。
-
SETDATA(PATH,DATA,VERSION)。入参分别是文件的全路径名PATH,数据DATA,和版本号VERSION。如果你传入了version,那么Zookeeper当且仅当文件的版本号与传入的version一致时,才会更新文件。
-
LIST(PATH)
-
zookeeper实现计数器
WHILE TRUE:
X, V = GETDATA("F")
IF SETDATA("f", X + 1, V):
BREAK
zookeeper实现锁
WHILE TRUE:
IF CREATE("f", data, ephemeral=TRUE): RETURN
IF EXIST("f", watch=TRUE):
WAIT
这里的锁设计并不是一个好的设计,因为它和前一个计数器的例子都受羊群效应(Herd Effect)的影响。所谓的羊群效应,对于计数器的例子来说,就是当有1000个客户端同时需要增加计数器时,我们的复杂度是
O(n2)O(n^2)O(n2)
,这是处理完1000个客户端的请求所需要的总时间。对于这一节的锁来说,也存在羊群效应,如果有1000个客户端同时要获得锁文件,为1000个客户端分发锁所需要的时间也是
O(n2)O(n^2)O(n2)
。因为每一次锁文件的释放,所有剩下的客户端都会收到WATCH的通知,并且回到循环的开始,再次尝试创建锁文件。所以CREATE对应的RPC总数与1000的平方成正比。所以这一节的例子也受羊群效应的影响,像羊群一样的客户端都阻塞在Zookeeper这。这一节实现的锁有另一个名字:非扩展锁(Non-Scalable Lock)。它对应的问题是真实存在的,我们会在其他系统中再次看到。zookeeper实现锁
CREATE("f", data, sequential=TRUE, ephemeral=TRUE)
WHILE TRUE:
LIST("f*")
IF NO LOWER #FILE: RETURN
IF EXIST(NEXT LOWER #FILE, watch=TRUE):
WAIT
在代码的第1行调用CREATE,并指定sequential=TRUE,我们创建了一个Sequential文件,如果这是以“f”开头的第27个Sequential文件,这里实际会创建类似以“f27”为名字的文件。这里有两点需要注意,第一是通过CREATE,我们获得了一个全局唯一序列号(比如27),第二Zookeeper生成的序号必然是递增的。
代码第3行,通过LIST列出了所有以“f”开头的文件,也就是所有的Sequential文件。
代码第4行,如果现存的Sequential文件的序列号都不小于我们在代码第1行得到的序列号,那么表明我们在并发竞争中赢了,我们获得了锁。所以当我们的Sequential文件对应的序列号在所有序列号中最小时,我们获得了锁,直接RETURN。序列号代表了不同客户端创建Sequential文件的顺序。在这种锁方案中,会使用这个顺序来向客户端分发锁。当存在更低序列号的Sequential文件时,我们要做的是等待拥有更低序列号的客户端释放锁。在这个方案中,释放锁的方式是删除文件。所以接下来,我们需要做的是等待序列号更低的锁文件删除,之后我们才能获得锁。
为什么重试的时候要在代码第3行再次LIST文件?
Robert教授:这是个好问题。问题是,我们在代码第3行得到了文件的列表,我们就知道了比自己序列号更小的下一个锁文件。Zookeeper可以确保,一旦一个序列号,比如说27,被使用了,那么之后创建的Sequential文件不会使用更小的序列号。所以,我们可以确定第一次LIST之后,不会有序列号低于27的锁文件被创建,那为什么在重试的时候要再次LIST文件?为什么不直接跳过?你们来猜猜答案。
答案是,持有更低序列号Sequential文件的客户端,可能在我们没有注意的时候就释放了锁,也可能已经挂了。比如说,我们是排在第27的客户端,但是排在第26的客户端在它获得锁之前就挂了。因为它挂了,Zookeeper会自动的删除它的锁文件(因为创建锁文件时,同时也指定了ephemeral=TRUE)。所以这时,我们要等待的是序列号25的锁文件释放。所以,尽管不可能再创建序列号更小的锁文件,但是排在前面的锁文件可能会有变化,所以我们需要在循环的最开始再次调用LIST,以防在等待锁的队列里排在我们前面的客户端挂了。
学生提问:如果不存在序列号更低的锁文件,那么当前客户端就获得了锁?
Robert教授:是的。
学生提问:为什么这种锁不会受羊群效应(Herd Effect)的影响?
Robert教授:假设我们有1000个客户端在等待获取锁,每个客户端都会在代码的第6行等待锁释放。但是每个客户端等待的锁文件都不一样,比如序列号为500的锁只会被序列号为501的客户端等待,而序列号500的客户端只会等待序列号499的锁文件。每个客户端只会等待一个锁文件,当一个锁文件被释放,只有下一个序列号对应的客户端才会收到通知,也只有这一个客户端会回到循环的开始,也就是代码的第3行,之后这个客户端会获得锁。所以,不管有多少个客户端在等待锁,每一次锁释放再被其他客户端获取的代价是一个常数。而在非扩展锁中,锁释放时,每个等待的客户端都会被通知到,之后,每个等待的客户端都会发送CREATE请求给Zookeeper,所以每一次锁释放再被其他客户端获取的代价与客户端数量成正比。
学生提问:那排在后面的客户端岂不是要等待很长的时间?
Robert教授:你可以去喝杯咖啡等一等。编程接口不是我们关心的内容,不过代码第6行的等待有两种可能,第一种是启动一个线程同步等待锁,在获得锁之前线程不会继续执行;第二种会更加复杂一些,你向Zookeeper发送请求,但是不等待其返回,同时有另外一个goroutine等待Zookeeper的返回,这跟前面介绍的AppCh(Apply Channel,详见6.6)一样,第二种方式更加常见。所以要么是多线程,要么是事件驱动,不管怎样,代码在等待的时候可以执行其他的动作。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号