03 Linux与Hadoop操作实验
(一)熟悉常用的Linux操作
请按要求上机实践如下linux基本命令。
cd命令:切换目录
(1)切换到目录 /usr/local

(2)去到目前的上层目录

(3)回到自己的主文件夹

ls命令:查看文件与目录
(4)查看目录/usr下所有的文件

mkdir命令:新建新目录
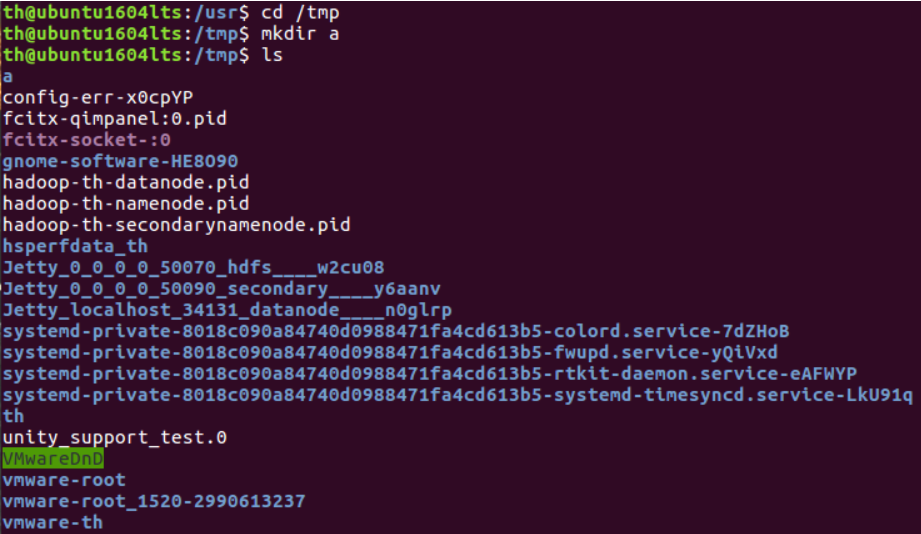
(5)进入/tmp目录,创建一个名为a的目录,并查看有多少目录存在
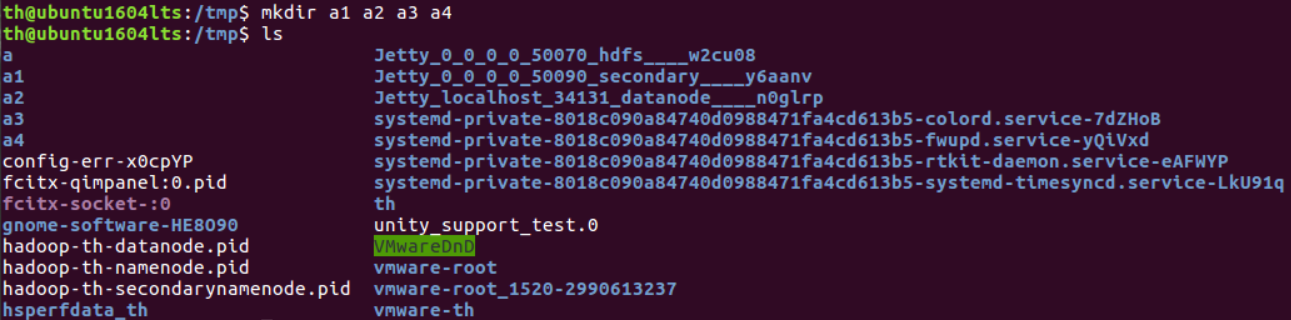
(6)创建目录a1/a2/a3/a4
rmdir命令:删除空的目录
(7)将上例创建的目录a(/tmp下面)删除

(8)删除目录a1/a2/a3/a4,查看有多少目录存在

cp命令:复制文件或目录
(9)将主文件夹下的.bashrc复制到/usr下,命名为bashrc1

(10)在/tmp下新建目录test,再复制这个目录内容到/usr

mv命令:移动文件与目录,或更名
(11)将上例文件bashrc1移动到目录/usr/test

(12)将上例test目录重命名为test2

rm命令:移除文件或目录
(13)将上例复制的bashrc1文件删除

(14)将上例的test2目录删除

cat命令:查看文件内容
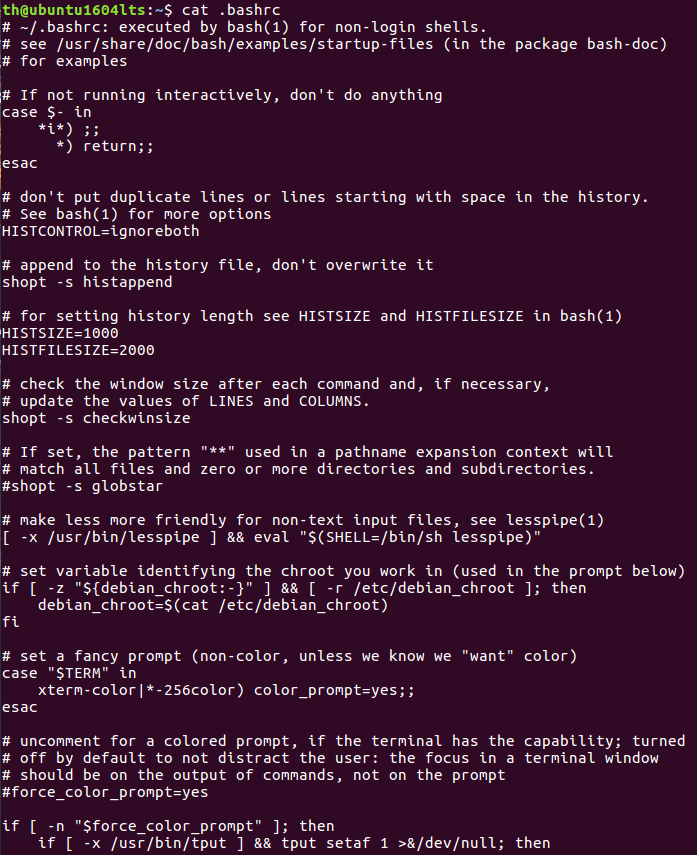
(15)查看主文件夹下的.bashrc文件内容
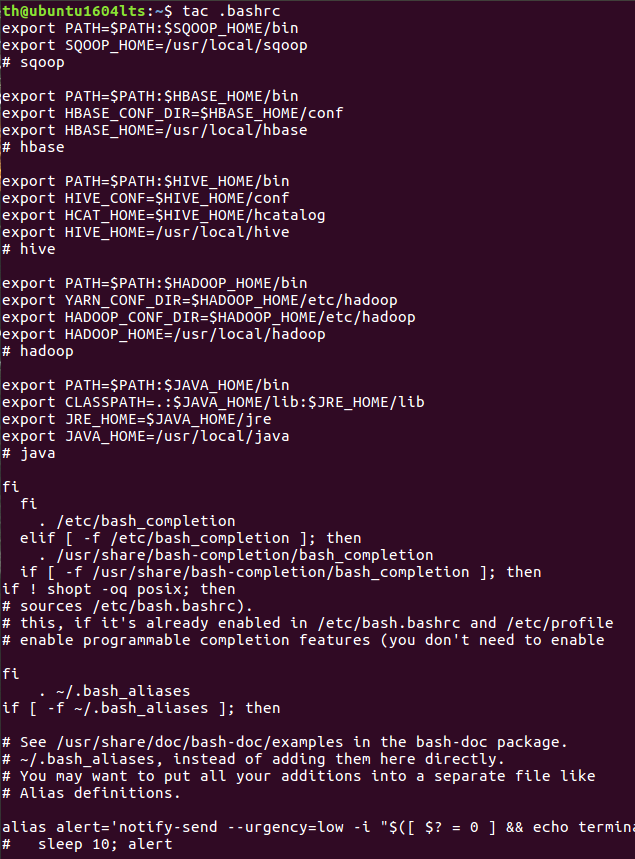
tac命令:反向列示
(16)反向查看主文件夹下.bashrc文件内容
more命令:一页一页翻动查看
(17)翻页查看主文件夹下.bashrc文件内容
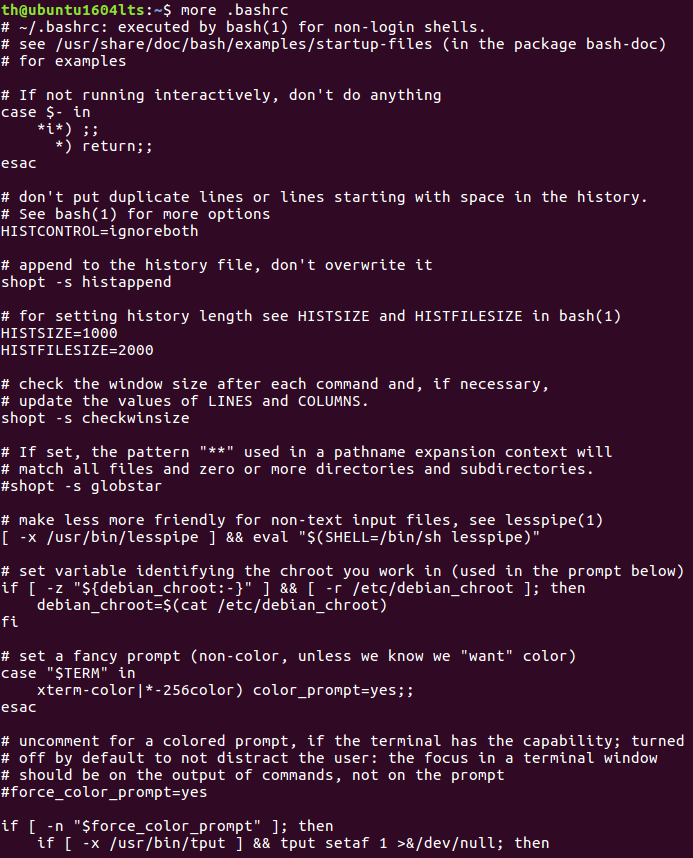
head命令:取出前面几行
(18)查看主文件夹下.bashrc文件内容前20行
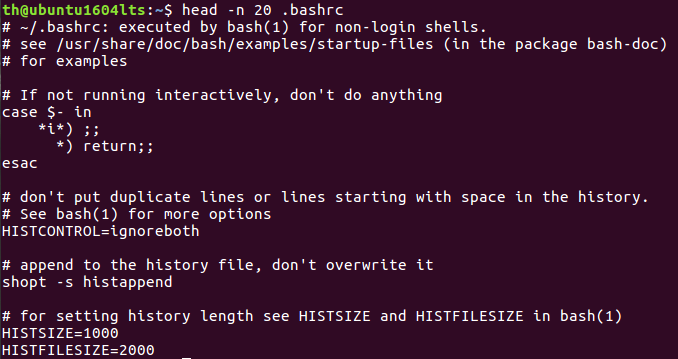
(19)查看主文件夹下.bashrc文件内容,后面50行不显示,只显示前面几行
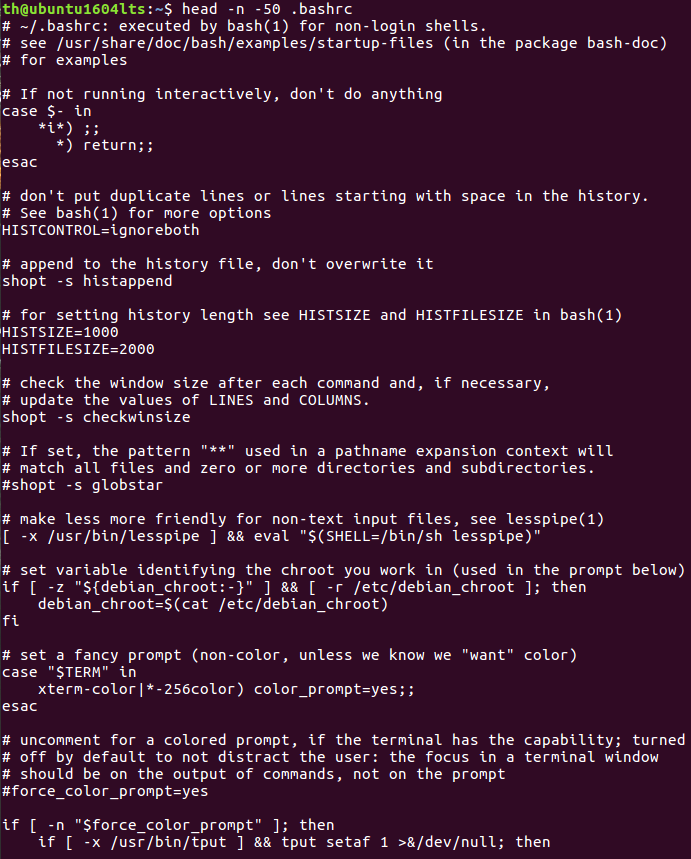
tail命令:取出后面几行
(20)查看主文件夹下.bashrc文件内容最后20行
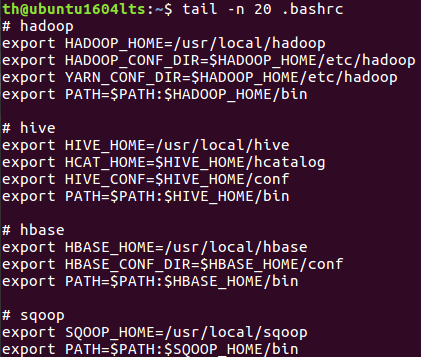
(21)查看主文件夹下.bashrc文件内容,只列出50行以后的数据
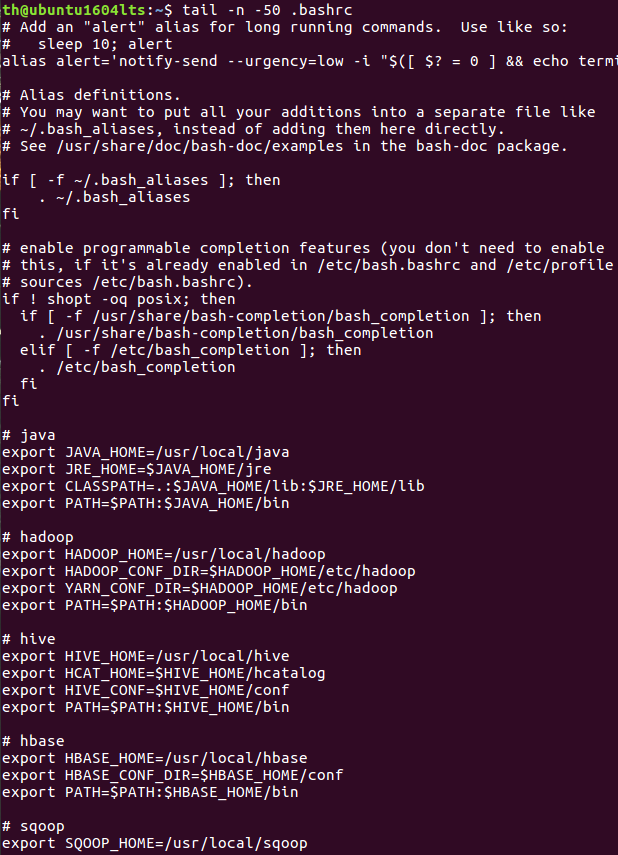
chown命令:修改文件所有者权限
(22)将hello文件所有者改为root帐号,并查看属性
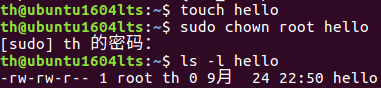
Vim/gedit/文本编辑器:新建文件
(23)在主文件夹下创建文本文件my.txt,输入文本保存退出。
tar命令:压缩命令
(24)将my.txt打包成test.tar.gz


(25)解压缩到~/tmp目录

(二)熟悉使用MySQL shell操作
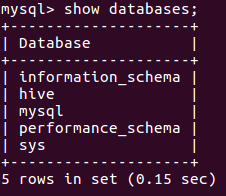
(26)显示库:show databases;
(27)进入到库:use 库名;

(28)展示库里表格:show tables;
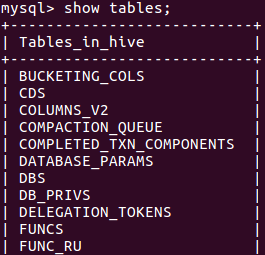
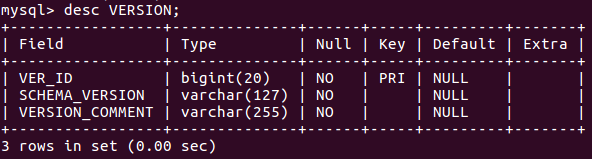
(29)显示某一个表格属性:desc 表格名;
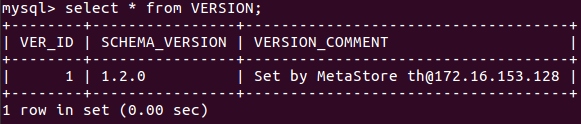
(30)显示某一个表格内的具体内容:select *form 表格名;
(31)创建一个数据库
create databases sc;

(32)在sc中创建一个表格
create table if not exists student(id bigint(12) not null,name varchar(10) character set utf8 collate utf8_general_ci);

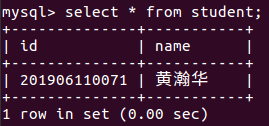
(33)向表格student中插入具体内容:插入记录包含自己的学号姓名。
insert into student values(201906110071,'黄瀚华');

(34)显示表的内容。
select * from student;
(三)熟悉Hadoop及其操作
1.用图文与自己的话,简要描述Hadoop起源与发展阶段。
起源:Hadoop最早起源于lucene下的Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
发展阶段:2003年、2004年谷歌发表的三篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
——分布式的结构化数据存储系统Bigtable,用来处理海量结构化数据。
Doug Cutting基于这三篇论文完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目(同年,cloudera公司成立),迎来了它的快速发展期。
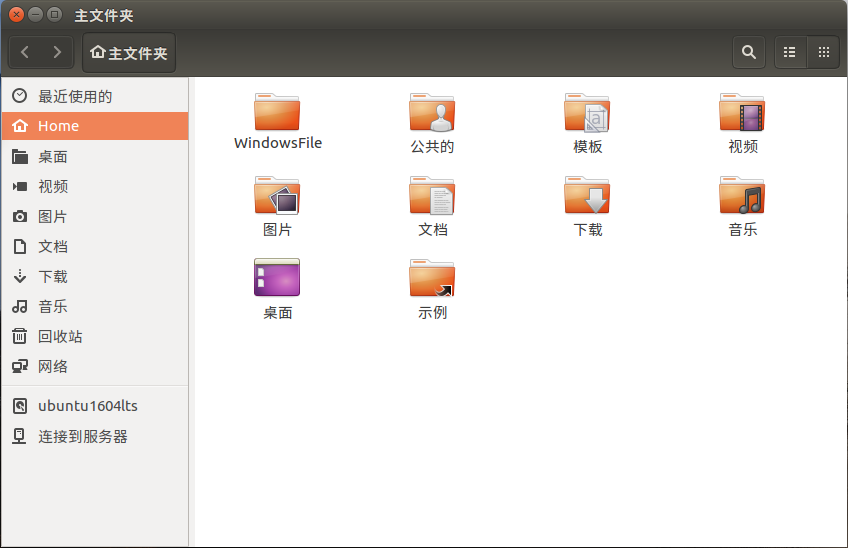
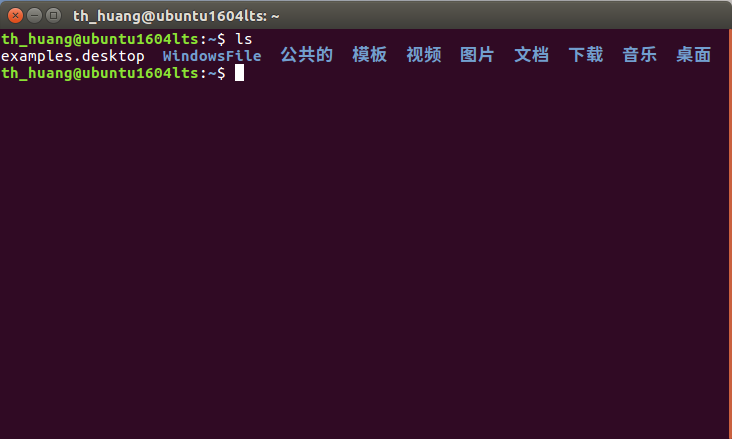
2.对比操作三个文件系统:分别用命令行与窗口方式查看windows,Linux和Hadoop的文件系统的用户主目录。
windows:
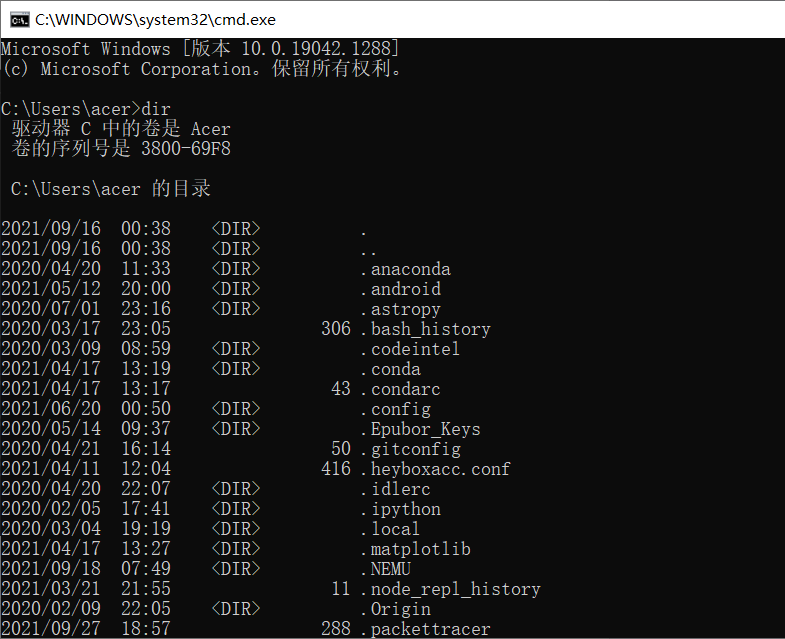
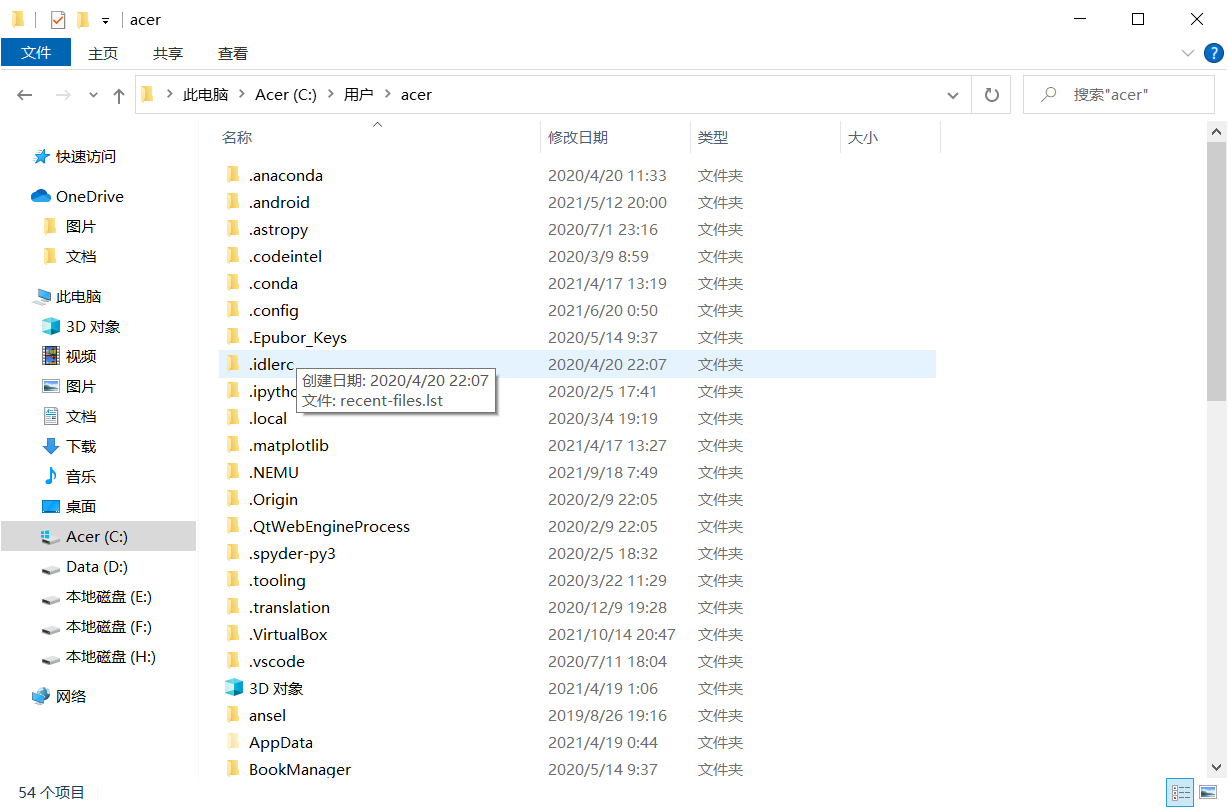
Linux:
3.一个操作案例
a.启动hdfs。
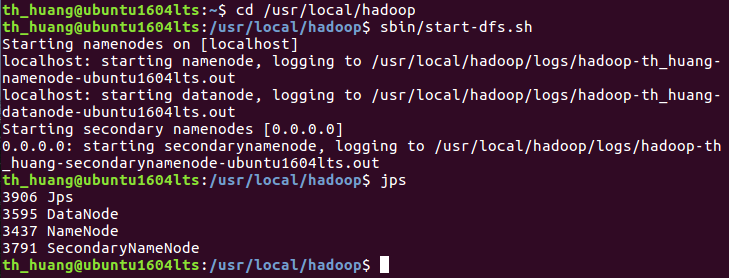
b.查看与创建hadoop用户目录。

c.在用户目录下创建与查看input目录。
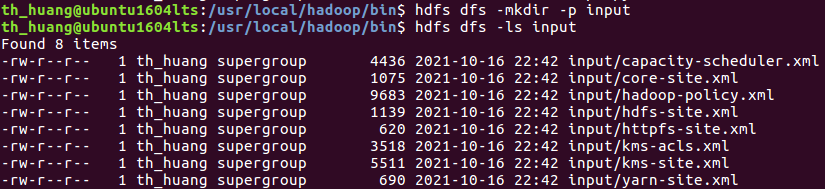
d.将hadoop的配置文件上传到hdfs上的input目录下。

e.运行MapReduce示例作业,输出结果放在output目录下。

f.查看output目录下的文件。

g.查看输出结果。

h.将输出结果文件下载到本地。

i.查看下载的本地文件。

j.停止hdfs。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号