
马尔可夫链蒙特卡罗算法(MCMC)
马尔可夫链蒙特卡罗算法(MCMC)
文章结构如下:
1: MCMC
- 1.1 MCMC是什么
- 1.2 为什么需要MCMC
2: 蒙特卡罗
- 2.1 引入
- 2.2 均匀分布,Box-Muller 变换
- 2.3 拒绝接受采样(Acceptance-Rejection Sampling)
- 2.4 接受拒绝采样的直观解释
- 2.5 接受拒绝采样方法有效性证明
- 2.6 接受拒绝采样方法python实现
- 2.7 蒙特卡罗方法小结
3: 马尔科夫链
- 3.1 马尔科夫链概述
- 3.2 马尔科夫链模型状态转移矩阵的性质
- 3.3 基于马尔科夫链采样
- 3.4 马尔科夫链采样小结
- 3.5 补充:PageRank:Google的民主表决式网页排名技术
4: 马尔可夫链蒙特卡罗算法
- 4.1 马尔科夫链的细致平稳条件(Detailed Balance Condition)
- 4.2 MCMC采样
5: M-H采样
- 5.1 M-H采样算法
- 5.2 M-H采样python实现
- 5.3 M-H采样小结
6:Gibbs采样
- 6.1 重新寻找合适的细致平稳条件
- 6.2 二维Gibbs采样
- 6.3 多维Gibbs采样
- 6.4 二维Gibbs采样python实现
- 6.5 Gibbs采样小结
7: 参考文献
不喜欢数学推导的可以移至这么篇文章:告别数学公式,图文解读什么是马尔可夫链蒙特卡罗方法(MCMC),这篇文章通俗的解释了MCMC是什么,本文也借鉴了里面一些内容。本文主要参考的刘建平博客:MCMC 。其他参考文章也在文末附上。另外大牛的文章也到单独附上,刘建平主要参考了此文章:靳志辉写的:LDA-math-MCMC 和 Gibbs Sampling ,PDF是《LDA数学八卦》,现在离开腾讯出来创业了,第一次知道他还是看了《正态分布的前世今生》。反正大神!
1: MCMC
1.1. MCMC是什么
那MCMC到底是什么呢?《告别数学公式,图文解读什么是马尔可夫链蒙特卡罗方法》里面这样解释:MCMC方法是用来在概率空间,通过随机采样估算兴趣参数的后验分布。
说的很玄,蒙特卡罗本来就可以采样,马尔科夫链可以采样,为啥要将他们合在一起?下面给出两个动机,后面将从蒙特卡罗开始一直推到gibbs采样,来深入了解为什么需要MCMC。
再次感谢刘建平MCMC,他是网上写的最详细的——将整个脉络梳理出来了,看完收获很多。本文几乎涵盖了它所有内容,因此只能算一篇读书笔记。
1.2: 为什么需要MCMC
动机一
假如你需要对一维随机变量$X$进行采样, 的样本空间是
,且概率分别是
,这很简单,只需写这样简单的程序:首先根据各离散取值的概率大小对
区间进行等比例划分,如划分为
这三个区间,再通过计算机产生
之间的伪随机数,根据伪随机数的落点即可完成一次采样。接下来,假如
是连续分布的呢,概率密度是
,那该如何进行采样呢?聪明的你肯定会想到累积分布函数,
,即在
间随机生成一个数
,然后求使得使
成立的
,
即可以视作从该分部中得到的一个采样结果。这里有两个前提:一是概率密度函数可积;第二个是累积分布函数有反函数。假如条件不成立怎么办呢?MCMC就登场了。
动机二
假如对于高维随机变量,比如 ,若每一维取100个点,则总共要取
,而已知宇宙的基本粒子大约有
个,对连续的也同样如此。因此MCMC可以解决“维数灾难”问题。
2: 蒙特卡罗
2.1 引入
蒙特卡罗方法于20世纪40年代美国在第二次世界大战中研制原子弹的“曼哈顿计划”计划时首先提出,为保密选择用赌城摩纳哥的Monte Carlo作为代号。
对于上图你如何求解圆的面积?当然知道圆的直径,或根据圆的方程进行积分很容易求解。也可以用如下方法进行简单近似:
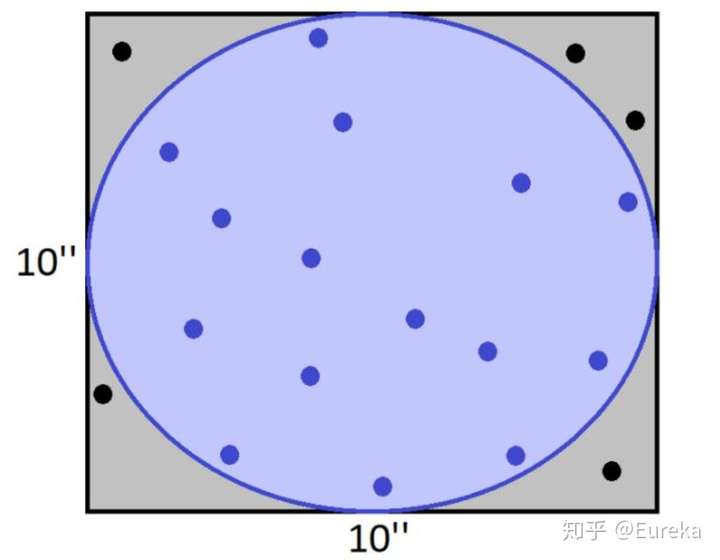
我们可以在这个正方形内随机撒20个米粒,然后我们数一下有多少个米粒落在圆圈内,计算这部分比例,并乘以正方形的面积。如上图大概是3/4正方形的面积。
这个方法在我们无法知道形状的方程时很有用,如下图的蝙蝠:
在一块长方形区域内随机抛掷点,蒙特卡罗方法能非常轻松地计算出该区域的近似值。
其上等价于如下公式:面积= ,即求出高度的均值在乘以宽度,因为任何一个不规则图形的面积都等价于一个矩形的面积。
但是它隐含了一个假定,即 在
之间是均匀分布的,而绝大部分情况,
在
之间不是均匀分布的。我们可以如下表示:
这里把 看做是
在区间内的概率分布函数,而把前面的分数部分看做一个函数,然后在
下抽取
个样本,当
足够大时,可以用采用均值来近似:
,这个形式就是蒙特卡罗方法的一般形式。
2.2 均匀分布,Box-Muller 变换
均匀分布是很容易采样的,比如在计算机中生成 之间的伪随机数序列,就可以看成是一种均匀分布。而我们常见的概率分布,无论是连续的还是离散的分布,都可以基于
的样本生成。例如正态分布可以通过著名的Box−Muller变换得到:
Box-Muller 变换
如果随机变量 独立且
,
则 独立且服从标准正态分布。
其它几个著名的连续分布,包括指数分布、Gamma 分布、t 分布、F 分布、Beta 分布、Dirichlet 分布等等,也都可以通过类似的数学变换得到;离散的分布通过均匀分布更加容易生成。在python的numpy,scikit-learn等类库中,都有生成这些常用分布样本的函数可以使用。
不过当 的形式很复杂,或者
是个高维的分布的时候,样本的生成就可能很困难了。譬如有如下的情况:
1) ,
我们可以得到,但是下面的积分我们无法得到显示解(归一化系数很难计算);
2) 是一个二维的分布函数,这个函数本身计算很困难,但是条件分布
的计算相对简单; 如果
是高维的,这种情形就更加明显。
2.3 拒绝接受采样(Acceptance-Rejection Sampling)
- 需求: 根某已知分布的概率密度函数
,产生服从此分布的样本
- 准备工作:
- 需要一个辅助的“建议分布proposal distribution”
(已知其概率密度函数
)来产生候选样本。——由分布来产生候选样本,因此需要我们能够从
抽样。即我们必须能够生成服从此概率分布的样本
。比如可以选择均匀分布、正态分布。
- 还需要另一个辅助的均匀分布
。
- 计算一个常数值
。——满足不等式
的最小值
(当然,我们非常希望
接近于1)
3. 开始样本生成:
- 从建议分布
抽样,得到样本
。
- 从分布
抽样,得到样本
。
- 如果
,则令
(接受
),否则继续执行步骤1(拒绝)。
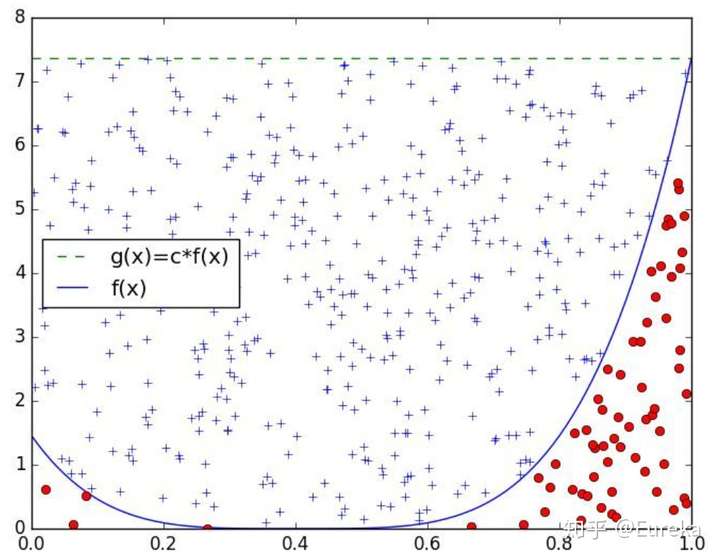
2.4 接受拒绝采样的直观解释
假设使用 来作为“proposal distribution”
,这样
。如下图所示,我们每次生成的两个样本
与
,对应下图中矩形内的一点
。接受条件
,即
的几何意义是点
在
下方,不接受
的几何意义是点
在
的上方。在
下方的点(o形状)满足接受条件,上方的点(+形状)不满足接受条件。
2.5 接受拒绝采样方法有效性证明
在我们进行证明之前,先给出几个非常重要的性质:
和
是随机变量,因此在第三步中
和
是独立的。
- 从proposal分布和均匀分布中成功一次获得
的抽样(迭代)次数
也是个随机变量,服从概率是
的几何分布:
,因此成功一次获得
的平均抽样(迭代)次数是
- 最后我们获得
在
给定下的条件分布,即
成立
我们可以直接计算出 ,因为
求积分得:
因此 ,从而得到我们选择一个
函数从而使
最小的合理性。
下面证明接受拒绝采样的有效性:
我们需要证明的是: 。我们定义:
,
。从上面我们知道:
,然后我们使用贝叶斯:
可以得到:
其中:
2.6 python实现
假如我们的目标概率密度函数是 ,对此分布生成样本。
- 准备工作:
- 建议分布函数
选择
,概率密度函数为
。(这里我们简单化了,一般要使得c最小的g函数);
- 辅助的均匀分布
;
- 计算常数值,
,(其中
,后面可以化简掉)
2. 生成代码如下:
import random
import math
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
%matplotlib inline
sns.set_style('darkgrid')
plt.rcParams['figure.figsize'] = (12, 8)
def AceeptReject(split_val):
global c
global power
while True:
x = random.uniform(0, 1)
y = random.uniform(0, 1)
if y*c <= math.pow(x - split_val, power):
return x
power = 4
t = 0.4
sum_ = (math.pow(1-t, power + 1) - math.pow(-t, power + 1)) / (power + 1) #求积分
x = np.linspace(0, 1, 100)
#常数值c
c = 0.6**4/sum_
cc = [c for xi in x]
plt.plot(x, cc, '--',label='c*f(x)')
#目标概率密度函数的值f(x)
y = [math.pow(xi - t, power)/sum_ for xi in x]
plt.plot(x, y,label='f(x)')
#采样10000个点
samples = []
for i in range(10000):
samples.append(AceeptReject(t))
plt.hist(samples, bins=50, normed=True,label='sampling')
plt.legend()
plt.