要我说,多线程事务它必须就是个伪命题!
这是why技术的第 74 篇原创文章

别问,问就是不行
分布式事务你应该是知道的。但是这个多线程事务......
没事,我慢慢给你说。

如图所示,有个小伙伴想要实现多线程事务。
这个需求其实我在不同的地方看到过很多次,所以我才说:这个问题又出现了。
那么有解决方案吗?
在此之前,我的回答都是非常的肯定:毋庸置疑,肯定是没有的。

为什么呢?
我们先从理论上去推理一下。
来,首先我问你,事务的特性是什么?
这个不难吧?八股文必背内容之一,ACID 必须张口就来:
原子性(Atomicity) 一致性(Consistency) 隔离性(Isolation) 持久性(Durability)
那么问题又来了,你觉得如果有多线程事务,那么我们破坏了哪个特性?
多线程事务你也别想的多深奥,你就想,两个不同的用户各自发起了一个下单请求,这个请求对应的后台实现逻辑中是有事务存在的。
这不就是多线程事务吗?
这种场景下你没有想过怎么分别去控制两个用户的事务操作吧?
因为这两个操作之间就是完全隔离的,各自拿着各自的链接玩儿。
所以多个事务之间的最基本的原则是什么?
隔离性。两个事务操作之间不应该相互干扰。
而多线程事务想要实现的是 A 线程异常了。A,B 线程的事务一起回滚。

事务的特性里面就卡的死死的。所以,多线程事务从理论上就是行不通的。
通过理论指导实践,那么多线程事务的代码也就是写不出来的。
前面说到隔离性。那么请问,Spring 的源码里面,对于事务的隔离性是如何保证的呢?
答案就是 ThreadLocal。
在事务开启的时候,把当前的链接保存在了 ThreadLocal 里面,从而保证了多线程之间的隔离性:
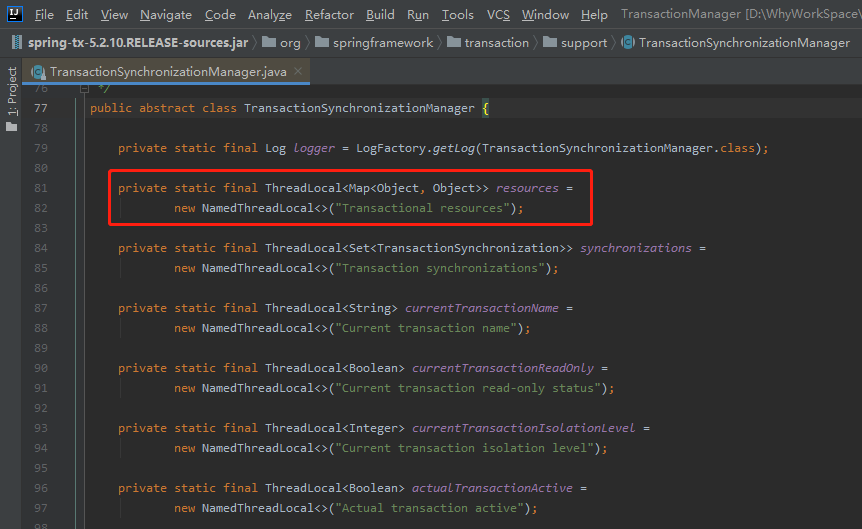
可以看到,这个 resource 对象是一个 ThreadLocal 对象。
在下面这个方法中进行了赋值操作:
org.springframework.jdbc.datasource.DataSourceTransactionManager#doBegin

其中的 bindResource 方法中,就是把当前链接绑定到当前线程中,其中的 resource 就是我们刚刚说的 ThreadLocal:
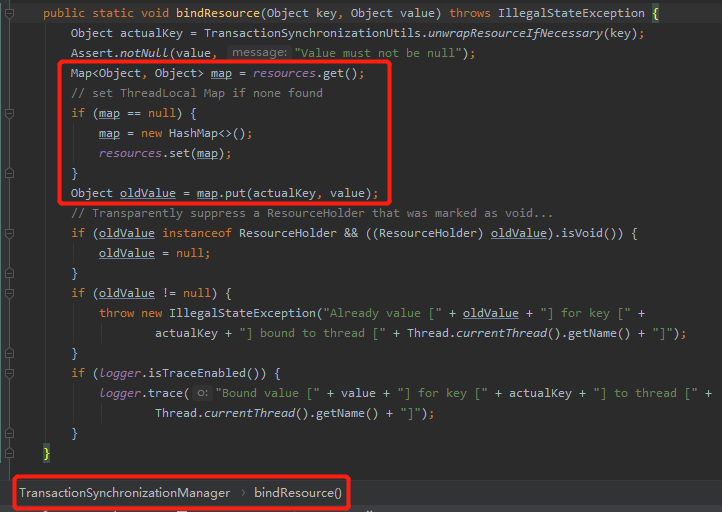
就是每个线程里面都各自玩自己的,我们不可能打破 ThreadLocal 的使用规则,让各个线程共享同一个 ThreadLocal 吧?
铁子,你要是这样去做的话,那岂不是走远了?
所以,无论从理论上,还是代码实现上,我都认为这个需求是不能实现的。
至少我之前是这样想的。
但是事情,稍稍的发生了一点点的变化。

说个场景,常规实现
任何脱离场景讨论技术实现的行为都是耍流氓。
所以,我们先看一下场景是什么。
假设我们有一个大数据系统,每天指定时间,我们就需要从大数据系统中拉取 50w 条数据,对数据进行一个清洗操作,然后把数据保存到我们业务系统的数据库中。
对于业务系统而言,这 50w 条数据,必须全部落库,差一条都不行。要么就是一条都不插入。
在这个过程中,不会去调用其他的外部接口,也不会有其他的流程去操作这个表的数据。
既然说到一条不差了,那么对于大家直观而言,想到的肯定是两个解决方案:
for 循环中一条条的事务插入。 直接一条语句批量插入。
对于这种需求,开启事务,然后在 for 循环中一条条的插入可以说是非常 low 的解决方案了。
效率非常的低下,给大家演示一下。
比如,我们有一个 Student 表,表结构非常简单,如下:
CREATE TABLE `student` (
`id` bigint(63) NOT NULL AUTO_INCREMENT,
`name` varchar(32) DEFAULT NULL,
`home` varchar(64) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
在我们的项目中,我们通过 for 循环插入数据,同时该方法上有 @Transactional 注解:
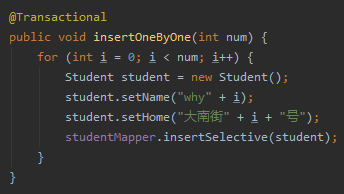
num 参数是我们通过前端请求传递过来的数据,代表要插入 num 条数据:
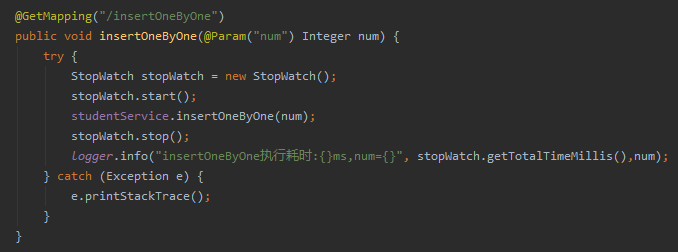
这种情况下,我们可以通过下面的链接,模拟插入指定数量的数据:
http://127.0.0.1:8081/insertOneByOne?num=xxx
我尝试了把 num 设置为 50w,让它慢慢的跑着,但是我还是太年轻了,等了非常长的时间都没有等到结果。
于是我把 num 改为了 5000,运行结果如下:
insertOneByOne执行耗时:133449ms,num=5000
一条条的插入 5000 条数据,耗时 133.5 s 的样子。
按照这个速度,插入 50w 条数据得 13350s,大概也是这么多小时:

这谁顶得住啊。
所以,这方案拥有巨大的优化空间。
比如我们优化为这样批量插入:
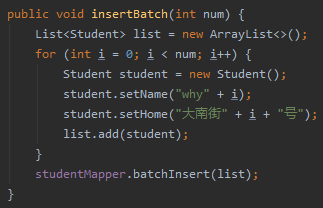
其对应的 sql 语句是这样的:
insert into table ([列名],[列名]) VALUES ([列值],[列值]), ([列值],[列值]);
我们还是通过前端接口调用:
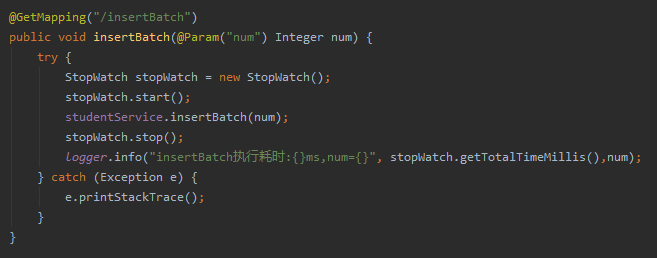
当我们的 num 设置为 5000 的时候,我页面刷新了 10 次,你看耗时基本上在 200ms 毫秒以内:

从 133.5s 到 200ms,朋友们,这是什么东西?
这是质的飞跃啊。性能提升了近 667 倍的样子。

为什么批量插入能有这么大的飞跃呢?
你想啊,之前 for 循环插入,虽然 SpringBoot 2.0 默认使用了 HikariPool,连接池里面默认给你搞 10 个连接。
但是你只需要一个连接,开启一次事务。这个不耗时。
耗时的地方是你 5000 次 IO 呀。
所以,耗时长是必然的。
而批量插入只是一条 sql 语句,所以只需要一个连接,还不需要开启事务。
为啥不用开启事务?
你一条 sql 开启事务有锤子用啊?
那么,如果我们一口气插入 50w 条数据,会是怎么样的呢?
来,搞一波,试一下:
http://127.0.0.1:8081/insertBatch?num=500000

可以看到抛出了一个异常。而且错误信息非常的清晰:
Packet for query is too large (42777840 > 1048576). You can change this value on the server by setting the max_allowed_packet' variable.; nested exception is com.mysql.jdbc.PacketTooBigException: Packet for query is too large (42777840 > 1048576).You can change this value on the server by setting the max_allowed_packet' variable.
说你这个包太大了。可以通过设置 max_allowed_packet 来改变包大小。
我们可以通过下面的语句查询当前的配置大小:
select @@max_allowed_packet;
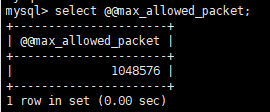
可以看到是 1048576,即 1024*1024,1M 大小。
而我们需要传输的包大小是 42777840 字节,大概是 41M 的样子。
所以我们需要修改配置大小。
这个地方也给大家提了个醒:如果你的 sql 语句非常大,里面有大字段,记得调整一下 mysql 的这个参数。
可以通过修改配置文件或者直接执行 sql 语句的方式进行修改。
我这里就使用 sql 语句修改为 64M:
set global max_allowed_packet = 1024*1024*64;
然后再次执行,可以看到插入成功了:
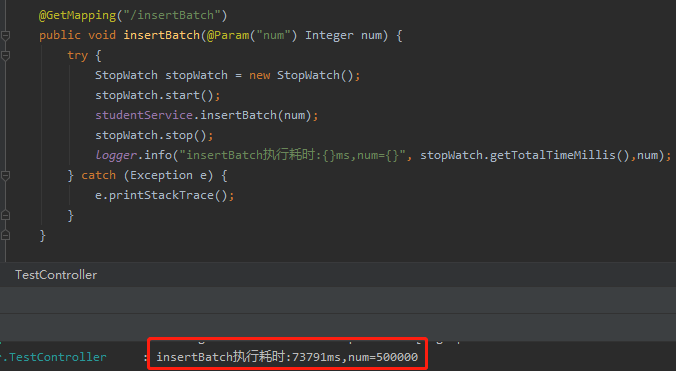
50w 的数据,74s 的样子。
数据要么全部提交,要么一条也没有,需求也实现了。
时间上呢,是有点长,但是好像也想不到什么好的提升方案。
那么我们怎么还能再缩短点时间呢?

骚想法出现了
我能想到的,只能是祭出多线程了。
50w 数据。我们开五个线程,一个线程处理 10w 数据,没有异常就保存入库,出现问题就回滚。
这个需求很好实现。分分钟就能写出来。
但是再加上一个需求:这 5 个线程的数据,如果有一个线程出现问题了,需要全部回滚。
顺着思路慢慢撸,我们发现这个时候就是所谓的多线程事务了。

我之前说完全不可能实现是因为提到事务我就想到了 @Transactional 注解去实现了。
我们只需要正确使用它,然后关系业务逻辑即可,不需要也根本插手不了事务的开启和提交或者回滚。
这种代码的写法我们叫做声明式事务。
和声明式事务对应的就是编程式事务了。
通过编程式事务,我们就能完全掌控事务的开启和提交或者回滚操作。
能想到编程式事务,这事基本上就成了一半了。
你想,首先我们有一个全局变量为 Boolean 类型,默认为可以提交。
在子线程里面,我们可以先通过编程式事务开启事务,然后插入 10w 条数据后,但是不提交。同时告诉主线程,我这边准备好了,进入等待。
如果子线程里面出现了异常,那么我就告诉主线程,我这边出问题了,然后自己进行回滚。
最后主线程收集到了 5 个子线程的状态。
如果有一个线程出现了问题,那么设置全局变量为不可提交。
然后唤醒所有等待的子线程,进行回滚。
根据上面的流程,写出模拟代码就是这样的,大家可以直接复制出来运行:
public class MainTest {
//是否可以提交
public static volatile boolean IS_OK = true;
public static void main(String[] args) {
//子线程等待主线程通知
CountDownLatch mainMonitor = new CountDownLatch(1);
int threadCount = 5;
CountDownLatch childMonitor = new CountDownLatch(threadCount);
//子线程运行结果
List<Boolean> childResponse = new ArrayList<Boolean>();
ExecutorService executor = Executors.newCachedThreadPool();
for (int i = 0; i < threadCount; i++) {
int finalI = i;
executor.execute(() -> {
try {
System.out.println(Thread.currentThread().getName() + ":开始执行");
// if (finalI == 4) {
// throw new Exception("出现异常");
// }
TimeUnit.MILLISECONDS.sleep(ThreadLocalRandom.current().nextInt(1000));
childResponse.add(Boolean.TRUE);
childMonitor.countDown();
System.out.println(Thread.currentThread().getName() + ":准备就绪,等待其他线程结果,判断是否事务提交");
mainMonitor.await();
if (IS_OK) {
System.out.println(Thread.currentThread().getName() + ":事务提交");
} else {
System.out.println(Thread.currentThread().getName() + ":事务回滚");
}
} catch (Exception e) {
childResponse.add(Boolean.FALSE);
childMonitor.countDown();
System.out.println(Thread.currentThread().getName() + ":出现异常,开始事务回滚");
}
});
}
//主线程等待所有子线程执行response
try {
childMonitor.await();
for (Boolean resp : childResponse) {
if (!resp) {
//如果有一个子线程执行失败了,则改变mainResult,让所有子线程回滚
System.out.println(Thread.currentThread().getName()+":有线程执行失败,标志位设置为false");
IS_OK = false;
break;
}
}
//主线程获取结果成功,让子线程开始根据主线程的结果执行(提交或回滚)
mainMonitor.countDown();
//为了让主线程阻塞,让子线程执行。
Thread.currentThread().join();
} catch (Exception e) {
e.printStackTrace();
}
}
}
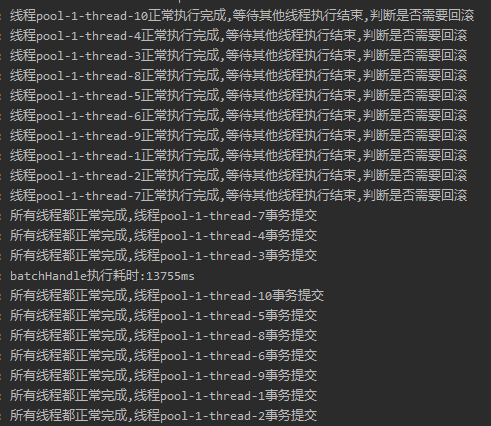
在所有子线程都正常的情况下,输出结果是这样的:
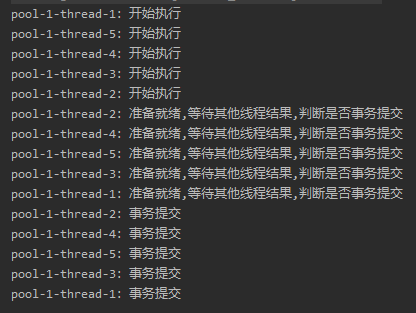
从结果看,是符合我们的预期的。
假设有子线程出现了异常,那么运行结果是这样的:
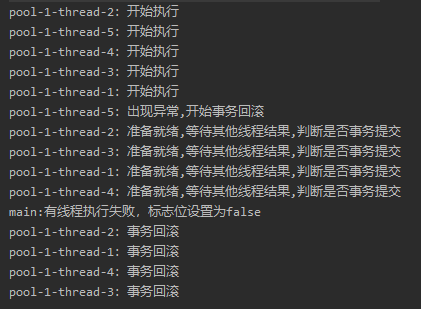
一个线程出现异常,全部线程都进行回滚,这样看来也是符合预期的。

如果你根据前面的需求写出了这样的代码,那么恭喜你,一不留神实现了一个类似于两阶段提交(2PC)的一致性协议。
我前面说的能想到编程式事务,这事基本上就成了一半了。
而另外一半,就是两阶段提交(2PC)。
依瓢画葫芦
有了前面的瓢,你照着画个葫芦不是很简单的事情吗?
就不大段上代码了,示例代码可以点击这里获取到,所以我这里截个图吧:
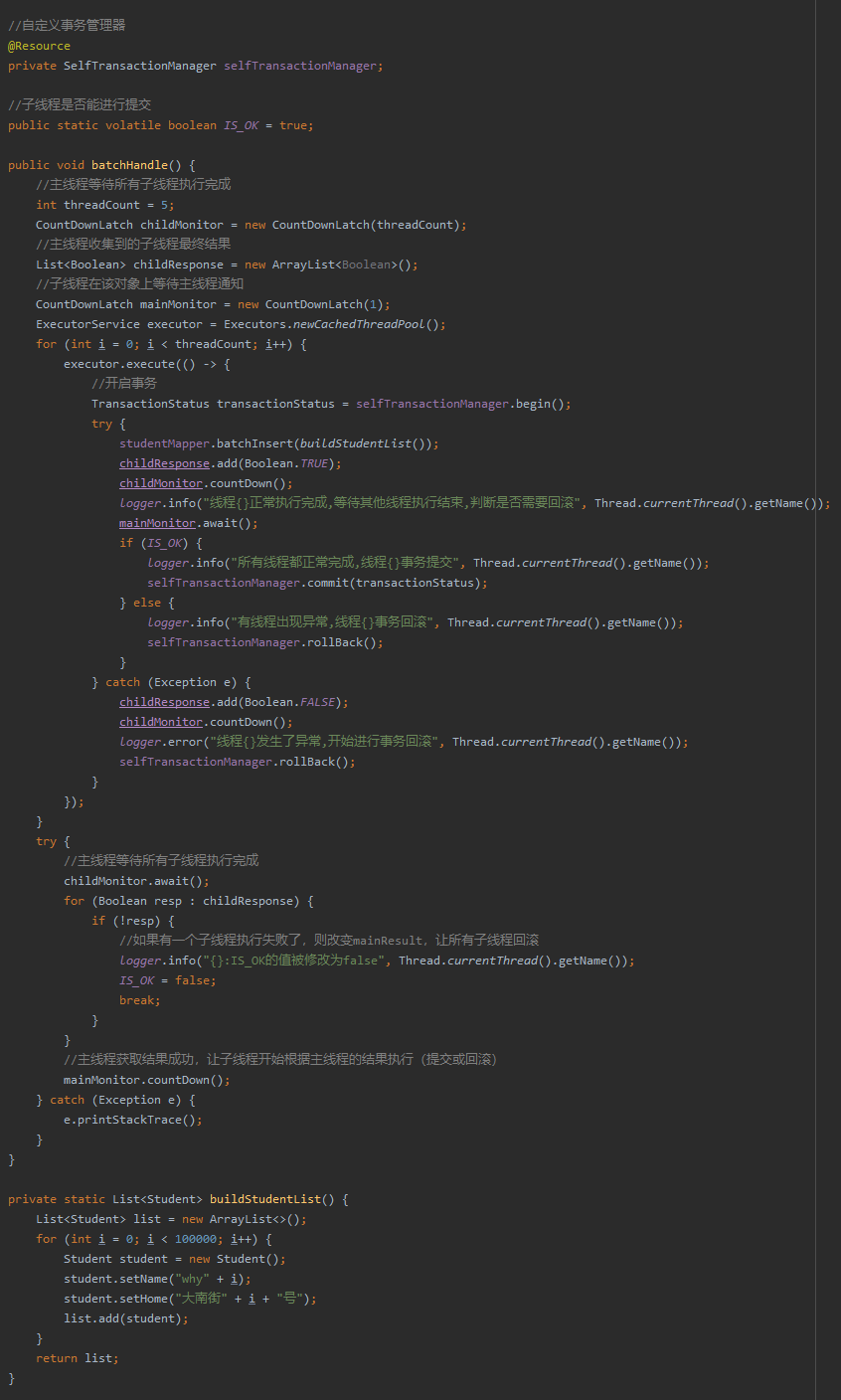
上面的代码应该是非常好理解的,开启五个线程,每个线程插入 10w 条数据。
这个不用说,用脚趾头想也能知道,肯定是比一次性批量插入 50w 条数据快的。
至于快多少,不废话了,直接看执行效果吧。
由于我们的 controller 是这样的:
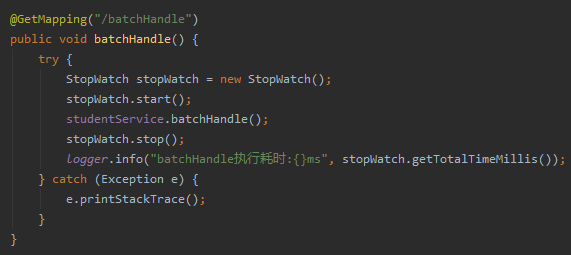
所以调用链接:
http://127.0.0.1:8081/batchHandle
输出结果如下:
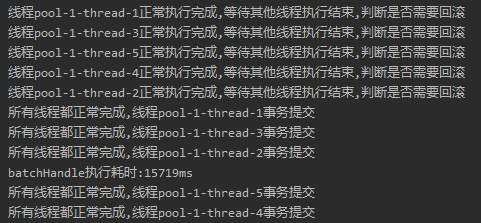
还记得我们批量插入的耗时吗?
73791ms。
从 73791ms 到 15719ms。快了 58s 的样子。
已经非常不错了。
那么如果是某个线程抛出了异常呢?比如这样:
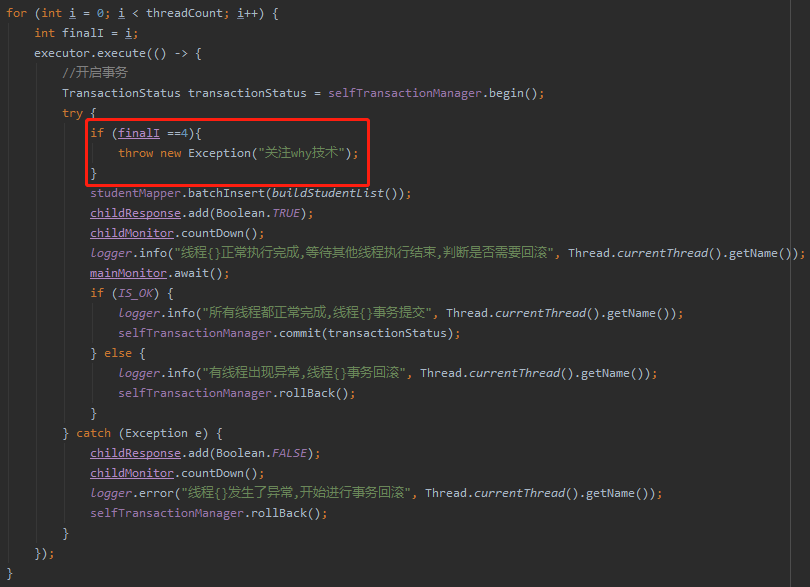
我们看看日志输出:
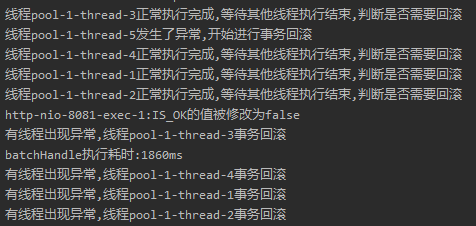
通过日志分析,看起来也是符合要求的。
而从读者反馈的实际测试效果来看,也是非常显著的:
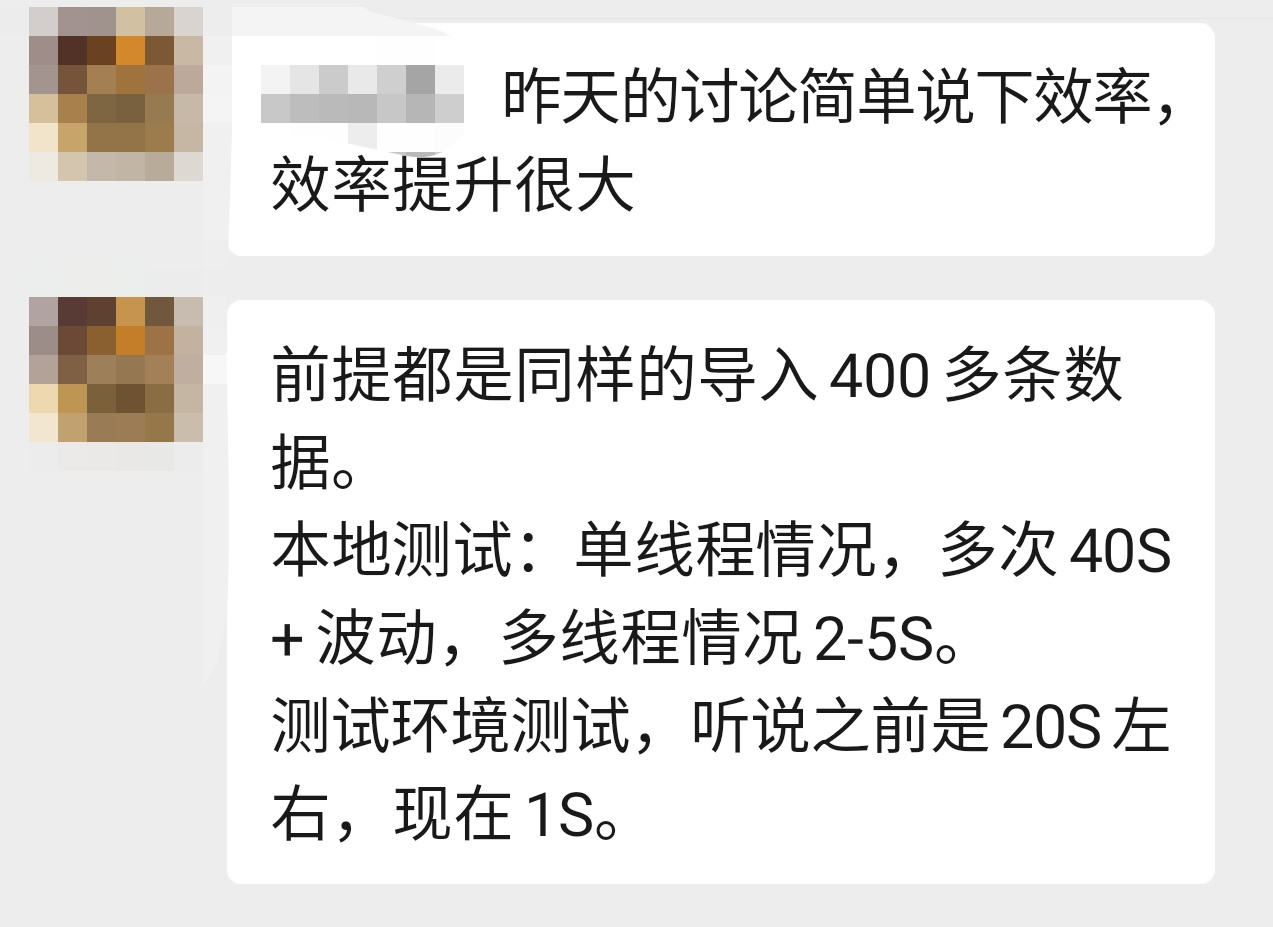
真的符合要求吗?
符合要求,只是看起来而已。
经验老道的读者朋友们肯定早就看到问题所在了。已经把手举得高高的:老师,这题我知道。

我之前说了,这个实现方式实际上就是编程式事务配合二阶段提交(2PC)使用。
破绽就出在 2PC 上。
就像我和读者讨论这样的:
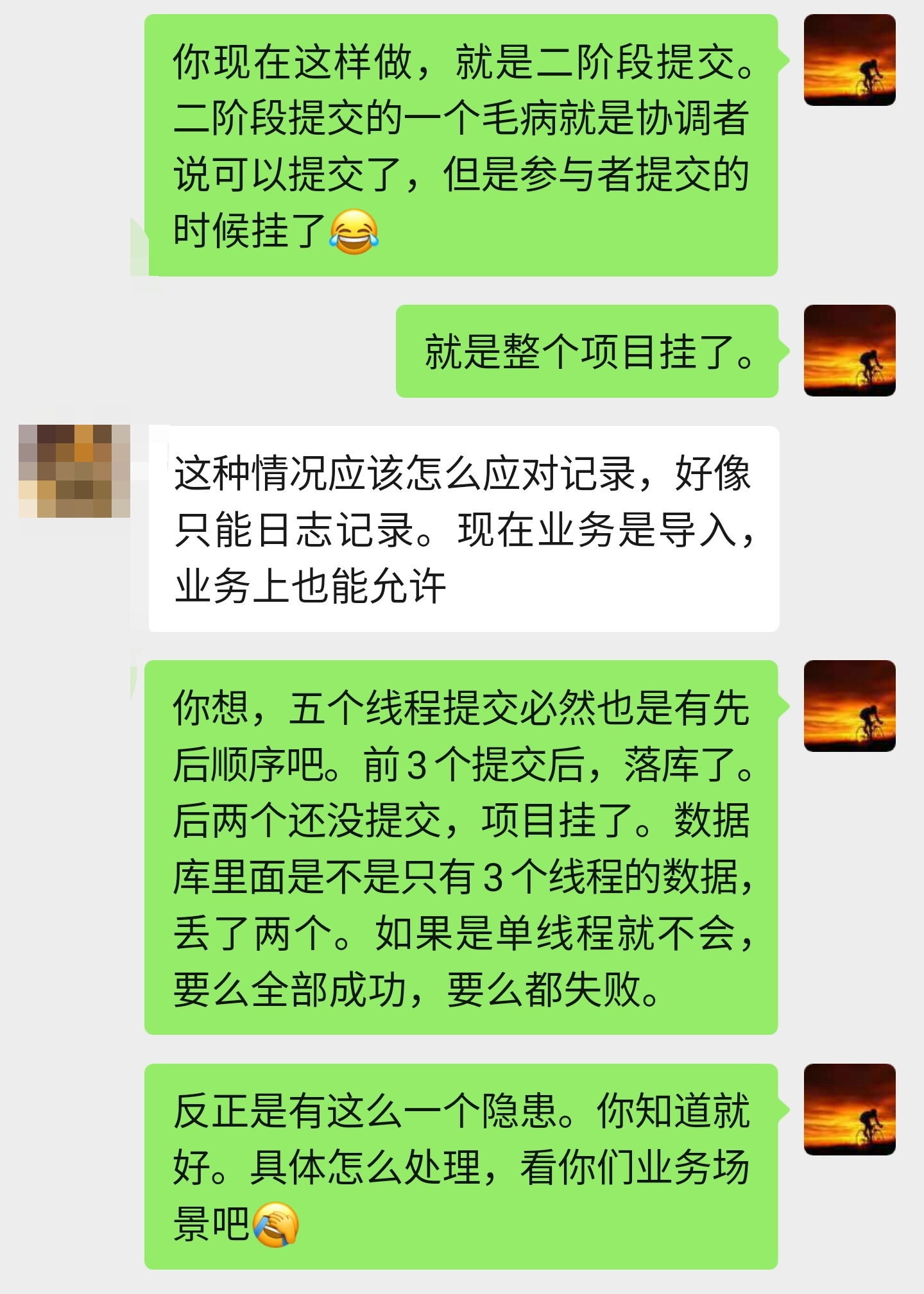
不能再往后扯了,再往后就是 3PC,TCC,Seata 这一套分布式事务的东西了。
这套东西写下来,就得上万字了。所以我从海神那边转了一篇文章,放在第二条推送里面了。如果大家有兴趣的可以去看一下。干货满满。
其实当我们把一个个子线程理解为微服务中的一个个子系统的时候,这就是一个分布式事务的场景了。
而我们拿出来的解决方案,并不是一个完美的解决方案。
虽然,从某种角度上,我们绕开了事务的隔离性,但是有一定概率出现数据一致性问题,虽然概率比较小。
所以我称之为这种方案叫做:基于运气编程,用运气换时间。
注意事项
关于上面的代码,其实还有几个需要注意的地方。
给大家提个醒。
第一个:启用多少线程进行分配数据插入,这个参数是可以进行调整的。
比如我修改为 10 个线程,每个线程插入 5w 条数据。那么执行时间又快了 2s:
但是一定记得不是越大越好,同时记得调整数据库连接池的最大连接数。不然白搭。
第二个:正是因为启动多少线程是可以进行调整的,甚至是可以每次进行计算的。
那么必须要注意的一个问题是不能让任何一个任务进入队列里面。一旦进入队列,程序立马就凉。

你想,如果我们需要开启 5 个子线程,但是核心线程数只有 4 个,有一个任务进入队列了。
那么这 4 个核心线程会一直阻塞住,等待主线程唤醒。
而主线程这个时候在干什么?
在等 5 个线程的运行结果,但是它只能收集到 4 个结果。
所以它会一直等下去。
第三个:这里是多个线程开启了事务在往表里插入数据,谨防数据库死锁。
第四个:注意程序里面的代码,countDown 安装标准写法上是要放到 finally 代码块里面的,我这里为了截图的美观度,省去了这个步骤:
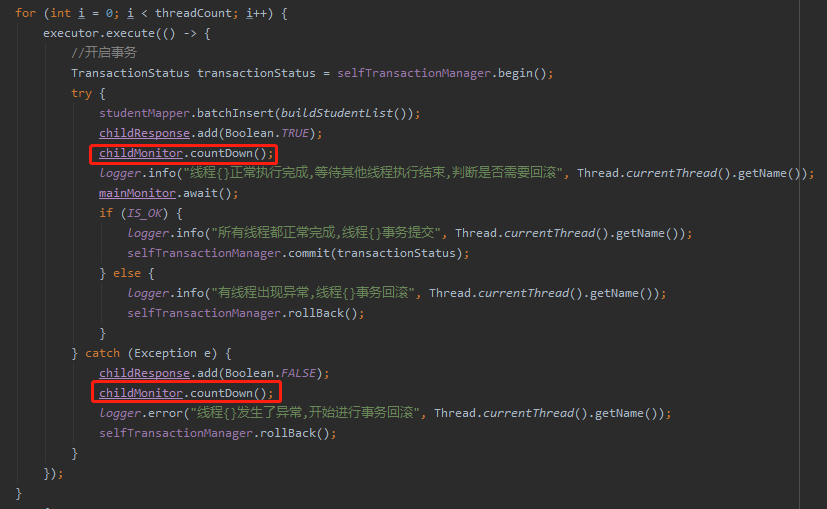
你如果真的要用,得注意一下。而且这个finally你得想清楚了写,不是随便写的。
第五个:我这里只是提供一个思路,而且它也根本不是什么多线程事务。
也再次证明了,多线程事务就是一个伪命题。
所以我给出一个基于运气的伪一致性的回答也不过分吧。
第六个:多线程事务换个角度想,可以理解为分布式事务。,可以借助这个案例去了解分布式事务。但是解决分布式事务的最好的方法就是:不要有分布式事务!
而解决分布式事务的绝大部分落地方案都是:最终一致性。
性价比高,大多数业务上也能接受。
第七个:这个解决方案你要拿到生产用的话,记得先和业务同事沟通好,能不能接受这种情况。速度和安全之间的两难抉择。
同时自己留好人工修数的接口:

最后说一句
才疏学浅,难免会有纰漏,如果你发现了错误的地方,可以在留言区提出来,我对其加以修改。 感谢您的阅读,我坚持原创,十分欢迎并感谢您的关注。
我是 why,一个被代码耽误的文学创作者,不是大佬,但是喜欢分享,是一个又暖又有料的四川好男人。
还有,欢迎关注我呀。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号