
CapProNet: 从胶囊投影网络的突破到Weight Normalization的高维推广
CapProNet: 从胶囊投影网络的突破到Weight Normalization的高维推广
应不少朋友的要求,在下面的原文最后,给出了一个简单地卷积化胶囊投影的思路。
============= 原文==============
胶囊神经网络(Capsule Nets)的概念最早有G. Hinton在2011年的一篇论文“Transformation Auto-Encoders"中提出,之后在2017年发表的"Dynamic Routing between Capsules"后引发了学术界和工业界的广泛关注。
尽管如此,由于Capsule Nets和dynamic routing 的复杂性,使得Hinton提出的Capsule Nets难以推广到非常深的结构上,而往往几层的胶囊网络结构也很难在准确度上战胜其他主流的深度网络结构。
同时,更关键的是,我们发现仅仅将一个特征层(feature map)中的若干通道(channel)分成几个胶囊(capsule),之后按照Hinton的假设,基于这种胶囊的长度来表式对不同概念的置信度也无法很合的提高识别准确率。
基于以上的问题,我们提出了一直新的胶囊投影网络(Capsule Project Networks)架构,
1)不仅做到在同样网络的复杂度(network size)下,在一系列数据集上将分类错误率下降10-20%;并第一次使得胶囊网络的分类准确率超过了其他的主流网络结构;
2)同时揭示了投影胶囊构造与weight normalization之间的深刻联系,指出了weight normalization是投影胶囊的一维情况下的特例,而胶囊投影将weight normalization不平凡地推广到了高维的情形,为极大地提高深度网络的性能指出了一条新思路;
3)通过分析投影胶囊网络的Back Propagation训练过程,我们发现了这种CapProNet 构造可以通过有效地利用包含在垂直于胶囊子空间的特征分量,有效地提高对胶囊子空间的更新效率,进而解释了CapProNet的高精度、低网络复杂度的结果。
相关工作发表在最新的NeurIPS2018会议上,相关代码也公布在github网站 Lab for MAchine Perception and LEarning (MAPLE)

下面我们简单扼要的介绍下CapProNet的构造。
其核心思想避免直接将特征层中的若干通道聚合成几个胶囊。相反,我们使用若干个子空间代表要建模的胶囊,而上一层输入的特征向量x,则通过正交投影到这几个胶囊子空间得到相应的胶囊表示:
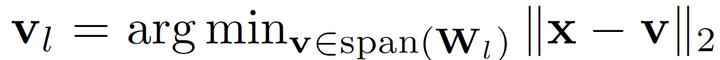
这里, 代表一个胶囊子空间基向量组成的权重矩阵,这时一个通过训练学习得到的网络参数;而
就是对应于这个子空间的胶囊特征。
和Hinton的胶囊网络类似,我们用胶囊的模 来代表属于对应概念的置信度来得到分类和识别的目的。不能看出,这个模可以表示成
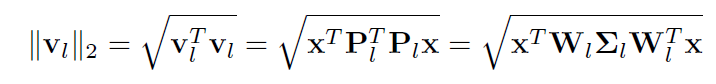
其中,我们有
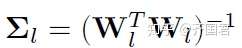
这里,当子空间只有一维的时候,参数矩阵退化成了一个参数向量。这时不难看出,胶囊向量在不改变其模大小的情况下,可以等价的表示成
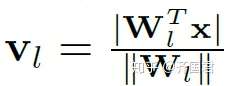
而这个其实就是通过归一化 而实现的weight normalization。
从这个意思上而已,普通的weight normalization是胶囊投影在一维胶囊子空间上的特例,而一个被胶囊投影网络则成功地将weight normalization推广到了更一般的高维情形,这部分展示了CapProNet的通用性。具体而言,在高维一般情形下的weight normalization是
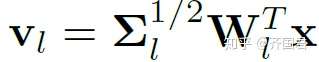
换言之,对weight matrix 的高维情形下的归一化,是通过
来实现。
更一般地,我们分析了通过反向传播过程训练胶囊投影网络的过程。不能看出,用来更新网络参数的误差梯度是
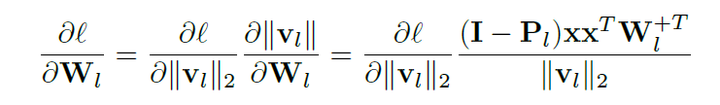
其中 是将输入特征x投影到与胶囊子空间正交的方向上。
显然,这个正交分量可以解释成包括了尚没有被胶囊子空间包含的新信息。而通过上面这个梯度来更新胶囊子空间时,子空间会被沿着这个正交方向更新,这样一来,更新后的胶囊子空间就会包含更多新的特征信息,从而更有效地对网络结构进行训练。
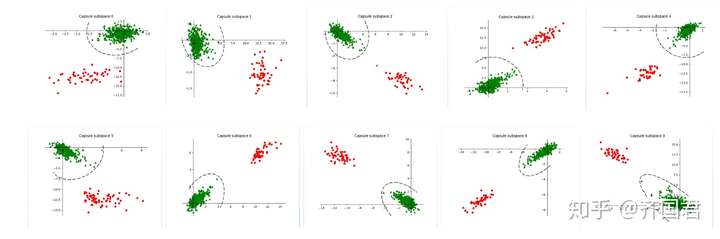
从实验上看,改胶囊投影网络可以很好地将不同语义概念的样本,在不同的子空间中按投影胶囊的模长把正负样本分开(如下图在CIFAR10数据集上的结果)。
同时,仅仅通过替换最后一层神经网络,我们在一系列数据集上也取得了相对与ResNet和DenseNet非常好的结果。
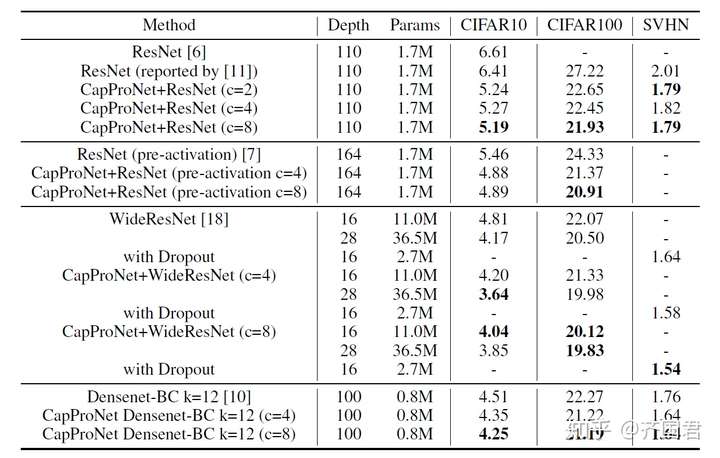

最后,我们还与非投影的胶囊网络(简单地把神经元聚合成胶囊,无投影算子,但基于相同的backbone network)做了对比,发现在投影胶囊要远远好于非投影的网络,如下。

卷积化的胶囊投影网络思路
后面我们将进一步把投影网络结构卷积化来全卷积的胶囊投影构造。这里提下全卷积胶囊投影的思路。简单地来说,一个卷积操作实际上就是一个线性运算。
我们考虑一个胶囊投影层,输入的feature map有n的channel,经过胶囊投影卷积后,输入的feature map有m个channel。考虑一个大小w乘以h的卷积核,那么这个卷积核就是n x w x h x m。我们把这个卷积核reshape成nwh x m的矩阵W。
这个矩阵就是和我们上面的权重矩阵W是一样的,只不过它实现的是一个从有n个channel的输入feature map图像上w x h patch到有m个channel的输出feature map图像上一个像素的线性变化。
对这个reshape后的权重矩阵W,我们可以同样的根据高维weight normalization 的公式,来得到normalization后的权重矩阵,即
。最后,把得到的normalize后的nwh x m的权重矩阵重新变换回n x w x h x m的卷积核就可以。
最后相关论文参见
https://nips.cc/Conferences/2018/Schedule?showEvent=11566 NIPS 2018代码
Lab for MAchine Perception and LEarning (MAPLE)github.com

最后,我们欢迎有兴趣的朋友一起将卷积化的胶囊投影网络用在更多的深度学习框架上。我们将非常乐意地在我们的github主页上认可和分享大家新代码和结构。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号