LLM大模型:next token reasoning成为下个阶段LLM的训练范式?
目前LLM的训练范式不外乎这么几步:pre-train、SFT、RL,每个步骤都有自己的作用,比如:
- pre-train:把训练预料的知识压缩到neural的结点
- SFT:初步学会问答
- RL:和人类的偏好对齐
经过上述三步骤后,LLM的效果会有很大提升,然鹅还是摆脱不了目前的一大困境:本质还是个statistic model,原理还是根据上文预测next token的概率,也就是所谓的next token predict,这也是被Yann LeCun这种大佬吐槽最多的点!这种局面能彻底改善么?
1、众所周知,目前LLM在RL阶段最常用的两种方式:
- RLHF:根据人类反馈“定向”训练LLM,比如DPO\PPO等;
- 需要一个reward model评判训练LLM输出的结果是否正确,容易被LLM转空子,就是所谓的reward hacking!
- RLVR:自己摸索过程,给出最终的结果,让rule判断是否正确,比如deepseek R1的GRPO
- 需要大量annotated data,否则无法确定reward信号,导致目前只能在math、code等narrow domain使用(容易基于rule判定reward信号)!
这里打个岔,顺便说一句: LLM有的时候指令遵从不好,可以用RL反复微调,让neural的weight适应训练预料,但这样做也有trade off:其他指令遵从能力可能会下降,所以适用于垂直领域的任务,不太适合通用任务!
2、回到目前LLM的本质:next token predict,核心是根据上文预测next token的概率,是个概率统计模型,怎么改变这一点了?近期清华、北大、微软的研究员借鉴COT的思路,提出了新的思路:Reinforcement Pre-Training,核心方案就是在做next token预测的时候加上reasoning,图示如下:

传统的COT:LLM在正式回答前有think阶段,think完成后才是正式的answer。think阶段做的核心工作:用户的意图理解、任务分解、context关联、信息检索、综合整理等,这些都做完后才是最终的answer,所以在answer之前,做了大量的准备工作,在一定程度上提升了准确率!既然answer的时候可以这么干,那么next token预测的时候不也能这么干么?所以就产生了:next token reasoning的方法!如上图所示,在产生next token的时候,先做reasoning,再输出最终的next token!这个思路也是模拟人的方式:讲话前先过脑子,想清楚了再说!
3、具体到实施,还是有些trick的:
- 要想LLM遵从reasoning的格式,目前最好的方法就是做RL了,作者团队采用的就是deepseek R1同款的GRPO;
- 因为最终的结果很明确,中间过程可以让LLM自己exploration,所以这种scenario特别适合GRPO这种RL的算法!
- 回答的token数量很多,如果每个token都做reasoning,计算量要上天,怎么在保证回答准确率的前提下减少计算量了?回顾一下传统的COT:遇到复杂任务的时候用reasoning提升准确率,普通的简单任务属实没必要了!思路横向迁移到这里:
- 如果next token的概率分布比较集中,说明可选范围小,这种情况直接选概率最大的,比如概率分布[0.6,0.1,0.05,0.09......], 0.6的概率明显大很多,这种情况直接选0.6的token
- 如果next token的概率分布比较平均,可选范围很大,比如[0.2,0.21,0.18,0.19.....] 这种情况怎么办了?这就需要用到reasoning的方法了:在选择next token之前先仔细thinking一下,再决定token选哪个!
- 概率分布是集中还是平均,可以用entropy来计算:entropy越小,说明概率分布越离散,需要reasoning,否则直接让LLM生成就行了!
- 为了让LLM有更好的generalization的性能,每次需要LLM生成multi token的reasoning,让LLM学到上文和next token之间的关系更加泛华、鲁棒,然后选择正确的一个,图示如下:
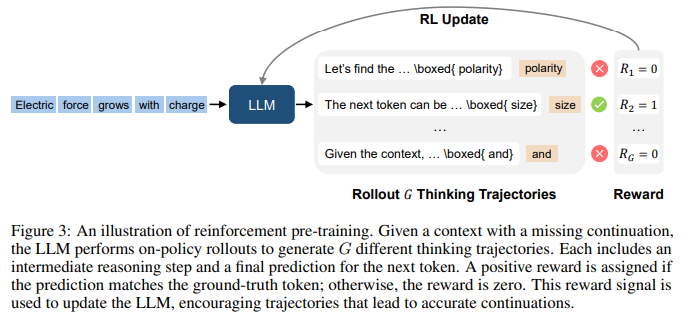
这种思路和deepseek R1的训练其实没本质区别:
- 使用的都是GRPO算法
- 唯一表面的区别就是reasoning的颗粒度不同:这里是针对token级别的reasoning,R1是针对整个回答的
4、效果展示:使用NTR next token reasoning后,准确率都有所提升!尤其是右边的对比:14B模型使用NTR训练后,准确率直逼32B,在一定程度上打破了scaling law?
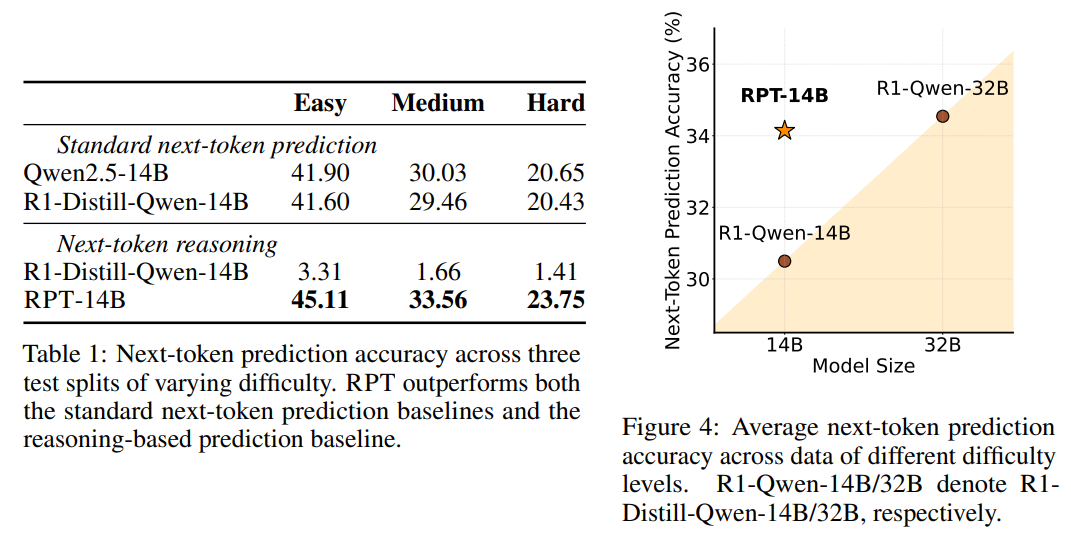
参考:
1、https://arxiv.org/pdf/2506.08007
2、https://www.bilibili.com/video/BV1z1KZzbENE/?spm_id_from=333.337.search-card.all.click&vd_source=241a5bcb1c13e6828e519dd1f78f35b2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号