04 Hadoop思想与原理,Hbase原理
1.用图与自己的话,简要描述Hadoop起源与发展阶段。
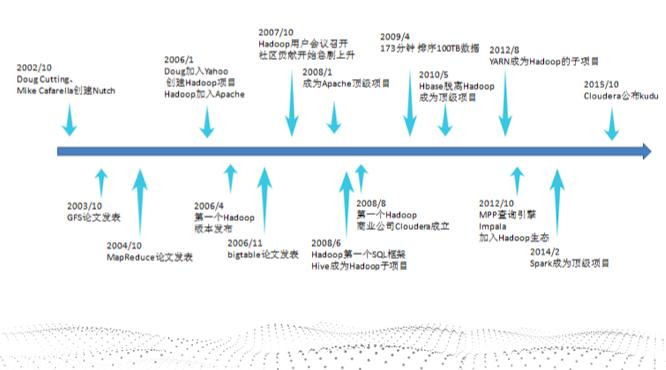
Hadoop是道格·卡丁(Doug Cutting)创建的,Hadoop起源于开源网络搜索引擎Apache Nutch,后者本身也是Lucene项目的一部分。Nutch项目面世后,面对数据量巨大的网页显示出了架构的灵活性不够。当时正好借鉴了谷歌分布式文件系统,做出了自己的开源系统NDFS分布式文件系统。第二年谷歌又发表了论文介绍了MapReduce系统,Nutch开发人员也开发出了MapReduce系统。随后NDFS和MapReduce命名为Hadoop,成为了Apache顶级项目。
从Hadoop的发展历程来看,它的思想来自于google的三篇论文。
GFS:Google File System 分布式处理系统 ------》解决存储问题
Mapreduce:分布式计算模型 ------》对数据进行计算处理
BigTable:解决查询分布式存储文件慢的问题,把所有的数据存入一张表中,通过牺牲空间换取时间
2.用图与自己的话,简要描述名称节点、第二名称节点、数据节点的主要功能及相互关系。
HDFS:分布式文件系统把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群。
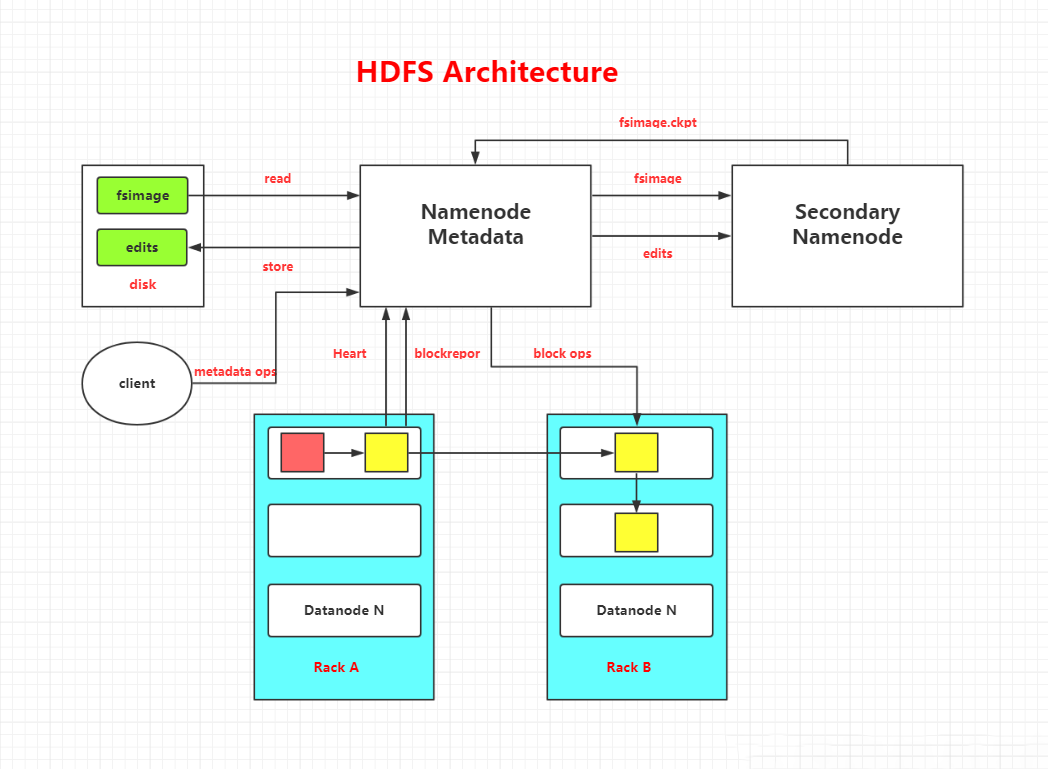
这些节点分为主从节点,主节点可叫作名称节点(NameNode),从节点可叫作数据节点(DataNode)。
名称节点最主要功能:名称节点记录了每个文件中各个块所在的数据节点的位置信息。
名称节点(NameNode)与DataNode的功能:
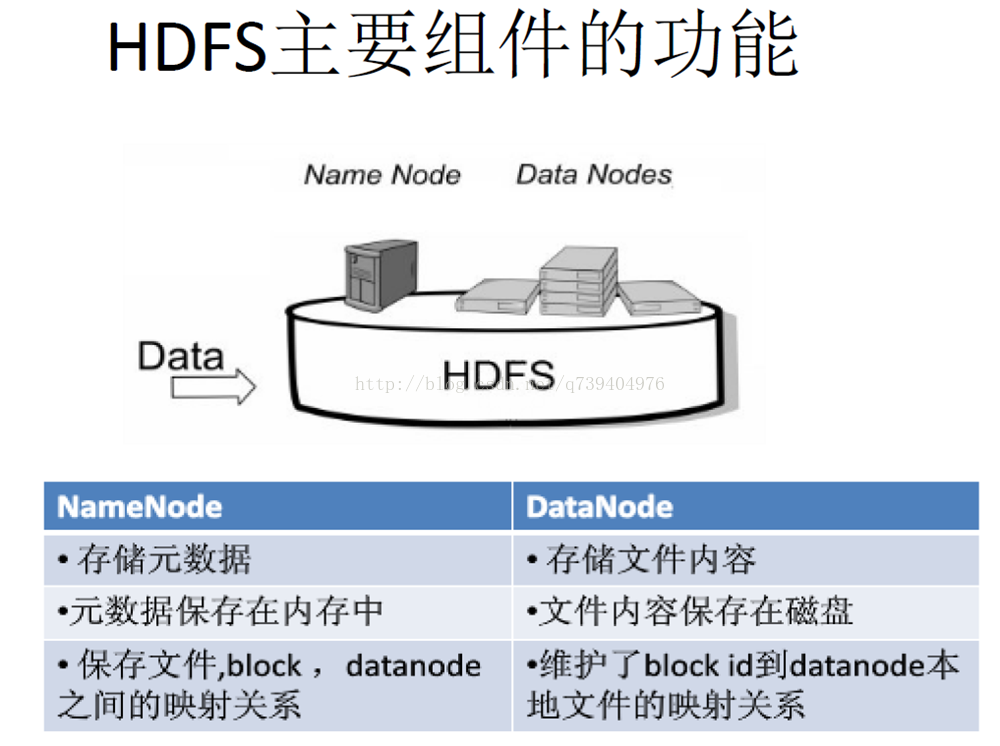
在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即FsImage和EditLog。
FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据。
操作日志文件EditLog中记录了所有针对文件的创建、删除、重命名等操作。
名称节点的启动:
2.一旦在内存中成功建立文件系统元数据的映射,则创建一个新的FsImage文件和一个空的EditLog文件。
3.名称节点起来之后,HDFS中的更新操作会重新写到EditLog文件中,因为FsImage文件一般都很大(GB级别的很常见),如果所有的更新操作都往FsImage文件中添加,这样会导致系统运行的十分缓慢,但是,如果往EditLog文件里面写就不会这样,因为EditLog 要小很多。每次执行写操作之后,且在向客户端发送成功代码之前,edits文件都需要同步更新。
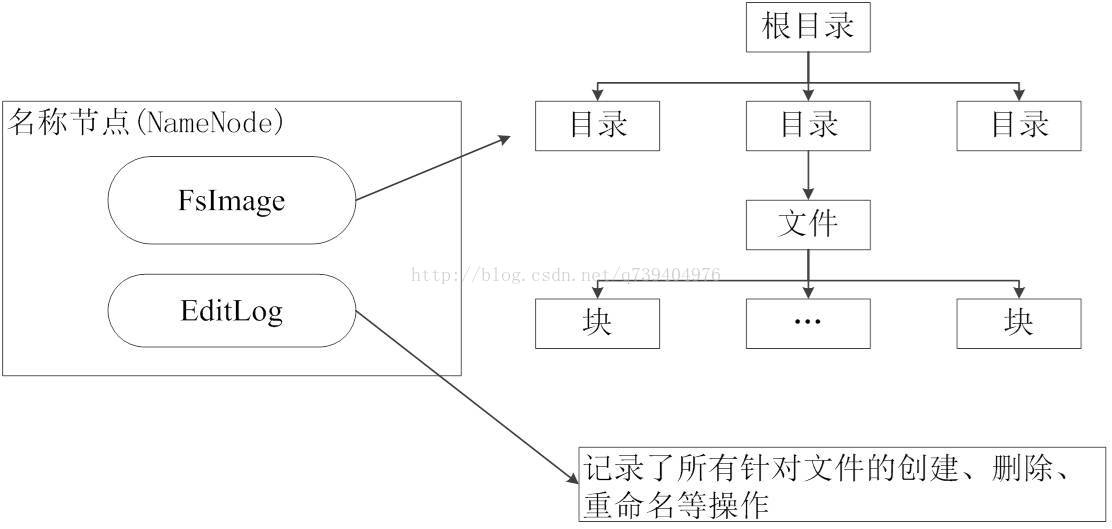
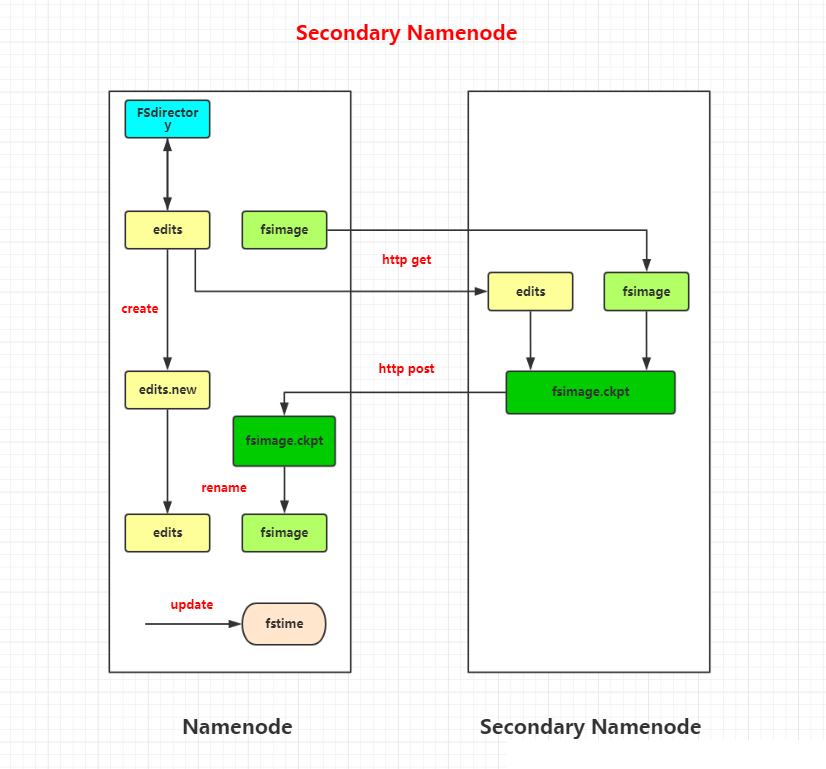
但为了防止EditLog过大的问题:引入了第二名称节点(SecondaryNameNode)
第二名称节点:是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间。
SecondaryNameNode一般是单独运行在一台机器上。
SecondaryNameNode让EditLog变小的工作流程:
(1)SecondaryNameNode会定期和NameNode通信,请求其停止使用EditLog文件,暂时将新的写操作写到一个新的文件edit.new上来,这个操作是瞬间完成,上层写日志的函数完全感觉不到差别。
(2)SecondaryNameNode通过HTTP GET方式从NameNode上获取到FsImage和EditLog文件,并下载到本地的相应目录下。
(3)SecondaryNameNode将下载下来的FsImage载入到内存,然后一条一条地执行EditLog文件中的各项更新操作,使得内存中的FsImage保持最新;这个过程就是EditLog和FsImage文件合并。
(4)SecondaryNameNode执行完操作之后,会通过post方式将新的FsImage文件发送到NameNode节点上。
DataNode:数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表。
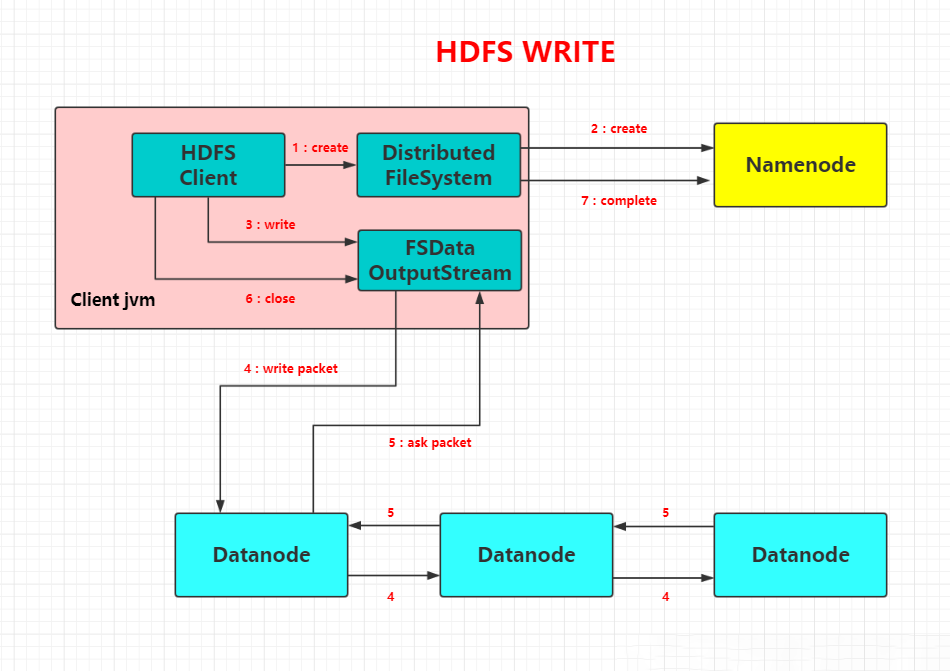
3.分别从以下这些方面,梳理清楚HDFS的结构与运行流程,以图的形式描述。
客户端与HDFS
客户端读
客户端写
数据结点与集群
数据结点与名称结点
名称结点与第二名称结点
数据结点与数据结点
数据冗余
数据存取策略
数据错误与恢复
HDFS结构图:
Secondary Namenode工作图解:
HDFS文件读流程:

HDFS文件写流程:
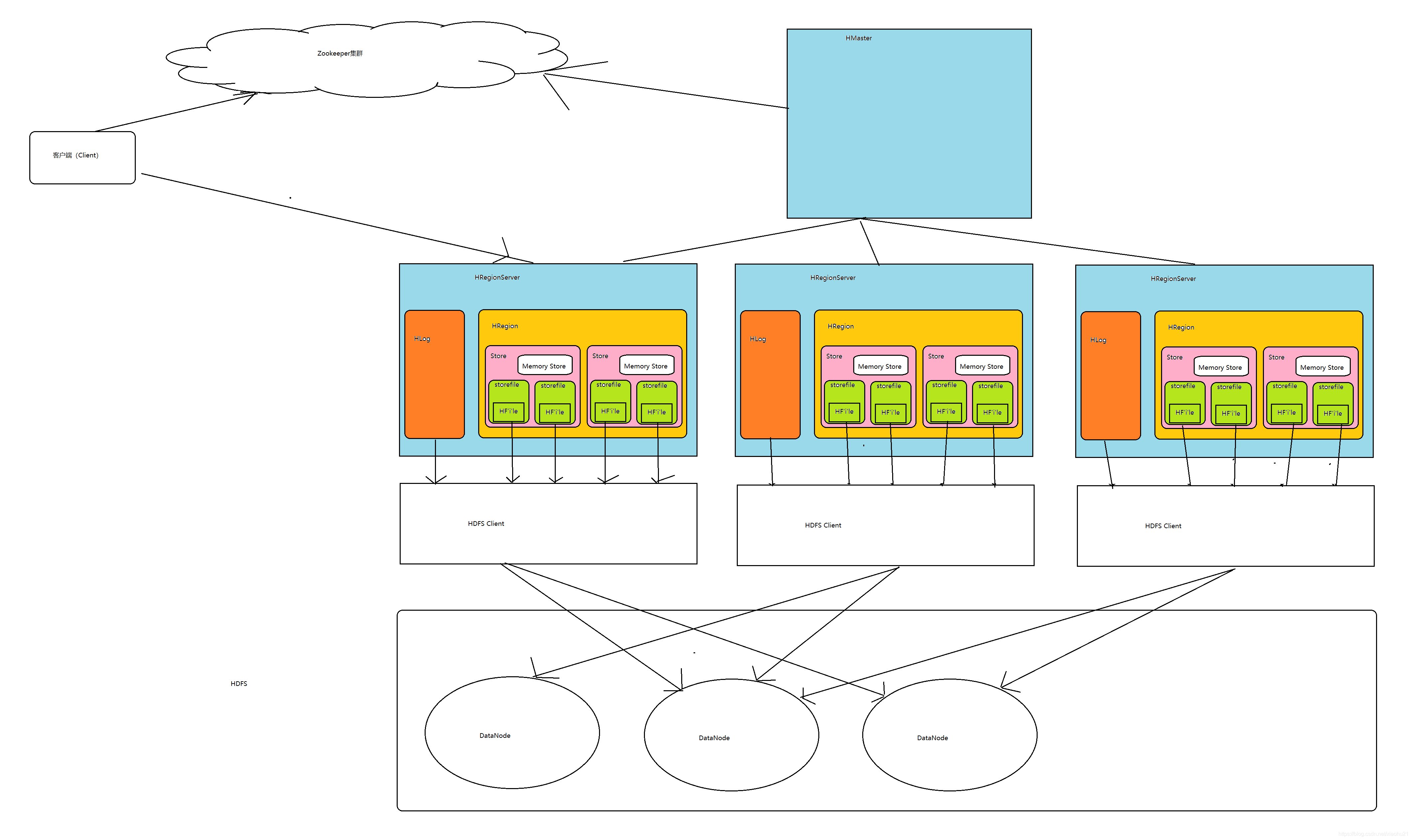
4.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述,图中包括以下内容:
Master主服务器的功能
Region服务器的功能
Zookeeper协同的功能
Client客户端的请求流程
四者之间的相系关系
与HDFS的关联
5.理解并描述Hbase表与Region与HDFS的关系。
Hbase表与Region:
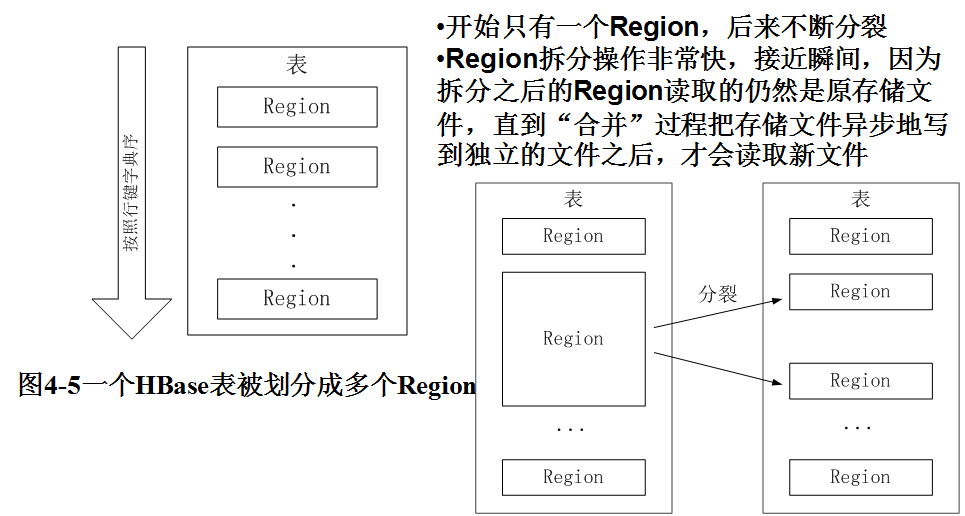
Hbase表与HDFS:
HDFS是Hadoop分布式文件系统。
HBase的数据通常存储在HDFS上。HDFS为HBase提供了高可靠性的底层存储支持。
Hbase是Hadoop database即Hadoop数据库。它是一个适合于非结构化数据存储的数据库,HBase基于列的而不是基于行的模式。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据。
HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。 Sqoop则为HBase提供了方便的RDBMS(关系型数据库)数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
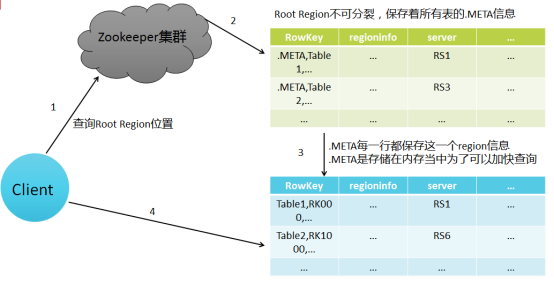
6.理解并描述Hbase的三级寻址。
寻址过程:client-->Zookeeper-->-ROOT-表-->.META.表-->RegionServer-->Region-->client
Hbase寻址机制
7.假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且每个Region限制为2GB,通过HBase的三级寻址方式,理论上Hbase的数据表最大有多大?
(-ROOT-表能够寻址的.META.表的Region个数)×(每个.META.表的 Region可以寻址的用户数据表的Region个数)
一个-ROOT-表最多只能有一个Region,也就是最多只能有128MB,按照每行(一个映射条目)占用1KB内存计算,128MB空间可以容纳128MB/1KB=217行,也就是说,一个-ROOT-表可以寻址个.META.表的Region。同理,每个.META.表的 Region可以寻址的用户数据表的Region个数是128MB/1KB=217。最终,三层结构可以保存的Region数目是(128MB/1KB) × (128MB/1KB) = 234个Region
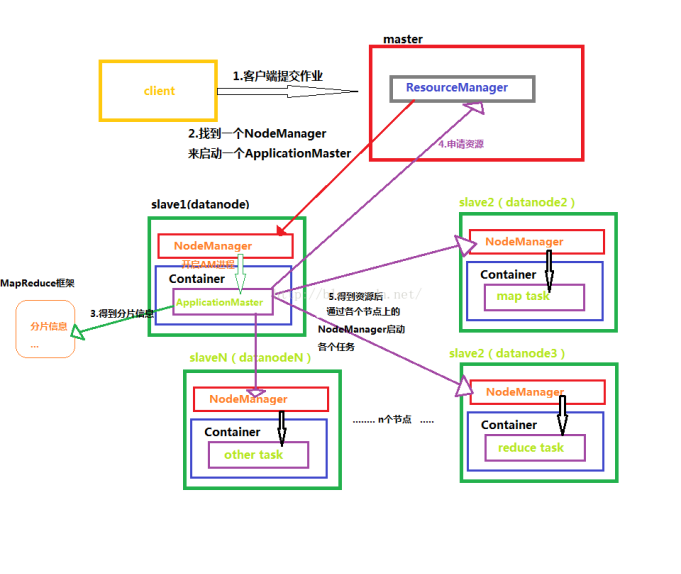
8.MapReduce的架构,各部分的功能,以及和集群其他组件的关系。
同HDFS一样,Hadoop MapReduce也采用了Master/Slave(M/S)架构,主要有以下几个组件构成:Client、JobTracker、TaskTracker和Task。
9.MapReduce的工作过程,用自己词频统计的例子,将split, map, partition,sort,spill,fetch,merge reduce整个过程梳理并用图形表达出来。
Mapper类:
1.将MapTask传给我们的文本内容转成string
2.根据分隔符号将每一行的单词切分
3.将单词输出为 <单词,1> :<hello,1><spring,1><winter,1>......
Redecer类:
1.汇总key个数
2.输出key次数
Driver类:
1.获取job实例对象
2.通过反射指定程序的jar包的位置
3.关联我们创建的Mapper类和Meducer类
4.指定Mapper输出数据的kv类型
5指定我们Reducer最终输出数据的类型
6.指定输入文件的路径
7.指定输出结果的目录,如果存在可以删除掉
8.提交作业

 浙公网安备 33010602011771号
浙公网安备 33010602011771号