python同步原语--线程锁
多线程锁是python多种同步原语中的其中一种。首先解析一下什么是同步原语,python因为GIL(全局解析锁)的缘故,并没有真正的多线性。另外python的多线程存在一个问题,在多线程编程时,会出现线程同时调用共同的存储空间而导致错误的出现(即‘竞态行为’)。虽然许多专家建议python开发者在处理并发的时候弃用多线程而用多进程,但是在I/O操作这种短时间的操作上(通常GIL锁在这段时间内已经释放),多线程编程还是有很大的优势的。而在计算密集型的编程时,本人还是觉得用多进程比较稳妥。
在处理多线程的‘竞态行为’的问题上,python提供了不少解决的方法--同步原语,例如:锁,事件,信号量等。
所以问题回归到锁添加的原因和加锁的优势:
在多线程同时进入临界资源区获取和操作共有资源时,会出现资源的争夺而出现混乱。为了避免这种混乱现象,python提出了锁机制,能够实现多线程程序的同步执行,从而避免因争夺资源而出现错误。
线程锁的定义和运用
一、创建锁对象:
语法:
lock = Lock()
锁对象一旦创建,就可以随时被进程或者线程调用,并且一次创建锁只有一把,如果多个资源想同时获取锁,必须‘排队’,等上一个进程/线程释放了锁才可以请求获取锁
二、上锁(也叫请求锁)
语法:
lock.acquire()
acquire()是一个阻塞函数。一旦请求获取锁成功,就会把下面将要执行的程序的变量内存空间‘锁住’;而获取不成功则会一直阻塞在那里,等待上一个获得锁的进程/线程
释放锁。
三、解锁
lock.release()
锁的创建、获取和释放其实很简单,而在实际运用中还需要处理一些比较复杂的问题。下面谈谈死锁的问题。
死锁和可重入锁
死锁的出现有两种情况:
1) 当一个进程或者一个线程一直调用或者占用同一锁Lock而不释放资源而导致其他进程/线程无法获得锁,就会出现的死锁状况,一直阻塞在aquire()处
2) 当有两个线程同时想获取两个锁的时候(再往上推就是多个线程想获取多个锁甚至是一个线程想获取多个锁),例如递归函数(一个线程获取多个锁)的使用。由于两者都是处于竞争关系,谁也不让谁,谁快谁得手,但计算机中这种竞争关系是很微妙的,时间的差异性很小,于是,就出现了两者都阻塞在同一个地方,都无法同时获得两个锁或者获取对方已经获取的但还没有释放的锁。
为了解决死锁的问题,于是python提出了可重入锁的机制(RLock)
重入锁定义后,一个进程就可以重复调用指定次数的一个重入锁,而不用去跟别的进程一起争夺其他锁。
重入锁中内部管理者两个对象,即Lock对象和锁的调用次数count
下面说说RLock到底是怎么用的
1)RLock的定义
mutexA = mutexB = RLock( )
mutex值可以是多个的,定义了多少个,RLock内部的count就为几
2)RLock的请求
mutexA.acquire()
mutexA.acquire()
上面这两行代码看似是一样的,但其实是两次请求锁。每申请一次锁,Rlock内部的count就会减小1,两次请求过后,count从2减为0
因为上面定义的重入锁的内部个数为2,所以该重入锁可以被一个进程调用两次,并且在虽然它内部有多个锁,但只能由一个进程/线程调用,其他进程/线程不能干预,只有当这个进程/线程释放掉所有的重入锁,count重新变为count=2时才可以被其他进程/线程调用。
3)RLock锁的释放
mutexA.release()
mutexB.release()
完整代码举例:
from multiprocessing import RLock,Process
from time import ctime,sleep
mutexA = mutexB =RLock() #定义可重入锁,内部有两个锁,即mutexA和mutexB
def fn1():
mutexA.acquire()
sleep(1)
print(ctime(),'进程1获取A锁')
mutexB.acquire()
sleep(2)
print(ctime(),'进程1获取B锁')
mutexA.release()
print('进程1释放A锁')
mutexB.release()
print('进程1释放B锁')
def fn2():
mutexA.acquire()
sleep(1)
print(ctime(),'进程2获取A锁')
mutexB.acquire()
sleep(1)
print(ctime(),'进程2获取B锁')
mutexA.release()
print('进程2释放A锁')
mutexB.release()
print('进程2释放B锁')
p1 = Process(target=fn1) #定义进程1
p2 = Process(target=fn2) #定义进程2
p1.start() #开启进程1
p2.start() #开启进程2
p1.join() #回收进程空间
p2.join()
注意:在实际开发中我们当然不会用sleep()这种方法来实现等待程序的执行(这是很愚蠢的一种行为),在这里只是作为一种演示,为了把逻辑比较清晰地表达出来。实际开发中通常是在成功执行一段程序,在获取预定的结果之后,再手动地释放锁。
那么上面的程序运行结果如下:
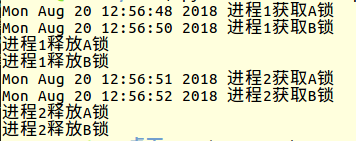
那么如果我让进程2先开启呢?
结果如下:
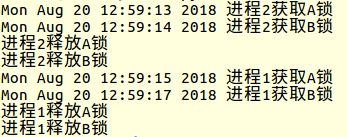
第一个案例中因为p1的进程比p2的进程更早运行(程序在运行顺序上更早),所以p1先获取了可重入锁。而在案例2中,p2就比p1更早地获取可重入锁了。
显然,从这两个案例中我们发现,锁的获得是谁快谁得手。同时也验证了我上面描述的,一个进程对一个可重入锁的请求是排他型的,一旦这个进程请求了
一个可重入锁,那么其他进程就无法再请求了,直到这个进程释放了可重入锁内部的所有锁。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号